A Declarative Language for Integrating Machine Learning in Visual Analytics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enhancing Usability Evaluation of Web-Based Geographic Information
Enhancing Usability Evaluation of Web-Based Geographic Information Systems (WebGIS) with Visual Analytics René Unrau Institute for Geoinformatics, University of Münster, Germany Christian Kray Institute for Geoinformatics, University of Münster, Germany Abstract Many websites nowadays incorporate geospatial data that users interact with, for example, to filter search results or compare alternatives. These web-based geographic information systems (WebGIS) pose new challenges for usability evaluations as both the interaction with classic interface elements and with map-based visualizations have to be analyzed to understand user behavior. This paper proposes a new scalable approach that applies visual analytics to logged interaction data with WebGIS, which facilitates the interactive exploration and analysis of user behavior. In order to evaluate our approach, we implemented it as a toolkit that can be easily integrated into existing WebGIS. We then deployed the toolkit in a user study (N=60) with a realistic WebGIS and analyzed users’ interaction in a second study with usability experts (N=7). Our results indicate that the proposed approach is practically feasible, easy to integrate into existing systems, and facilitates insights into the usability of WebGIS. 2012 ACM Subject Classification Human-centered computing → User studies; Human-centered computing → Usability testing Keywords and phrases map interaction, usability evaluation, visual analytics Digital Object Identifier 10.4230/LIPIcs.GIScience.2021.I.15 Supplementary Material The source code is publicly available at https://github.com/ReneU/ session-viewer and includes configuration instructions for use in other scenarios. 1 Introduction Geospatial data has become a critical backbone of many web services available today, such as search engines, online booking sites, or open data portals [29]. -

Geotime As an Adjunct Analysis Tool for Social Media Threat Analysis and Investigations for the Boston Police Department Offeror: Uncharted Software Inc
GeoTime as an Adjunct Analysis Tool for Social Media Threat Analysis and Investigations for the Boston Police Department Offeror: Uncharted Software Inc. 2 Berkeley St, Suite 600 Toronto ON M5A 4J5 Canada Business Type: Canadian Small Business Jurisdiction: Federally incorporated in Canada Date of Incorporation: October 8, 2001 Federal Tax Identification Number: 98-0691013 ATTN: Jenny Prosser, Contract Manager, [email protected] Subject: Acquiring Technology and Services of Social Media Threats for the Boston Police Department Uncharted Software Inc. (formerly Oculus Info Inc.) respectfully submits the following response to the Technology and Services of Social Media Threats RFP. Uncharted accepts all conditions and requirements contained in the RFP. Uncharted designs, develops and deploys innovative visual analytics systems and products for analysis and decision-making in complex information environments. Please direct any questions about this response to our point of contact for this response, Adeel Khamisa at 416-203-3003 x250 or [email protected]. Sincerely, Adeel Khamisa Law Enforcement Industry Manager, GeoTime® Uncharted Software Inc. [email protected] 416-203-3003 x250 416-708-6677 Company Proprietary Notice: This proposal includes data that shall not be disclosed outside the Government and shall not be duplicated, used, or disclosed – in whole or in part – for any purpose other than to evaluate this proposal. If, however, a contract is awarded to this offeror as a result of – or in connection with – the submission of this data, the Government shall have the right to duplicate, use, or disclose the data to the extent provided in the resulting contract. GeoTime as an Adjunct Analysis Tool for Social Media Threat Analysis and Investigations 1. -

