A Novel Mass Spectrometry-Based Proteomic and Phosphoproteomic Strategy for the Quantitative Analysis of a Leukemic Cell Line Infected by an Oncolytic Virus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -
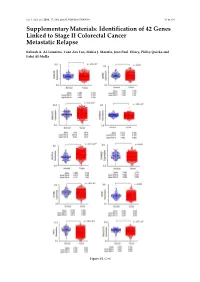
Identification of 42 Genes Linked to Stage II Colorectal Cancer Metastatic Relapse
Int. J. Mol. Sci. 2016, 17, 598; doi:10.3390/ijms17040598 S1 of S16 Supplementary Materials: Identification of 42 Genes Linked to Stage II Colorectal Cancer Metastatic Relapse Rabeah A. Al-Temaimi, Tuan Zea Tan, Makia J. Marafie, Jean Paul Thiery, Philip Quirke and Fahd Al-Mulla Figure S1. Cont. Int. J. Mol. Sci. 2016, 17, 598; doi:10.3390/ijms17040598 S2 of S16 Figure S1. Mean expression levels of fourteen genes of significant association with CRC DFS and OS that are differentially expressed in normal colon compared to CRC tissues. Each dot represents a sample. Table S1. Copy number aberrations associated with poor disease-free survival and metastasis in early stage II CRC as predicted by STAC and SPPS combined methodologies with resident gene symbols. CN stands for copy number, whereas CNV is copy number variation. Region Cytoband % of CNV Count of Region Event Gene Symbols Length Location Overlap Genes chr1:113,025,076–113,199,133 174,057 p13.2 CN Loss 0.0 2 AKR7A2P1, SLC16A1 chr1:141,465,960–141,822,265 356,305 q12–q21.1 CN Gain 95.9 1 SRGAP2B MIR5087, LOC10013000 0, FLJ39739, LOC10028679 3, PPIAL4G, PPIAL4A, NBPF14, chr1:144,911,564–146,242,907 1,331,343 q21.1 CN Gain 99.6 16 NBPF15, NBPF16, PPIAL4E, NBPF16, PPIAL4D, PPIAL4F, LOC645166, LOC388692, FCGR1C chr1:177,209,428–177,226,812 17,384 q25.3 CN Gain 0.0 0 chr1:197,652,888–197,676,831 23,943 q32.1 CN Gain 0.0 1 KIF21B chr1:201,015,278–201,033,308 18,030 q32.1 CN Gain 0.0 1 PLEKHA6 chr1:201,289,154–201,298,247 9093 q32.1 CN Gain 0.0 0 chr1:216,820,186–217,043,421 223,235 q41 CN -

Supplemental Tables A. Miscellaneous Protein/Peptide
Supplemental Tables a. Miscellaneous protein/peptide sequences GST protein MSPILGYWKIKGLVQPTRLLLEYLEEKYEEHLYERDEGDKWRNKKFELG LEFPNLPYYIDGDVKLTQSMAIIRYIADKHNMLGGCPKERAEISMLEGA VLDIRYGVSRIAYSKDFETLKVDFLSKLPEMLKMFEDRLCHKTYLNGDH VTHPDFMLYDALDVVLYMDPMCLDAFPKLVCFKKRIEAIPQIDKYLKSS KYIAWPLQGWQATFGGGDHPPK TEV protease ENLYFQG cleavage site G4S Linker GGGGS b. Cdk phosphorylation site sequences PKTPKKAKKL(H1 PKTPKKAKKL site) Rb775-787(S780) RPPTLSPIPHIPR Rb790-805(S795) GSYKFPSSPLRIPGGNIY c. Cdk substrate docking site sequences RxL docking HTLKGRRLVFDNQLT Helix docking SKFQQKLAEMTSTRTRMQKQK Helix mut. SKAQQKAAEMTSTATRMQKQK docking Reversed Helix KQKQMRTRTSTMEALKQQFKS docking RxL docking HTLKGRRLVFDNQLT d. Full GST-PKTPKKAKKL(H1 site) phosphorylation site fusion protein sequences GST- PKTPKKAKKL(H1 GST-SD-TEV-GS- PKTPKKAKKL(H1 site) site) GST- GST-SD-TEV-GS- PKTPKKAKKL(H1 site)-G4S-RxL docking PKTPKKAKKL(H1 site)+RxL docking GST- GST-SD-TEV-GS- PKTPKKAKKL(H1 site)-G4S-Helix PKTPKKAKKL(H1 docking site)+Helix docking GST- GST-SD-TEV-GS- PKTPKKAKKL(H1 site)-G4S-Helix mut. PKTPKKAKKL(H1 Docking site)+Helix mut. docking 1 e. Full GST-Rb775-787(S780) phosphorylation site fusion protein sequences GST-Rb775- GST-SD-TEV-Rb775-787(S780) 787(S780) GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-G4S-RxL docking 787(S780)+RxL docking GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-G4S-Helix docking 787(S780)+Helix docking GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-G4S-Helix mut. 787(S780)+Helix docking mut. docking GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-RxL docking 787(S780)-no linker+RxL docking GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-G4S-G4S-Helix 787(S780)- docking 2xlinker+Helix docking GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-G4S-G4S-G4S-Helix 787(S780)- docking 3xlinker+Helix docking GST-Rb775- GST-SD-TEV-GS-Rb775-787(S780)-G4S-G4S-G4S-Reversed 787(S780)- Helix docking 3xlinker+reverse d Helix docking f. -

