Integrating Mobile Computing with Fixed Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Velocity Users Guide
Velocity Users Guide The Apache Velocity Developers Version 1.5 Copyright © 2006 The Apache Software Foundation Table of Contents 1. Preface .......................................................................................................................................... 1 1.1. About this Guide .................................................................................................................. 1 1.2. Acknowledgements ............................................................................................................... 1 1.3. Intended Audience ................................................................................................................ 1 1.4. Feedback ............................................................................................................................ 1 2. What is Velocity? ........................................................................................................................... 2 2.1. The Fruit Store .................................................................................................................... 2 2.2. An introduction to the Velocity Template Language ................................................................... 3 2.3. Hello Velocity World! ........................................................................................................... 4 3. Language elements .......................................................................................................................... 5 3.1. Statements and directives -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

Mastering Apache Velocity Joseph D. Gradecki Jim Cole
a 457949 FM.qxd 6/13/03 1:45 PM Page i Mastering Apache Velocity Joseph D. Gradecki Jim Cole Wiley Publishing, Inc. a 457949 FM.qxd 6/13/03 1:45 PM Page xii a 457949 FM.qxd 6/13/03 1:45 PM Page i Mastering Apache Velocity Joseph D. Gradecki Jim Cole Wiley Publishing, Inc. a 457949 FM.qxd 6/13/03 1:45 PM Page ii Publisher: Joe Wikert Copyeditor: Elizabeth Welch Executive Editor: Robert Elliott Compositors: Gina Rexrode and Amy Hassos Editorial Manager: Kathryn Malm Managing Editor: Vincent Kunkemueller Book Producer: Ryan Publishing Group, Inc. Copyright © 2003 by Joseph D. Gradecki and Jim Cole. All rights reserved. Published by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8700. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4447, E-mail: [email protected]. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or com- pleteness of the contents of this book and specifically disclaim any implied warranties of mer- chantability or fitness for a particular purpose. -

Interop.Jar Activation
Resource name License name License reference Usage Type a-j-interop.jar Eclipse 1.0 http://www.j-interop.org/license.html Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/javax/activation/act activation-1.1.jar CDDL 1.0 ivation/1.1/activation-1.1.pom Dynamic library activation.jar LGPL 2.1 https://github.com/wildfly/wildfly/blob/master/README.md Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-all-5.7.0.jar Apache 2.0 q/activemq-all/5.7.0/activemq-all-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-core-5.7.0.jar Apache 2.0 q/activemq-core/5.7.0/activemq-core-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-pool-5.7.0.jar Apache 2.0 q/activemq-pool/5.7.0/activemq-pool-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-protobuf-1.1.jar Apache 2.0 q/protobuf/activemq-protobuf/1.1/activemq-protobuf-1.1.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/axis2/a addressing-1.6.2.jar Apache 2.0 ddressing/1.6.2/addressing-1.6.2.pom Dynamic library advancedPersistentLookupLib-1.0.jar Commercial http://www.talend.com Dynamic library aether-api-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic library aether-connector-asynchttpclient-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic library aether-connector-wagon-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic -

Michael Ormsby
Michael Ormsby 24 Dawn Heath Drive Littleton, CO 80127 [email protected] Skype: ormsbytrek 303 933 7793 (home) 303 946 3678 (cell) Michael's website Michael's LinkedIn profile Career Objective A web / RIA design and development position offering interesting work utilizing some of the following interests: y Web design, web application design, Adobe Flex / Flash / AIR, HTML, CSS y Programming in Actionscript, Javascript, PHP, Ruby, and Java y User Interface design y Digital photography, digital video y UNIX, Linux, Mac OS X, Solaris Web Programming, Authoring, Admin Skills Adobe Flex 3, some familiarity with Flex 4. Adobe AIR, Flash, Cairngorm. HTML, XHTML, DHTML, CSS. XML, XSLT, XPath. Actionscript, Javascript, PHP, SVG, DOM API, Ajax. jQuery Javascript library. Eclipse, Ruby, Perl, Java 5, JSP. Omniture. Social Networking APIs. Apache Velocity and VTL. Apache web server administration. HTTP, DNS. Web Front End and Media Skills User Interface design. Drawing wireframes. Adobe CS4 apps: Flash, Photoshop, Illustrator. Adobe Flex 3 / AIR certification (ACE). Digital photography, digital image manipulation and formats. Video file formats, conversions, and encodings such as H.264. Some familiarity with shooting and editing video footage. Web Application Frameworks and Infrastructure Cairngorm and Kingussie Flex frameworks. RubyAMF. Liferay Portal, Oracle (BEA) Weblogic Portal. Servlets, JSR 286 portlets, web services. Apache Struts, WebLogic Server. Database Skills Relational database design, SQL, JDBC, Oracle, MySQL. Other Programming Languages C++, C, UNIX shells. Programming Design Methodologies UML notation. Use Cases. Design Patterns. OOP. Hardware and Operating Systems Apple hardware and OS X. Sun Solaris. Wacom graphics tablet. UNIX / Linux system APIs. Linux installation and configuration. -

Another Tool
Sr.N o. 3rd Party Software 3rd Party Files Provider URL License Type Reference to License License Link ANTLR – Another Tool for Copyright (c) 2005, Terence 1 Language Recognition antlr-2.7.6.jar http://www.antlr.org/ Parr, BSD License ANTLR_License.txt http://www.antlr2.org/license.html ASM - An all purpose Java bytecode manipulation and Copyright (c) 2000-2005 INRIA, 2 analysis framework asm.jar, asm-attrs.jar http://asm.ow2.org/ France Telecom BSD ASM.txt http://asm.ow2.org/license.html http://archive.apache.org/dist/avalon/avalon- 3 Apache Avalon Framework avalon-framework-cvs-20020806.jar http://avalon.apache.org/closed.html Apache License, Version 2.0 Apache2_License.txt framework/jars/LICENSE.txt 4 Apache Axis - Web Services axis.jar http://ws.apache.org/axis/ Apache License, Version 2.0 Apache2_License.txt http://www.apache.org/licenses/LICENSE-2.0.txt 5 Batik SVG Toolkit batik.jar http://xmlgraphics.apache.org/batik/faq.html Apache License, Version 2.0 Apache2_License.txt http://xmlgraphics.apache.org/batik/license.html Eclipse Public License, Version 6 bilki bliki-core-3.0.15.jar http://code.google.com/p/gwtwiki/downloads/list 1.0 EPL.txt http://www.eclipse.org/legal/epl-v10.html 7 Bean Scripting Framework (BSF) bsf.jar http://jakarta.apache.org/bsf/ Apache License, Version 2.0 Apache2_License.txt http://www.apache.org/licenses/LICENSE-2.0.txt GNU Lesser General Public 8 Bean Shell (BSH) bsh-1.2b7.jar http://www.beanshell.org/ License, Sun Public License BSH_License.txt http://www.gnu.org/licenses/lgpl-3.0.txt Apache/IBM Bean Scripting Framework (BSF) Adapter for GNU Lesser General Public 9 BeanShell bsh-bsf-2.0b4.jar http://www.beanshell.org/download.html License, Sun Public License BSH_License.txt http://www.gnu.org/licenses/lgpl-3.0.txt c3p0:JDBC Copyright (C) 2005 Machinery 10 DataSources/Resource Pools c3p0-0.9.1.2.jar http://sourceforge.net/projects/c3p0 For Change, Inc. -

