Error Variance Estimation in Nonparametric Regression Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Generalized Linear Models and Generalized Additive Models
00:34 Friday 27th February, 2015 Copyright ©Cosma Rohilla Shalizi; do not distribute without permission updates at http://www.stat.cmu.edu/~cshalizi/ADAfaEPoV/ Chapter 13 Generalized Linear Models and Generalized Additive Models [[TODO: Merge GLM/GAM and Logistic Regression chap- 13.1 Generalized Linear Models and Iterative Least Squares ters]] [[ATTN: Keep as separate Logistic regression is a particular instance of a broader kind of model, called a gener- chapter, or merge with logis- alized linear model (GLM). You are familiar, of course, from your regression class tic?]] with the idea of transforming the response variable, what we’ve been calling Y , and then predicting the transformed variable from X . This was not what we did in logis- tic regression. Rather, we transformed the conditional expected value, and made that a linear function of X . This seems odd, because it is odd, but it turns out to be useful. Let’s be specific. Our usual focus in regression modeling has been the condi- tional expectation function, r (x)=E[Y X = x]. In plain linear regression, we try | to approximate r (x) by β0 + x β. In logistic regression, r (x)=E[Y X = x] = · | Pr(Y = 1 X = x), and it is a transformation of r (x) which is linear. The usual nota- tion says | ⌘(x)=β0 + x β (13.1) · r (x) ⌘(x)=log (13.2) 1 r (x) − = g(r (x)) (13.3) defining the logistic link function by g(m)=log m/(1 m). The function ⌘(x) is called the linear predictor. − Now, the first impulse for estimating this model would be to apply the transfor- mation g to the response. -

Stochastic Process - Introduction
Stochastic Process - Introduction • Stochastic processes are processes that proceed randomly in time. • Rather than consider fixed random variables X, Y, etc. or even sequences of i.i.d random variables, we consider sequences X0, X1, X2, …. Where Xt represent some random quantity at time t. • In general, the value Xt might depend on the quantity Xt-1 at time t-1, or even the value Xs for other times s < t. • Example: simple random walk . week 2 1 Stochastic Process - Definition • A stochastic process is a family of time indexed random variables Xt where t belongs to an index set. Formal notation, { t : ∈ ItX } where I is an index set that is a subset of R. • Examples of index sets: 1) I = (-∞, ∞) or I = [0, ∞]. In this case Xt is a continuous time stochastic process. 2) I = {0, ±1, ±2, ….} or I = {0, 1, 2, …}. In this case Xt is a discrete time stochastic process. • We use uppercase letter {Xt } to describe the process. A time series, {xt } is a realization or sample function from a certain process. • We use information from a time series to estimate parameters and properties of process {Xt }. week 2 2 Probability Distribution of a Process • For any stochastic process with index set I, its probability distribution function is uniquely determined by its finite dimensional distributions. •The k dimensional distribution function of a process is defined by FXX x,..., ( 1 x,..., k ) = P( Xt ≤ 1 ,..., xt≤ X k) x t1 tk 1 k for anyt 1 ,..., t k ∈ I and any real numbers x1, …, xk . -

Variance Function Regressions for Studying Inequality
Variance Function Regressions for Studying Inequality The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Western, Bruce and Deirdre Bloome. 2009. Variance function regressions for studying inequality. Working paper, Department of Sociology, Harvard University. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:2645469 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Open Access Policy Articles, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#OAP Variance Function Regressions for Studying Inequality Bruce Western1 Deirdre Bloome Harvard University January 2009 1Department of Sociology, 33 Kirkland Street, Cambridge MA 02138. E-mail: [email protected]. This research was supported by a grant from the Russell Sage Foundation. Abstract Regression-based studies of inequality model only between-group differ- ences, yet often these differences are far exceeded by residual inequality. Residual inequality is usually attributed to measurement error or the in- fluence of unobserved characteristics. We present a regression that in- cludes covariates for both the mean and variance of a dependent variable. In this model, the residual variance is treated as a target for analysis. In analyses of inequality, the residual variance might be interpreted as mea- suring risk or insecurity. Variance function regressions are illustrated in an analysis of panel data on earnings among released prisoners in the Na- tional Longitudinal Survey of Youth. We extend the model to a decomposi- tion analysis, relating the change in inequality to compositional changes in the population and changes in coefficients for the mean and variance. -

