STATISTICAL ANALYSIS of PROFESSIONAL GOLF PLAYER ABILITIES Based on the Selection in the Ryder Cup
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PGA TOUR Player/Manager List
2016 PGA TOUR Player/Manager List Generated On: 2/17/2016 - A - ADAMS, Blake - 1 Degree Management, LLC AIKEN, Thomas - Wasserman Media Group - London ALLEM, Fulton - Players Group, Inc ALLENBY, Robert - MVP, Inc. ALLEN, Michael - Medalist Management, Inc. ALLRED, Jason - 4U Management, LLC AL, Geiberger, - Cross Consulting AMES, Stephen - Wasserman Media Group - Canada ANCER, Abraham - The Legacy Agency ANDERSON, Mark - Blue Giraffe Sports ANDRADE, Billy - 4Sports & Entertainment ANGUIANO, Mark - The Legacy Agency AOKI, Isao - High Max APPLEBY, Stuart - Blue Giraffe Sports ARAGON, Alex - Wasserman Media Group - VA ARMOUR III, Tommy - Tommy Armour, III, Inc. ARMOUR, Ryan - IMG ATKINS, Matt - a3 Athletics AUSTIN, Woody - The Legacy Agency AXLEY, Eric - a3 Athletics AZINGER, Paul - TCP Sports Management, LLC A., Jimenez, Miguel - Marketing and Management International - B - BADDELEY, Aaron - Pro-Sport Management BAEK, Todd - Hambric Sports Management BAIRD, Briny - Pinnacle Enterprises, Inc. BAKER-FINCH, Ian - IMG Media BAKER, Chris - 1 Degree Management, LLC BALLO, JR., Mike - Lagardere Sports BARBER, Blayne - IMG BARLOW, Craig - The Legacy Agency BARNES, Ricky - Lagardere Sports BATEMAN, Brian - Lagardere Sports - GA BEAUFILS, Ray - Wasserman Media Group - VA BECKMAN, Cameron - Wasserman Media Group - VA BECK, Chip - Tour Talent BEEM, Rich - Marketing and Management International BEGAY III, Notah - Freeland Sports, LLC BELJAN, Charlie - Meister Sports Management BENEDETTI, Camilo - The Legacy Agency BERGER, Daniel - Excel Sports Management BERTONI, Travis - Medalist Management, Inc. BILLY, Casper, - Pinnacle Enterprises, Inc. BLAUM, Ryan - 1 Degree Management, LLC BLIXT, Jonas - Lagardere Sports - FL BOHN, Jason - IMG BOLLI, Justin - Blue Giraffe Sports BOWDITCH, Steven - Players Group, Inc BOWDITCH, Steven - IMG BRADLEY, Keegan - Lagardere Sports - FL BRADLEY, Michael - Lagardere Sports BREHM, Ryan - Wasserman Media Group - Wisconsin BRIGMAN, D.J. -

2013 AMPC Rd 3 Notes
2013 World Golf Championships-Accenture Match Play Championship (The 8th of 36 events in the PGA TOUR Season) Marana, Ariz. Feb. 18-24, 2012 Purse: $8,750,000 ($1,500,000 to the winner) The Golf Club at Dove Mountain Par/Yards: 36-36 – 72/7,791 Third-Round Notes – Saturday, February 23, 2013 Weather A cold start with temperatures in the low to mid-30s and areas of frost. Frost forced a 45-minute delay of tee times. Sunny skies and warmer temperatures in the afternoon with highs reaching the low to mid-60s. Winds NE 5-10 mph. Breakdown of the field of 64 players, by country: To start the first round: After the third round: International players: 43 International players: 3 U.S. players: 21 U.S. players: 5 Countries represented: 17 Countries represented: 4 Largest international contingent: South Africa (7) Largest international contingent: 3 with 1 each Winners