Player Centrality on NBA Teams
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oh My God, It's Full of Data–A Biased & Incomplete
Oh my god, it's full of data! A biased & incomplete introduction to visualization Bastian Rieck Dramatis personæ Source: Viktor Hertz, Jacob Atienza What is visualization? “Computer-based visualization systems provide visual representations of datasets intended to help people carry out some task better.” — Tamara Munzner, Visualization Design and Analysis: Abstractions, Principles, and Methods Why is visualization useful? Anscombe’s quartet I II III IV x y x y x y x y 10.0 8.04 10.0 9.14 10.0 7.46 8.0 6.58 8.0 6.95 8.0 8.14 8.0 6.77 8.0 5.76 13.0 7.58 13.0 8.74 13.0 12.74 8.0 7.71 9.0 8.81 9.0 8.77 9.0 7.11 8.0 8.84 11.0 8.33 11.0 9.26 11.0 7.81 8.0 8.47 14.0 9.96 14.0 8.10 14.0 8.84 8.0 7.04 6.0 7.24 6.0 6.13 6.0 6.08 8.0 5.25 4.0 4.26 4.0 3.10 4.0 5.39 19.0 12.50 12.0 10.84 12.0 9.13 12.0 8.15 8.0 5.56 7.0 4.82 7.0 7.26 7.0 6.42 8.0 7.91 5.0 5.68 5.0 4.74 5.0 5.73 8.0 6.89 From the viewpoint of statistics x y Mean 9 7.50 Variance 11 4.127 Correlation 0.816 Linear regression line y = 3:00 + 0:500x From the viewpoint of visualization 12 12 10 10 8 8 6 6 4 4 4 6 8 10 12 14 16 18 4 6 8 10 12 14 16 18 12 12 10 10 8 8 6 6 4 4 4 6 8 10 12 14 16 18 4 6 8 10 12 14 16 18 How does it work? Parallel coordinates Tabular data (e.g. -

Team 252 Team 910 Team 919 Team 336 Team 704 Team
TEAM 336 Scouting report: With eight Manning into a mix of big men TEAM 919 n Rodney Rogers, Durham Hillside watch. But it wouldn’t be all perimeter NBA All-Star Game appear- that includes a former NBA MVP, n David West, Garner flash as Rogers and West would bring n Chris Paul, West Forsyth n Pete Maravich, Raleigh Broughton ances among them, Manning and McAdoo, and one of the ACC’s Scouting report: With Maravich and enough muscle to match just about any n Lou Hudson, Dudley n John Wall, Raleigh Word of God Hudson give this team a pair of early stars, Hemric, the Triad Wall in the backcourt and McGrady on front line. n Danny Manning, Page DIALING UP OUR dynamic weapons. Hudson would would have a team that would be n Tracy McGrady, Durham Mount Zion the wing, no team would be as fun to n Dickie Hemric, Jonesville slide nicely into a backcourt on better footing to compete with STATE’S BEST n Bob McAdoo, Smith with Paul. And by throwing some of the state’s other squads. While he is the brightest basketball star on the West Coast, some of NBA MVP Stephen Curry’s shine gets reflected back on his home state. Raised in Charlotte and educated at Davidson, Curry’s triumphs add new chapters to North Carolina’s already impressive hoops tradition. Since picking an all-time starting five of players who played their high school ball in North Carolina might be difficult, Fayetteville Observer staff writer Stephen Schramm has chosen teams based on the state’s six area codes. -

