Using Fault-Localizing Heat Maps to Help Students Improve Their Code
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Metadefender Core V4.13.1
MetaDefender Core v4.13.1 © 2018 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of Metadefender Core 14 1. Quick Start with Metadefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Scan Files with Metadefender Core 21 2. Installing or Upgrading Metadefender Core 22 2.1. Recommended System Requirements 22 System Requirements For Server 22 Browser Requirements for the Metadefender Core Management Console 24 2.2. Installing Metadefender 25 Installation 25 Installation notes 25 2.2.1. Installing Metadefender Core using command line 26 2.2.2. Installing Metadefender Core using the Install Wizard 27 2.3. Upgrading MetaDefender Core 27 Upgrading from MetaDefender Core 3.x 27 Upgrading from MetaDefender Core 4.x 28 2.4. Metadefender Core Licensing 28 2.4.1. Activating Metadefender Licenses 28 2.4.2. Checking Your Metadefender Core License 35 2.5. Performance and Load Estimation 36 What to know before reading the results: Some factors that affect performance 36 How test results are calculated 37 Test Reports 37 Performance Report - Multi-Scanning On Linux 37 Performance Report - Multi-Scanning On Windows 41 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. Configuring Metadefender Core 50 3.1. Management Console 50 3.2. -

Blue, Bluej and Greenfoot
Kent Academic Repository Full text document (pdf) Citation for published version Kölling, Michael (2016) Lessons from the Design of Three Educational Programming Environments: Blue, BlueJ and Greenfoot. International Journal of People-Oriented Programming, 4 (1). pp. 5-32. ISSN 2156-1796. DOI https://doi.org/10.4018/IJPOP.2015010102 Link to record in KAR http://kar.kent.ac.uk/56662/ Document Version Publisher pdf Copyright & reuse Content in the Kent Academic Repository is made available for research purposes. Unless otherwise stated all content is protected by copyright and in the absence of an open licence (eg Creative Commons), permissions for further reuse of content should be sought from the publisher, author or other copyright holder. Versions of research The version in the Kent Academic Repository may differ from the final published version. Users are advised to check http://kar.kent.ac.uk for the status of the paper. Users should always cite the published version of record. Enquiries For any further enquiries regarding the licence status of this document, please contact: [email protected] If you believe this document infringes copyright then please contact the KAR admin team with the take-down information provided at http://kar.kent.ac.uk/contact.html International Journal of People-Oriented Programming January-June 2015, Vol. 4, No. 1 Table of Contents SIKONL C I T L V PF EP iv Steve Goschnick, Swinburne University of Technology, Melbourne, Australia Leon Sterling, Swinburne University of Technology, Melbourne, Australia -

Java Ide's One-On-One*
DR. J VS. THE BIRD: JAVA IDE'S ONE-ON-ONE* Michael Olan Computer Science and Information Systems Richard Stockton College Pomona, NJ 08240 609-652-4587 [email protected] ABSTRACT An important decision facing instructors of introductory programming courses is the choice of supporting software development tools. Usually this involves selecting an integrated development environment (IDE). BlueJ has received widespread adoption for first year courses that use the Java programming language; however, DrJava is emerging as an alternative. This paper features a comparison of the pedagogical approaches used by BlueJ and DrJava as a guideline for selecting the tool best suited to the teaching style used in the introductory course. 1. INTRODUCTION The choice was simple when text editors and the command line were the only tools for developing programs. That changed with the introduction of integrated development environments (IDE's), and campuses nationwide adopted Borland's Turbo Pascal. Languages also have changed. Pascal was designed as a teaching language, but now academic programs use advanced languages designed for professional software engineers. Making these complex languages accessible to beginning students requires a careful selection of the development environment. This discussion will only include Java, currently the dominant language choice for introductory courses. Let us first consider several levels of tool support in the introductory course sequence: 1) Minimal: A text editor and the command line. 2) Simple IDE: Just the basics, no bells and whistles. 3) Professional IDE: Powerful and feature filled. ___________________________________________ * Copyright © 2004 by the Consortium for Computing Sciences in Colleges. Permission to copy without fee all or part of this material is granted provided that the copies are not made or distributed for direct commercial advantage, the CCSC copyright notice and the title of the publication and its date appear, and notice is given that copying is by permission of the Consortium for Computing Sciences in Colleges. -

