Cryptanalysis of the Vigenere Cipher
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Cryptography Teachers' Reference
Introduction to Cryptography Teachers’ Reference Dear Teachers! Here I have mentioned some guidelines for your good self so that your students can benefit form these modules. I am very hopeful that you will enjoy conducting the session. After Module-1 1. Scytale Decryption In your class ask your students to devise a method to decrypt the message just been encrypted using Scytale. Encourage them to look around to find a decryption tool. Ask your students to cut a strip of paper some 4mm wide, 32cm long and light pencil lines drawn on it at 4mm distance. To give it the following shape. Now write cipher text on the paper strip in the following way. t i t i r s a e e e e e b h y w i t i l r f d n m g o e e o h v n t t r a a e c a g o o w d m h Encourage them once again to find a tool around them to decrypt it. Ask them to look for a very familiar thing they must have been using right from their early school days to do their work. Now many of them must have figured out that you are asking for a pencil. Now ask them to use the pencil to decrypt the cipher text by using pencil and the only reasonable way would be to wrap the paper strip around the strip. The plain text will be visible along the six side faces of the pencil. Encourage them to reason that how did it work? There is a connection between six rows of the table in which the plain text was filled and the six faces of the pencil. -

Classical Encryption Techniques
CPE 542: CRYPTOGRAPHY & NETWORK SECURITY Chapter 2: Classical Encryption Techniques Dr. Lo’ai Tawalbeh Computer Engineering Department Jordan University of Science and Technology Jordan Dr. Lo’ai Tawalbeh Fall 2005 Introduction Basic Terminology • plaintext - the original message • ciphertext - the coded message • key - information used in encryption/decryption, and known only to sender/receiver • encipher (encrypt) - converting plaintext to ciphertext using key • decipher (decrypt) - recovering ciphertext from plaintext using key • cryptography - study of encryption principles/methods/designs • cryptanalysis (code breaking) - the study of principles/ methods of deciphering ciphertext Dr. Lo’ai Tawalbeh Fall 2005 1 Cryptographic Systems Cryptographic Systems are categorized according to: 1. The operation used in transferring plaintext to ciphertext: • Substitution: each element in the plaintext is mapped into another element • Transposition: the elements in the plaintext are re-arranged. 2. The number of keys used: • Symmetric (private- key) : both the sender and receiver use the same key • Asymmetric (public-key) : sender and receiver use different key 3. The way the plaintext is processed : • Block cipher : inputs are processed one block at a time, producing a corresponding output block. • Stream cipher: inputs are processed continuously, producing one element at a time (bit, Dr. Lo’ai Tawalbeh Fall 2005 Cryptographic Systems Symmetric Encryption Model Dr. Lo’ai Tawalbeh Fall 2005 2 Cryptographic Systems Requirements • two requirements for secure use of symmetric encryption: 1. a strong encryption algorithm 2. a secret key known only to sender / receiver •Y = Ek(X), where X: the plaintext, Y: the ciphertext •X = Dk(Y) • assume encryption algorithm is known •implies a secure channel to distribute key Dr. -

Enhancing the Security of Caesar Cipher Substitution Method Using a Randomized Approach for More Secure Communication
International Journal of Computer Applications (0975 – 8887) Volume 129 – No.13, November2015 Enhancing the Security of Caesar Cipher Substitution Method using a Randomized Approach for more Secure Communication Atish Jain Ronak Dedhia Abhijit Patil Dept. of Computer Engineering Dept. of Computer Engineering Dept. of Computer Engineering D.J. Sanghvi College of D.J. Sanghvi College of D.J. Sanghvi College of Engineering Engineering Engineering Mumbai University, Mumbai, Mumbai University, Mumbai, Mumbai University, Mumbai, India India India ABSTRACT communication can be encoded to prevent their contents from Caesar cipher is an ancient, elementary method of encrypting being disclosed through various techniques like interception plain text message into cipher text protecting it from of message or eavesdropping. Different ways include using adversaries. However, with the advent of powerful computers, ciphers, codes, substitution, etc. so that only the authorized there is a need for increasing the complexity of such people can view and interpret the real message correctly. techniques. This paper contributes in the area of classical Cryptography concerns itself with four main objectives, cryptography by providing a modified and expanded version namely, 1) Confidentiality, 2) Integrity, 3) Non-repudiation for Caesar cipher using knowledge of mathematics and and 4) Authentication. [1] computer science. To increase the strength of this classical Cryptography is divided into two types, Symmetric key and encryption technique, the proposed modified algorithm uses Asymmetric key cryptography. In Symmetric key the concepts of affine ciphers, transposition ciphers and cryptography a single key is shared between sender and randomized substitution techniques to create a cipher text receiver. The sender uses the shared key and encryption which is nearly impossible to decode. -