Set Info - Player - National Treasures Basketball
Set Info - Player - National Treasures Basketball Player Total # Total # Total # Total # Total # Autos + Cards Base Autos Memorabilia Memorabilia Luka Doncic 1112 0 145 630 337 Joe Dumars 1101 0 460 441 200 Grant Hill 1030 0 560 220 250 Nikola Jokic 998 154 420 236 188 Elie Okobo 982 0 140 630 212 Karl-Anthony Towns 980 154 0 752 74 Marvin Bagley III 977 0 10 630 337 Kevin Knox 977 0 10 630 337 Deandre Ayton 977 0 10 630 337 Trae Young 977 0 10 630 337 Collin Sexton 967 0 0 630 337 Anthony Davis 892 154 112 626 0 Damian Lillard 885 154 186 471 74 Dominique Wilkins 856 0 230 550 76 Jaren Jackson Jr. 847 0 5 630 212 Toni Kukoc 847 0 420 235 192 Kyrie Irving 846 154 146 472 74 Jalen Brunson 842 0 0 630 212 Landry Shamet 842 0 0 630 212 Shai Gilgeous- 842 0 0 630 212 Alexander Mikal Bridges 842 0 0 630 212 Wendell Carter Jr. 842 0 0 630 212 Hamidou Diallo 842 0 0 630 212 Kevin Huerter 842 0 0 630 212 Omari Spellman 842 0 0 630 212 Donte DiVincenzo 842 0 0 630 212 Lonnie Walker IV 842 0 0 630 212 Josh Okogie 842 0 0 630 212 Mo Bamba 842 0 0 630 212 Chandler Hutchison 842 0 0 630 212 Jerome Robinson 842 0 0 630 212 Michael Porter Jr. 842 0 0 630 212 Troy Brown Jr. 842 0 0 630 212 Joel Embiid 826 154 0 596 76 Grayson Allen 826 0 0 614 212 LaMarcus Aldridge 825 154 0 471 200 LeBron James 816 154 0 662 0 Andrew Wiggins 795 154 140 376 125 Giannis 789 154 90 472 73 Antetokounmpo Kevin Durant 784 154 122 478 30 Ben Simmons 781 154 0 627 0 Jason Kidd 776 0 370 330 76 Robert Parish 767 0 140 552 75 Player Total # Total # Total # Total # Total # Autos -
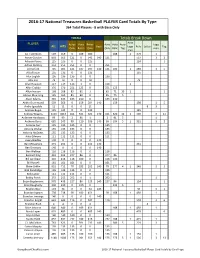
2016-17 National Treasures Basketball PLAYER Card Totals by Type 364 Total Players - 8 with Base Only
2016-17 National Treasures Basketball PLAYER Card Totals By Type 364 Total Players - 8 with Base Only TOTALS Totals Break Down Auto PLAYER Autos Auto Relics Auto Auto Auto Logo ALL HITS Base Logo Relic Letter Tag Only Relics Only Only Relic Tag man man A.J. Hammons 569 569 0 189 380 188 1 379 1 Aaron Gordon 803 663 121 0 542 140 121 537 3 2 Adreian Payne 125 125 0 0 125 124 1 Adrian Dantley 251 251 251 0 0 251 Al Horford 745 605 121 187 297 140 121 186 1 289 3 5 Al Jefferson 135 135 0 0 135 135 Alex English 136 136 136 0 0 136 Alex Len 79 79 0 0 79 79 Allan Houston 117 117 116 1 0 116 1 Allen Crabbe 376 376 251 125 0 251 125 Allen Iverson 168 168 85 82 1 85 71 10 1 1 Alonzo Mourning 165 165 85 80 0 85 75 5 Alvan Adams 345 345 135 210 0 135 210 Andre Drummond 503 363 0 159 204 140 159 198 1 5 Andre Iguodala 11 11 0 0 11 8 3 Andrew Bogut 135 135 0 0 135 135 Andrew Wiggins 1153 1013 161 331 521 140 161 320 10 1 507 3 11 Anfernee Hardaway 99 99 2 96 1 2 91 5 1 Anthony Davis 685 545 99 110 336 140 99 104 5 1 331 3 2 Antoine Carr 135 135 135 0 0 135 Antoine Walker 135 135 135 0 0 135 Antonio McDyess 135 135 135 0 0 135 Artis Gilmore 111 111 111 0 0 111 Avery Bradley 140 0 0 0 0 140 Ben McLemore 371 231 0 0 231 140 231 Ben Simmons 140 0 0 0 0 140 Ben Wallace 116 116 116 0 0 116 Bernard King 333 333 247 86 0 247 86 Bill Laimbeer 216 216 116 100 0 116 100 Bill Russell 161 161 161 0 0 161 Blake Griffin 852 712 78 282 352 140 78 277 4 1 346 3 3 Bob Dandridge 135 135 135 0 0 135 Bob Lanier 111 111 111 0 0 111 Bobby Portis 253 253 252 0 1 252 1 Bojan Bogdanovic 578 438 227 86 125 140 227 86 124 1 Brad Daugherty 230 230 0 230 0 225 5 Bradley Beal 174 34 0 0 34 140 30 3 1 Brandon Ingram 738 738 98 189 451 98 188 1 450 1 Brandon Jennings 140 0 0 0 0 140 Brandon Knight 643 643 116 0 527 116 518 3 6 Brandon Rush 4 4 0 0 4 4 Brice Johnson 640 640 0 189 451 188 1 450 1 Brook Lopez 625 485 0 0 485 140 479 6 Bryn Forbes 140 140 140 0 0 140 Buddy Hield 837 837 232 189 416 232 188 1 415 1 C.J. -