by country (Number of players initially in the field in parentheses) United States (21) Lee Westwood (R1) Denmark (2) Matt Kuchar David Lynn (R1) Thorbjorn Olesen (R2) Hunter Mahan Chris Wood (R1) Thomas Bjorn (R1) Robert Garrigus Justin Rose (R2) Steve Stricker Luke Donald (R2) Ireland (2) Webb Simpson Padraig Harrington (R1) Rickie Fowler (R1) Sweden (5) Shane Lowry (R3) Tiger Woods (R1) Henrik Stenson (R1) Jason Dufner (R1) Carl Pettersson (R2) Italy (2) Keegan Bradley (R1) Peter Hanson (R2) Francesco Molinari (R1) Dustin Johnson (R1) Aleander Noren (R2) Matteo Manassero (R1) Zach Johnson (R1) Fredrick Jacobson (R3) Bil Haas (R1) Northern Ireland (2) Ryan Moore (R1) Australia (4) Graeme McDowell David Toms (R1) Jason Day Rory McIlroy (R1) Bo Van Pelt (R2) Adam Scott (R1) Russell Henley (R2) John Senden (R1) Belgium (1) Charles Howell III (R2) Marcus Fraser (R2) Nicolas Colsaerts (R3) Jim Furyk (R2) Nick Watney (R2) Scotland (3) Japan (1) Scott Piercy (R3) Paul Lawrie Hiroyuki Fujita (R1) Bubba Watson (R3) Stephen Gallacher Richie Ramsay South Korea (1) South Africa (7) K.J. -

10 March 2021 Official Pro-Am Players Championship Hosted at Dainfern Golf Estate
Players Championship hosted at Dainfern Golf Estate Official Pro-Am 10 March 2021 Tee Professional Amateur Professional Amateur Time Tee Professional Amateur Professional Amateur 1 Jacques Blaauw Mike Kennedy James Kingston Rob Tregoning 10:30 10 Ruan Conradie Kieran Bell Jayden Schaper Mark Bell 1 Merrick Bremner Kevin Wylie Jacques Kuyswijk Johan Liebenberg 10:40 10 Andre De Decker Eugene Honey Deon Germishuys Naoki Nakamura 1 Michael Palmer Ross Volk JJ Senekal Dean Butts 10:50 10 Stephen Ferreira Sebastian Thomas Ruan Korb Gary Heynz 1 Dylan Naidoo Shamin Jaffer Alex Haindl Miranda Reeder 11:00 10 Jaco Prinsloo Nick Garner Neil Schietekat Don Wolmarans Arnav 1 JC Ritchie Martin Rohwer Dhashen Perumal 11:10 10 Jake Redman Prinesh Pillay Jean-Paul Strydom Sagaren Chetty Jhunjhunwala Rourke van der 1 Jean Hugo Selwyn Nathan Daniel van Tonder Leonard Loxton 11:20 10 Thriston Lawrence Jan van der Putten Adam Beadon Spuy 1 Daniel Greene Thomas Abt Steve Surry Jeremy Ord 11:30 10 Rupert Kaminski Laurence Michel PH McIntyre Eddy van Dyk Andrew van der 1 Keith Horne Brian Keats Toto Thimba Jnr Savan Marimuthu 11:40 10 Richard Joubert Bert Nel Shaun Nel Knaap Dewald 1 Hennie Otto Jason Dedekind Jaco Ahlers 11:50 10 Jason Smith Peter Carey MJ Viljoen Randy Westraadt Gelderblom 1 CJ du Plessis Allan E Bennett Paul Boshoff Louis Boshoff 12:00 10 Oliver Bekker Hjalmar Bekker Luca Filipi Kevin Diab 1 Jaco Van Zyl Dion Nair Keenan Davidse Grant Mc Cann 12:10 10 Adilson Da Silva Mike Clatworthy Trevor Fisher Jnr Terence Ladner Richard 1 Christiaan Basson Luke Jerling Gabriel Reeder 12:20 10 Andriessen . -

Golf Foundation JGM Newsletter Issue 58 Final 02/12/2016 12:16 Page 1