COS433/Math 473: Cryptography Mark Zhandry Princeton University Spring 2017 Cryptography Is Everywhere a Long & Rich History
COS433/Math 473: Cryptography Mark Zhandry Princeton University Spring 2017 Cryptography Is Everywhere A Long & Rich History Examples: • ~50 B.C. – Caesar Cipher • 1587 – Babington Plot • WWI – Zimmermann Telegram • WWII – Enigma • 1976/77 – Public Key Cryptography • 1990’s – Widespread adoption on the Internet Increasingly Important COS 433 Practice Theory Inherent to the study of crypto • Working knowledge of fundamentals is crucial • Cannot discern security by experimentation • Proofs, reductions, probability are necessary COS 433 What you should expect to learn: • Foundations and principles of modern cryptography • Core building blocks • Applications Bonus: • Debunking some Hollywood crypto • Better understanding of crypto news COS 433 What you will not learn: • Hacking • Crypto implementations • How to design secure systems • Viruses, worms, buffer overflows, etc Administrivia Course Information Instructor: Mark Zhandry (mzhandry@p) TA: Fermi Ma (fermima1@g) Lectures: MW 1:30-2:50pm Webpage: cs.princeton.edu/~mzhandry/2017-Spring-COS433/ Office Hours: please fill out Doodle poll Piazza piaZZa.com/princeton/spring2017/cos433mat473_s2017 Main channel of communication • Course announcements • Discuss homework problems with other students • Find study groups • Ask content questions to instructors, other students Prerequisites • Ability to read and write mathematical proofs • Familiarity with algorithms, analyZing running time, proving correctness, O notation • Basic probability (random variables, expectation) Helpful: • Familiarity with NP-Completeness, reductions • Basic number theory (modular arithmetic, etc) Reading No required text Computer Science/Mathematics Chapman & Hall/CRC If you want a text to follow along with: Second CRYPTOGRAPHY AND NETWORK SECURITY Cryptography is ubiquitous and plays a key role in ensuring data secrecy and Edition integrity as well as in securing computer systems more broadly. -

Simple Substitution and Caesar Ciphers
Spring 2015 Chris Christensen MAT/CSC 483 Simple Substitution Ciphers The art of writing secret messages – intelligible to those who are in possession of the key and unintelligible to all others – has been studied for centuries. The usefulness of such messages, especially in time of war, is obvious; on the other hand, their solution may be a matter of great importance to those from whom the key is concealed. But the romance connected with the subject, the not uncommon desire to discover a secret, and the implied challenge to the ingenuity of all from who it is hidden have attracted to the subject the attention of many to whom its utility is a matter of indifference. Abraham Sinkov In Mathematical Recreations & Essays By W.W. Rouse Ball and H.S.M. Coxeter, c. 1938 We begin our study of cryptology from the romantic point of view – the point of view of someone who has the “not uncommon desire to discover a secret” and someone who takes up the “implied challenged to the ingenuity” that is tossed down by secret writing. We begin with one of the most common classical ciphers: simple substitution. A simple substitution cipher is a method of concealment that replaces each letter of a plaintext message with another letter. Here is the key to a simple substitution cipher: Plaintext letters: abcdefghijklmnopqrstuvwxyz Ciphertext letters: EKMFLGDQVZNTOWYHXUSPAIBRCJ The key gives the correspondence between a plaintext letter and its replacement ciphertext letter. (It is traditional to use small letters for plaintext and capital letters, or small capital letters, for ciphertext. We will not use small capital letters for ciphertext so that plaintext and ciphertext letters will line up vertically.) Using this key, every plaintext letter a would be replaced by ciphertext E, every plaintext letter e by L, etc. -