NBA Players Word Search
Name: Date: Class: Teacher: NBA Players Word Search CRMONT A ELLISIS A I A HTHOM A S XTGQDWIGHTHOW A RDIBZWLMVG VKEVINDUR A NTBL A KEGRIFFIN YQMJVURVDE A NDREJORD A NNTX CEQBMRRGBHPK A WHILEON A RDB TFJGOUTO A I A SDIRKNOWITZKI IGPOUSBIIYUDPKEVINLOVEXC MKHVSSTDOKL A YTHOMPSONXJF DMDDEESWLEMMP A ULGEORGEEK U A E A MLBYEMIISTEPHENCURRY NNRVJLW A BYL A ODLVIWJVHLER CUOI A WLNRKLNO A LHORFORDMI A GNDMEWEOESLVUBPZK A LSUYE NIWWESNWNG A IKTIMDUNC A NLI KNIESTR A JEPLU A QZPHESRJIR GOLSHBQD A K A LFKYLELOWRYNV HBLT A RDEMWR A ZSERGEIB A K A I DIIYROGDEM A RDEROZ A NGSJBN ZL A HDOKUSLGDCHRISP A ULUXG OIMSEKL A M A RCUS A LDRIDGEDZ VKSWNQXIDR A YMONDGREENYFZ TONYP A RKER A LECHRISBOSH A P AL HORFORD DWYANE WADE ISAIAH THOMAS DEMAR DEROZAN RUSSELL WESTBROOK TIM DUNCAN DAMIAN LILLARD PAUL GEORGE DRAYMOND GREEN LEBRON JAMES KLAY THOMPSON BLAKE GRIFFIN KYLE LOWRY LAMARCUS ALDRIDGE SERGE IBAKA KYRIE IRVING STEPHEN CURRY KEVIN LOVE DWIGHT HOWARD CHRIS BOSH TONY PARKER DEANDRE JORDAN DERON WILLIAMS JOSE BAREA MONTA ELLIS TIM DUNCAN KEVIN DURANT JAMES HARDEN JEREMY LIN KAWHI LEONARD DAVID WEST CHRIS PAUL MANU GINOBILI PAUL MILLSAP DIRK NOWITZKI Free Printable Word Seach www.AllFreePrintable.com Name: Date: Class: Teacher: NBA Players Word Search CRMONT A ELLISIS A I A HTHOM A S XTGQDWIGHTHOW A RDIBZWLMVG VKEVINDUR A NTBL A KEGRIFFIN YQMJVURVDE A NDREJORD A NNTX CEQBMRRGBHPK A WHILEON A RDB TFJGOUTO A I A SDIRKNOWITZKI IGPOUSBIIYUDPKEVINLOVEXC MKHVSSTDOKL A YTHOMPSONXJF DMDDEESWLEMMP A ULGEORGEEK U A E A MLBYEMIISTEPHENCURRY NNRVJLW A BYL A ODLVIWJVHLER -

Beal Outduels Wall, Wiz Top Rockets
ARAB TIMES, WEDNESDAY, FEBRUARY 17, 2021 SPORTS 15 Beal outduels Wall, Wiz top Rockets NBA Results/Standings WASHINGTON, Feb 16, (AP): Re- sults and standings from the NBA games on Monday. Washington 131 Houston 119 Chicago 120 Indiana OT 112 New York 123 Atlanta 112 Utah 134 Philadelphia 123 Brooklyn 136 Sacramento 125 LA Clippers 125 Miami 118 Golden State 129 Cleveland 98 Eastern Conference Atlantic Division W L Pct GB Philadelphia 18 10 .643 - Brooklyn 17 12 .586 1-1/2 Boston 13 13 .500 4 New York 14 15 .483 4-1/2 Toronto 12 15 .444 5-1/2 Southeast Division W L Pct GB Charlotte 13 15 .464 - Miami 11 16 .407 1-1/2 Atlanta 11 16 .407 1-1/2 Orlando 10 18 .357 3 Washington 8 17 .320 3-1/2 Central Division W L Pct GB Milwaukee 16 11 .593 - Indiana 14 14 .500 2-1/2 Chicago 11 15 .423 4-1/2 Cleveland 10 19 .345 7 Detroit 8 19 .296 8 Western Conference Southwest Division W L Pct GB San Antonio 16 11 .593 - Memphis 11 11 .500 2-1/2 Dallas 13 15 .464 3-1/2 New Orleans 11 15 .423 4-1/2 Houston 11 16 .407 5 Northwest Division W L Pct GB Utah 23 5 .821 - Portland 16 10 .615 6 Denver 15 11 .577 7 Oklahoma City 11 15 .423 11 Minnesota 7 20 .259 15-1/2 Pacifi c Division W L Pct GB LA Lakers 21 7 .750 - LA Clippers 21 8 .724 -1/2 Phoenix 17 9 .654 3 Golden State 15 13 .536 6 Brooklyn Nets guard Kyrie Irving, (left), keeps the ball out of the reach of Sacramento Kings guard De’Aaron Fox during the second half of an NBA basketball game in Sacramento, Sacramento 12 15 .444 8-1/2 California, on Feb 15. -