Stories in Geotime
Stories in GeoTime Ryan Eccles, Thomas Kapler, Robert Harper, William Wright Information Visualization ( 2008 ) © Stefan John 2008 Summer term 2008 1 Introduction • Story a powerful abstraction − Used by intelligence analysts to conceptualize threats and understand patterns − Part of the analytical process • Oculus Info’s GeoTime™ − Geo-temporal event visualization tool − Augmented with story system − Narratives, hypertext-linked visualizations, visual annotations, and pattern detection − Environment for analytic exploration and communication − Detects geo-temporal patterns − Integrates story narration to increase analytic sense-making cohesion Summer term 2008 2 1 Introduction • Assisting the analyst in: − Identifying, − Extracting, − Arranging, and − Presenting stories within the data • Story system − Lets analysts operate at story level − Higher level abstractions of data (behaviors and events) − Staying connected to the evidence − Developed in collaboration with analysts • Formal evaluation showed high utility and usability Summer term 2008 3 Overview • Storytelling • Related Work • Geo-Temporal Visualization in GeoTime • Stories in GeoTime • Evaluation Summer term 2008 4 2 Storytelling • First described in Aristotle’s Poetics − Objects of a tragedy (story): - Plot -> arrangements of incidents -Character - Thought -> processes of reasoning leading characters to their respective behavior • Narrative theory suggests: − People are essentially storytellers − Implicit ability to evaluate a story for: - Consistency -Detail - Structure Summer -
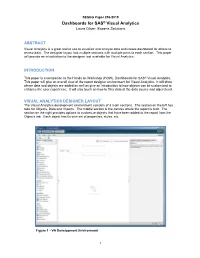
Dashboards for SAS® Visual Analytics Laura Oliver, Experis Solutions
SESUG Paper 256-2019 Dashboards for SAS® Visual Analytics Laura Oliver, Experis Solutions ABSTRACT Visual Analytics is a great tool to use to visualize and analyze data and create dashboard for others to review data. The designer layout has multiple sections with multiple parts to each section. This paper will provide an introduction to the designer tool available for Visual Analytics. INTRODUCTION This paper is a companion to the Hands on Workshop (HOW), Dashboards for SAS® Visual Analytics. This paper will give an overall view of the report designer environment for Visual Analytics. It will show where data and objects are added as well as give an introduction to how objects can be customized to enhance the user experience. It will also touch on how to filter data at the data source and object level. VISUAL ANALYTICS DESIGNER LAYOUT The Visual Analytics development environment consists of 3 main sections. The section on the left has tabs for Objects, Data and Imports. The middle section is the canvas where the report is built. The section on the right provides options to customize objects that have been added to the report from the Objects tab. Each object has its own set of properties, styles, etc. Figure 1 - VA Development Environment 1 DATA TAB The first step in creating a report is adding a data source. This is done on the Data tab using the Select a data source drop down. The Add Data Source dialog box will open, allowing a data source to be selected. All data sources must have been previously uploaded to the LASR server to be available for use in a report. -

SAS Visual Analytics Tricks We Learned From
SESUG Paper RV-58-2017 SAS® Visual Analytics Tricks We Learned from Reading Hundreds of SAS® Community Posts Tricia Aanderud, Ryan Kumpfmiller; Zencos Consulting Rob Collum, SAS Institute ABSTRACT After you know the basics of SAS Visual Analytics, you realize there are some situations that require unique strategies. Sometimes tables are not structured right or become too large for the environment. Maybe creating the right custom calculation for a dashboard can be confusing. Geospatial data is hard to work with if you haven’t ever used it before. We looked through 100s of SAS Communities posts for the most common questions. These solutions (and a few extras) were extracted from the newly released Introduction to SAS Visual Analytics book. INTRODUCTION Our goal in writing the Introduction to SAS Visual Analytics book was to create a really practical and useful book for users. As part of the research for the book, we read hundreds of posts in the SAS Communities: SAS Visual Analytics section. This was a great exercise because we could confirm some of the sticking points that we know users have and pick up some tips to emphasize in the book as well. This paper combines our favorite tips from the book and some other ones that we think are worth sharing. Note: All examples were done using SAS Visual Analytics version 7.3 WHAT IS SAS COMMUNITIES? SAS Communities is an open forum on the SAS website, https://communities.sas.com, which connects SAS users all over the world. With over a hundred thousand members, users can post questions about challenges they are currently having working with SAS products or provide answers to other users who are looking for advice. -

A Visual Analytics Approach to Dynamic Social Networks
A Visual Analytics Approach to Dynamic Social Networks Paolo Federico1, Wolfgang Aigner1, Silvia Miksch1, Florian Windhager2, Lukas Zenk2 1Institute of Software Technology 2Department for Knowledge and Interactive Systems and Communication Management Vienna University of Technology, Austria Danube University Krems, Austria {federico, aigner, {florian.windhager, miksch}@cvast.tuwien.ac.at lukas.zenk}@donau-uni.ac.at ABSTRACT of employees in a large enterprise; the widespread connections The visualization and analysis of dynamic networks have become through social networking services; or the covert activities of increasingly important in several fields, for instance sociology or small, interconnected terrorist cells. economics. The dynamic and multi-relational nature of this data On the one hand, dynamic networks are capable of modeling poses the challenge of understanding both its topological structure such diverse problems, but on the other hand, they are complex in and how it changes over time. In this paper we propose a visual many respects and they are not easy to grasp for non-expert users. analytics approach for analyzing dynamic networks that For this reason we designed and developed a research prototype integrates: a dynamic layout with user-controlled trade-off aiming to facilitate the interactive exploration of dynamic between stability and consistency; three temporal views based on networks, the comprehension of their structure and in particular different combinations of node-link diagrams (layer how these structures change over time. We adopted a visual superimposition, layer juxtaposition, and two-and-a-half- analytics approach by combining interactive visualization dimensional view); the visualization of social network analysis techniques with automated analysis methods, taking into account metrics; and specific interaction techniques for tracking node some basic perceptual aspects. -