Flexible Signal Denoising Via Flexible Empirical Bayes Shrinkage
Journal of Machine Learning Research 22 (2021) 1-28 Submitted 1/19; Revised 9/20; Published 5/21 Flexible Signal Denoising via Flexible Empirical Bayes Shrinkage Zhengrong Xing [email protected] Department of Statistics University of Chicago Chicago, IL 60637, USA Peter Carbonetto [email protected] Research Computing Center and Department of Human Genetics University of Chicago Chicago, IL 60637, USA Matthew Stephens [email protected] Department of Statistics and Department of Human Genetics University of Chicago Chicago, IL 60637, USA Editor: Edo Airoldi Abstract Signal denoising—also known as non-parametric regression—is often performed through shrinkage estima- tion in a transformed (e.g., wavelet) domain; shrinkage in the transformed domain corresponds to smoothing in the original domain. A key question in such applications is how much to shrink, or, equivalently, how much to smooth. Empirical Bayes shrinkage methods provide an attractive solution to this problem; they use the data to estimate a distribution of underlying “effects,” hence automatically select an appropriate amount of shrinkage. However, most existing implementations of empirical Bayes shrinkage are less flexible than they could be—both in their assumptions on the underlying distribution of effects, and in their ability to han- dle heteroskedasticity—which limits their signal denoising applications. Here we address this by adopting a particularly flexible, stable and computationally convenient empirical Bayes shrinkage method and apply- ing it to several signal denoising problems. These applications include smoothing of Poisson data and het- eroskedastic Gaussian data. We show through empirical comparisons that the results are competitive with other methods, including both simple thresholding rules and purpose-built empirical Bayes procedures. -

Variance Function Estimation in Multivariate Nonparametric Regression by T
Variance Function Estimation in Multivariate Nonparametric Regression by T. Tony Cai, Lie Wang University of Pennsylvania Michael Levine Purdue University Technical Report #06-09 Department of Statistics Purdue University West Lafayette, IN USA October 2006 Variance Function Estimation in Multivariate Nonparametric Regression T. Tony Cail, Michael Levine* Lie Wangl October 3, 2006 Abstract Variance function estimation in multivariate nonparametric regression is consid- ered and the minimax rate of convergence is established. Our work uses the approach that generalizes the one used in Munk et al (2005) for the constant variance case. As is the case when the number of dimensions d = 1, and very much contrary to the common practice, it is often not desirable to base the estimator of the variance func- tion on the residuals from an optimal estimator of the mean. Instead it is desirable to use estimators of the mean with minimal bias. Another important conclusion is that the first order difference-based estimator that achieves minimax rate of convergence in one-dimensional case does not do the same in the high dimensional case. Instead, the optimal order of differences depends on the number of dimensions. Keywords: Minimax estimation, nonparametric regression, variance estimation. AMS 2000 Subject Classification: Primary: 62G08, 62G20. Department of Statistics, The Wharton School, University of Pennsylvania, Philadelphia, PA 19104. The research of Tony Cai was supported in part by NSF Grant DMS-0306576. 'Corresponding author. Address: 250 N. University Street, Purdue University, West Lafayette, IN 47907. Email: [email protected]. Phone: 765-496-7571. Fax: 765-494-0558 1 Introduction We consider the multivariate nonparametric regression problem where yi E R, xi E S = [0, Ild C Rd while a, are iid random variables with zero mean and unit variance and have bounded absolute fourth moments: E lail 5 p4 < m. -