Golf Foundation JGM Newsletter Issue 58_Final 02/12/2016 12:16 Page 1 Issue 58 November 2016 The Golf Foundation helps young people to ‘Start, Learn and Stay’ in the sport, with ambitious targets Photo: Leaderboard Photography Leaderboard Photo: 40,000 extra youngsters visiting clubs The Golf Foundation team is pleased girls from different backgrounds per year in a encourage 50,000 extra youngsters through with progress this year but seeks to raise unique community to club pathway. Having a the gates of a golf club each year via HSBC the bar further in 2017 in our purpose to beginning often with golf in school, the system Golf Roots, with 15,000 playing regular golf make the benefits of golf available to any helps the young person find a start in club from there. young person and to help them ‘Start, golf through expert PGA Professional Learn and Stay’ in the sport. As a charity, supervision, playing regularly and attaining The great news is that in the year up to we passionately believe that golf should that first handicap. March 2016 we are very much on track, be a game open to all and our HSBC though much more work needs to be done. Golf Roots programme is underpinned The Foundation team is working hard with its This charity encouraged 40,000 extra by this, one of our core values. partners to recruit and retain more players youngsters to go through the gates of a club and we have ambitious targets in this area. In in England in the last year and 14,000 HSBC Golf Roots reaches 500,000 boys and England, by 2018, the charity is looking to continue to play regularly. -

Oklahoma State Golf - in the News Location Stillwater, Oklahoma 74078 HONORS Founded Dec
TABLE OF CONTENTS COWBOY GOLF HISTORY 1 Table of Contents • Quick Facts • Credits 126 OSU at the NCAA Championships CREDITS 2 2014-15 Roster • 2014-15 Schedule 128 NCAA Champion Teams The Oklahoma State University Men’s Golf Guide 3 Primary Media Outlets 138 Year-By-Year NCAA Tournament was written and edited by Coordinator of Athletic 4 OSU Golf History 150 School-by-School Consecutive NCAA Appearances Media Relations Ryan Cameron and Alan Bratton, 6 Cowboy Scholarship Endowment 151 NCAA Tournament Success Head Coach. It was designed and produced by Grant 7 Cowboy Pro-Am 152 NCAA Championship Finishes Hawkins Design. 8 Karsten Creek Golf Club 153 OSU at Conference Championships 12 Karsten Creek Donors 154 Individual Big Eight Tournament Finishes Karsten Creek photos were taken by Mike Klemme, 13 Karsten Creek Hole-by-Hole 155 Individual Big 12 Tournament Finishes Golfoto/provided by Henebry Photography; and, 15 Cowboy Golf Coaches 156 Conference Tournament Team Records Chris Carroll. Action photos provided by Kevin 16 Solheim Tribute 157 OSU at the NCAA Regional Allen, Kohler Co.; Jeremy Cook, OSU; Terry Harris, 17 This Is Oklahoma State University 158 Individual Regional Finishes Ardmore; Mike Holder, OSU; Will Hart, NCAA Photos; Craig Jenkins, GCAA; Tony Sargent, Stillwater; COACHES RECORDS James Schammerhorn, OSU; Steve Spatafore, 20 Alan Bratton, Head Coach 160 Individual Records Sportography; Sideline Sports; Brian Tirpak, Western 22 Brian Guetz, Assistant Coach 161 Year-by-Year Individual Leaders Kentucky; Golf Coaches Association of