The Mathemathics of Secrets.Pdf
THE MATHEMATICS OF SECRETS THE MATHEMATICS OF SECRETS CRYPTOGRAPHY FROM CAESAR CIPHERS TO DIGITAL ENCRYPTION JOSHUA HOLDEN PRINCETON UNIVERSITY PRESS PRINCETON AND OXFORD Copyright c 2017 by Princeton University Press Published by Princeton University Press, 41 William Street, Princeton, New Jersey 08540 In the United Kingdom: Princeton University Press, 6 Oxford Street, Woodstock, Oxfordshire OX20 1TR press.princeton.edu Jacket image courtesy of Shutterstock; design by Lorraine Betz Doneker All Rights Reserved Library of Congress Cataloging-in-Publication Data Names: Holden, Joshua, 1970– author. Title: The mathematics of secrets : cryptography from Caesar ciphers to digital encryption / Joshua Holden. Description: Princeton : Princeton University Press, [2017] | Includes bibliographical references and index. Identifiers: LCCN 2016014840 | ISBN 9780691141756 (hardcover : alk. paper) Subjects: LCSH: Cryptography—Mathematics. | Ciphers. | Computer security. Classification: LCC Z103 .H664 2017 | DDC 005.8/2—dc23 LC record available at https://lccn.loc.gov/2016014840 British Library Cataloging-in-Publication Data is available This book has been composed in Linux Libertine Printed on acid-free paper. ∞ Printed in the United States of America 13579108642 To Lana and Richard for their love and support CONTENTS Preface xi Acknowledgments xiii Introduction to Ciphers and Substitution 1 1.1 Alice and Bob and Carl and Julius: Terminology and Caesar Cipher 1 1.2 The Key to the Matter: Generalizing the Caesar Cipher 4 1.3 Multiplicative Ciphers 6 -

FROM JULIUS CAESAR to the BLOCKCHAIN: a BRIEF HISTORY of CRYPTOGRAPHY by Côme JEAN JARRY & Romain ROUPHAEL, Cofounders of BELEM
Corporate identity in the digital era #9 JANUARY 2017 FROM JULIUS CAESAR TO THE BLOCKCHAIN: A BRIEF HISTORY OF CRYPTOGRAPHY By Côme JEAN JARRY & Romain ROUPHAEL, cofounders of BELEM 22 The world’s most important asset is information. Now message was inscribed lengthwise. Once the parchment more than ever. With computer theft and hacking was unrolled, the letters of the message were mixed becoming a common threat, protecting information up and the message meaningless. The receiver would is crucial to ensure a trusted global economy. need an identical stick to decipher the text. The E-commerce, online banking, social networking or scytale transposition cipher relied on changing the emailing, online medical results checking, all our order of the letters, rather than the letters themselves. transactions made across digital networks and This cryptographic technique still prevails today. insecure channels of communication, such as the Internet, mobile phones or ATMs, are subjected to vulnerabilities. Our best answer is cryptography. And THE ART OF SUBSTITUTION it has always been. As a science and as an art, it is Julius Caesar was also known to use encryption to an essential way to protect communication. convey messages to his army generals posted in the Cryptography goes back to older times, as far back as war front. The Caesar cipher is a simple substitution the Ancient World. cipher in which each letter of the plaintext is rotated left or right by some number of positions down the alphabet. The receiver of the message would then Early cryptography was solely concerned with shift the letters back by the same number of positions concealing and protecting messages. -

Index-Of-Coincidence.Pdf
The Index of Coincidence William F. Friedman in the 1930s developed the index of coincidence. For a given text X, where X is the sequence of letters x1x2…xn, the index of coincidence IC(X) is defined to be the probability that two randomly selected letters in the ciphertext represent, the same plaintext symbol. For a given ciphertext of length n, let n0, n1, …, n25 be the respective letter counts of A, B, C, . , Z in the ciphertext. Then, the index of coincidence can be computed as 25 ni (ni −1) IC = ∑ i=0 n(n −1) We can also calculate this index for any language source. For some source of letters, let p be the probability of occurrence of the letter a, p be the probability of occurrence of a € b the letter b, and so on. Then the index of coincidence for this source is 25 2 Isource = pa pa + pb pb +…+ pz pz = ∑ pi i=0 We can interpret the index of coincidence as the probability of randomly selecting two identical letters from the source. To see why the index of coincidence gives us useful information, first€ note that the empirical probability of randomly selecting two identical letters from a large English plaintext is approximately 0.065. This implies that an (English) ciphertext having an index of coincidence I of approximately 0.065 is probably associated with a mono-alphabetic substitution cipher, since this statistic will not change if the letters are simply relabeled (which is the effect of encrypting with a simple substitution). The longer and more random a Vigenere cipher keyword is, the more evenly the letters are distributed throughout the ciphertext. -