Variance Function Program
Variance Function Program Version 15.0 (for Windows XP and later) July 2018 W.A. Sadler 71B Middleton Road Christchurch 8041 New Zealand Ph: +64 3 343 3808 e-mail: [email protected] (formerly at Nuclear Medicine Department, Christchurch Hospital) Contents Page Variance Function Program 15.0 1 Windows Vista through Windows 10 Issues 1 Program Help 1 Gestures 1 Program Structure 2 Data Type 3 Automation 3 Program Data Area 3 User Preferences File 4 Auto-processing File 4 Graph Templates 4 Decimal Separator 4 Screen Settings 4 Scrolling through Summaries and Displays 4 The Variance Function 5 Variance Function Output Examples 8 Variance Stabilisation 11 Histogram, Error and Biological Variation Plots 12 Regression Analysis 13 Limit of Blank (LoB) and Limit of Detection (LoD) 14 Bland-Altman Analysis 14 Appendix A (Program Delivery) 16 Appendix B (Program Installation) 16 Appendix C (Program Removal) 16 Appendix D (Example Data, SD and Regression Files) 16 Appendix E (Auto-processing Example Files) 17 Appendix F (History) 17 Appendix G (Changes: Version 14.0 to Version 15.0) 18 Appendix H (Version 14.0 Bug Fixes) 19 References 20 Variance Function Program 15.0 1 Variance Function Program 15.0 The variance function (the relationship between variance and the mean) has several applications in statistical analysis of medical laboratory data (eg. Ref. 1), but the single most important use is probably the construction of (im)precision profile plots (2). This program (VFP.exe) was initially aimed at immunoassay data which exhibit relatively extreme variance relationships. It was based around the “standard” 3-parameter variance function, 2 J σ = (β1 + β2U) 2 where σ denotes variance, U denotes the mean, and β1, β2 and J are the parameters (3, 4). -

Nonparametric Regression 1 Introduction
Nonparametric Regression 10/36-702 Larry Wasserman 1 Introduction Now we focus on the following problem: Given a sample (X1;Y1);:::,(Xn;Yn), where d Xi 2 R and Yi 2 R, estimate the regression function m(x) = E(Y jX = x) (1) without making parametric assumptions (such as linearity) about the regression function m(x). Estimating m is called nonparametric regression or smoothing. We can write Y = m(X) + where E() = 0. This follows since, = Y − m(X) and E() = E(E(jX)) = E(m(X) − m(X)) = 0 A related problem is nonparametric prediction. Given a pair (X; Y ), we want to predict Y from X. The optimal predictor (under squared error loss) is the regression function m(X). Hence, estimating m is of interest for its own sake and for the purposes of prediction. Example 1 Figure 1 shows data on bone mineral density. The plots show the relative change in bone density over two consecutive visits, for men and women. The smooth estimates of the regression functions suggest that a growth spurt occurs two years earlier for females. In this example, Y is change in bone mineral density and X is age. Example 2 Figure 2 shows an analysis of some diabetes data from Efron, Hastie, Johnstone and Tibshirani (2004). The outcome Y is a measure of disease progression after one year. We consider four covariates (ignoring for now, six other variables): age, bmi (body mass index), and two variables representing blood serum measurements. A nonparametric regression model in this case takes the form Y = m(x1; x2; x3; x4) + . -

