“Visualization Tool Development and Malleable Applications Planning”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Forge and Performance Reports Modules $ Module Load Intel Intelmpi $ Module Use /P/Scratch/Share/VI-HPS/JURECA/Mf/ $ Module Load Arm-Forge Arm-Reports
Acting on Insight Tips for developing and optimizing scientific applications [email protected] 28/06/2019 Agenda • Introduction • Maximize application efficiency • Analyze code performance • Profile multi-threaded codes • Optimize Python-based applications • Visualize code regions with Caliper 2 © 2019 Arm Limited Arm Technology Already Connects the World Arm is ubiquitous Partnership is key Choice is good 21 billion chips sold by We design IP, we do not One size is not always the best fit partners in 2017 manufacture chips for all #1 in Infrastructure today with Partners build products for HPC is a great fit for 28% market shares their target markets co-design and collaboration 3 © 2019 Arm Limited Arm’s solution for HPC application development and porting Combines cross-platform tools with Arm only tools for a comprehensive solution Cross-platform Tools Arm Architecture Tools FORGE C/C++ & FORTRAN DDT MAP COMPILER PERFORMANCE PERFORMANCE REPORTS LIBRARIES 4 © 2019 Arm Limited The billion dollar question in “weather and forecasting” Is it going to rain tomorrow? 1. Choose domain 2. Gather Data 3. Create Mesh 4. Match Data to Mesh 5. Simulate 6. Visualize 5 © 2019 Arm Limited Weather forecasting workflow Deploy Production Staging environment Builds Scalability Performance Develop Fix Regressions CI Agents Optimize Commit Continuous Version Start CI job control integration Pull system framework • 24 hour timeframe 6 © 2019 Arm Limited • 2 to 3 test runs for 1 production run Application efficiency Scientist Developer System admin Decision maker • Efficient use of allocation • Characterize application • Maximize resource usage • High-level view of system time behaviour • Diagnose performance workload • Higher result throughput • Gets hints on next issues • Reporting figures and optimization steps analysis to help decision making 7 © 2019 Arm Limited Arm Performance Reports Characterize and understand the performance of HPC application runs Gathers a rich set of data • Analyses metrics around CPU, memory, IO, hardware counters, etc. -

Adaptive Data Migration in Load-Imbalanced HPC Applications
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 10-16-2020 Adaptive Data Migration in Load-Imbalanced HPC Applications Parsa Amini Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Computer Sciences Commons Recommended Citation Amini, Parsa, "Adaptive Data Migration in Load-Imbalanced HPC Applications" (2020). LSU Doctoral Dissertations. 5370. https://digitalcommons.lsu.edu/gradschool_dissertations/5370 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. ADAPTIVE DATA MIGRATION IN LOAD-IMBALANCED HPC APPLICATIONS A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Computer Science by Parsa Amini B.S., Shahed University, 2013 M.S., New Mexico State University, 2015 December 2020 Acknowledgments This effort has been possible, thanks to the involvement and assistance of numerous people. First and foremost, I thank my advisor, Dr. Hartmut Kaiser, who made this journey possible with their invaluable support, precise guidance, and generous sharing of expertise. It has been a great privilege and opportunity for me be your student, a part of the STE||AR group, and the HPX development effort. I would also like to thank my mentor and former advisor at New Mexico State University, Dr. -

