Machine Learning Algorithms for the Forecasting of Wastewater Quality Indicators
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Troubleshooting Activated Sludge Processes Introduction
Troubleshooting Activated Sludge Processes Introduction Excess Foam High Effluent Suspended Solids High Effluent Soluble BOD or Ammonia Low effluent pH Introduction Review of the literature shows that the activated sludge process has experienced operational problems since its inception. Although they did not experience settling problems with their activated sludge, Ardern and Lockett (Ardern and Lockett, 1914a) did note increased turbidity and reduced nitrification with reduced temperatures. By the early 1920s continuous-flow systems were having to deal with the scourge of activated sludge, bulking (Ardem and Lockett, 1914b, Martin 1927) and effluent suspended solids problems. Martin (1927) also describes effluent quality problems due to toxic and/or high-organic- strength industrial wastes. Oxygen demanding materials would bleedthrough the process. More recently, Jenkins, Richard and Daigger (1993) discussed severe foaming problems in activated sludge systems. Experience shows that controlling the activated sludge process is still difficult for many plants in the United States. However, improved process control can be obtained by systematically looking at the problems and their potential causes. Once the cause is defined, control actions can be initiated to eliminate the problem. Problems associated with the activated sludge process can usually be related to four conditions (Schuyler, 1995). Any of these can occur by themselves or with any of the other conditions. The first is foam. So much foam can accumulate that it becomes a safety problem by spilling out onto walkways. It becomes a regulatory problem as it spills from clarifier surfaces into the effluent. The second, high effluent suspended solids, can be caused by many things. It is the most common problem found in activated sludge systems. -

Chemical Industry Wastewater Treatment
CHEMICAL INDUSTRY WASTEWATER TREATMENT Fayza A. Nasr\ Hala S. Doma\ Hisham S Abdel-Halim", Saber A. El-Shafai* * Water Pollution Research department, National Research Centre, Cairo, Egypt "Faculty of Engineering, Cairo University, Cairo, Egypt Abstract Treatment of chemical industrial wastewater from building and construction chemicals factory and plastic shoes manufacturing factory was investigated. The two factories discharge their wastewater into the public sewerage network. The results showed the wastewater discharged from the building and construction chemicals factory was highly contaminated with organic compounds. The average values of COD and BOD were 2912 and 150 mg02/l. Phenol concentration up to 0.3 mg/l was detected. Chemical treatment using lime aided with ferric chloride proved to be effective and produced an effluent characteristics in compliance with Egyptian permissible limits. With respect to the other factory, industrial wastewater was mixed with domestic wastewater in order to lower the organic load. The COD, BOD values after mixing reached 5239 and 2615 mg02/l. The average concentration of phenol was 0.5 mg/l. Biological treatment using activated sludge or rotating biological contactor (RBC) proved to be an effective treatment system in terms of producing an effluent characteristic within the permissible limits set by the law. Therefore, the characteristics of chemical industrial wastewater determine which treatment system to utilize. Based on laboratory results TESCE, Vol. 30, No.2 <@> December 2004 engineering design of each treatment system was developed and cost estimate prepared. Key words: chemical industry, wastewater, treatment, chemical, biological Introduction The chemical industry is of importance in terms of its impact on the environment. -

Industrial Wastewater Treatment Technologies Fitxategia
INDUSTRIAL WASTEWATER TREATMENT TECHNOLOGIES Image by Frauke Feind from Pixabay licensed under CC0 Estibaliz Saez de Camara Oleaga & Eduardo de la Torre Pascual Faculty of Engineering Bilbao (UPV/EHU) Department of Chemical and Environmental Engineering Industrial Wastewaters (IWW) means the water or liquid that carries waste from industrial or processes, if it is distinct from domestic wastewater. Desalination plant “Rambla Morales desalination plant (Almería - Spain)” by David Martínez Vicente from Flickr licensed under CC BY 2.0 IWW may result from any process or activity of industry which uses water as a reactant or for transportation of heat or materials. 2 Characteristics of wastewater from industrial sources vary with the type and the size of the facility and the on-site treatment methods, if any. Because of this variation, it is often difficult to define typical operating conditions for industrial activities. Options available for the treatment of IWW are summarized briefly in next figure. To introduce in a logical order in the description of treatment techniques, the relationship between pollutants and respective typical treatment technology is taken as reference. 1. Removal of suspended solids and insoluble liquids 2. Removal of inorganic, non-biodegradable or poorly degradable soluble content 3. Removal of biodegradable soluble content 3 Range of wastewater treatments in relation to type of contaminants. Source: BREF http://eippcb.jrc.ec.europa.eu/reference/ 4 3.1. CLASSIFICATION OF INDUSTRIAL EFFLUENTS CLASSIFICATION OF EFFLUENTS -