Single Cell Derived Clonal Analysis of Human Glioblastoma Links
SUPPLEMENTARY INFORMATION: Single cell derived clonal analysis of human glioblastoma links functional and genomic heterogeneity ! Mona Meyer*, Jüri Reimand*, Xiaoyang Lan, Renee Head, Xueming Zhu, Michelle Kushida, Jane Bayani, Jessica C. Pressey, Anath Lionel, Ian D. Clarke, Michael Cusimano, Jeremy Squire, Stephen Scherer, Mark Bernstein, Melanie A. Woodin, Gary D. Bader**, and Peter B. Dirks**! ! * These authors contributed equally to this work.! ** Correspondence: [email protected] or [email protected]! ! Supplementary information - Meyer, Reimand et al. Supplementary methods" 4" Patient samples and fluorescence activated cell sorting (FACS)! 4! Differentiation! 4! Immunocytochemistry and EdU Imaging! 4! Proliferation! 5! Western blotting ! 5! Temozolomide treatment! 5! NCI drug library screen! 6! Orthotopic injections! 6! Immunohistochemistry on tumor sections! 6! Promoter methylation of MGMT! 6! Fluorescence in situ Hybridization (FISH)! 7! SNP6 microarray analysis and genome segmentation! 7! Calling copy number alterations! 8! Mapping altered genome segments to genes! 8! Recurrently altered genes with clonal variability! 9! Global analyses of copy number alterations! 9! Phylogenetic analysis of copy number alterations! 10! Microarray analysis! 10! Gene expression differences of TMZ resistant and sensitive clones of GBM-482! 10! Reverse transcription-PCR analyses! 11! Tumor subtype analysis of TMZ-sensitive and resistant clones! 11! Pathway analysis of gene expression in the TMZ-sensitive clone of GBM-482! 11! Supplementary figures and tables" 13" "2 Supplementary information - Meyer, Reimand et al. Table S1: Individual clones from all patient tumors are tumorigenic. ! 14! Fig. S1: clonal tumorigenicity.! 15! Fig. S2: clonal heterogeneity of EGFR and PTEN expression.! 20! Fig. S3: clonal heterogeneity of proliferation.! 21! Fig. -

The Transcriptional and Epigenetic Role of Brd4 in the Regulation of the Cellular Stress Response
THE TRANSCRIPTIONAL AND EPIGENETIC ROLE OF BRD4 IN THE REGULATION OF THE CELLULAR STRESS RESPONSE INAUGURAL-DISSERTATION to obtain the academic degree Doctor rerum naturalium (Dr. rer. nat.) submitted to the Department of Biology, Chemistry and Pharmacy of Freie Universität Berlin by Michelle Hussong from Zweibrücken 2015 Die vorliegende Arbeit wurde im Zeitraum von Juli 2012 bis September 2015 am Max- Planck-Institut für Molekulare Genetik in Berlin sowie an der Universität zu Köln unter der Leitung von Frau Prof. Dr. Dr. Michal-Ruth Schweiger angefertigt. 1. Gutachter: Prof. Dr. Dr. Michal-Ruth Schweiger 2. Gutachter: Prof. Dr. Rupert Mutzel Disputation am 07.12.2015 ACKNOWLEDGMENT ACKNOWLEDGMENT This dissertation would not have been possible without the guidance and the help of many people who in one way or another contributed to the preparation and completion of this study. Firstly, I would like to express my sincere gratitude to my advisor Prof. Dr. Dr. Michal-Ruth Schweiger, for her continuous support throughout my PhD study, for her patience, motivation, and immense knowledge. I am eminently thankful for the multiple possibilities she gave me to work on this interesting and challenging field of research. I also want to thank Professor Dr. Rupert Mutzel for taking the time of being my second supervisor. My sincere thanks also goes to Prof. Dr. Hans Lehrach for having given me the opportunity to do my PhD thesis in the extraordinary and inspiring environment at the Max-Planck- Institute for Molecular Genetics in Berlin. Especially, the multitude of technologies and knowledge in his department made my work successful. -