Fairborn Camera & Video
© 2006 The Dayton Microcomputer Association, Inc. V O L UM E 3 1 , I S S U E 6 P A G E 1 TM Volume 31 Issue 6 www.DMA.org November 2006 Association of PC User Groups (APCUG) Member Location for October 31 General Meeting Topic meeting & map inside ... Parking Permits Fairborn Camera & Video Available … Mike Petros - Guest Speaker As the holidays approach, the search be- for prints. RAW format allows the option of gins for the hottest items for Christmas. We manipulating details with photo-editing soft- generally look for some high-tech gadget ware on a PC. It’s a good thing that memory that could make our lives easier, more pro- cards hold more data than ever before. ductive, or just plain fun. The latest in cam- Mike Petros, Store Manager at Fairborn era equipment has always been a favorite Camera & Video, has agreed to demonstrate and the choices this year are impressive. several of this year’s latest digital cameras There seem to be a half dozen models for and help make sense of their many features. every application. Credit-card sized “point Mike draws from 30 years of experience in and shoot” cameras fit easily in a pocket and the business. He often gives presentations to travel well. Those best suited for sports pho- local organizations and once wrote articles tography are the ones marked “single-lens- for the Midwest PC Review magazine. reflex”. They tend to be more responsive Although he would not give away any de- and accept interchangeable lenses. Cameras tails on the specials they will be running this of all sizes offer digital viewfinders. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -
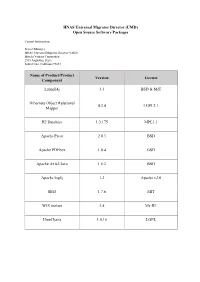
UMD) Open Source Software Packages
HNAS Universal Migrator Director (UMD) Open Source Software Packages Contact Information: Project Manager HNAS Universal Migrator Director (UMD) Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Launch4j 3.3 BSD & MIT Hibernate Object Relational 4.3.4 LGPL2.1 Mapper H2 Database 1.3.175 MPL1.1 Apache Pivot 2.0.3 BSD Apache PDFbox 1.8.4 BSD Apache Axis2/Java 1.6.2 BSD Apache log4j 1.2 Apache v2.0 Slf4J 1.7.6 MIT WIX toolset 3.8 Ms-RL JfreeCharts 1.0.16 LGPL The text of the open source software licenses listed in this document is provided in the Open Source Software License Terms document on www.hitachivantara.com. Note that the source code for packages licensed under the GNU General Public License or similar type of license that requires the licensor to make the source code publicly available (“GPL Software”) may be available for download as indicated. If the source code for GPL Software is not included in the software or available for download, please send requests for source code for GPL Software to the contact person listed above for this product. The material in this document is provided “AS IS,” without warranty of any kind, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. Unless specified in an applicable open source license, access to this material grants you no right or license, express or implied, statutorily or otherwise, under any patent, trade secret, copyright, or any other intellectual property right of Hitachi Vantara Corporation (“Hitachi”). -

Performance Tuning Workshop
Performance Tuning Workshop Samuel Khuvis Scientifc Applications Engineer, OSC February 18, 2021 1/103 Workshop Set up I Workshop – set up account at my.osc.edu I If you already have an OSC account, sign in to my.osc.edu I Go to Project I Project access request I PROJECT CODE = PZS1010 I Reset your password I Slides are the workshop website: https://www.osc.edu/~skhuvis/opt21_spring 2/103 Outline I Introduction I Debugging I Hardware overview I Performance measurement and analysis I Help from the compiler I Code tuning/optimization I Parallel computing 3/103 Introduction 4/103 Workshop Philosophy I Aim for “reasonably good” performance I Discuss performance tuning techniques common to most HPC architectures I Compiler options I Code modifcation I Focus on serial performance I Reduce time spent accessing memory I Parallel processing I Multithreading I MPI 5/103 Hands-on Code During this workshop, we will be using a code based on the HPCCG miniapp from Mantevo. I Performs Conjugate Gradient (CG) method on a 3D chimney domain. I CG is an iterative algorithm to numerically approximate the solution to a system of linear equations. I Run code with srun -n <numprocs> ./test_HPCCG nx ny nz, where nx, ny, and nz are the number of nodes in the x, y, and z dimension on each processor. I Download with: wget go . osu .edu/perftuning21 t a r x f perftuning21 I Make sure that the following modules are loaded: intel/19.0.5 mvapich2/2.3.3 6/103 More important than Performance! I Correctness of results I Code readability/maintainability I Portability - -

2. Enterprise Architecture 2.4 User Interaction Capabilities
VA Enterprise Design Patterns: 2. Enterprise Architecture 2.4 User Interaction Capabilities Office of Technology Strategies (TS) Architecture, Strategy, and Design (ASD) Office of Information and Technology (OI&T) Version 1.0 Date Issued: October 2015 THIS PAGE INTENTIONALLY LEFT BLANK FOR PRINTING PURPOSES APPROVAL COORDINATION Digitally signed by TIMOTHY L MCGRAIL 111224 TIMOTHY L DN: dc=gov, dc=va, o=internal, ou=people, MCGRAIL 0.9.2342.19200300.100.1.1=tim. [email protected], cn=TIMOTHY L MCGRAIL 111224 Date: 111224 Date: 2015.11.17 08:23:43 -05'00' Tim McGrail Senior Program Analyst ASD Technology Strategies Digitally signed by PAUL A. TIBBITS PAUL A. 116858 DN: dc=gov, dc=va, o=internal, ou=people, TIBBITS 0.9.2342.19200300.100.1.1=paul.tibbits@ va.gov, cn=PAUL A. TIBBITS 116858 Date: Reason: I am approving this document. 116858 Date: 2015.11.30 12:29:02 -05'00' Paul A. Tibbits, M.D. DCIO Architecture, Strategy, and Design REVISION HISTORY Version Date Organization Notes 0.1 2/27/2015 ASD TS Initial Draft Updated draft to reflect additional research and inputs 0.3 5/8/2015 ASD TS from vendor engagements and Stakeholders, with QA provided by TS DP Contractor Team Updated draft to reflect feedback from the Public 0.5 5/22/2015 ASD TS Forum held on 13 May 2015, and QA provided by ASD TS Updated version to align to the latest template for 0.7 10/13/15 ASD TS Enterprise Design Patterns and to account for internal QA review 0.9 REVISION HISTORY APPROVALS Version Date Approver Role 0.1 2/27/2015 Joseph Brooks ASD TS Design Pattern Government Lead 0.3 5/8/2015 Joseph Brooks ASD TS Design Pattern Government Lead 0.5 5/22/2015 Joseph Brooks ASD TS Design Pattern Government Lead 0.7 10/13/15 Joseph Brooks ASD TS Design Pattern Government Lead 1.0 11/17/15 Tim McGrail ASD TS Design Pattern Final Review TABLE OF CONTENTS 1.0 INTRODUCTION ........................................................................................................................................ -

