Stochastic Calculus for Finance II: Continuous-Time Models Solution of Exercise Problems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Official Colours of Chinese Regimes: a Panchronic Philological Study with Historical Accounts of China
TRAMES, 2012, 16(66/61), 3, 237–285 OFFICIAL COLOURS OF CHINESE REGIMES: A PANCHRONIC PHILOLOGICAL STUDY WITH HISTORICAL ACCOUNTS OF CHINA Jingyi Gao Institute of the Estonian Language, University of Tartu, and Tallinn University Abstract. The paper reports a panchronic philological study on the official colours of Chinese regimes. The historical accounts of the Chinese regimes are introduced. The official colours are summarised with philological references of archaic texts. Remarkably, it has been suggested that the official colours of the most ancient regimes should be the three primitive colours: (1) white-yellow, (2) black-grue yellow, and (3) red-yellow, instead of the simple colours. There were inconsistent historical records on the official colours of the most ancient regimes because the composite colour categories had been split. It has solved the historical problem with the linguistic theory of composite colour categories. Besides, it is concluded how the official colours were determined: At first, the official colour might be naturally determined according to the substance of the ruling population. There might be three groups of people in the Far East. (1) The developed hunter gatherers with livestock preferred the white-yellow colour of milk. (2) The farmers preferred the red-yellow colour of sun and fire. (3) The herders preferred the black-grue-yellow colour of water bodies. Later, after the Han-Chinese consolidation, the official colour could be politically determined according to the main property of the five elements in Sino-metaphysics. The red colour has been predominate in China for many reasons. Keywords: colour symbolism, official colours, national colours, five elements, philology, Chinese history, Chinese language, etymology, basic colour terms DOI: 10.3176/tr.2012.3.03 1. -

Ideophones in Middle Chinese
KU LEUVEN FACULTY OF ARTS BLIJDE INKOMSTSTRAAT 21 BOX 3301 3000 LEUVEN, BELGIË ! Ideophones in Middle Chinese: A Typological Study of a Tang Dynasty Poetic Corpus Thomas'Van'Hoey' ' Presented(in(fulfilment(of(the(requirements(for(the(degree(of(( Master(of(Arts(in(Linguistics( ( Supervisor:(prof.(dr.(Jean=Christophe(Verstraete((promotor)( ( ( Academic(year(2014=2015 149(431(characters Abstract (English) Ideophones in Middle Chinese: A Typological Study of a Tang Dynasty Poetic Corpus Thomas Van Hoey This M.A. thesis investigates ideophones in Tang dynasty (618-907 AD) Middle Chinese (Sinitic, Sino- Tibetan) from a typological perspective. Ideophones are defined as a set of words that are phonologically and morphologically marked and depict some form of sensory image (Dingemanse 2011b). Middle Chinese has a large body of ideophones, whose domains range from the depiction of sound, movement, visual and other external senses to the depiction of internal senses (cf. Dingemanse 2012a). There is some work on modern variants of Sinitic languages (cf. Mok 2001; Bodomo 2006; de Sousa 2008; de Sousa 2011; Meng 2012; Wu 2014), but so far, there is no encompassing study of ideophones of a stage in the historical development of Sinitic languages. The purpose of this study is to develop a descriptive model for ideophones in Middle Chinese, which is compatible with what we know about them cross-linguistically. The main research question of this study is “what are the phonological, morphological, semantic and syntactic features of ideophones in Middle Chinese?” This question is studied in terms of three parameters, viz. the parameters of form, of meaning and of use. -

