You Don't Always Need an Application Server to Run Jakarta EE Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Download Issue
Issue October 2019 | presented by www.jaxenter.com #70 The digital magazine for enterprise developers JavaThe JDK’s hidden 13 treasures i Jakarta EE 8 Let the games begin JDK 13 Why text blocks are worth the wait OpenJFX 13 JavaFX gets its own identity © Teguh Mujiono/Shutterstock.com, Pushkin/Shutterstock.com Illustrationen: Sun Microsystems Inc., S&S Media Editorial Let’s celebrate Java – three times! It’s that time again: A new Java version is here! Java 13 Last but not least: Jakarta EE, the follow-up project of was launched as planned, six months after the release Java EE, has announced its first release under the umbrella of of Java 12, and again it has some interesting features on the Eclipse Foundation. We got hold of the executive director board. In this issue of Jax Magazine, we’ve covered them of the Eclipse Foundation, Mike Milinkovich, and asked him for you in detail. about the current status of Jakarta EE. The good news doesn’t end there, as JavaFX 13 has also been released. The UI toolkit is no longer included in the JDK Happy reading, but has adjusted its new version releases to the new Java re- lease cadence. Find out what’s new here! Hartmut Schlosser Java 13 – a deep dive into the JDK’s 3 Kubernetes as a multi-cloud 17 new features operating system Falk Sippach Patrick Arnold Index Java 13 – why text blocks are worth the wait 6 Multi-tier deployment with Ansible 21 Tim Zöller Daniel Stender Jakarta EE 8 is sprinting towards an 9 Do we need a service mesh? 28 exciting future for enterprise Java Anton Weiss Thilo Frotscher -

Creating Dynamic Web-Based Reporting Dana Rafiee, Destiny Corporation, Wethersfield, CT
Creating Dynamic Web-based Reporting Dana Rafiee, Destiny Corporation, Wethersfield, CT ABSTRACT OVERVIEW OF SAS/INTRNET SOFTWARE In this hands on workshop, we'll demonstrate and discuss how to take a standard or adhoc report and turn it into a web based First, it is important to understand SAS/INTRNET software and its report that is available on demand in your organization. In the use. workshop, attendees will modify an existing report and display the results in various web based formats, including HTML, PDF Three components are required for the SAS/INTRNET software and RTF. to work. INTRODUCTION 1) Web Server Software – such as Microsoft’s Personal To do this, we’ll use Dreamweaver software as a GUI tool to Web Server/Internet Information Services, or the create HTML web pages. We’ll use SAS/Intrnet software as a Apache Web Server. back end tool to execute SAS programs with parameters selected on the HTML screen presented to the user. 2) Web Browser – Such as Microsoft’s Internet Explorer or Netscape’s Navigator. Our goal is to create the following screen for user input. 3) SAS/INTRNET Software – Called the Application Dispatcher. It is composed of 2 pieces. o SAS Application Server – A SAS program on a Server licensed with the SAS/INTRNET Module. o Application Broker – A Common Gateway Interface (CGI) program that resides on the web server and communicates between the Browser and the Application Server. These components can all reside on the same system, or on different systems. Types of Services 1) Socket Service: is constantly running, waiting for incoming Transactions. -

Red Hat Jboss Enterprise Application Platform 7.4 Developing Jakarta Enterprise Beans Applications
Red Hat JBoss Enterprise Application Platform 7.4 Developing Jakarta Enterprise Beans Applications Instructions and information for developers and administrators who want to develop and deploy Jakarta Enterprise Beans applications for Red Hat JBoss Enterprise Application Platform. Last Updated: 2021-09-10 Red Hat JBoss Enterprise Application Platform 7.4 Developing Jakarta Enterprise Beans Applications Instructions and information for developers and administrators who want to develop and deploy Jakarta Enterprise Beans applications for Red Hat JBoss Enterprise Application Platform. Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. -