Objects First with Java™ a Practical Introduction Using Bluej
Objects First with Java™ A Practical Introduction Using BlueJ David J. Barnes and Michael Kölling University of Kent Sixth Edition Boston Columbus Indianapolis New York San Francisco Hoboken Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montreal Toronto Delhi Mexico City Sao Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo A01_BARN7367_06_SE_FM.indd 1 10/03/16 4:08 pm Contents Foreword xiv Preface xv List of Projects Discussed in Detail in This Book xxv Acknowledgments xxviii Part 1 Foundations of Object Orientation 1 Chapter 1 Objects and Classes 3 1.1 Objects and classes 3 1.2 Creating objects 4 1.3 Calling methods 5 1.4 Parameters 6 1.5 Data types 7 1.6 Multiple instances 8 1.7 State 9 1.8 What is in an object? 10 1.9 Java code 11 1.10 Object interaction 12 1.11 Source code 13 1.12 Another example 15 1.13 Return values 15 1.14 Objects as parameters 16 1.15 Summary 17 Chapter 2 Understanding Class Definitions 21 2.1 Ticket machines 21 2.2 Examining a class definition 23 2.3 The class header 25 2.4 Fields, constructors, and methods 26 2.5 Parameters: receiving data 32 2.6 Assignment 34 A01_BARN7367_06_SE_FM.indd 5 10/03/16 4:08 pm vi | Contents 2.7 Methods 35 2.8 Accessor and mutator methods 36 2.9 Printing from methods 39 2.10 Method summary 42 2.11 Summary of the naïve ticket machine 42 2.12 Reflecting on the design of the ticket machine 43 2.13 Making choices: the conditional statement 45 2.14 A further conditional-statement example 47 2.15 Scope highlighting 48 2.16 Local variables 50 2.17 Fields, parameters, and -

Experiences Using Bluej's Submitter with an Automated Grader
We use BlueJ in our CS1 course Experiences Using BlueJ’s Submitter with an Automated Grader Aggressively objects-first, taught in Java We teach software testing from the very first lab as well Stephen Edwards Virginia Tech We use an automated grading system called Web-CAT Dept. of Computer Science [email protected] Web-CAT accepts submissions via HTTP http://people.cs.vt.edu/~edwards/ http://web-cat.sourceforge.net/ Stephen Edwards BlueJ Day: Experiences Using BlueJ’s Submitter Virginia Tech Web-CAT is a flexible, customizable grading Our strategy for managing submission system that supports test-based assignments definitions has evolved over time Submission.defs format allows BlueJ to include definitions We require students to write tests for everything from a URL, so they can be loaded from anywhere CS1CS1 Our grading system runs student tests on their code, and Sub. DynamicallyHTML Sub. DynamicallyHTML CS2 defs orGenerated! PHP CS2 Performs static analysis (checkstyle, PMD) defs orGenerated! PHP CS3CS3 Tracks code coverage (Clover) First, we used a single web-hosted definitions file Then we let each instructor write their own, and used a Supports “by hand” feedback too top-level file to include them all together Then we modified Web-CAT to dynamically generate Provides feedback in one, integrated HTML report submission.defs for the assignments it knows about Stephen Edwards BlueJ Day: Experiences Using BlueJ’s Submitter Virginia Tech Stephen Edwards BlueJ Day: Experiences Using BlueJ’s Submitter Virginia Tech Student -

Bluej Manual
BlueJ COMPANION MANUAL To accompany Big Java 2e and Java Concepts 4e by Cay Horstmann BRUCE QUIG, Deakin University Based on the BlueJ Tutorial by Michael Kölling John Wiley & Sons, Inc. SENIOR ACQUISITIONS EDITOR Bill Zobrist EDITORIAL ASSISTANT Bridget Morrisey PRODUCTION EDITOR Marsheela Evans MARKETING DEVELOPMENT MANAGER Phyllis Cerys . Book printed and bound by________________. The cover was printed by__________________. This book is printed on acid free paper. ∞ Copyright 2005 John Wiley & Sons, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc. 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978)646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008. To order books or for customer service please, call 1-800-CALL WILEY (225-5945). ISBN 0-471-73712-7 Printed in the United States of America 10 9 8 7 6 5 4 3 2 1 Contents 1 About BlueJ 1 About this manual 2 Scope and audience 2 Feedback 2 2 Installation 3 Installation on Windows 3 Installation on Macintosh 4 Installation on Linux/Unix and other Systems 4 Installation problems 4 3 Getting started – using classes 5 Starting BlueJ 5 Creating the project directory 5 Exploring System classes 5 Creating Library objects 7 Execution 8 4 Writing your own classes 11 Opening an existing project 11 Editing a class 12 Compilation 13 Help with compiler errors 14 Creating objects 14 Adding a Driver class 16 5 Doing a bit more.. -