America; The 23 Jake Manzelmann, Speed, Strength & Conditioning 161 Miscellaneous Individual Stats Daily Oklahoman; the PGA Tour and Matt Deason, 23 Ryan Cameron, Coordinator of Media Relations 162 All-Time Most Rounds in the 60s Doug Healey, Monte Mahan, Sandy Marucci, Brad 24 Mike McGraw – 2005-2013 163 Year-by-Year Team Statistics Payne, Ed Robinson, Phil Shockley and Paul 26 Mike Holder – 1973-2005 163 Team Season Records Rutherford; Tina Uihlein, USGA. -

PLAYERS GUIDE — Shinnecock Hills Golf Club | Southampton, N.Y
. OP U.S EN SHINNECOCK HILLS TH 118TH U.S. OPEN PLAYERS GUIDE — Shinnecock Hills Golf Club | Southampton, N.Y. — June 14-17, 2018 conducted by the 2018 U.S. OPEN PLAYERS' GUIDE — 1 Exemption List SHOTA AKIYOSHI Here are the golfers who are currently exempt from qualifying for the 118th U.S. Open Championship, with their exemption categories Shota Akiyoshi is 183 in this week’s Official World Golf Ranking listed. Birth Date: July 22, 1990 Player Exemption Category Player Exemption Category Birthplace: Kumamoto, Japan Kiradech Aphibarnrat 13 Marc Leishman 12, 13 Age: 27 Ht.: 5’7 Wt.: 190 Daniel Berger 12, 13 Alexander Levy 13 Home: Kumamoto, Japan Rafael Cabrera Bello 13 Hao Tong Li 13 Patrick Cantlay 12, 13 Luke List 13 Turned Professional: 2009 Paul Casey 12, 13 Hideki Matsuyama 11, 12, 13 Japan Tour Victories: 1 -2018 Gateway to The Open Mizuno Kevin Chappell 12, 13 Graeme McDowell 1 Open. Jason Day 7, 8, 12, 13 Rory McIlroy 1, 6, 7, 13 Bryson DeChambeau 13 Phil Mickelson 6, 13 Player Notes: ELIGIBILITY: He shot 134 at Japan Memorial Golf Jason Dufner 7, 12, 13 Francesco Molinari 9, 13 Harry Ellis (a) 3 Trey Mullinax 11 Club in Hyogo Prefecture, Japan, to earn one of three spots. Ernie Els 15 Alex Noren 13 Shota Akiyoshi started playing golf at the age of 10 years old. Tony Finau 12, 13 Louis Oosthuizen 13 Turned professional in January, 2009. Ross Fisher 13 Matt Parziale (a) 2 Matthew Fitzpatrick 13 Pat Perez 12, 13 Just secured his first Japan Golf Tour win with a one-shot victory Tommy Fleetwood 11, 13 Kenny Perry 10 at the 2018 Gateway to The Open Mizuno Open. -
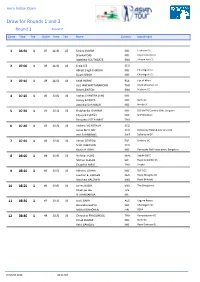
Draw for Rounds 1 and 2 Round 1 Round 2
Hero Indian Open Draw for Rounds 1 and 2 Round 1 Round 2 Game Time Tee Game Time Tee Name Country Attachment 1 06:50 1 37 11:30 10 Sanjay KUMAR IND Lucknow Gc Shankar DAS IND Royal Calcutta GC Matthew SOUTHGATE ENG Thorpe Hall GC 2 07:00 1 38 11:40 10 Craig LEE SCO Abhijit Singh CHADHA IND Chandigarh GC Sujjan SINGH IND Chandigarh GC 3 07:10 1 39 11:50 10 Keith HORNE RSA Eye of Africa Jazz JANEWATTANANOND THA Black Mountain GC Steve LEWTON ENG Woburn GC 4 07:20 1 40 12:00 10 Yashas CHANDRA (AM) IND Honey BAISOYA IND Delhi GC Amardip Sinh MALIK IND Noida GC 5 07:30 1 41 12:10 10 Shubhankar SHARMA IND DLF Golf & Country Club, Gurgaon Edouard ESPAÑA FRA Golf Bordelais Panuphol PITTAYARAT THA 6 07:40 1 42 12:20 10 Andrew MCARTHUR SCO Jamie MCLEARY SCO Dalmahoy Hotel & Country Club Jens FAHRBRING SWE Sollentuna GK 7 07:50 1 43 12:30 10 Adrian OTAEGUI