Web Applicationapplication Architecturearchitecture && Structurestructure
WebWeb ApplicationApplication ArchitectureArchitecture && StructureStructure SangSang ShinShin MichèleMichèle GarocheGaroche www.JPassion.comwww.JPassion.com ““LearnLearn withwith JPassion!”JPassion!” 1 Agenda ● Web application, components and Web container ● Technologies used in Web application ● Web application development and deployment steps ● Web Application Archive (*.WAR file) – *.WAR directory structure – WEB-INF subdirectory ● Configuring Web application – Web application deployment descriptor (web.xml file) 2 Web Application & Web Application & WebWeb ComponentsComponents && WebWeb ContainerContainer 3 Web Components & & Container Web Components Applet Applet JNDI Client App App Client App Container Browser Container Browser J2SE J2SE Client Client App App J2SE JMS RMI/IIOP HTTPS HTTPS HTTP/ HTTP/ HTTPS HTTPS HTTP/ JDBC HTTP/ JNDI JSP JMS JSP Web Web Container Web Web Container RMI J2SE RMI JTA JavaMail JAF Servlet Servlet RMI/IIOP JDBC RMI RMI JNDI JMS Database Database EJB Container EJB Container J2SE JTA EJB JavaMail EJB JAF RMI/IIOP 4 JDBC Web Components & Container ● Web components are in the form of either Servlet or JSP (JSP is converted into Servlet) ● Web components run in a Web container – Tomcat/Jetty are popular web containers – All J2EE compliant app servers (GlassFish, WebSphere, WebLogic, JBoss) provide web containers ● Web container provides system services to Web components – Request dispatching, security, and life cycle management 5 Web Application & Components ● Web Application is a deployable package – Web -

Modern Web Application Frameworks
MASARYKOVA UNIVERZITA FAKULTA INFORMATIKY Û¡¢£¤¥¦§¨ª«¬Æ°±²³´µ·¸¹º»¼½¾¿Ý Modern Web Application Frameworks MASTER’S THESIS Bc. Jan Pater Brno, autumn 2015 Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or ex- cerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Bc. Jan Pater Advisor: doc. RNDr. Petr Sojka, Ph.D. i Abstract The aim of this paper was the analysis of major web application frameworks and the design and implementation of applications for website content ma- nagement of Laboratory of Multimedia Electronic Applications and Film festival organized by Faculty of Informatics. The paper introduces readers into web application development problematic and focuses on characte- ristics and specifics of ten selected modern web application frameworks, which were described and compared on the basis of relevant criteria. Practi- cal part of the paper includes the selection of a suitable framework for im- plementation of both applications and describes their design, development process and deployment within the laboratory. ii Keywords Web application, Framework, PHP,Java, Ruby, Python, Laravel, Nette, Phal- con, Rails, Padrino, Django, Flask, Grails, Vaadin, Play, LEMMA, Film fes- tival iii Acknowledgement I would like to show my gratitude to my supervisor doc. RNDr. Petr So- jka, Ph.D. for his advice and comments on this thesis as well as to RNDr. Lukáš Hejtmánek, Ph.D. for his assistance with application deployment and server setup. Many thanks also go to OndˇrejTom for his valuable help and advice during application development. -

