A Pliable Hybrid Architecture for Code Isolation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

TK Backman, Jason Yang, SW Development at MS
T.K. Backman Jason Yang [email protected] [email protected] Principal Development Lead Principal Development Lead Debugging and Tools Group Analysis Technologies Team Windows Engineering Desktop Windows Engineering Desktop Microsoft Corporation Microsoft Corporationnnn Code on a massive scale Developers on a massive scale Tight constraints on schedules University of Washington 3/2/2011 2 ◦ Company structure Why the world is not just about developers ☺ ◦ Innovation strategy How we actually improve software over time ◦ Dynamic tension When people are involved, everything changes ◦ Development cycles How we build software products in cycles ◦ Program analysis How we push quality upstream ◦ Windows engineering system How we build large-scale products University of Washington 3/2/2011 3 ◦ Total size: ~89,000 employees ◦ Windows & Office – “perfect org structure” PM – program managers Dev – software developers Test – software developers in test ◦ Around 1000 PM+Dev+Test feature teams on 100s of products University of Washington 3/2/2011 4 ◦ Team size: ~10,000 employees ◦ Sales & marketing ◦ Project managers / product managers ◦ 30 feature teams 1500 Devs 1500 Testers 1000 PMs ◦ Customer support engineers ◦ Build engineers University of Washington 3/2/2011 5 “I often say that when you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meager and unsatisfactory kind; it may be the beginning -

Scheduling, Thread Context, and IRQL
Scheduling, Thread Context, and IRQL December 31, 2020 Abstract This paper presents information about how thread scheduling, thread context, and a processor’s current interrupt request level (IRQL) affect the operation of kernel- mode drivers for the Microsoft® Windows® family of operating systems. It is intended to provide driver writers with a greater understanding of the environment in which their code runs. A companion paper, “Locks, Deadlocks, and Synchronization” at http://www.microsoft.com/whdc/hwdev/driver/LOCKS.mspx, builds on these fundamental concepts to address synchronization issues in drivers. Contents Introduction ....................................................................................................................... 3 Thread Scheduling ............................................................................................................ 3 Thread Context and Driver Routines .................................................................................. 4 Driver Threads .................................................................................................................. 5 Interrupt Request Levels .................................................................................................... 6 Processor-Specific and Thread-Specific IRQLs .............................................................. 8 IRQL PASSIVE_LEVEL ............................................................................................ 8 IRQL PASSIVE_LEVEL, in a critical region .............................................................. -
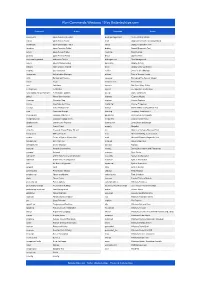
Run-Commands-Windows-10.Pdf
Run Commands Windows 10 by Bettertechtips.com Command Action Command Action documents Open Documents Folder devicepairingwizard Device Pairing Wizard videos Open Videos Folder msdt Diagnostics Troubleshooting Wizard downloads Open Downloads Folder tabcal Digitizer Calibration Tool favorites Open Favorites Folder dxdiag DirectX Diagnostic Tool recent Open Recent Folder cleanmgr Disk Cleanup pictures Open Pictures Folder dfrgui Optimie Drive devicepairingwizard Add a new Device diskmgmt.msc Disk Management winver About Windows dialog dpiscaling Display Setting hdwwiz Add Hardware Wizard dccw Display Color Calibration netplwiz User Accounts verifier Driver Verifier Manager azman.msc Authorization Manager utilman Ease of Access Center sdclt Backup and Restore rekeywiz Encryption File System Wizard fsquirt fsquirt eventvwr.msc Event Viewer calc Calculator fxscover Fax Cover Page Editor certmgr.msc Certificates sigverif File Signature Verification systempropertiesperformance Performance Options joy.cpl Game Controllers printui Printer User Interface iexpress IExpress Wizard charmap Character Map iexplore Internet Explorer cttune ClearType text Tuner inetcpl.cpl Internet Properties colorcpl Color Management iscsicpl iSCSI Initiator Configuration Tool cmd Command Prompt lpksetup Language Pack Installer comexp.msc Component Services gpedit.msc Local Group Policy Editor compmgmt.msc Computer Management secpol.msc Local Security Policy: displayswitch Connect to a Projector lusrmgr.msc Local Users and Groups control Control Panel magnify Magnifier -