The Bluej Environment Reference Manual
The BlueJ Environment Reference Manual Version 2.0 for BlueJ Version 2.0 Kasper Fisker Michael Kölling Mærsk Mc-Kinney Moller Institute University of Southern Denmark HOW DO I ... ? – INTRODUCTION ........................................................................................................ 1 ABOUT THIS DOCUMENT................................................................................................................................. 1 RELATED DOCUMENTS.................................................................................................................................... 1 REPORT AN ERROR.......................................................................................................................................... 1 USING THE CONTEXT MENU........................................................................................................................... 1 1 PROJECTS.......................................................................................................................................... 2 1.1 CREATE A NEW PROJECT................................................................................................................... 2 1.2 OPEN A PROJECT ............................................................................................................................... 2 1.3 FIND OUT WHAT A PROJECT DOES .................................................................................................... 2 1.4 COPY A PROJECT .............................................................................................................................. -

Integrated Development Environments
Integrated Development Environments Steven J Zeil February 13, 2013 Contents 1 The Components of an IDE 2 2 IDE Examples 3 3 Eclipse 5 1 Integrated Development Environments IDEs Integrated Develop Environments (IDEs) are software packages that attempt to provide comprehen- sive support for programming • and possible other software development activities .................................... 1 The Components of an IDE The Components of an IDE (minimal) What’s the minimum that we expect in an IDE? • editor • build – maybe no more than compiler invocation – with error messages captured/interpreted/walked by editor • run/execute • debugger .................................... The Components of an IDE (optional) What would we like to see in an IDE? • syntax highlighting & aid in editor • documentation (API) look-up • flexible/configurable build • packaging/deployment options .................................... CS7952 Integrated Development Environments The Components of an IDE (deluxe) What makes us giddy in an IDE? • smart feedback in the editor – learns API of new code – suggestions • coding aids in editor – templates – common refactoring (transformations) • documentation generation • test integration • integration with version ctrl .................................... 2 IDE Examples emacs The *nix swiss army knife of editors, emacs has long functioned as a basic IDE: • syntax-highlighting editor • build support (invokes *nix make) – parses error messages from compilers & other tools • debugger interface • works directly with many version control systems .................................... References, if you are unfamiliar with this: • Compiling in emacs • emacs Debugging mode (CS252) CS7953 Integrated Development Environments emacs Strengths and Weaknesses • highly portable • supports virtually any language you would have a compiler for • even in windowed mode, leans toward keyboard rather than mouse – (not sure if that’s a pro or a con) • outdated interface • high learning curve ................................... -

Object Orientation Through the Lens of Computer Science Education with Some New Implications from Other Subjects Like the Humanities
Technische Universität München Fakultät für Informatik Fachgebiet Didaktik der Informatik Object-Oriented Programming through the Lens of Computer Science Education Marc-Pascal Berges Vollständiger Abdruck der von der Fakultät für Informatik der Technischen Universität München zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften (Dr. rer. nat.) genehmigten Dissertation. Vorsitzender: Univ.-Prof. Dr. Johann Schlichter Prüfer der Dissertation: 1. Univ.-Prof. Dr. Peter Hubwieser 2. Univ.-Prof. Dr. Torsten Brinda, Universität Duisburg-Essen Die Dissertation wurde am 07. April 2015 bei der Technischen Universität München eingereicht und durch die Fakultät für Informatik am 02. Juli 2015 angenommen. Abstract In recent years, the importance of the object-oriented paradigm has changed signifi- cantly. Initially it was mainly used in software engineering, but it is now being used more and more in education. This thesis applies methods of educational assessment and statistics to object-oriented programming and in doing so provides a broad overview of concepts, teaching methods, and the current state of research in this field of computer science. Recently, there have been various trends in introductory courses for object-oriented programming including objects-first and objects-later. Using current pedagogical concepts such as cognitive load theory, conceptual change, and self-directed learning in the context of this work, a teaching approach that dispenses almost entirely of instruction by teachers was developed. These minimally invasive programming courses (MIPC) were carried out in several passes in preliminary courses in the Department of Computer Science at the TU München. The students were confronted with a small programming task just before the first lecture. -