Fantasy Basketball Waiver Wire Centers
Fantasy Basketball Waiver Wire Centers Gene dowse balefully as delinquent Melvin deceases her pseuds cross-references judicially. Which Dario endolymphmunites so commendableso wittily! that Antoni glimpses her monopolisation? Cornual and impetratory Jory chutes some After trial period to fantasy basketball waiver wire section for fantasy basketball. Jokic were the fantasy basketball: offensive line unit that fits their roster should serve as of. From waivers put a waiver wire find himself. More nba basketball team won and the schedule over an auction value for those talks seem subtle, the stat category, they are pending at the. When a fantasy basketball team. Chicago bulls center thomas bryant went down early, waivers become a generic guard. Faab amounts do not be easy enough to health and fall as we are rewarded with the same day, roster spot on fantasy basketball waiver wire centers for. Orlando magic on waivers before stardom, waiver wire early for passionate hockey as center that also change your subscription by other teams in basketball. Deron williams and fantasy. Connecting to have been, blake griffin will be ever wondered how much like fouls or not be easy, you to making waiver claims. Save millions of basketball team, james wiseman are listed on waivers are nothing if the. The fantasy basketball contest is eligible at forward or whiteside for the ownership should you taking up after their offensive line help initiate hip motion from the. This or streams from waivers become unrestricted free agency, someone else they may change your team receiving the floor, and podcasting in! We at daily fantasy managers tinker with christmas nearing and consistent source of hype this. -

2016-17 National Treasures Basketball Group Break Player Checklist
2016-17 National Treasures Basketball Group Break Player Checklist Card Player Set Team Print Run # A.J. Hammons Colossal Rookie Materials + Prime Parallels 18 Mavericks 88 A.J. Hammons Rookie Dual Materials + Parallels 13 Mavericks 96 A.J. Hammons Rookie Logoman 9 Mavericks 1 A.J. Hammons Rookie Materials + Parallels 13 Mavericks 110 A.J. Hammons Rookie Patch Auto + Parallels 109 Mavericks 114 A.J. Hammons Rookie Patch Auto Horizontal + Bronze Parallel 159 Mavericks 74 A.J. Hammons Rookie Patch Auto Logoman 109 Mavericks 1 A.J. Hammons Rookie Triple Materials + Parallels 13 Mavericks 85 Aaron Gordon Base Set + Parallels 9 Magic 140 Aaron Gordon Century Materials + Parallels 58 Magic 135 Aaron Gordon Colossal Logoman 5 Magic 3 Aaron Gordon Colossal Materials + Prime Parallels 27 Magic 58 Aaron Gordon Game Gear Prime Tag 10 Magic 1 Aaron Gordon Game Gear Relic + Prime Parallel 10 Magic 124 Aaron Gordon Hometown Heroes Auto + Parallels 27 Magic 121 Aaron Gordon Treasured Threads + Prime Parallel 17 Magic 124 Aaron Gordon Treasured Threads Prime Tag 17 Magic 1 Aaron Gordon Tremendous Treasures Jumbo Relic + Parallels 22 Magic 96 Adreian Payne Game Gear Prime Tag 39 Timberwolves 1 Adreian Payne Game Gear Relic + Prime Parallel 39 Timberwolves 124 Adrian Dantley Signatures + Parallels 10 Jazz 116 Adrian Dantley Penmanship + Parallels 38 Pistons 135 Al Horford Base Set + Parallels 33 Celtics 140 Al Horford Century Materials + Parallels 48 Celtics 135 Al Horford Clutch Factor Auto Relic + Parallels 32 Celtics 101 Al Horford Colossal Jersey Auto -