2020 Annual Report
2020 ANNUAL REPORT About IHV The Institute of Human Virology (IHV) is the first center in the United States—perhaps the world— to combine the disciplines of basic science, epidemiology and clinical research in a concerted effort to speed the discovery of diagnostics and therapeutics for a wide variety of chronic and deadly viral and immune disorders—most notably HIV, the cause of AIDS. Formed in 1996 as a partnership between the State of Maryland, the City of Baltimore, the University System of Maryland and the University of Maryland Medical System, IHV is an institute of the University of Maryland School of Medicine and is home to some of the most globally-recognized and world- renowned experts in the field of human virology. IHV was co-founded by Robert Gallo, MD, director of the of the IHV, William Blattner, MD, retired since 2016 and formerly associate director of the IHV and director of IHV’s Division of Epidemiology and Prevention and Robert Redfield, MD, resigned in March 2018 to become director of the U.S. Centers for Disease Control and Prevention (CDC) and formerly associate director of the IHV and director of IHV’s Division of Clinical Care and Research. In addition to the two Divisions mentioned, IHV is also comprised of the Infectious Agents and Cancer Division, Vaccine Research Division, Immunotherapy Division, a Center for International Health, Education & Biosecurity, and four Scientific Core Facilities. The Institute, with its various laboratory and patient care facilities, is uniquely housed in a 250,000-square-foot building located in the center of Baltimore and our nation’s HIV/AIDS pandemic. -

Women Lai Jiang Zhongwen! Æ‹‚Ä»¬Æš¥È®²Ä¸Łæœ
SUNY Geneseo KnightScholar Geneseo Authors Milne Library Publishing 1-1-2013 WOMEN LAI JIANG ZHONGWEN! 我们来 讲中文!Let’s Speak Chinese! Jasmine Kong-Yan Tang SUNY Geneseo Follow this and additional works at: https://knightscholar.geneseo.edu/geneseo-authors Recommended Citation Tang, Jasmine Kong-Yan, "WOMEN LAI JIANG ZHONGWEN! 我们来讲中文!Let’s Speak Chinese!" (2013). Geneseo Authors. 7. https://knightscholar.geneseo.edu/geneseo-authors/7 This Book is brought to you for free and open access by the Milne Library Publishing at KnightScholar. It has been accepted for inclusion in Geneseo Authors by an authorized administrator of KnightScholar. For more information, please contact [email protected]. WOMEN LAI JIANG ZHONGWEN! 我们来讲中文! Authors LET’S SPEAK CHINESE! 李公燕 by JASMINE KONG-YAN TANG WOMEN LAI JIANG ZHONGWEN! 我们来讲中文! LET’S SPEAK CHINESE! 李公燕 By JASMINE KONG-YAN TANG ©2013 Jasmine Kong-Yan Tang Published by Milne Library, State University of New York at Geneseo, Geneseo, NY 14454 Cover photographs by Jasmine Kong-Yan Tang Cover and book design by Allison P. Brown Sound recordings produced by Steve Dresbach, read by Jasmine Kong-Yan Tang and Steve Dresbach. About this Textbook This book is for those with experience learning Mandarin but who need confidence interacting in everyday situations. What distinguishes Let’s Speak Chinese! from other language acquisition guides is the emphasis on practical usage and the promotion of self-learning. To speak the language with ease, one needs to find the courage to simply ask for what you want in order to receive what you seek. Once you are able to do so, then vocabulary, grammar rules, and intonation will flow more smoothly in your speech. -

East Asian Science, Technology, and Medicine (EASTM - Universität Tübingen)
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by East Asian Science, Technology, and Medicine (EASTM - Universität Tübingen) EASTM 42 (2015): 39-71 The Experience of Illness in Early Twentieth-century Rural Shanxi Henrietta Harrison [Henrietta Harrison is professor of modern Chinese studies at Oxford University. She received her doctorate from Oxford University in 1996 and subsequently taught at Leeds and Harvard universities. She works mainly on the history of central Shanxi and has published a biography of Liu Dapeng (The Man Awakened from Dreams: One Man’s Life in a North China Village 1857- 1942, 2005) as well as a history of a Catholic village in the same area (The Missionary’s Curse and Other Tales from a Chinese Catholic Village, 2013). Contact: [email protected]] * * * Abstract: This paper uses the diary and other records of Liu Dapeng 劉大鵬 (1857-1942), a Shanxi village resident, to examine how people in rural China experienced and understood illness at an important time of transition for medical systems in China. It explains how Liu understood the illnesses that afflicted himself and members of his family in terms of providence. The healing methods he used ranged through self-medication with folk remedies and modern patent medicines; remedies provided by families friends and neighbours (including acupuncture and prescriptions based on classical Chinese medicine); remedies provided by gods and shamans; and prescriptions provided by professional doctors of Chinese medicine, whom Liu deeply distrusted. It also examines the arrival of Western medicine in Shanxi and argues that while this existed it was incorporated into networks of medicine provided by family and friends, rather than functioning as a separate institutional system. -