Poster Summary
Grand Challenge Award 2008: Support for Diverse Analytic Techniques - nSpace2 and GeoTime Visual Analytics Lynn Chien, Annie Tat, Pascale Proulx, Adeel Khamisa, William Wright* Oculus Info Inc. ABSTRACT nSpace2 allows analysts to share TRIST and Sandbox files in a GeoTime and nSpace2 are interactive visual analytics tools that web environment. Multiple Sandboxes can be made and opened were used to examine and interpret all four of the 2008 VAST in different browser windows so the analyst can interact with Challenge datasets. GeoTime excels in visualizing event patterns different facets of information at the same time, as shown in in time and space, or in time and any abstract landscape, while Figure 2. The Sandbox is an integrating analytic tool. Results nSpace2 is a web-based analytical tool designed to support every from each of the quite different mini-challenges were combined in step of the analytical process. nSpace2 is an integrating analytic the Sandbox environment. environment. This paper highlights the VAST analytical experience with these tools that contributed to the success of these The Sandbox is a flexible and expressive thinking environment tools and this team for the third consecutive year. where ideas are unrestricted and thoughts can flow freely and be recorded by pointing and typing anywhere [3]. The Pasteboard CR Categories: H.5.2 [Information Interfaces & Presentations]: sits at the bottom panel of the browser and relevant information User Interfaces – Graphical User Interfaces (GUI); I.3.6 such as entities, evidence and an analyst’s hypotheses can be [Methodology and Techniques]: Interaction Techniques. copied to it and then transferred to other Sandboxes to be assembled according to a different perspective for example. -

A Two-Stage Framework for Designing Visual Analytics System in Organizational Environments
A Two-stage Framework for Designing Visual Analytics System in Organizational Environments Xiaoyu Wang Wenwen Dou Thomas Butkiewicz Eric A. Bier William Ribarsky UNC Charlotte UNC Charlotte University of New Hampshire Palo Alto Research Center UNC Charlotte researchers and designers new ideas regarding how to evaluate ABSTRACT and improve their own work. A perennially interesting research topic in the field of visual Given the need to incorporate successes from diverse VA analytics is how to effectively develop systems that support systems, it is difficult to generate a framework that can summarize organizational users' decision-making and reasoning processes. and instruct all the design requirements from a top-down The problem is, however, most domain analytical practices perspective. High-level VA design frameworks like [14, 41, 44, generally vary from organization to organization. This leads to 55] are certainly of great value. Nonetheless, little specific diverse designs of visual analytics systems in incorporating guidance or recommendation is currently available to articulate domain analytical processes, making it difficult to generalize the the boundaries within which particular design assumptions apply, success from one domain to another. Exacerbating this problem is leaving the system design to be solely based on designers' prior the dearth of general models of analytical workflows available to experience. For example, how does a designer know which enable such timely and effective designs. analysis method is suitable to characterize an organization? Are To alleviate these problems, we present a two-stage framework there components that a designer should follow to systematically for informing the design of a visual analytics system. -

Visualizing Relationships and Connections in Complex Data Using Network Diagrams in SAS® Visual Analytics Stephen Overton, Ben Zenick, Zencos Consulting
Paper 3323-2015 Visualizing Relationships and Connections in Complex Data Using Network Diagrams in SAS® Visual Analytics Stephen Overton, Ben Zenick, Zencos Consulting ABSTRACT Network diagrams in SAS® Visual Analytics help highlight relationships in complex data by enabling users to visually correlate entire populations of values based on how they relate to one another. Network diagrams are appealing because they enable an analyst to visualize large volumes and relationships of data and to assign multiple roles to represent key factors for analysis such as node size and color and linkage size and color. SAS Visual Analytics can overlay a network diagram on top of a spatial geographic map for an even more appealing visualization. This paper focuses specifically on how to prepare data for network diagrams and how to build network diagrams in SAS Visual Analytics. This paper provides two real-world examples illustrating how to visualize users and groups from SAS® metadata and how banks can visualize transaction flow using network diagrams. INTRODUCTION Network diagrams became widely popular when social media outlets opened their doors for developers to create visual representations of a person’s social network. Users of Facebook and LinkedIn can visualize their entire network of connections using third party developer tools that utilize network diagrams to mathematically group and correlate relationships to highlight mutual connections and visualize clusters of relationships. A network diagram is composed of nodes and links. Each link represents a relationship between two values represented as nodes. The effectiveness of a network diagram can be defined by the sizing, coloring, spacing, and clustering of nodes and links. -