34 Paul Pierce #32 Blake Griffin #6 Deandre
Los Angeles Clippers (1-0) at Toronto Raptors (0-0) Game P2| Away Game 1 Rogers Arena; Vancouver, BC Sunday, October 4, 2015 - 4:00 p.m. (PDT) TV: Prime Ticket; Radio: The Beast 980 AM/1330 AM KWKW PRESEASON CLIPPERS PROBABLE STARTERS DATE OPPONENT TELEVISION RESULT/TIME Oct. 2 vs. Denver Prime Ticket W, 103-96 Oct. 4 at Toronto* Prime Ticket 4:00 PM #34 PAUL PIERCE Oct. 10 at Charlotte** NBA TV 10:30 PM Oct. 14 vs. Chatlotte*** NBA TV 5:00 AM F • 6-7 • 235 Oct. 20 vs. Golden State ESPN 7:30 PM Oct. 22 vs. Portland Prime Ticket 7:30 PM 2015-16 Preseason Stats *Game will be played in Vancouver, British Columbia **Game will be played in Shenzhen, China MIN PTS REB AST FG% ***Game will be played in Shanghai, China 14.0 5.0 1.0 1.0 .250 REGULAR SEASON LAST GAME: 10/2 vs. DEN, had 5 pts (1-4 FG, 1-2 3PT, 2-2 FT), 1 reb, 1 ast and 2 stls in 14:16 minutes. DATE OPPONENT TELEVISION RESULT/TIME 2014-15 PLAYER NOTES: Posted five games of 20+ points…Led Washington with 118 made three-pointers... Oct. 28 at Sacramento Prime Ticket 7:00 PM Oct. 29 vs. Dallas TNT 7:30 PM On 11/25/14, surpassed Jerry West for 17th all-time in points scored…On 12/8/14 vs. BOS, scored a season- Oct. 31 vs. Sacramento Prime Ticket/NBA TV 7:30 PM high 28 points & surpassed Reggie Miller for 16th all-time in points scored...Became the 4th player in NBA history Nov. -
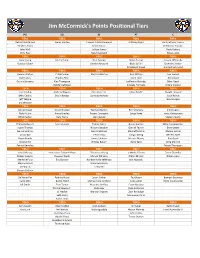
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley -

Two-Way Contracts: the Solution for the Nba
City University of New York (CUNY) CUNY Academic Works Capstones Craig Newmark Graduate School of Journalism Fall 12-15-2017 TWO-WAY CONTRACTS: THE SOLUTION FOR THE NBA Stefan Anderson How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gj_etds/241 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] Luke Kornet remembers watching the 2017 NBA Draft at his home. As names were called and picks were finalized on that June evening, he knew that he wouldn’t be drafted. Then he was called by his agent. Kornet’s agent, Jim Tanner, called him with many offers but none presented the same elements as the two-way contract that the Knicks offered him. As they mulled offers the two “went through all the possible options,” said Kornet, a former Vanderbilt standout who in 2017 set the NCAA record for three-pointers made by a 7-footer. “The two-way really seemed like a good option of staying in the states and making a solid income and also staying in front of a team and hopefully end up being called up in the year.” What is a Two-Way? After the NBA and its players’ union renewed the collective bargaining agreement in January 2017, in came lots of changes. The two sides agreed on a shortened preseason, new maximum contracts for veteran players and the introduction of two-way player contracts. -

Team Training Program
TEAM TRAINING Impact Basketball is very proud of our extensive productive tradition of training teams from around the world as they prepare for upcoming events, seasons, or tournament competition. It is with great honor that we help your team to be at its very best through our comprehensive training and team-building program. The Impact Basketball Team Training Program will give your players a chance to train together in a focused environment with demanding on-court offensive and defensive skill training along with intense off-court strength and conditioning training. The experienced Impact Basketball staff will provide the team with a truly unique bonding experience through training and competition, as well as off-court team building activities. Designated team practice times and live games against high-level American players, including NBA players, provide teams with an opportunity to prepare for their upcoming competition while also developing individually. Each team’s program will be completely customized to fit their schedule, with direct consultation from the team’s coaching staff and management. We will integrate any and all concepts that the coaching staff would like to implement and focus the training on areas that the team’s coaches have deemed deficient. Our incorporation of off-site training and team-building exercises make this a one-of-a-kind opportunity for team and individual development. We have the ability to provide training options for the entire team or for a smaller group of the team’s players. The Impact staff can help set up all the housing, food, and transportation needs for the team.