Using Online Applications to Improve Tone Perception Among L2 Learners of Chinese (网络应用对中文二语学习者声调辨识的有效性研究)
Journal of Technology and Chinese Language Teaching Volume 10 Number 1, June 2019 http://www.tclt.us/journal/2019v10n1/xulili.pdf pp. 26-56 Using Online Applications to Improve Tone Perception among L2 Learners of Chinese (网络应用对中文二语学习者声调辨识的有效性研究) Xu, Hongying Li, Yan Li, Yingjie (徐红英) (李艳) (李颖颉) University of University of University of Colorado- Wisconsin-La Crosse Kansas Boulder (威斯康星大学拉克 (堪萨斯大学) (科罗拉多大学博尔得分 罗校区) [email protected] 校) [email protected] [email protected] Abstract: This study investigated the effectiveness of an online application in helping beginning-level Chinese learners improve their perception of the tones in Mandarin Chinese. Two groups—one experimental and one traditional—of beginning Chinese learners from two universities in the Midwest participated in this study. The experimental group (n=20) used the online application to practice tones for four 15-minute sessions in class. The traditional group (n=11) participated in traditional instructor-led practice in class in lieu of the online practice. Both groups completed a pre-test, an immediately administered post-test, and a delayed post-test designed to assess their perception of the tones of monosyllabic and disyllabic words. No statistically significant difference has been found between the two groups in their tone perception performance in the post-test and in the delayed post-test. However, the experimental group showed a positive trend in improving their perception on those tones which posed more difficulty than others. Their experience with this online application and the pronunciation learning strategies of participants in the experimental group were also examined through a survey. Based on the findings, it is proposed that the use of online tone practice is worthwhile in a Chinese language class, but might fit better into the curriculum as external assignments. -

The Saxophone in China: Historical Performance and Development
THE SAXOPHONE IN CHINA: HISTORICAL PERFORMANCE AND DEVELOPMENT Jason Pockrus Dissertation Prepared for the Degree of DOCTOR OF MUSICAL ARTS UNIVERSITY OF NORTH TEXAS August 201 8 APPROVED: Eric M. Nestler, Major Professor Catherine Ragland, Committee Member John C. Scott, Committee Member John Holt, Chair of the Division of Instrumental Studies Benjamin Brand, Director of Graduate Studies in the College of Music John W. Richmond, Dean of the College of Music Victor Prybutok, Dean of the Toulouse Graduate School Pockrus, Jason. The Saxophone in China: Historical Performance and Development. Doctor of Musical Arts (Performance), August 2018, 222 pp., 12 figures, 1 appendix, bibliography, 419 titles. The purpose of this document is to chronicle and describe the historical developments of saxophone performance in mainland China. Arguing against other published research, this document presents proof of the uninterrupted, large-scale use of the saxophone from its first introduction into Shanghai’s nineteenth century amateur musical societies, continuously through to present day. In order to better describe the performance scene for saxophonists in China, each chapter presents historical and political context. Also described in this document is the changing importance of the saxophone in China’s musical development and musical culture since its introduction in the nineteenth century. The nature of the saxophone as a symbol of modernity, western ideologies, political duality, progress, and freedom and the effects of those realities in the lives of musicians and audiences in China are briefly discussed in each chapter. These topics are included to contribute to a better, more thorough understanding of the performance history of saxophonists, both native and foreign, in China. -