Nonparametric Regression with Complex Survey Data
CHAPTER 11 NONPARAMETRIC REGRESSION WITH COMPLEX SURVEY DATA R. L. Chambers Department of Social Statistics University of Southampton A.H. Dorfman Office of Survey Methods Research Bureau of Labor Statistics M.Yu. Sverchkov Department of Statistics Hebrew University of Jerusalem June 2002 11.1 Introduction The problem considered here is one familiar to analysts carrying out exploratory data analysis (EDA) of data obtained via a complex sample survey design. How does one adjust for the effects, if any, induced by the method of sampling used in the survey when applying EDA methods to these data? In particular, are adjustments to standard EDA methods necessary when the analyst's objective is identification of "interesting" population (rather than sample) structures? A variety of methods for adjusting for complex sample design when carrying out parametric inference have been suggested. See, for example, SHS, Pfeffermann (1993) and Breckling et al (1994). However, comparatively little work has been done to date on extending these ideas to EDA, where a parametric formulation of the problem is typically inappropriate. We focus on a popular EDA technique, nonparametric regression or scatterplot smoothing. The literature contains a limited number of applications of this type of analysis to survey data, usually based on some form of sample weighting. The design-based theory set out in chapter 10, with associated references, provides an introduction to this work. See also Chesher (1997). The approach taken here is somewhat different. In particular, it is model-based, building on the sample distribution concept discussed in section 2.3. Here we develop this idea further, using it to motivate a number of methods for adjusting for the effect of a complex sample design when estimating a population regression function. -

Nonparametric Bayesian Inference
Nonparametric Bayesian Methods 1 What is Nonparametric Bayes? In parametric Bayesian inference we have a model M = ff(yjθ): θ 2 Θg and data Y1;:::;Yn ∼ f(yjθ). We put a prior distribution π(θ) on the parameter θ and compute the posterior distribution using Bayes' rule: L (θ)π(θ) π(θjY ) = n (1) m(Y ) Q where Y = (Y1;:::;Yn), Ln(θ) = i f(Yijθ) is the likelihood function and n Z Z Y m(y) = m(y1; : : : ; yn) = f(y1; : : : ; ynjθ)π(θ)dθ = f(yijθ)π(θ)dθ i=1 is the marginal distribution for the data induced by the prior and the model. We call m the induced marginal. The model may be summarized as: θ ∼ π Y1;:::;Ynjθ ∼ f(yjθ): We use the posterior to compute a point estimator such as the posterior mean of θ. We can also summarize the posterior by drawing a large sample θ1; : : : ; θN from the posterior π(θjY ) and the plotting the samples. In nonparametric Bayesian inference, we replace the finite dimensional model ff(yjθ): θ 2 Θg with an infinite dimensional model such as Z F = f : (f 00(y))2dy < 1 (2) Typically, neither the prior nor the posterior have a density function with respect to a dominating measure. But the posterior is still well defined. On the other hand, if there is a dominating measure for a set of densities F then the posterior can be found by Bayes theorem: R A Ln(f)dπ(f) πn(A) ≡ P(f 2 AjY ) = R (3) F Ln(f)dπ(f) Q where A ⊂ F, Ln(f) = i f(Yi) is the likelihood function and π is a prior on F. -
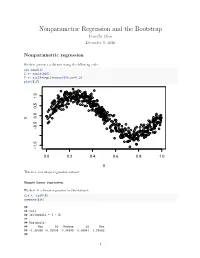
Nonparametric Regression and the Bootstrap Yen-Chi Chen December 5, 2016
Nonparametric Regression and the Bootstrap Yen-Chi Chen December 5, 2016 Nonparametric regression We first generate a dataset using the following code: set.seed(1) X <- runif(500) Y <- sin(X*2*pi)+rnorm(500,sd=0.2) plot(X,Y) 1.0 0.5 0.0 Y −0.5 −1.5 0.0 0.2 0.4 0.6 0.8 1.0 X This is a sine shape regression dataset. Simple linear regression We first fit a linear regression to this dataset: fit <- lm(Y~X) summary(fit) ## ## Call: ## lm(formula = Y ~ X) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1.38395 -0.35908 0.04589 0.38541 1.05982 ## 1 ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 1.03681 0.04306 24.08 <2e-16 *** ## X -1.98962 0.07545 -26.37 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 '' 1 ## ## Residual standard error: 0.4775 on 498 degrees of freedom ## Multiple R-squared: 0.5827, Adjusted R-squared: 0.5819 ## F-statistic: 695.4 on 1 and 498 DF, p-value: < 2.2e-16 We observe a negative slope and here is the scatter plot with the regression line: plot(X,Y, pch=20, cex=0.7, col="black") abline(fit, lwd=3, col="red") 1.0 0.5 0.0 Y −0.5 −1.5 0.0 0.2 0.4 0.6 0.8 1.0 X After fitted a regression, we need to examine the residual plot to see if there is any patetrn left in the fit: plot(X, fit$residuals) 2 1.0 0.5 0.0 fit$residuals −0.5 −1.0 0.0 0.2 0.4 0.6 0.8 1.0 X We see a clear pattern in the residual plot–this suggests that there is a nonlinear relationship between X and Y. -