Unit OS6: Device Management
Lab Manual - OS6 Device Management Unit OS6: Device Management 6.4. Lab Manual Windows Operating System Internals - by David A. Solomon and Mark E. Russinovich with Andreas Polze 1 Lab Manual - OS6 Device Management Copyright Notice © 2000-2005 David A. Solomon and Mark Russinovich These materials are part of the Windows Operating System Internals Curriculum Development Kit, developed by David A. Solomon and Mark E. Russinovich with Andreas Polze Microsoft has licensed these materials from David Solomon Expert Seminars, Inc. for distribution to academic organizations solely for use in academic environments (and not for commercial use) 2 2 Lab Manual - OS6 Device Management Roadmap for Section 6.4. Lab experiments investigating: Viewing Security Processes Looking at the SAM Viewing Access Tokens Looking at Security Identifiers (SIDs) Viewing a Security Descriptor structure Investigating ordering of Access Control Entries (ACEs) Investigating Privileges 3 This Lab Manual includes experiments investigating the the I/O system mechanisms and concepts implemented inside the Windows operating system. Students are expected to carry out Labs in addition to studying the learning materials in Unit OS6. A thorough understanding of the concepts presented in Unit OS6: Device Management is a prerequisite for these Labs. 3 Lab Manual - OS6 Device Management Lab: Viewing the Installed Driver List View the list of System Drivers in the Software Environment section of the Windows Information utility (Msinfo32.exe) Note: the distinction between File System Drivers and Kernel Drivers is from the Type value in the driver’s Registry key. This distinction is meaningless. 4 Lab objective: Viewing the Loaded Driver List You can see a list of registered drivers on a Windows 2000 system by going to the Drivers section of the Computer Management Microsoft Management Console (MMC) snapin or by right-clicking the My Computer icon on the desktop and selecting Manage from the context menu. -

Hardware Architectures for Software Security
Hardware Architectures for Software Security Joshua N. Edmison Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Engineering Dr. Mark T. Jones, Chair Dr. Lynn Abbott Dr. Peter M. Athanas Dr. Ezra Brown Dr. Thomas L. Martin Dr. Cameron D. Patterson June 29, 2006 Bradley Department of Electrical and Computer Engineering Blacksburg, Virginia Keywords: Security, architecture, FPGA, configurable, graph theory, information flow Copyright 2005 c , Joshua N. Edmison Hardware Architectures for Software Security Joshua N. Edmison (ABSTRACT) The need for hardware-based software protection stems primarily from the increasing value of software coupled with the inability to trust software that utilizes or manages shared resources. By correctly utilizing security functions in hardware, trust can be removed from software. Existing hardware-based software protection solutions generally suffer from utiliza- tion of trusted software, lack of implementation, and/or extreme measures such as processor redesign. In contrast, the research outlined in this document proposes that substantial, hardware-based software protection can be achieved, without trusting software or redesign- ing the processor, by augmenting existing processors with security management hardware placed outside of the processor boundary. Benefits of this approach include the ability to add security features to nearly any processor, update security features without redesigning the processor, and provide maximum transparency to the software development and distribution processes. The major contributions of this research include the the augmentation method- ology, design principles, and a graph-based method for analyzing hardware-based security systems. -

Windows Kernel Internals II Windows Driver Model University of Tokyo – July 2004*
Windows Kernel Internals II Windows Driver Model University of Tokyo – July 2004* Dave Probert, Ph.D. Advanced Operating Systems Group Windows Core Operating Systems Division Microsoft Corporation © Microsoft Corporation 2004 1 Windows I/O Model Asychronous, Packet-based, Extensible Device discovery supports plug-and-play — volumes automatically detected and mounted — power management support (ACPI) Drivers attach to per device driver stacks — Drivers can filter actions of other drivers in each stack Integrated kernel support — memory Manager provides DMA support — HAL provides device access, PnP manages device resources — Cache manager provides file-level caching via MM file-mapping Multiple I/O completion mechanisms: —synchronous —update user-mode memory status —signal events —callbacks within initiating thread —reaped by threads waiting on an I/O Completion Port © Microsoft Corporation 2004 2 IO Request Packet (IRP) IO operations encapsulated in IRPs IO requests travel down a driver stack in an IRP Each driver gets an IRP stack location which contains parameters for that IO request IRP has major and minor codes to describe IO operations Major codes include create, read, write, PNP, devioctl, cleanup and close Irps are associated with the thread that made the IO request © Microsoft Corporation 2004 3 Object Relationships Driver Object Device Object Device Device Device Object Object Object Volume Device Object Driver Object File Object File Object © Microsoft Corporation 2004 4 Layering Drivers Device objects attach one on top of another -