Han Chinese Males with Surnames Related to the Legendary Huang and Yan Emperors Are Enriched for the Top Two Neolithic Super-Gra
bioRxiv preprint doi: https://doi.org/10.1101/077222; this version posted September 30, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Han Chinese males with surnames related to the legendary Huang and Yan Emperors are enriched for the top two Neolithic super-grandfather Y chromosomes O3a2c1a and O3a1c, respectively Pei He, Zhengmao Hu, Zuobin Zhu, Kun Xia, and Shi Huang* State Key Laboratory of Medical Genetics School of life sciences Central South University 110 Xiangya Road Changsha, Hunan, 410078, China *Corresponding author: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/077222; this version posted September 30, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Most populations now use hereditary surnames, and most societies have patrilineal surnames. This naming system is believed to have started almost 5000 years ago in China. According to legends and ancient history books, there were Eight Great Xings of High Antiquity that were the ancestors of most Chinese surnames today and are thought to be descended from the two legendary prehistoric Emperors Yan and Huang. Recent work identified three Neolithic super-grandfathers represented by Y chromosome haplotypes, O3a1c, O3a2c1, and O3a2c1a, which makes it possible to test the tales of Yan-Huang and their descendant surnames. We performed two independent surveys of contemporary Han Chinese males (total number of subjects 2415) and divided the subjects into four groups based on the relationships of their surnames with the Eight Great Xings, Jiang (Yan), Ying (Huang), Ji(Huang), and Others (5 remaining Xings related to Huang). -
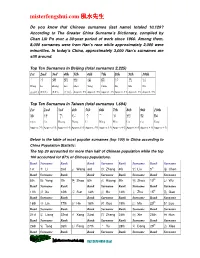
Misterfengshui.Com 風水先生
misterfengshui.com 風水先生 Do you know that Chinese surnames (last name) totaled 10,129? According to The Greater China Surname’s Dictionary, compiled by Chan Lik Pu over a 30-year period of work since 1960. Among them, 8,000 surnames were from Han’s race while approximately 2,000 were minorities. In today’s China, approximately 3,000 Han’s surnames are still around. Top Ten Surnames In Beijing (total surnames 2,225) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 王 李 張 劉 趙 楊 陳 徐 馬 吳 Wang Li Zhang Liu Zhao Yang Chen Xu Ma Wu (10.6% ) (9.6%) (9.6%) (7.7% ) Approx. 5% Approx. 5% Approx. 4% Approx. 4% Approx. 4% Approx. 3% Top Ten Surnames In Taiwan (total surnames 1,694) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 陳 林 黃 張 李 王 吳 劉 蔡 楊 Chen Lin Huang Zhang Li Wang Wux. Liu Cai Yang Approx .7% Approx 6 % Approx 6 % Approx 6 % Approx. 5% Approx 5 % Approx 4 % Approx 4 % Approx 4 % Approx 4 % Below is the table of most popular surnames (top 100) in China according to China Population Statistic: The top 20 accounted for more than half of Chinese population while the top 100 accounted for 87% of Chinese populations. Rank Surname Rank Rank Surname Rank Surname Rank Surname 1st 李 Li 2nd 王 Wang 3rd 張 Zhang 4th 劉 Liu 5th 陳 Chen Rank Surname Rank Rank Surname Rank Surname Rank Surname 6th 楊 Yang 7th 趙 Zhao 8th 黃 Huang 9th 周 Zhou 10 th 吳 Wu Rank Surname Rank Rank Surname Rank Surname Rank Surname 11th 徐 Xu 12th 孫 Sun 13th 胡 Hu 14th 朱 Zhu 15 th 高 Gao Rank Surname Rank Rank Surname Rank Surname Rank Surname 16th 林 Lin 17th 何 He 18th 郭 Guo 19th 馬 Ma 20 th 羅 Luo Rank -

A Hypothesis on the Origin of the Yu State
SINO-PLATONIC PAPERS Number 139 June, 2004 A Hypothesis on the Origin of the Yu State by Taishan Yu Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established, scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin (MSM) and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino- Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out to be refereed, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. We do, however, strongly recommend that prospective authors consult our style guidelines at www.sino-platonic.org/stylesheet.doc. -