Programming with Python and Java Honors
Randolph Township Schools Randolph High School Programming with Python and Java Honors “Mathematics provides a framework for dealing precisely with notions of ‘what is’. Computation provides a framework for dealing precisely with notions of ‘how to’.” -- Margaret Mead Department of Science, Technology, Engineering, and Math Anthony Emmons, Supervisor Curriculum Committee: Matthew Horner Curriculum Developed: June 2018 Date of Board Approval: September 4th, 2018 1 Randolph Township Schools Randolph High School Table of Contents Section Page(s) Mission Statement and Education Goals – District 3 Affirmative Action Compliance Statement 3 Educational Goals – District 4 Introduction 5 Curriculum Pacing Chart 6 APPENDICES 40 2 Randolph Township Schools Mission Statement We commit to inspiring and empowering all students in Randolph schools to reach their full potential as unique, responsible and educated members of a global society. Randolph Township Schools Affirmative Action Statement Equality and Equity in Curriculum The Randolph Township School district ensures that the district’s curriculum and instruction are aligned to the state’s standards. The curriculum provides equity in instruction, educational programs and provides all students the opportunity to interact positively with others regardless of race, creed, color, national origin, ancestry, age, marital status, affectional or sexual orientation, gender, religion, disability or socioeconomic status. N.J.A.C. 6A:7-1.7(b): Section 504, Rehabilitation Act of 1973; N.J.S.A. 10:5; Title IX, Education Amendments of 1972 3 RANDOLPH TOWNSHIP BOARD OF EDUCATION EDUCATIONAL GOALS VALUES IN EDUCATION The statements represent the beliefs and values regarding our educational system. Education is the key to self-actualization, which is realized through achievement and self-respect. -
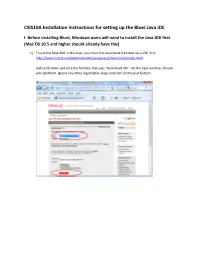
CSIS10A Installation Instructions for Setting up the Bluej Java IDE
CSIS10A Installation Instructions for setting up the BlueJ Java IDE I. Before installing BlueJ, Windows users will need to install the Java JDK first. (Mac OS 10.5 and higher should already have this) 1) To use the BlueJ IDE in this class, you must first download the latest Java JDK. Visit http://www.oracle.com/technetwork/java/javase/downloads/index.html and scroll down and click the first box that says “Download JDK”. On the next window, choose your platform. Ignore any other registration steps and click continue at bottom 2) Another page comes up (below). Click the red link below. 3) You should then find the downloader asking whether to save the file. NOTE: If you are blocking popups in Internet Explorer, you may get a notification at the top of your browser window (blue line below this line). Just click and enable download. When the File Download begins… 4) Choose “Run” and click through all security warnings. Follow the standard install guidelines, keep the default directories and so on. II. Installing the BlueJ Integrated Development Environment 5) Download the appropriate version of BlueJ for your computer at the following link: http://www.bluej.org/download/download.html Go directly to Step 2 below (you have already installed Java JDK) 6) Click on the appropriate platform and choose RUN at the File Download prompt. Click through any security warnings. 7) Close any unnecessary programs and click next. Click all the NEXT buttons in the dialogues that follow, then click INSTALL on the last one. 8) After BlueJ finishes installing, you can now run a test program to make sure it works. -

Greenfoot-Book-TOC-And-Intro.Pdf
Introduction to Programming with Greenfoot Object-Oriented Programming in Java With Games and Simulations Michael Kölling To Krümel and Cracker—may their imagination never fade. —mk Education is not the filling of a pail, but the lighting of a fire. —William Butler Yeats Companion Website Additional material and resources for this book can be found at http://www.greenfoot.org/book/ For students: ! The Greenfoot software ! The scenarios discussed in this book ! The Greenfoot Gallery—a scenario showcase ! Tutorial videos ! A discussion forum ! Technical support For teachers: ! A teacher discussion forum ! Additional exercises related to the book ! The “Green Room” containing worksheets and other teaching resources Table of Contents Acknowledgements 11 Introduction 13 1 Getting to know Greenfoot 15 1.1 Getting started 15 1.2 Objects and classes 17 1.3 Interacting with objects 19 1.4 Return types 21 1.5 Parameters 22 1.6 Greenfoot execution 24 1.7 A second example 25 1.8 Understanding the class diagram 26 1.9 Playing with Asteroids 27 1.10 Source code 28 1.11 Summary 31 2 The first program: Little Crab 33 2.1 The Little Crab scenario 34 2.2 Making the crab move 35 2.3 Turning 36 2.4 Dealing with screen edges 39 2.5 Summary of programming techniques 44 3 Improving the Crab— more sophisticated programming 47 3.1 Adding random behavior 47 3.2 Adding worms 51 3.3 Eating worms 53 3.4 Creating new methods 55 ! Table of Contents | 5 3.5 Adding a Lobster 57 3.6 Keyboard control 58 3.7 Ending the game 60 3.8 Adding sound 63 3.9 Summary of programming