Windows Internals, Sixth Edition, Part 2
spine = 1.2” Part 2 About the Authors Mark Russinovich is a Technical Fellow in ® the Windows Azure™ group at Microsoft. Windows Internals He is coauthor of Windows Sysinternals SIXTH EDITION Administrator’s Reference, co-creator of the Sysinternals tools available from Microsoft Windows ® The definitive guide—fully updated for Windows 7 TechNet, and coauthor of the Windows Internals and Windows Server 2008 R2 book series. Delve inside Windows architecture and internals—and see how core David A. Solomon is coauthor of the Windows Internals book series and has taught components work behind the scenes. Led by a team of internationally his Windows internals class to thousands of renowned internals experts, this classic guide has been fully updated Windows developers and IT professionals worldwide, SIXTH for Windows 7 and Windows Server® 2008 R2—and now presents its including Microsoft staff. He is a regular speaker 6EDITION coverage in two volumes. at Microsoft conferences, including TechNet As always, you get critical, insider perspectives on how Windows and PDC. operates. And through hands-on experiments, you’ll experience its Alex Ionescu is a chief software architect and internal behavior firsthand—knowledge you can apply to improve consultant expert in low-level system software, application design, debugging, system performance, and support. kernel development, security training, and Internals reverse engineering. He teaches Windows internals courses with David Solomon, and is ® In Part 2, you will: active in the security research community. -

SAS/C Library Reference, Third Edition, Release 6.00 Volume 2
SAS/C Library Reference, Third Edition, Release 6.00 Volume 2 SAS Institute Inc. SAS Campus Drive Cary, NC 27513 The correct bibliographic citation for this manual is as follows: SAS Institute Inc., SAS/C Library Reference, Third Edition, Volume 2, Release 6.00, Cary, NC: SAS Institute Inc., 1995. 623 pp. SAS/C Library Reference, Third Edition, Volume 2, Release 6.00 Copyright 1995 by SAS Institute Inc., Cary, NC, USA. ISBN 1-55544-667-1 All rights reserved. Printed in the United States of America. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. Restricted Rights Legend. Use, duplication, or disclosure by the U.S. Government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013. SAS Institute Inc., SAS Campus Drive, Cary, North Carolina 27513. 1st printing, October 1995 The SAS System is an integrated system of software providing complete control over data access, management, analysis, and presentation. Base SAS software is the foundation of the SAS System. Products within the SAS System include SAS/ACCESS, SAS/AF, SAS/ASSIST, SAS/CALC, SAS/CONNECT, SAS/CPE, SAS/DMI, SAS/EIS, SAS/ENGLISH, SAS/ETS, SAS/FSP, SAS/GRAPH, SAS/IMAGE, SAS/IML, SAS/IMS-DL/I, SAS/INSIGHT, SAS/LAB, SAS/NVISION, SAS/OR, SAS/PH-Clinical, SAS/QC, SAS/REPLAY-CICS, SAS/SESSION, SAS/SHARE, SAS/SPECTRAVIEW, SAS/STAT, SAS/TOOLKIT, SAS/TRADER, SAS/TUTOR, SAS/DB2, SAS/GEO, SAS/GIS, SAS/PH-Kinetics, SAS/SHARE*NET, and SAS/SQL-DS software. -

Dan's Motorcycle Windows Commands
1 Complete List of Run Commands in Windows XP, Vista, 7, 8 & 8.1 ¶ People can get stuck if they are attacked with viruses or in any way can’t access different Applications in Windows. Sometimes it gets difficult to find the commands to start the applications directly. Knowing the Run Command for a program in different Windows versions can be very useful. if you’d like to start a program from a script file or if you only have access to a command line interface this can be helpful. For example, If you have Microsoft Word installed (Any version of Microsoft Office®) rather then searching or clicking the start icon, locating the Microsoft Office folder and then clicking the Microsoft Word. You can use the Windows Run Box instead to access the application directly. Just Click Start and Click Run or press "Window Key + R" and type "Winword" and press enter, Microsoft Word will open immediately. Here is a, hopefully, Complete list of RUN Commands in Windows XP, Vista, 7, 8 and 8.1 for your quick and easy access. Description of Applications Run Command 32-bit ODBC driver under 64-bit platform = C:\windows\sysWOW64\ odbcad32.exe 64 bit ODBC driver under 64-bit platform = C:\windows\system32\ odbcad32.exe Accessibility Controls access.cpl Accessibility Options control access.cpl Accessibility Wizard accwiz Copyright © 1999-2016 dansmc.com. All rights reserved. Adapter Troubleshooter (Vista/Win7) AdapterTroubleshooter 2 Add Features to Windows 8 Win8 windowsanytimeupgradeui Add Hardware Wizard Win8 hdwwiz Add New Hardware Wizard hdwwiz.cpl Add/Remove -