Insulin and Glucose Alter Death-Associated Protein Kinase 3 (DAPK3) DNA Methylation
Page 1 of 89 Diabetes Insulin and glucose alter death-associated protein kinase 3 (DAPK3) DNA methylation in human skeletal muscle Jonathan M. Mudry1, David G. Lassiter1, Carolina Nylén1, Sonia García-Calzón2, Erik Näslund3, Anna Krook2, Juleen R. Zierath1,2,4. Running title: DAPK3 DNA methylation in human skeletal muscle 1Department of Molecular Medicine and Surgery, Integrative Physiology, Karolinska Institutet, Stockholm, Sweden. 2Department of Physiology and Pharmacology, Integrative Physiology, Karolinska Institutet, Stockholm, Sweden. 3Division of Surgery, Department of Clinical Sciences, Danderyd Hospital, Karolinska Institutet, Stockholm, Sweden. 4Section of Integrative Physiology, The Novo Nordisk Foundation Center for Basic Metabolic Research, Faculty of Health and Medical Science, University of Copenhagen, Copenhagen, Denmark. Juleen R. Zierath Department of Molecular Medicine and Surgery, Section of Integrative Physiology, Karolinska Institutet, von Eulers väg 4a, SE 171 77 Stockholm, Sweden Phone: +46 (0)8 524 87581 Fax: +46 (0) 8 33 54 36 E-mail: [email protected] Diabetes Publish Ahead of Print, published online December 23, 2016 Diabetes Page 2 of 89 Abstract DNA methylation is altered by environmental factors. We hypothesized DNA methylation is altered in skeletal muscle in response to either insulin or glucose exposure. We performed a genome-wide DNA methylation analysis in muscle from healthy men before and after insulin exposure. DNA methylation of selected genes was determined in muscle from healthy and type 2 diabetic men before and after a glucose tolerance test. Insulin altered DNA methylation in the 3’UTR of the calcium pump ATP2A3 gene. Insulin increased DNA methylation in the gene body of DAPK3, a gene involved in cell proliferation, apoptosis and autophagy. -

Antibody Tools Immunohistochemistry
Antibody Tools Immunohistochemistry $$ 250 - 150 - 100 - 75 - 50 - 37 - Western Blot 25 - 20 - 15 - 10 - 1.4 1.2 1 0.8 0.6 OD 450 0.4 Sandwich ELISA 0.2 0 0.01 0.1 1 10 100 1000 Recombinant Protein Concentration(mg/ml) Immunohistochemistry Immunofluorescence 1 2 3 250 - 150 - 100 - 75 - 50 - Immunoprecipitation 37 - 25 - 20 - 15 - 100 80 60 % of Max 40 Flow Cytometry 20 0 3 4 5 0 102 10 10 10 www.abnova.com March 2013 (Sixth Edition) Abnova Corporation www.abnova.com Email: [email protected] Address: 9F, No. 108, Jhouzih St., Neihu, Taipei 114, Taiwan Tel: + 886 2 8751 1888 Fax: + 886 2 6602 1218 Antibodies tool for IHC, Class I IVD (In Vitro Diagnostics) Cat. Num. DH0003 DH0013 DH0020 DH0015 Product Name Anti-ACTN4 monoclonal antibody Anti-ANXA5 monoclonal antibody Anti-CDH17 monoclonal antibody Anti-CLDN1 monoclonal antibody Application Immunoperoxidase of monoclonal antibody Immunoperoxidase of monoclonal antibody to Immunoperoxidase of monoclonal antibody to Immunoperoxidase of monoclonal antibody to to ACTN4 on formalin-fixed paraffin- ANXA5 on formalin-fixed paraffin-embedded CDH17 on formalin-fixed paraffin-embedded CLDN1 on formalin-fixed paraffin-embedded embedded human pancreatic cancer. [antibody human colon cancer. [antibody concentration 3 human colon cancer. [antibody concentration 3 human colon cancer. [antibody concentration 3 concentration 1.5 ug/ml] ug/ml] ug/ml] ug/ml] Cat. Num. DH0002 DH0021 DH0010 DH0017 Product Name Anti-CTH monoclonal antibody Anti-EGR1 monoclonal antibody Anti-EIF2C2 monoclonal antibody Anti-ENO1 monoclonal antibody Application Immunoperoxidase of monoclonal antibody Immunoperoxidase of monoclonal antibody Immunoperoxidase of monoclonal antibody to Immunoperoxidase of monoclonal antibody to CTH on formalin-fixed paraffin-embedded to EGR1 on formalin-fixed paraffin-embedded EIF2C2 on formalin-fixed paraffin-embedded to ENO1 on formalin-fixed paraffin-embedded human liver. -
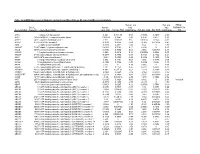
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