The Power of Interoperability: Why Objects Are Inevitable
The Power of Interoperability: Why Objects Are Inevitable Jonathan Aldrich Carnegie Mellon University Pittsburgh, PA, USA [email protected] Abstract 1. Introduction Three years ago in this venue, Cook argued that in Object-oriented programming has been highly suc- their essence, objects are what Reynolds called proce- cessful in practice, and has arguably become the dom- dural data structures. His observation raises a natural inant programming paradigm for writing applications question: if procedural data structures are the essence software in industry. This success can be documented of objects, has this contributed to the empirical success in many ways. For example, of the top ten program- of objects, and if so, how? ming languages at the LangPop.com index, six are pri- This essay attempts to answer that question. After marily object-oriented, and an additional two (PHP reviewing Cook’s definition, I propose the term ser- and Perl) have object-oriented features.1 The equiva- vice abstractions to capture the essential nature of ob- lent numbers for the top ten languages in the TIOBE in- jects. This terminology emphasizes, following Kay, that dex are six and three.2 SourceForge’s most popular lan- objects are not primarily about representing and ma- guages are Java and C++;3 GitHub’s are JavaScript and nipulating data, but are more about providing ser- Ruby.4 Furthermore, objects’ influence is not limited vices in support of higher-level goals. Using examples to object-oriented languages; Cook [8] argues that Mi- taken from object-oriented frameworks, I illustrate the crosoft’s Component Object Model (COM), which has unique design leverage that service abstractions pro- a C language interface, is “one of the most pure object- vide: the ability to define abstractions that can be ex- oriented programming models yet defined.” Academ- tended, and whose extensions are interoperable in a ically, object-oriented programming is a primary focus first-class way. -

SWG1 N153 2010-08-26 Title: Open Source Software Category
SWG1 N153 2010-08-26 Title: Open Source Software Category Date Assigned: 2010-08-26 Source: Japan MB Backward Pointer: None Document Type: Status: This document will be discussed on First OMATF meeting. Open Source Software Category No Software Category No Software 1-1 OS Linux 1 Andoroid 2 Debian 3 Fedora 4 Google Chrome OS 5 openSUSE 6 Ubuntu 7 Vine Linux 1-2 BSD 1 FreeBSD 2 NetBSD 3 OpenBSD 1-3 Other 1 OpenSolaris 2 Symbian OS 2-1 Internet Server WEB 1 Apache HTTP Server 2 Appweb 3 Jetty 4 lighttpd 5 Mongoose 6 Open Web Server 7 TUX Web Server 2-2 SMTP:Simple Mail Transfer Protocol 1 Courier-MTA 2 Postfix 3 qmail 4 sendmail 5 XMail 2-3 POP:Post Office Protocol/IMAP:Internet Message Access Protocol 1 Courier IMAP 2 Cyrus IMAP 3 Dovecot 4 qpopper 2-4 Proxy 1 Squid Cache 2 Delegate 3 Tor 2-5 DNS:Domain Name System 1 BIND 2 djbdns 3 NSD 4 unbound 2-6 DHCP:Dynamic Host Configuration Protocol 1 DHCP 2-7 LDAP:Lightweight Directory Access Protocol 1 Apache Directory Server 2 Fedora Directory Server 3 OpenDS 4 OpenLDAP 2-8 Cooperation with Windows 1 Samba 2-9 FTP:File Transfer Protocol 1 FileZilla 2 ProFTPD 3 publicfile 4 Pure-FTPd 5 vsftpd 6 WU-FTPD 7 zFTPServer 3-1Application Server Java Platform, Enterprise Edition Server 1 Apache Geronimo 2 Apache Tomcat 3 Enhydra Server 4 GlassFish 5 JBoss Application Server 6 JOnAS 7 Seasar2 3-2 Other Java Platform, Enterprise Edition Server 1 Seasar2 2 Zope 3-3 Execution Environment 1 GCC 2 OpenJDK 3-4 Script 1 Perl 2 PHP 3 Python 4 Ruby 4-1Database DBMS: DataBase Management System 1 Apache Derby 2 Firebird -