CPSC 467B: Cryptography and Computer Security
Outline Perfect secrecy One-time pad Cryptanalysis CPSC 467b: Cryptography and Computer Security Michael J. Fischer Lecture 3 January 15, 2010 Michael J. Fischer CPSC 467b 1/40 Outline Perfect secrecy One-time pad Cryptanalysis 1 Perfect secrecy Caesar cipher Loss of perfection 2 One-time pad 3 Cryptanalysis Caesar cipher Brute force attack Manual attacks Michael J. Fischer CPSC 467b 2/40 Outline Perfect secrecy One-time pad Cryptanalysis Caesar cipher Loss of perfection Caesar cipher Recall: Base Caesar cipher: Ek (m) = (m + k) mod 26 Dk (c) = (c − k) mod 26: Full Caesar cipher: r Ek (m1 ::: mr ) = Ek (m1) ::: Ek (mr ) r Dk (c1 ::: cr ) = Dk (c1) ::: Dk (cr ): Michael J. Fischer CPSC 467b 3/40 Outline Perfect secrecy One-time pad Cryptanalysis Caesar cipher Loss of perfection Simplified Caesar cipher A probabilistic analysis of the Caesar cipher. Simplify by restricting to a 3-letter alphabet. M = C = K = f0; 1; 2g Ek (m) = (m + k) mod 3 Dk (m) = (m − k) mod 3. A priori message probabilities: m pm 0 1=2 1 1=3 2 1=6 Michael J. Fischer CPSC 467b 4/40 Outline Perfect secrecy One-time pad Cryptanalysis Caesar cipher Loss of perfection Joint message-key distribution Each key has probability 1/3. Joint probability distribution: k z }| { 0 1 2 8 0 1=6 1=6 1=6 < m 1 1=9 1=9 1=9 : 2 1=18 1=18 1=18 Michael J. Fischer CPSC 467b 5/40 Outline Perfect secrecy One-time pad Cryptanalysis Caesar cipher Loss of perfection Conditional probability distribution Recall P[m = 1] = 1=3. -

An Investigation Into Mathematical Cryptography with Applications
Project Report BSc (Hons) Mathematics An Investigation into Mathematical Cryptography with Applications Samuel Worton 1 CONTENTS Page: 1. Summary 3 2. Introduction to Cryptography 4 3. A History of Cryptography 6 4. Introduction to Modular Arithmetic 12 5. Caesar Cipher 16 6. Affine Cipher 17 7. Vigenère Cipher 19 8. Autokey Cipher 21 9. One-Time Pad 22 10. Pohlig-Hellman Encryption 24 11. RSA Encryption 27 12. MATLAB 30 13. Conclusion 35 14. Glossary 36 15. References 38 2 1. SUMMARY AND ACKNOWLEDGEMENTS In this report, I will explore the history of cryptography, looking at the origins of cryptosystems in the BC years all the way through to the current RSA cryptosystem which governs the digital era we live in. I will explain the mathematics behind cryptography and cryptanalysis, which is largely based around number theory and in particular, modular arithmetic. I will relate this to several famous, important and relevant cryptosystems, and finally I will use the MATLAB program to write codes for a few of these cryptosystems. I would like to thank Mr. Kuldeep Singh for his feedback and advice during all stages of my report, as well as enthusiasm towards the subject. I would also like to thank Mr. Laurence Taylor for generously giving his time to help me in understanding and producing the MATLAB coding used towards the end of this investigation. Throughout this report I have been aided by the book ‘Elementary Number Theory’ by Mr. David M. Burton, amongst others, which was highly useful in refreshing my number theory knowledge and introducing me to the concepts of cryptography; also Mr. -

Automating the Development of Chosen Ciphertext Attacks
Automating the Development of Chosen Ciphertext Attacks Gabrielle Beck∗ Maximilian Zinkus∗ Matthew Green Johns Hopkins University Johns Hopkins University Johns Hopkins University [email protected] [email protected] [email protected] Abstract In this work we consider a specific class of vulner- ability: the continued use of unauthenticated symmet- In this work we investigate the problem of automating the ric encryption in many cryptographic systems. While development of adaptive chosen ciphertext attacks on sys- the research community has long noted the threat of tems that contain vulnerable format oracles. Unlike pre- adaptive-chosen ciphertext attacks on malleable en- vious attempts, which simply automate the execution of cryption schemes [17, 18, 56], these concerns gained known attacks, we consider a more challenging problem: practical salience with the discovery of padding ora- to programmatically derive a novel attack strategy, given cle attacks on a number of standard encryption pro- only a machine-readable description of the plaintext veri- tocols [6,7, 13, 22, 30, 40, 51, 52, 73]. Despite repeated fication function and the malleability characteristics of warnings to industry, variants of these attacks continue to the encryption scheme. We present a new set of algo- plague modern systems, including TLS 1.2’s CBC-mode rithms that use SAT and SMT solvers to reason deeply ciphersuite [5,7, 48] and hardware key management to- over the design of the system, producing an automated kens [10, 13]. A generalized variant, the format oracle attack strategy that can entirely decrypt protected mes- attack can be constructed when a decryption oracle leaks sages. -
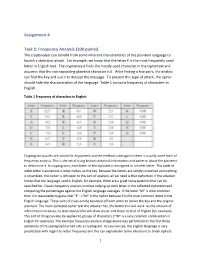
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language.