Reverse Osmosis Treatment, Rejection of Carbon Dioxide, And
Evaluating the Impact of Reverse Osmosis Treatment on Finished Water Carbon Dioxide Concentration and pH WATERCON2012 March 21, 2012 Presented By: Jerry Phipps, P.E. Outline • Purpose • Background • Reverse Osmosis (RO) Fundamentals • Post-Treatment Processes • Pertinent Aquatic Chemistry • Case Studies • Conclusions and Recommendations • Questions Purpose • Review RO and carbonate chemistry fundamentals • Review data from full scale projects to determine change in carbon dioxide and pH from feed to permeate stream Background • The Reverse Osmosis (RO) process uses a semipermeable membrane to separate an influent stream into two streams, a purified permeate stream and a concentrated reject stream • Many references indicate that dissolved gases such as carbon dioxide (CO2) may pass through the membrane with no rejection • The combination of low alkalinity and high carbon dioxide results in an aggressive permeate stream with a lower pH than the influent stream Reverse Osmosis Membranes The most common RO membrane material today is aromatic polyamide, typically in the form of thin-film composites. They consist of a thin film of membrane, bonded to layers of other porous materials that are tightly wound to support and strengthen the membrane. Flow Recovery • Percent recovery is a key design parameter • Defined as permeate flow / influent flow • Recovery is limited by solubility products, Ksp • Typical value for groundwater is ~75%-85%, but varies with application • Example: Influent stream = 100 gpm, 75% recovery. Permeate stream = 75 gpm, -

The Ph of Drinking Water
The pH of drinking water The pH is a measure of the acidity or alkalinity. The water quality regulations specify that the pH of tap water should be between 6.5 and 9.5. What is pH and why do we test our Why has the pH of my water changed? water for it? If the problem only affects your property, the The pH is a numerical value used to indicate source is most likely your internal pipework and the degree to which water is acidic. pH plumbing. Possible sources include plumbed-in measurements range between 0 (strong acid) water filters or softeners, incorrectly installed and 14 (strong alkali), with 7 being neutral. The washing machines or dishwashers, incorrect water quality regulations specify that the pH fittings and taps supplied from storage tanks. of water at your tap should be between 6.5 If you have had plumbing work done recently and 9.5. Water leaving our treatment works then excessive use of solder or flux could be typically has a pH between 7 and 8, but this the cause. In this case the problem may lessen can change as it passes through the network of as water is used. Alternatively you may wish to reservoirs and water mains. consider changing the pipework or joints. We consume many different foods and beverages with a large range of pH. Your water quality For example, citrus fruits like oranges, lemons If you’re interested in finding out more about and limes are quite acidic (pH = 2.0 - 4.0). the quality of your drinking water, please visit Carbonated drinks such as cola have a pH unitedutilities.com/waterquality and enter your 4.0 to 4.5. -

Understanding Your Watershed- What Is
Understanding Your Watershed pH NR/WQ/2005-19 Nancy Mesner and John Geiger June 2005 (pr) What is pH? pH is a measurement of how acidic or how basic (alkaline) a solution is. When substances dissolve in water they produce charged molecules called ions. Acidic water contains extra hydrogen ions (H+) and basic water contains extra hydroxyl (OH-) ions. pH is measured on a scale of 0 to 14. Water that is neutral has a pH of 7. Acidic water has pH values less than 7, with 0 being the most acidic. Likewise, basic water has values greater than 7, with 14 being the most basic. A change of 1 unit on a pH scale represents a 10 fold change in the pH, so that water with pH of 6 is 10 times more acidic than water with a pH of 7, and water with a pH of 5 is 100 times more acidic than water with a pH of 7. You might expect rainwater to be neutral, but it is actually somewhat acidic. As rain drops fall through the atmosphere, they dissolve gaseous carbon dioxide, creating a weak acid. Pure rainfall has a pH of about 5.6. The figure below shows the pH of some common solutions. The pH of lakes and rivers in Utah typically falls between 6.5 and 9.0. Why is the pH of water important? Effects on animals and plants Most aquatic animals and plants have adapted to life in water with a specific pH and may suffer from even a slight change. -