ESP Goiburu GC Scott JAMIESON SCO Khalin H JOSHI IND Karnataka Golf Association, Bengaluru 8 08:00 1 44 12:40 10 Nicholas FUNG MAS Sabah G&CC Mithun PERERA SRI Royal Colombo GC Chapchai NIRAT THA Singha 9 08:10 1 45 12:50 10 Abhinav LOHAN IND DLF GCC Joachim B. HANSEN DEN Royal Mougins GC Matthew BALDWIN ENG Royal Birkdale 10 08:20 1 46 13:00 10 James BUSBY ENG The Shropshire Chieh-po LEE TPE N THANGARAJA SRI 11 08:30 1 47 13:10 10 Scott BARR AUS Laguna Resort Harendra GUPTA IND Chandigarh GC Mikko KORHONEN FIN DEFA 12 08:40 1 48 13:20 10 Chinnarat PHADUNGSIL THA Rumpaipanny GC Vinod KUMAR IND Delhi GC Rahil GANGJEE IND Royal Calcutta GC 15 March 2016 08:13 AM Hero Indian Open Draw for Rounds -
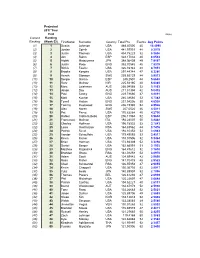
Current Ranking Projected 2017 Year End Ranking (Week 52) Firstname
Projected 2017 Year End Playing Current Ranking Ranking (Week 52) FirstName Surname Country Total Pts Events Avg Points (1) 1 Dustin Johnson USA 468.40505 45 10.4090 (2) 2 Jordan Spieth USA 441.97951 48 9.2079 (3) 3 Justin Thomas USA 434.75223 52 8.3606 (4) 4 Jon Rahm ESP 322.17032 40 8.0543 (5) 5 Hideki Matsuyama JPN 388.06439 49 7.9197 (6) 6 Justin Rose ENG 352.70545 45 7.8379 (7) 7 Rickie Fowler USA 326.16344 48 6.7951 (8) 8 Brooks Koepka USA 297.44344 47 6.3286 (9) 9 Henrik Stenson SWE 259.65729 44 5.9013 (11) 10 Sergio Garcia ESP 249.2501 44 5.6648 (10) 11 Rory McIlroy NIR 225.54165 40 5.6385 (13) 12 Marc Leishman AUS 266.04568 52 5.1163 (12) 13 Jason Day AUS 211.81394 42 5.0432 (14) 14 Paul Casey ENG 229.78666 47 4.8891 (15) 15 Matt Kuchar USA 246.38665 52 4.7382 (16) 16 Tyrrell Hatton ENG 231.54236 50 4.6308 (17) 17 Tommy Fleetwood ENG 236.73385 52 4.5526 (18) 18 Alex Noren SWE 207.0526 46 4.5011 (19) 19 Pat Perez USA 170.82268 40 4.2706 (20) 20 Rafael Cabrera Bello ESP 206.11968 52 3.9638 (21) 21 Francesco Molinari ITA 192.24007 50 3.8448 (23) 22 Charley Hoffman USA 196.78533 52 3.7843 (22) 23 Louis Oosthuizen RSA 164.89562 44 3.7476 (24) 24 Patrick Reed USA 192.10453 52 3.6943 (25) 25 Xander Schauffele USA 179.49093 52 3.4517 (26) 26 Kevin Kisner USA 174.01506 52 3.3464 (27) 27 Brian Harman USA 172.93339 52 3.3256 (28) 28 Daniel Berger USA 162.86991 51 3.1935 (29) 29 Matthew Fitzpatrick ENG 164.47612 52 3.1630 (30) 30 Branden Grace RSA 161.04258 52 3.0970 (31) 31 Adam Scott AUS 124.69842 42 2.9690 (33) 32 Ross Fisher ENG 141.70478 -

2020 PGA Championship TPC Harding Park Final Round Pairings and Starting Times Sunday, August 9, 2020
2020 PGA Championship TPC Harding Park Final Round Pairings and Starting Times Sunday, August 9, 2020 TEE # 1 7:00 Sung Kang Republic of Korea 70 71 76 217 7:10 Ryan Palmer Colleyville, TX 74 66 76 216 Jordan Spieth Dallas, TX 73 68 76 217 7:20 Chez Reavie Scottsdale, AZ 71 70 75 216 J.T. Poston Sea Island, GA 67 74 75 216 7:30 Erik van Rooyen South Africa 71 70 74 215 Matt Wallace England 71 70 74 215 7:40 Danny Lee New Zealand 69 71 74 214 Robert MacIntyre Scotland 73 67 74 214 7:50 Adam Long St. Louis, MO 73 68 72 213 Bubba Watson Bagdad, FL 70 71 73 214 8:00 Joost