AVR Simulator
AVR Simulator Ryan Moore - Colorado State University February 8, 2011 1 Overview The AVR Simulator is designed to simulate the minimal number of instructions that is required to program the MeggyJr RGB device. The simulator can either run in a batch mode, where the assembly program will run to completion or till a system imposed hop count occurs, or in a gui mode where there is visualization for the stack, heap, registers and program space (there is a planned update to include a visualization of the actual device with button presses). The simulator is entirely written in Java and uses several open source api's. The simulator is distributed as an executable jar and does not require any other les/libraries in order to run. Using the Simulator In order to use the simulator you must invoke the java jvm with the jar option: java -jar MJSIM.jar This will invoke the java jvm and execute the simulator in gui mode. The default behavior is to load the gui, and then a user can open an assembly le within the application, and then step through, or run, the assembly program. The default behavior can be modied with dierent command line options. The most important of these is the batch mode option and the le option. To invoke the simulator in batch mode add the -b option after MJSIM.jar: java -jar MJSIM.jar -b This command will invoke the simulator in batch mode. This however will not run. When executing the simulator in batch mode a le is required as well. -

Performance Tuning Workshop
Performance Tuning Workshop Samuel Khuvis Scientific Applications Engineer, OSC 1/89 Workshop Set up I Workshop – set up account at my.osc.edu I If you already have an OSC account, sign in to my.osc.edu I Go to Project I Project access request I PROJECT CODE = PZS0724 I Slides are on event page: osc.edu/events I Workshop website: https://www.osc.edu/˜skhuvis/opt19 2/89 Outline I Introduction I Debugging I Hardware overview I Performance measurement and analysis I Help from the compiler I Code tuning/optimization I Parallel computing 3/89 Introduction 4/89 Workshop Philosophy I Aim for “reasonably good” performance I Discuss performance tuning techniques common to most HPC architectures I Compiler options I Code modification I Focus on serial performance I Reduce time spent accessing memory I Parallel processing I Multithreading I MPI 5/89 Hands-on Code During this workshop, we will be using a code based on the HPCCG miniapp from Mantevo. I Performs Conjugate Gradient (CG) method on a 3D chimney domain. I CG is an iterative algorithm to numerically approximate the solution to a system of linear equations. I Run code with mpiexec -np <numprocs> ./test HPCCG nx ny nz, where nx, ny, and nz are the number of nodes in the x, y, and z dimension on each processor. I Download with git clone [email protected]:khuvis.1/performance2019 handson.git I Make sure that the following modules are loaded: intel/18.0.3 mvapich2/2.3 6/89 More important than Performance! I Correctness of results I Code readability/maintainability I Portability - future systems -

Best Practice Guide Modern Processors
Best Practice Guide Modern Processors Ole Widar Saastad, University of Oslo, Norway Kristina Kapanova, NCSA, Bulgaria Stoyan Markov, NCSA, Bulgaria Cristian Morales, BSC, Spain Anastasiia Shamakina, HLRS, Germany Nick Johnson, EPCC, United Kingdom Ezhilmathi Krishnasamy, University of Luxembourg, Luxembourg Sebastien Varrette, University of Luxembourg, Luxembourg Hayk Shoukourian (Editor), LRZ, Germany Updated 5-5-2021 1 Best Practice Guide Modern Processors Table of Contents 1. Introduction .............................................................................................................................. 4 2. ARM Processors ....................................................................................................................... 6 2.1. Architecture ................................................................................................................... 6 2.1.1. Kunpeng 920 ....................................................................................................... 6 2.1.2. ThunderX2 .......................................................................................................... 7 2.1.3. NUMA architecture .............................................................................................. 9 2.2. Programming Environment ............................................................................................... 9 2.2.1. Compilers ........................................................................................................... 9 2.2.2. Vendor performance libraries