Kguard: Lightweight Kernel Protection Against Return-To-User Attacks
kGuard: Lightweight Kernel Protection against Return-to-user Attacks VasileiosP.Kemerlis GeorgiosPortokalidis AngelosD.Keromytis Network Security Lab Department of Computer Science Columbia University, New York, NY, USA {vpk, porto, angelos}@cs.columbia.edu Abstract Such return-to-user (ret2usr) attacks have affected all major OSs, including Windows [60], Linux [16, 18], Return-to-user (ret2usr) attacks exploit the operating sys- and FreeBSD [19, 59, 61], while they are not limited to tem kernel, enabling local users to hijack privileged ex- x86 systems [23], but have also targeted the ARM [30], ecution paths and execute arbitrary code with elevated DEC [31], and PowerPC [25] architectures. privileges. Current defenses have proven to be inade- There are numerous reasons to why attacks against the quate, as they have been repeatedly circumvented, in- kernel are becoming more common. First and foremost, cur considerable overhead, or rely on extended hypervi- processes running with administrative privileges have be- sors and special hardware features. We present kGuard, come harder to exploit due to the various defense mech- a compiler plugin that augments the kernel with com- anisms adopted by modern OSs [52, 34]. Second, NULL pact inline guards, which prevent ret2usr with low per- pointer dereference errors had not received significant at- formance and space overhead. kGuard can be used with tention, until recently, exactly because they were thought any operating system that features a weak separation be- impractical and too difficult to exploit. In fact, 2009 has tween kernel and user space, requires no modifications been proclaimed, by some security researchers, as “the to the OS, and is applicable to both 32- and 64-bit ar- year of the kernel NULL pointer dereference flaw”[15]. -

Testing Closed-Source Binary Device Drivers with DDT
Testing Closed-Source Binary Device Drivers with DDT Volodymyr Kuznetsov, Vitaly Chipounov, and George Candea School of Computer and Communication Sciences École Polytechnique Fédérale de Lausanne (EPFL), Switzerland Abstract non-privileged users to elevate their privileges to Local DDT is a system for testing closed-source binary de- System, leading to complete system compromise [24]. vice drivers against undesired behaviors, like race con- Our goal is to empower users to thoroughly test ditions, memory errors, resource leaks, etc. One can drivers before installing and loading them. We wish that metaphorically think of it as a pesticide against device the Windows pop-up requesting confirmation to install driver bugs. DDT combines virtualization with a spe- an uncertified driver also offered a “Test Now” button. cialized form of symbolic execution to thoroughly ex- By clicking that button, the user would launch a thor- ercise tested drivers; a set of modular dynamic check- ough test of the driver’s binary; this could run locally or ers identify bug conditions and produce detailed, exe- be automatically shipped to a trusted Internet service to cutable traces for every path that leads to a failure. These perform the testing on behalf of the user. Such function- traces can be used to easily reproduce and understand ality would benefit not only end users, but also the IT the bugs, thus both proving their existence and helping staff charged with managing corporate networks, desk- debug them. We applied DDT to several closed-source tops, and servers using proprietary device drivers. Microsoft-certified Windows device drivers and discov- Our work applies to all drivers, including those for ered 14 serious new bugs. -

Windriver™ USB User's Manual
WinDriver™ USB User's Manual Version 11.2.0 Jungo Ltd. WinDriver™ USB User's Manual: Version 11.2.0 Copyright © Jungo Ltd. 2005–2013 All Rights Reserved. Information in this document is subject to change without notice. The software described in this document is furnished under a license agreement. The software may be used, copied or distributed only in accordance with that agreement. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or any means, electronically or mechanically, including photocopying and recording for any purpose without the written permission of Jungo Ltd. Brand and product names mentioned in this document are trademarks of their respective owners and are used here only for identification purposes. © Jungo Ltd. 2005–2013 ii Table of Contents 1. WinDriver Overview .................................................................................................................. 1 1.1. Introduction to WinDriver .............................................................................................. 1 1.2. Background ..................................................................................................................... 2 1.2.1. The Challenge ...................................................................................................... 2 1.2.2. The WinDriver Solution ...................................................................................... 2 1.3. Conclusion ......................................................................................................................