Ph in Drinking-Water
WHO/SDE/WSH/07.01/1 pH in Drinking-water Revised background document for development of WHO Guidelines for Drinking-water Quality © World Health Organization 2007 This document may be freely reviewed, abstracted, reproduced and translated in part or in whole but not for sale or for use in conjunction with commercial purposes. Inquiries should be addressed to: [email protected]. The designations employed and the presentation of the material in this document do not imply the expression of any opinion whatsoever on the part of the World Health Organization concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The mention of specific companies or of certain manufacturers’ products does not imply that they are endorsed or recommended by the World Health Organization in preference to others of a similar nature that are not mentioned. Errors and omissions excepted, the names of proprietary products are distinguished by initial capital letters. The World Health Organization does not warrant that the information contained in this publication is complete and correct and shall not be liable for any damages incurred as a result of its use. Preface One of the primary goals of WHO and its member states is that “all people, whatever their stage of development and their social and economic conditions, have the right to have access to an adequate supply of safe drinking water.” A major WHO function to achieve such goals is the responsibility “to propose regulations, and to make recommendations with respect to international health matters ....” The first WHO document dealing specifically with public drinking-water quality was published in 1958 as International Standards for Drinking-water. -

Aeration, Ph Adjustment, and UF/MF Filtration for TSS Reduction of Produced Waters from Hayneville
Aeration, pH Adjustment, and UF/MF Filtration for TSS Reduction of Produced Waters from Hayneville Research & Engineering - Environmental Solutions, Applied Research Tor H. Palmgren - Exploratory & Special Projects Manager James R. Fajt - Senior Scientist Alexander G. Danilov - ProACT Engineer Texas A&M University David Burnett, Director of Technology, GPRI 1 11/30/2013 Haynesville Shale Shale straddles Arkansas, Louisiana and Texas Copyright © 2013 PennWell Corporation. All rights reserved. 2 11/30/2013 Haynesville - General Characteristics • Depth: 10,500 to 13,600 ft. • Lateral reach about the same • Fracturing Pressure > 10,000 psi • Bottom Hole Temperature: 100 to 350 F • Fracturing fluids used: slick water, linear gel and cross linked • Water sources: rivers, bayous, ponds, lakes, wells, flow back and produced water Source: Chesapeake Energy 3 11/30/2013 Haynesville - Produced Waters Characteristics • Recycled water utilized per well fractured : 0-35% • Common water contaminants: TSS, Calcium Magnesium, Iron, Bacteria • Key treatment targets: TSS, Scale Forming Ions, Bacteria • This discussion will focus on TSS removal and fluid clarification via membrane filtration Source: Chesapeake Energy 4 11/30/2013 Four Common Membrane Processes Process Name Approximate Useful Particle Permeate Size Removed Microfiltration 0.5 - 50 µm Clarified water Ultrafiltration 0.2 µm Clarified water Nanofiltration 0.5 - 0.7 nm Softened water Reverse Osmosis 0.1 -1 nm Low salinity water 5 11/30/2013 Filters Used in this Study Filter Manufacturer Micron -

Ph Neutralization English , PDF, 0.51MB
FS-PRE-004 TECHNOLOGY FACT SHEETS FOR EFFLUENT TREATMENT PLANTS ON TEXTILE INDUSTRY pH NEUTRALIZATION SERIES: PRE-TREATMENTS TITLE pH NEUTRALIZATION (FS-PRE-004) Last update December 2014 Last review pH NEUTRALIZATION FS-PRE-004 pH NEUTRALIZATION (FS-PRE-004) Date December 2014 Authors Pablo Ures Rodríguez Alfredo Jácome Burgos Joaquín Suárez López Revised by Last update Date Done by: Update main topics INDEX 1.INTRODUCTION 2.FUNDAMENTALS OF CHEMICAL NEUTRALIZATION 2.1. pH 2.2. Acidity and alkalinity 2.3. Buffer capacity 2.4. Commonly used chemicals 3.DESIGN AND OPERATION 3.1. Neutralizing system selection criteria 3.2. System design: batch or continuous 3.3. Design parameters 4.CONTROL OF PROCESS 5.SPECIFICATIONS FOR TEXTILE INDUSTRY EFFLUENT TREATMENT 5.1. Process water pre-treatment 5.2. Mill effluent pre-treatment 5.3. On the ETP treatment line 6.CONTROL PARAMETERS AND STRATEGIES 7.OPERATION AND MAINTENANCE TROUBLESHOOTING REFERENCES ANNEX 1.- COMMON REACTIVES ON NEUTRALIZATION PROCESS CHARACTERISTICS ANNEX 2.- GRAPHICAL DESCRIPTION OF PROCESS UNITS pH NEUTRALIZATION FS-PRE-004 Page 2 of 10 1. INTRODUCTION Many industrial wastes contain acidic or alkaline materials that require neutralization prior to discharge to receiving waters or prior to chemical or biological treatment. (Eckenfelder, 2000) Neutralization is the process of adjusting the pH of water through the addition of an acid or a base, depending on the target pH and process requirements. Most part of the effluents can be neutralized at a pH of 6 to 9 prior to discharge. In chemical industrial treatment, neutralization of excess alkalinity or acidity is often required. -