Verteilte Systeme
Verteilte Systeme Interprozesskommunikation & Entfernter Aufruf 1 Interprozesskommunikation Applikationen, Dienste RemoteMethodInvocation und RemoteProcedureCall Middleware- Anforderung/Antwort-Protokoll (request-reply protocol) schichten Marshalling und externe Datendarstellung UniversalDatagramProtocol und TransmissionControlProtocol ACHTUNG: In der „Zweitliteratur“ wird RMI oft mit Java RMI gleichgesetzt! Korrekt ist: Java-RMI ist eine konkrete Realisierung des RMI-Konzeptes. 2 Interprozesskommunikation u Anwendungsprogramme laufen in Prozessen ab. u Ein Prozess ist ein Objekt des Betriebssystems, durch das Anwendungen sicheren Zugriff auf die Ressourcen des Computers erhalten. Einzelne Prozesse sind deshalb gegeneinander isoliert. (Aufgabe des Betriebssystems) u Damit zwei Prozesse Informationen austauschen können, müssen sie Interprozesskommunikation (interprocess- communication, IPC) verwenden. u IPC basiert auf (Speicher-/Nachrichtenbasierter) Kommunikation 1. gemeinsamen Speicher: für VS nicht direkt verwendbar 2. Austausch von Nachrichten (= Bytefolge) über einen Kommunikationskanal zwischen Sender und Empfänger. 3 Interprozesskommunikation •Betriebssystem: Koordiniert IPC innerhalb dieses BS. •IPC in verteilten Systemen geschieht ausschließlich über Nachrichten •Koordination der IPC durch Middleware oder/und durch Entwickler •Hierbei sind gewisse Normen zu beachten, damit die Kommunikation klappt!! •Protokoll := Festlegung der Regeln und des algorithmischen Ablaufs bei der Kommunikation zwischen zwei oder mehr Partnern Nachricht -
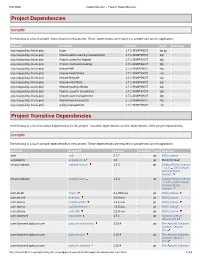
Project Dependencies Project Transitive Dependencies
9/8/2020 Dependencies – Project Dependencies Project Dependencies compile The following is a list of compile dependencies for this project. These dependencies are required to compile and run the application: GroupId ArtifactId Version Type Licenses org.onap.policy.drools-pdp base 1.7.1-SNAPSHOT tar.gz - org.onap.policy.drools-pdp feature-active-standby-management 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-controller-logging 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-distributed-locking 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-eelf 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-healthcheck 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-lifecycle 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-mdc-filters 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-pooling-dmaap 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-session-persistence 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-state-management 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp feature-test-transaction 1.7.1-SNAPSHOT zip - org.onap.policy.drools-pdp policy-management 1.7.1-SNAPSHOT zip - Project Transitive Dependencies The following is a list of transitive dependencies for this project. Transitive dependencies are the dependencies of the project dependencies. compile The following is a list of compile dependencies for this project. These dependencies are required to compile and run the application: GroupId ArtifactId Version Classifier Type Licenses antlr antlr 2.7.7 - jar BSD License -

Chapter 5: Bonforum Chat Application: Use and Design 5.1
Chapter 5: bonForum Chat Application: Use and Design - XML, XSLT, Java, and JSP Page 1 of 22 Chapter 5: bonForum Chat Application: Use and Design This chapter introduces you to bonForum, the Web chat application that will be the major subject of the rest of the book. bonForum was designed as a tool to explore each of the subjects of this book, XML, XSLT, Java servlets, Java applets, and JavaServer Pages, while solving some real Web application problems. 5.1 Installing and Running bonForum You can understand the remainder of this book much more easily if you have installed and tried out the Web chat application that it features. Therefore, we begin this chapter with instructions for installing and running bonForum. 5.1.1 A Preview of the Rest of the Book After helping you install and try bonForum, this chapter gives you some hints about how you can customize bonForum and develop it further yourself. After that, we discuss the design process. This chapter ends with some additional material about using XML data in Web applications. The next chapter continues this overview of the entire bonForum project and begins by describing the implementation that our design led us to develop. That chapter ends with highlights of some of the major problems that we encountered, together with solutions found and solutions planned. In Chapters 7–11, we cover in detail the code that we developed as we created this prototype for a multiuser, server-based Web application. Each of those chapters focuses on a different software technology that we applied to create the bonForum Web chat and uses excerpts from the source code to illustrate the discussion. -

Attacking AJAX Web Applications Vulns 2.0 for Web 2.0
Attacking AJAX Web Applications Vulns 2.0 for Web 2.0 Alex Stamos Zane Lackey [email protected] [email protected] Blackhat Japan October 5, 2006 Information Security Partners, LLC iSECPartners.com Information Security Partners, LLC www.isecpartners.com Agenda • Introduction – Who are we? – Why care about AJAX? • How does AJAX change Web Attacks? • AJAX Background and Technologies • Attacks Against AJAX – Discovery and Method Manipulation – XSS – Cross-Site Request Forgery • Security of Popular Frameworks – Microsoft ATLAS – Google GWT –Java DWR • Q&A 2 Information Security Partners, LLC www.isecpartners.com Introduction • Who are we? – Consultants for iSEC Partners – Application security consultants and researchers – Based in San Francisco • Why listen to this talk? – New technologies are making web app security much more complicated • This is obvious to anybody who reads the paper – MySpace – Yahoo – Worming of XSS – Our Goals for what you should walk away with: • Basic understanding of AJAX and different AJAX technologies • Knowledge of how AJAX changes web attacks • In-depth knowledge on XSS and XSRF in AJAX • An opinion on whether you can trust your AJAX framework to “take care of security” 3 Information Security Partners, LLC www.isecpartners.com Shameless Plug Slide • Special Thanks to: – Scott Stender, Jesse Burns, and Brad Hill of iSEC Partners – Amit Klein and Jeremiah Grossman for doing great work in this area – Rich Cannings at Google • Books by iSECer Himanshu Dwivedi – Securing Storage – Hackers’ Challenge 3 • We are -