Velocity Reference
APPENDIX Velocity Reference VELOCITY HAS A WIDE RANGE of configuration settings, directives, and resource loaders. This appendix is a reference for aU aspects of Velocity configuration and usage. Introducing the Directives The following sections show the syntax for the standard directives included in the Velocity distribution. #set The #set directive assigns variables' values. These values can be a simple literal value or another variable. Syntax #set($variable=<literal value> I <variable_name» Example #set($myVar = "Hello World") Output The #set directive has no output. 347 Appendix #if/#else/#end The #if/#else/#end directives support conditional processing within your tem plates. The use of these directives is synonymous with the use of the if/else construct in Java. Syntax #if«boolean expression> I <boolean literal> I <boolean variable reference» Output for true #else Output for false #end Example #set($someVar = true) #if($someVar) Hello World! #else Goodbye Cruel World! #end Output Hello World! #foreach The #foreach directive iterates over all elements in a collection or an array and performs some processing for each element. Syntax #foreach($var in $collectionOrArray) ## do something with $var #end 348 Velocity Reference Example #foreach($num in [0 •• 5]) $num #end Output o 1 2 3 4 5 #include The #include directive includes some content from another resource in the out put stream. The content is added as-is with no processing by the Velocity engine. Syntax #import«resource_name» Example For example, the main template, template. vm, could contain the followingVfL code: Hello #include("world.txt") And an external file resource, world. txt, could contain the following static text: World Output Hello World 349 Appendix #parse The #parse directive functions in a similar manner to the #include directive; however, the external resource is first parsed by the Velocity engine, and any VTL constructs are processed as if they were part of the main template. -

Talend Open Studio for Big Data Getting Started Guide
Talend Open Studio for Big Data Getting Started Guide 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date: July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, -

4.2 Using Spring IO Platform with Gradle
Spring IO Platform Reference Guide Cairo-RELEASE Copyright © 2014-2018 Copies of this document may be made for your own use and for distribution to others, provided that you do not charge any fee for such copies and further provided that each copy contains this Copyright Notice, whether distributed in print or electronically. Spring IO Platform Reference Guide Table of Contents I. Spring IO Platform Documentation ............................................................................................ 1 1. About the documentation ................................................................................................ 2 2. Getting help .................................................................................................................... 3 II. Getting Started ....................................................................................................................... 4 3. Introducing Spring IO Platform ........................................................................................ 5 4. Using Spring IO Platform ................................................................................................ 6 4.1. Using Spring IO Platform with Maven .................................................................... 6 4.2. Using Spring IO Platform with Gradle .................................................................... 7 5. Overriding Spring IO Platform’s dependency management ................................................ 9 5.1. Overriding a version using Maven ........................................................................ -