Visual Analytics for Making Smarter Decisions Faster Applying Self-Service Business Intelligence Technologies to Data-Driven Objectives
TDWI RESEARCH THIRD QUARTER 2015 TDWI BEST PRACTICES REPORT Visual Analytics for Making Smarter Decisions Faster Applying Self-Service Business Intelligence Technologies to Data-Driven Objectives By David Stodder tdwi.org Research Sponsors Research Sponsors IBM Information Builders Oracle Qlik SAP SAS Tableau Software TIBCO Spotfire TDWI RESEARCH BEST PRACTICES REPORT THIRD QUARTER 2015 Visual Analytics for Table of Contents Making Smarter Research Methodology and Demographics 3 Executive Summary 4 Decisions Faster Breaking Open the Potential of Data 5 Applying Self-Service Business Accelerating toward User Self-Service 5 Intelligence Technologies to Current Satisfaction with Tools and Functionality 7 Data-Driven Objectives Use of Cloud and SaaS Deployment Options 8 By David Stodder Responsibility for Technology Selection and Maintenance 9 BI and Visual Analytics on Mobile: Slight Growth 11 Driving Visual Analytics Expansion: Benefits and Growth 12 BI and Visual Analytics Growth Paths 14 User Experiences with Visual Analytics 17 Visual Interaction with Diverse Data Sources 19 Contribution of In-Memory Computing 20 Data Preparation: Moving toward Self-Service 22 Hadoop and NoSQL Data Sources: Moderate Interest 24 Data Interaction and Collaboration 25 Satisfaction with Dashboards 27 Data Storytelling to Improve Collaboration 27 Data Governance and Business/IT Collaboration 30 Visual Analytics and Decision Management 32 Visualizing Operational Performance 32 Vendor Products 35 Recommendations 38 © 2015 by TDWI, a division of 1105 Media, Inc. All rights reserved. Reproductions in whole or in part are prohibited except by written permission. E-mail requests or feedback to [email protected]. Product and company names mentioned herein may be trademarks and/or registered trademarks of their respective companies. -

Visual Analytics
Visual Analytics Daniel A. Keim, Florian Mansmann, Andreas Stoffel, Hartmut Ziegler University of Konstanz, Germany http://infovis.uni-konstanz.de SYNONYMS Visual Analysis; Visual Data Analysis; Visual Data Mining DEFINITION Visual analytics is the science of analytical reasoning supported by interactive visual interfaces according to [6]. Over the last decades data was produced at an incredible rate. However, the ability to collect and store this data is increasing at a faster rate than the ability to analyze it. While purely automatic or purely visual analysis methods were developed in the last decades, the complex nature of many problems makes it indispensable to include humans at an early stage in the data analysis process. Visual analytics methods allow decision makers to combine their flexibility, creativity, and background knowledge with the enormous storage and processing capacities of today's computers to gain insight into complex problems. The goal of visual analytics research is thus to turn the information overload into an opportunity by enabling decision-makers to examine this massive information stream to take effective actions in real-time situations. HISTORICAL BACKGROUND Automatic analysis techniques such as statistics and data mining developed independently from visualization and interaction techniques. However, some key thoughts changed the rather limited scope of the fields into what is today called visual analytics research. One of the most important steps in this direction was the need to move from confirmatory data analysis to exploratory data analysis, which was first stated in the statistics research community by John W. Tukey in his book \Exploratory data analysis" [7]. Later with the availability of graphical user interfaces with proper interaction devices, a whole research community devoted their efforts to information visualization [1, 2, 5, 8]. -

Developing World-Class Reports with SAS® Visual Analytics® Lucy Smith, Amadeus Software Ltd
Paper 5027-2020 Raising the Bar! Developing World-Class Reports with SAS® Visual Analytics® Lucy Smith, Amadeus Software Ltd ABSTRACT SAS® Visual Analytics 8.x provides around 40 different visuals out of the box. This gives all users, both novice and advanced, a lot of potential ways to present their data. However, as the reporting requirements and dashboards develop, the default visuals might not always be enough. This paper covers three exciting ways to enhance and extend the default visuals in SAS Visual Analytics. The first method starts with default visual and explores options in SAS Visual Analytics to customize the appearance. The second method looks at using the custom graph builder to extend the default visuals to represent your data in the required way. The last method showcases how to include a completely new custom visual to SAS Visual Analytics, using the D3.js JavaScript framework for visualization. This paper is for SAS Visual Analytics users of any ability, and the techniques covered are applicable in SAS Visual Analytics 8.x on SAS® Viya®. INTRODUCTION Whether you are a seasoned SAS Visual Analytics user or have just started using the tool, you will be familiar with the extensive list of out of the box visualizations that are available. The objects tab contains a comprehensive list of graphs to help you present your data in a suitable way. There are also additional objects, called controls, to help you create dynamic graphs and containers to control the layout of your report. Data comes in many different formats so the perfect way to present it may not be possible using the default visuals.