Luiten Netherlands 71 68 73 212 Rory Sabbatini Slovakia 71 70 72 213 8:10 Kevin Streelman Wheaton, IL 69 70 73 212 Viktor Hovland Norway 68 71 73 212 8:20 Jim Herman Palm City, FL 71 69 72 212 Gary Woodland Topeka, KS 67 72 73 212 8:30 Tiger Woods Jupiter, FL 68 72 72 212 Tom Hoge Fargo, ND 72 68 72 212 8:40 Sepp Straka Austria 70 71 71 212 Byeong Hun An Republic of Korea 72 69 71 212 8:50 Billy Horschel Ponte Vedra Beach, FL 69 71 71 211 Abraham Ancer Mexico 69 70 72 211 9:00 Phil Mickelson Rancho Santa Fe, CA 72 69 70 211 Russell Henley Columbus, GA 71 69 71 211 9:10 Luke List Augusta, GA 72 69 70 211 Mark Hubbard Denver, CO 70 71 70 211 9:20 Bud Cauley Palm Beach Gardens, FL 66 71 73 210 Louis Oosthuizen South Africa 70 71 70 211 9:30 Brian Harman Sea Island, GA 68 71 71 210 Brandt Snedeker Nashville, TN 72 66 72 210 9:50 Kurt Kitayama Chico, CA 68 72 70 210 Rory McIlroy N. -

OMEGA Mission Hills World Cup Field Country Player Player Argentina
OMEGA Mission Hills World Cup Field Country Player Player Argentina Tano Goya Rafa Echenique Australia Robert Allenby* Stuart Appleby* Brazil Rafael Barcello Ronaldo Francisco Canada Graeme DeLaet Stuart Anderson Chile Martin Ureta Hugo Leon China Liang Wen-Chong Zhang Lian-Wei Chinese Taipei Lin Wen-Tang Lu Wei-Chih Denmark Soren Hansen Soren Kjeldsen England Ian Poulter* Ross Fisher** France Thomas Levet Christian Cevaer Germany Martin Kaymer Alex Cejka* India Jeev Milkha Singh** Jyoti Randhawa Ireland Rory McIlroy** Graeme McDowell** Italy Francesco Molinari Edoardo Molinari Japan Ryuji Imada* Hiroyuki Fujita New Zealand David Smail Danny Lee Pakistan Muhammad Munir Muhammad Shabbir Philippines Angelo Que Marc Pucay Republic of Korea Y.E. Yang* Charlie Wi* Scotland David Drysdale Alastair Forsyth Singapore Lam Chih Bing Mardan Mamat South Africa Rory Sabbatini* Richard Sterne Spain Sergio Garcia* Gonzalo Fernandez-Castano Sweden Henrik Stenson Robert Karlsson Thailand Thongchai Jaidee Prayad Marksaeng United States Nick Watney* John Merrick* Venezuela Jhonattan Vegas*** Alfredo Adrian Wales Stephen Dodd Jamie Donaldson * PGA TOUR Member ** Special Temporary PGA TOUR Member *** Nationwide Tour Member OMEGA Mission Hills World Cup Pre-Tournament Notes Alex Cejka is representing Germany at the World Cup for the ninth time and third in succession. He has played in all three previous World Cups held at Mission Hills’ Olazabal Course, as well as the 1995 tournament at the Nicklaus Course. Cejka’s previous-best finish at the event was Germany’s tie for fourth in 1997 with Sven Struver at Kiawah Island, SC. This is the third consecutive year Cejka and Martin Kaymer have teamed together. -
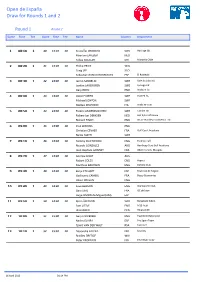
Draw for Rounds 1 and 2 Open De España