Jakarta Enhancement Guide (V6.0) Table of Contents
Jakarta Enhancement Guide (v6.0) Table of Contents Maven . 3 Ant . 5 Command Line . 7 Runtime Enhancement . 9 Programmatic API . 10 Enhancement Contract Details . 11 Persistable . 11 Byte-Code Enhancement Myths . 12 Cloning of enhanced classes . 12 Serialisation of enhanced classes. 12 Decompilation. 13 DataNucleus requires that all Jakarta entities implement Persistable and Detachable. Rather than requiring that a user add this themself, we provide an enhancer that will modify your compiled classes to implement all required methods. This is provided in datanucleus-core.jar. • The use of this interface means that you get transparent persistence, and your classes always remain your classes; ORM tools that use a mix of reflection and/or proxies are not totally transparent. • DataNucleus' use of Persistable provides transparent change tracking. When any change is made to an object the change creates a notification to DataNucleus allowing it to be optimally persisted. ORM tools that dont have access to such change tracking have to use reflection to detect changes. The performance of this process will break down as soon as you read a large number of objects, but modify just a handful, with these tools having to compare all object states for modification at transaction commit time. • OpenJPA requires a similar bytecode enhancement process also, and EclipseLink and Hibernate both allow it as an option since they also now see the benefits of this approach over use of proxies and reflection. In the DataNucleus bytecode enhancement contract there are 3 categories of classes. These are Entity, PersistenceAware and normal classes. The Meta-Data (XML or annotations) defines which classes fit into these categories. -

Licensing Information User Manual Release 21C (21.1) F37966-01 March 2021
Oracle® Zero Downtime Migration Licensing Information User Manual Release 21c (21.1) F37966-01 March 2021 Introduction This Licensing Information document is a part of the product or program documentation under the terms of your Oracle license agreement and is intended to help you understand the program editions, entitlements, restrictions, prerequisites, special license rights, and/or separately licensed third party technology terms associated with the Oracle software program(s) covered by this document (the "Program(s)"). Entitled or restricted use products or components identified in this document that are not provided with the particular Program may be obtained from the Oracle Software Delivery Cloud website (https://edelivery.oracle.com) or from media Oracle may provide. If you have a question about your license rights and obligations, please contact your Oracle sales representative, review the information provided in Oracle’s Software Investment Guide (http://www.oracle.com/us/ corporate/pricing/software-investment-guide/index.html), and/or contact the applicable Oracle License Management Services representative listed on http:// www.oracle.com/us/corporate/license-management-services/index.html. Licensing Information Third-Party Notices and/or Licenses About the Third-Party Licenses The third party licensing information in Oracle Database Licensing Information User Manual, Third-Party Notices and/or Licenses and Open Source Software License Text, applies to Oracle Zero Downtime Migration. The third party licensing information included in the license notices provided with Oracle Linux applies to Oracle Zero Downtime Migration. Open Source or Other Separately Licensed Software Required notices for open source or other separately licensed software products or components distributed in Oracle Zero Downtime Migration are identified in the following table along with the applicable licensing information. -

Third-Party License Acknowledgments
Symantec Privileged Access Manager Third-Party License Acknowledgments Version 3.4.3 Symantec Privileged Access Manager Third-Party License Acknowledgments Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. Copyright © 2021 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. 2 Symantec Privileged Access Manager Third-Party License Acknowledgments Contents Activation 1.1.1 ..................................................................................................................................... 7 Adal4j 1.1.2 ............................................................................................................................................ 7 AdoptOpenJDK 1.8.0_282-b08 ............................................................................................................ 7 Aespipe 2.4e aespipe ........................................................................................................................