Names of Chinese People in Singapore
101 Lodz Papers in Pragmatics 7.1 (2011): 101-133 DOI: 10.2478/v10016-011-0005-6 Lee Cher Leng Department of Chinese Studies, National University of Singapore ETHNOGRAPHY OF SINGAPORE CHINESE NAMES: RACE, RELIGION, AND REPRESENTATION Abstract Singapore Chinese is part of the Chinese Diaspora.This research shows how Singapore Chinese names reflect the Chinese naming tradition of surnames and generation names, as well as Straits Chinese influence. The names also reflect the beliefs and religion of Singapore Chinese. More significantly, a change of identity and representation is reflected in the names of earlier settlers and Singapore Chinese today. This paper aims to show the general naming traditions of Chinese in Singapore as well as a change in ideology and trends due to globalization. Keywords Singapore, Chinese, names, identity, beliefs, globalization. 1. Introduction When parents choose a name for a child, the name necessarily reflects their thoughts and aspirations with regards to the child. These thoughts and aspirations are shaped by the historical, social, cultural or spiritual setting of the time and place they are living in whether or not they are aware of them. Thus, the study of names is an important window through which one could view how these parents prefer their children to be perceived by society at large, according to the identities, roles, values, hierarchies or expectations constructed within a social space. Goodenough explains this culturally driven context of names and naming practices: Department of Chinese Studies, National University of Singapore The Shaw Foundation Building, Block AS7, Level 5 5 Arts Link, Singapore 117570 e-mail: [email protected] 102 Lee Cher Leng Ethnography of Singapore Chinese Names: Race, Religion, and Representation Different naming and address customs necessarily select different things about the self for communication and consequent emphasis. -

YAN LIU: Curriculum Vitae
YAN LIU Curriculum Vitae Krannert School of Management Phone: +1 (919) 428-1118 Purdue University Email: [email protected] West Lafayette, IN 47907 Website: http://www.yliu1.com EDUCATION 2008 - 2014 Ph.D. in Finance, Duke University 2006 - 2008 M.A. in Statistics, University of Minnesota, Twin Cities 2002 - 2006 B.S. in Mathematics, with distinction, Tsinghua University EMPLOYMENT Purdue University 2019 - present Assistant Professor of Finance Texas A&M University 2017 - 2019 RepublicBank Research Fellow 2014 - 2019 Assistant Professor of Finance RESEARCH INTERESTS Asset pricing, Financial econometrics, Macro finance, Hedge funds, Mutual funds, Financial re- porting, Financial institutions, Corporate events, Machine learning [Google Scholar] PUBLICATIONS • \Reconstructing the Yield Curve", with Jing Cynthia Wu, 2020. Forthcoming, Journal of Financial Economics.[Link] - Solicited by Journal of Financial Economics • \Luck versus Skill in the Cross-Section of Mutual Fund Returns: Reexamining the Evidence", with Campbell R. Harvey. 2020. (Conditionally accepted, Journal of Finance) [Link] • \Index Option Returns and Generalized Entropy Bounds", 2020. Forthcoming, Journal of Financial Economics.[Link] • \False (and Missed) Discoveries in Financial Economics", with Campbell R. Harvey, 2020. Forth- coming, Journal of Finance, October 2020. [Link] 1 • \Lucky Factors?", with Campbell R. Harvey, 2020. Forthcoming, Journal of Financial Eco- nomics.[Link] • \An Evaluation of Alternative Multiple Testing Methods for Finance Applications", with Camp- bell R. Harvey and Alessio Saretto, 2020. Forthcoming, Review of Asset Pricing Studies. [Link] - Invited and Refereed • \Cross-Sectional Alpha Dispersion and Performance Evaluation", with Campbell R. Harvey, 2019. Journal of Financial Economics, 134, 273{296. [Link] • \Detecting Repeatable Performance", with Campbell R. Harvey, 2018. Review of Financial Studies, 31, 2499{2552.