Nonparametric Regression
Nonparametric Regression Statistical Machine Learning, Spring 2015 Ryan Tibshirani (with Larry Wasserman) 1 Introduction, and k-nearest-neighbors 1.1 Basic setup, random inputs Given a random pair (X; Y ) Rd R, recall that the function • 2 × f0(x) = E(Y X = x) j is called the regression function (of Y on X). The basic goal in nonparametric regression is ^ d to construct an estimate f of f0, from i.i.d. samples (x1; y1);::: (xn; yn) R R that have the same joint distribution as (X; Y ). We often call X the input, predictor,2 feature,× etc., and Y the output, outcome, response, etc. Importantly, in nonparametric regression we do not assume a certain parametric form for f0 Note for i.i.d. samples (x ; y );::: (x ; y ), we can always write • 1 1 n n yi = f0(xi) + i; i = 1; : : : n; where 1; : : : n are i.i.d. random errors, with mean zero. Therefore we can think about the sampling distribution as follows: (x1; 1);::: (xn; n) are i.i.d. draws from some common joint distribution, where E(i) = 0, and then y1; : : : yn are generated from the above model In addition, we will assume that each i is independent of xi. As discussed before, this is • actually quite a strong assumption, and you should think about it skeptically. We make this assumption for the sake of simplicity, and it should be noted that a good portion of theory that we cover (or at least, similar theory) also holds without the assumption of independence between the errors and the inputs 1.2 Basic setup, fixed inputs Another common setup in nonparametric regression is to directly assume a model • yi = f0(xi) + i; i = 1; : : : n; where now x1; : : : xn are fixed inputs, and 1; : : : are still i.i.d. -

Examining Residuals
Stat 565 Examining Residuals Jan 14 2016 Charlotte Wickham stat565.cwick.co.nz So far... xt = mt + st + zt Variable Trend Seasonality Noise measured at time t Estimate and{ subtract off Should be left with this, stationary but probably has serial correlation Residuals in Corvallis temperature series Temp - loess smooth on day of year - loess smooth on date Your turn Now I have residuals, how could I check the variance doesn't change through time (i.e. is stationary)? Is the variance stationary? Same checks as for mean except using squared residuals or absolute value of residuals. Why? var(x) = 1/n ∑ ( x - μ)2 Converts a visual comparison of spread to a visual comparison of mean. Plot squared residuals against time qplot(date, residual^2, data = corv) + geom_smooth(method = "loess") Plot squared residuals against season qplot(yday, residual^2, data = corv) + geom_smooth(method = "loess", size = 1) Fitted values against residuals Looking for mean-variance relationship qplot(temp - residual, residual^2, data = corv) + geom_smooth(method = "loess", size = 1) Non-stationary variance Just like the mean you can attempt to remove the non-stationarity in variance. However, to remove non-stationary variance you divide by an estimate of the standard deviation. Your turn For the temperature series, serial dependence (a.k.a autocorrelation) means that today's residual is dependent on yesterday's residual. Any ideas of how we could check that? Is there autocorrelation in the residuals? > corv$residual_lag1 <- c(NA, corv$residual[-nrow(corv)]) > head(corv) . residual residual_lag1 . 1.5856663 NA xt-1 = lag 1 of xt . -0.4928295 1.5856663 .