Netbeans/Distributed Netbeans
Modern Software Development Tools on OpenVMS Meg Watson Principal Software Engineer © 2006 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice Topics • Modern Development Tools for OpenVMS – NetBeans/Distributed NetBeans • Modernizing Existing Applications – Web Service Integration Toolkit • Questions page 2 What is Modern Software Development? • Object-Oriented Languages – Java, C++, C#, etc • Current Popular Software Designs – Web-based – Application server based • JSPs, Servlets, EJBs, Web Services – Service oriented architecture • Distributed Applications – Heterogeneous execution environments • Modern development methodology – Agile methods – Work well with object-oriented languages Goal: Use the same tools to develop all the pieces! page 3 Today’s Environment Application Enterprise PDA Web servers Windows servers system Web Server Enterprise browser Apache JavaBean (J2EE) Database Desktop and scripting Perl JavaBean (J2SE) Web PHP Services Legacy ASP applications JSP Other .NET Java servlet Client Presentation Business Logic Enterprise Tier Middle Tier Tier page 4 What is NetBeans? • Sun-Sponsored Open-Source Integrated Development Environment • 100% Java – runs anywhere there’s a JVM • Current version is 5.5.1, with 6.0 in beta • Feature-rich: drag-n-drop GUI creation, excellent editing, JSPs, Web services, excellent debugging, profiling, etc. • Extensible via plug-ins • Positioned as platform and IDE • Competes with Eclipse…the leap frog effect page 5 Why Not Use Eclipse? -
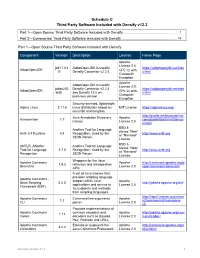
Schedule C Third Party Software Included with Densify V12.2
Schedule C Third Party Software Included with Densify v12.2 Part 1—Open Source Third Party Software Included with Densify ....................................................... 1 Part 2—Commercial Third Party Software Included with Densify ....................................................... 14 Part 1—Open Source Third Party Software Included with Densify Component Version Description License Home Page Apache License 2.0, jdk11.0.4 AdoptOpenJDK is used in https://adoptopenjdk.net/inde AdoptOpenJDK _11 Densify Connector v2.2.4 GPL v2 with x.html Classpath Exception Apache AdoptOpenJDK is used in License 2.0, jdk8u202 Densify Connector v2.2.3 https://adoptopenjdk.net/inde AdoptOpenJDK -b08 and Densify 12.x on- GPL v2 with x.html premises version. Classpath Exception Security-oriented, lightweight Alpine Linux 3.11.5 Linux distribution based on MIT License https://alpinelinux.org/ musl libc and busybox. http://gradle.artifactoryonline. Java Annotation Discovery Apache Annovention 1.7 com/gradle/libs/tv/cntt/annov Library License 2.0 ention/ BSD 3- Another Tool for Language clause "New" Antlr 3.4 Runtime 3.4 Recognition. Used by the http://www.antlr.org or "Revised" JSON Parser. License BSD 3- ANTLR, ANother Another Tool for Language clause "New" Tool for Language 2.7.5 Recognition. Used by the http://www.antlr.org or "Revised" Recognition JSON Parser. License Wrappers for the Java Apache Commons Apache http://commons.apache.org/p 1.9.3 reflection and introspection BeanUtils License 2.0 roper/commons-beanutilsl APIs. A set of Java classes that provides scripting language Apache Commons - support within Java Apache Bean Scripting 2.4.0 http://jakarta.apache.org/bsf/ applications and access to License 2.0 Framework (BSF) Java objects and methods from scripting languages. -

WE05 Hacking Velocity
Hacking Velocity – ApacheCon 2004 • What is Velocity • Velocity Tools • Custom Directives • Custom Resourceloaders • Custom Introspector • Adding Event Handlers • Modifying Velocity Syntax Presenter Contact Info: Will Glass-Husain Menlo Park, California USA [email protected] + 1 415 440-7500 November 17, 2004 (c) 2004 Will Glass-Husain. Non-commercial redistribution permitted freely. 1 What is Velocity? • A templating engine that can generate any type of text output, including HTML, email, SQL, or Java source code. • Based on a "pull" approach in which a text file includes "References" to data objects that are pulled from a provided "Context". $Date Date Order Dear $Contact.FirstName $Contact.LastName, Contact Thank you for your recent purchase of $Order.ProductName. The cost of the item was $Order.TotalCost#if($Order.Tax > 0) including a tax of $Order.TaxRate%#end. Sincerely, November 17, 2004 Biggest and Best Book Merchants, Inc. Dear Jennifer Glass, Thank you for your recent purchase of Alice in Wonderland, Annotated Edition. The cost of the item was $29.95. Sincerely, Biggest and Best Book Merchants, Inc. November 17, 2004 (c) 2004 Will Glass-Husain. Non-commercial redistribution permitted freely. 2 Basic Velocity Concepts • References – References objects from the Velocity context. Starts with a "$". – Can have Properties or Methods – Common practice is to provide two types: data objects (with properties) and "tools" (with methods). – Examples: • $contact.FirstName • $format("$#,##0.00",$order.price) • Directives – Control statements. Starts with a "#" – Example block directive: • #if ($columncount > 0) display a table #end – Example line directive: • #include('header.vm') November 17, 2004 (c) 2004 Will Glass-Husain. Non-commercial redistribution permitted freely.