Nucleosome-Interacting Proteins Regulated by DNA and Histone Methylation
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Spiral - Imperial College Digital Repository Nucleosome-Interacting Proteins Regulated by DNA and Histone Methylation Till Bartke1, Michiel Vermeulen2,3, Blerta Xhemalce1, Samuel C. Robson1, Matthias Mann2, and Tony Kouzarides1,* 1The Gurdon Institute and Department of Pathology, Tennis Court Road, Cambridge, CB2 1QN, UK 2Department of Proteomics and Signal Transduction, Max-Planck-Institute for Biochemistry, D-82152 Martinsried, Germany 3Current Address: Department of Physiological Chemistry and Cancer Genomics Centre, University Medical Center Utrecht, Utrecht, The Netherlands *Correspondence: [email protected] 1 Abstract Modifications on histones or on DNA recruit proteins that regulate chromatin function. Here we use nucleosomes methylated on DNA and on histone H3 in an affinity assay, in conjunction with a SILAC-based proteomic analysis, to identify “cross-talk” between these two distinct classes of modification. Our analysis reveals proteins whose binding to nucleosomes is regulated by methylation of CpGs, H3K4, H3K9, and H3K27 or a combination thereof. We identify the Origin Recognition Complex (ORC), including LRWD1 as a subunit, to be a methylation-sensitive nucleosome interactor which is recruited cooperatively by DNA and histone methylation. Other interactors, such as the lysine demethylase Fbxl11/KDM2A, recognise nucleosomes methylated on histones but their recruitment is disrupted by DNA methylation. These data establish SILAC nucleosome affinity purifications (SNAP) as a tool for studying the dynamics between different chromatin modifications and provide a modification binding “profile” for proteins regulated by DNA and histone methylation. 2 Introduction Most of the genetic information of eukaryotic cells is stored in the nucleus in the form of a nucleoprotein complex termed chromatin. -

WO 2016/070129 Al 6 May 2016 (06.05.2016) W P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2016/070129 Al 6 May 2016 (06.05.2016) W P O P C T (51) International Patent Classification: (74) Agent: BAKER, C , Hunter; Wolf, Greenfield & Sacks, A61K 9/00 (2006.01) C07K 14/435 (2006.01) P.C., 600 Atlantic Avenue, Boston, MA 02210-2206 (US). (21) International Application Number: (81) Designated States (unless otherwise indicated, for every PCT/US20 15/058479 kind of national protection available): AE, AG, AL, AM, AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, (22) International Filing Date: BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, 30 October 2015 (30.10.201 5) DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, (25) Filing Language: English HN, HR, HU, ID, IL, IN, IR, IS, JP, KE, KG, KN, KP, KR, KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, MG, (26) Publication Language: English MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, OM, (30) Priority Data: PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, SC, 14/529,010 30 October 2014 (30. 10.2014) US SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (71) Applicant: PRESIDENT AND FELLOWS OF HAR¬ VARD COLLEGE [US/US]; 17 Quincy Street, Cam (84) Designated States (unless otherwise indicated, for every bridge, MA 02138 (US). -

UC San Francisco Electronic Theses and Dissertations
UCSF UC San Francisco Electronic Theses and Dissertations Title Toward drugging the translocon: sequence determinants and cellular consequences Sec61 inhibition Permalink https://escholarship.org/uc/item/9610t3s7 Author Maglathlin, Rebecca Publication Date 2014 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Copyright (2014) By Rebecca L. Maglathlin ii Acknowledgements “In the discovery of secret things, and in the investigation of hidden causes, stronger reasons are obtained from sure experiments and demonstrated arguments than from probable conjectures and the opinions of philosophical speculators.” -William Gilbert, Loadstone and Magnetic Bodies, and on The Great Magnet of the Earth, translated from the 1600 edition of De Magnete by P. Fleury Mottelay (Bernard Quaritch, London, 1893) I would like to thank my mentor, Jack Taunton, for instilling in me that “good” is never enough and that greatness is just as much a matter of hard work and perseverance as it is a function of intelligence and insight. I would like to thank Jeff Johnson and Tasha Johnson for their work on the mass spectrometry in Chapter 2. I would also like to thank Gonzalo Ureta and Emma McCullagh of Sebastian Bernales’ Lab (Fundacion Ciencia de la Vida, Chile) for their work cited in Chapter 3. I would like to thank the members of the Taunton Lab, past and present, for their insights, expertise, friendship and general all around awesomeness. I would specifically like to thank Ville, Sarah and Andy for their guidance on this project and for their beautiful work cited herein. I would also like to thank Geoff Smith for his contribution of the STAT5 phosphorylation experiment in Chapter 2.