Open de España Draw for Rounds 1 and 2 Round 1 Round 2 Game Time Tee Game Time Tee Name Country Attachment 1 08:10 1 40 13:10 10 Kristoffer BROBERG SWE Haninge GK Maarten LAFEBER NED Felipe AGUILAR CHI Marbella Chile 2 08:20 1 41 13:20 10 Phillip PRICE WAL Craig LEE SCO Sebastian GARCIA RODRIGUEZ ESP El Robledal 3 08:30 1 42 13:30 10 Jarmo SANDELIN SWE Vale do Lobo GC Joakim LAGERGREN SWE Lydinge GK Gary BOYD ENG Woburn GC 4 08:40 1 43 13:40 10 Oscar FLOREN SWE Oijared GC Michael JONZON SWE Matteo DELPODIO ITA RO&CHI-GOLF 5 08:50 1 44 13:50 10 Fredrik ANDERSSON HED SWE Laholm GK Robert-Jan DERKSEN NED Het Ryk Golf Banen Richard FINCH ENG Brian Yeardley Continental Ltd. 6 09:00 1 45 14:00 10 Paul WARING ENG Christian CÉVAËR FRA Golf Court Academy Niclas FASTH SWE 7 09:10 1 46 14:10 10 Tommy FLEETWOOD ENG Formby Hall Ricardo GONZALEZ ARG Handicap Cero Golf Academy Jean-Baptiste GONNET FRA G&CC Cannes Mougins 8 09:20 1 47 14:20 10 Andrew DODT AUS Robert COLES ENG Aspect Matthew BALDWIN ENG DeVere Club 9 09:30 1 48 14:30 10 Borja ETCHART ESP Real club de Negori Guillaume CAMBIS FRA Bussy Guerrantes Oliver WILSON ENG 10 09:40 1 49 14:40 10 Seve BENSON ENG Wentworth Club Gary STAL FRA GC de Lyon Jorge SIMON de Miguel (AM) ESP 11 09:50 1 50 14:50 10 Björn ÅKESSON SWE Barseback G&CC Sam LITTLE ENG M25 Audi JB HANSEN DEN Hillerod GK 12 10:00 1 51 15:00 10 Gary LOCKERBIE ENG Paul Bird Motorsport Nacho ELVIRA ESP Pro Spain Team Tjaart VAN DER WALT RSA Fancourt 13 10:10 1 52 15:10 10 Alexandre KALEKA FRA Marcilly Bradley DREDGE WAL Peter EROFEJEFF -

April 16-18 2018 01
April 16-18 2018 01 Table of Contents Welcome to the eighth celebration of Create@State: A Symposium of Research, Scholarship Schedule . 2 & Creativity, showcasing the quality works of our students from across all of our university’s colleges and disciplines . This venue provides an opportunity for undergraduate and graduate Map . 3 students to present original work to stakeholders and the community in a professional Presentation Schedule . 7 setting . The theme for Create@State 2018 is focused around the STEAM initiative to highlight integration of STEM (Science, Technology, Engineering and Math) with Art + Design . We are Oral & Creative Presentations . 22 excited to welcome Edwin Faughn, our distinguished keynote, as he presents to campus Poster Presentations . 45 and the community the intersection of art, design and science . I am proud of the intellect, creativity and innovation taking place at Arkansas State University . This event is a testament to the rich cocurricular learning experiences that are provided by our outstanding faculty Student Research Ambassadors 2017-2018 mentors . I hope you will participate in as many of the events over the three days as possible . Ashley Schulz Brett Hale Olivia Smith Genevieve Quenum Anna Mears Parker Knapp Best regards, Nathan Baggett Kristian Watson Courtney Cox QianQian Yu Neha Verma Quy Van Cameron Duke Andrew Sustich, Ph .D . Associate Vice Chancellor for Research Student Research Advisory Committee 2017-2018 Katerina Hill . .Neil Griffin College of Business Hilary Schloemer . Neil Griffin College of Business Tina Teague . College of Agriculture, Engineering & Technology Zahid Hossain . College of Agriculture, Engineering & Technology Virginie Rolland . College of Sciences & Mathematics David Saarnio .