Ph NEUTRAL TOILET CLEANER Page: 1 Compilation Date: 15/03/2016 Revision Date: 18/01/2021 Revision No: 10
SAFETY DATA SHEET pH NEUTRAL TOILET CLEANER Page: 1 Compilation date: 15/03/2016 Revision date: 18/01/2021 Revision No: 10 Section 1: Identification of the substance/mixture and of the company/undertaking 1.1. Product identifier Product name: ph NEUTRAL TOILET CLEANER Product code: CP-NETCL-1L 1.2. Relevant identified uses of the substance or mixture and uses advised against Use of substance / mixture: PC35: Washing and cleaning products (including solvent based products). 1.3. Details of the supplier of the safety data sheet Bothongo Hygiene Solutions (UK) Ltd Company name: Briary Barn, 1st floor Pury Hill Business Park Towcester Northamptonshire NN12 7LS United Kingdom Tel: 07979377639 Email: [email protected] 1.4. Emergency telephone number Emergency tel: 07979377639 (office hours only) Section 2: Hazards identification 2.1. Classification of the substance or mixture Classification under CLP: This product has no classification under CLP. 2.2. Label elements Label elements: Precautionary statements: P305+P351+P338: IF IN EYES: Rinse cautiously with water for several minutes. Remove contact lenses, if present and easy to do. Continue rinsing. 2.3. Other hazards PBT: This product is not identified as a PBT/vPvB substance. Section 3: Composition/information on ingredients [cont...] SAFETY DATA SHEET pH NEUTRAL TOILET CLEANER Page: 2 3.2. Mixtures Contains: Fragrance D'Limonene Non ionic surfactant (Alcohol Ethoxylate) 1,2-Benzisothiazol-3(2H)-one Zinc Pyrithione Sodium Laureth Sulphate (Anionic Surfactant) Section 4: First aid measures 4.1. Description of first aid measures Eye contact: Bathe the eye with running water for 15 minutes. Ingestion: Do not induce vomiting. -
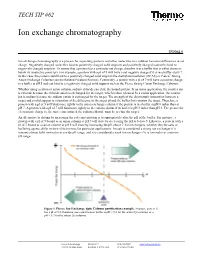
Ion Exchange Chromatography
TECH TIP #62 Ion exchange chromatography TR0062.0 Ion exchange chromatography is a process for separating proteins and other molecules in a solution based on differences in net charge. Negatively charged molecules bind to positively charged solid supports and positively charged molecules bind to negatively charged supports. To ensure that a protein has a particular net charge, dissolve it in a buffer that is either above or below its isoelectric point (pI). For example, a protein with a pI of 5 will have a net negative charge if it is in a buffer at pH 7. In this case, the protein could bind to a positively charged solid support like diethylaminoethanol (DEAE) or Pierce® Strong Anion Exchange Columns (see the Related Products Section). Conversely, a protein with a pI of 7 will have a positive charge in a buffer at pH 5 and can bind to a negatively charged solid support such as the Pierce Strong Cation Exchange Columns. Whether using a cation or anion column, sodium chloride can elute the bound protein. In an anion application, the counter ion is chloride because the chloride anion is exchanged for the target, which is then released. In a cation application, the counter ion is sodium because the sodium cation is exchanged for the target. The strength of the electrostatic interaction between a target and a solid support is a function of the difference in the target pI and the buffer that contains the target. Therefore, a protein with a pI of 5 will bind more tightly to the anion exchange column if the protein is in a buffer at pH 8 rather than at pH 7. -

Total Dissolved Solids in Drinking-Water
WHO/SDE/WSH/03.04/16 English only Total dissolved solids in Drinking-water Background document for development of WHO Guidelines for Drinking-water Quality __________________ Originally published in Guidelines for drinking-water quality, 2nd ed. Vol. 2. Health criteria and other supporting information. World Health Organization, Geneva, 1996. © World Health Organization 2003 All rights reserved. Publications of the World Health Organization can be obtained from Marketing and Dissemination, World Health Organization, 20 Avenue Appia, 1211 Geneva 27, Switzerland (tel: +41 22 791 2476; fax: +41 22 791 4857; email: [email protected]). Requests for permission to reproduce or translate WHO publications - whether for sale or for noncommercial distribution - should be addressed to Publications, at the above address (fax: +41 22 791 4806; email: [email protected]). The designations employed and the presentation of the material in this publication do not imply the expression of any opinion whatsoever on the part of the World Health Organization concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The mention of specific companies or of certain manufacturers’ products does not imply that they are endorsed or recommended by the World Health Organization in preference to others of a similar nature that are not mentioned. Errors and omissions excepted, the names of proprietary products are distinguished by initial capital letters. The World Health