Xbox 360 System Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Second Edition Microsoft Azure Essentials
Fundamentals of Azure Second Edition Microsoft Azure Essentials Michael Collier Robin Shahan PUBLISHED BY Microsoft Press A division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2016 by Michael Collier, Robin Shahan All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. ISBN: 978-1-5093-0296-3 Microsoft Press books are available through booksellers and distributors worldwide. If you need support related to this book, email Microsoft Press Support at [email protected]. Please tell us what you think of this book at http://aka.ms/tellpress. This book is provided “as-is” and expresses the author’s views and opinions. The views, opinions and information expressed in this book, including URL and other Internet website references, may change without notice. Some examples depicted herein are provided for illustration only and are fictitious. No real association or connection is intended or should be inferred. Microsoft and the trademarks listed at http://www.microsoft.com on the “Trademarks” webpage are trademarks of the Microsoft group of companies. All other marks are property of their respective owners. Acquisitions Editor: Devon Musgrave Developmental Editor: Carol Dillingham Editorial Production: Cohesion Copyeditor: Ann Weaver Cover: Twist Creative • Seattle To my wife, Sonja, and sons, Aidan and Logan; I love you more than words can express. I could not have written this book without your immense support and patience. —Michael S. Collier I dedicate this book to the many people who helped make this the best book possible by reviewing, discussing, and sharing their technical wisdom. -

Xbox LIVE Arcade Game Development Katie Stone Perez
Xbox LIVE Arcade Game Development Katie Stone Perez Sr. Game Program Manager Microsoft Endless Fun is Just a Download Away! Agenda What is Xbox LIVE Arcade The Growth of Xbox LIVE Arcade What’s New Portfolio Goals Questions What is Xbox LIVE Arcade? Xbox Live Arcade is a destination for users to download, try and buy broad appeal content on Xbox 360 High-visibility placement in every console (Games Blade) Deep Marketplace integration (download, purchase, licensing) Available to both Silver & Gold Xbox Live Subscribers Arcade-specific banner placements drives awareness of new titles Rich around-the-game feature set drives retention & repeat play What is an Xbox LIVE Arcade Game? Full game experience No pieces of games Must stand on its own Smaller in size <150 MB (most games <50 MB) Playable without physical media or other dependencies No instruction manual required Approachable pickup & play Free Trial Version with limited but entertaining gameplay Must up-sell to unlocked “full” version In-game promotional up-sell Plugs into Xbox Live Arcade around-the-game experiences Out-of-game Leaderboards Achievements & Gamerscore Cross-game invites Growth Of Xbox LIVE Arcade 25M games downloaded Instant hit on the Xbox 360, with nearly 70% of all connected consoles already downloading and playing Xbox LIVE Arcade titles. Widespread recognition of XBLA as a “key differentiator” for Xbox 360 Broad recognition of individual titles Over 600K search results for “Cloning Clyde” or “Assault Heroes” Rapid growth of XBLA publisher ecosystem Ultimately means more great games! Top Arcade Titles to Date Street Fighter II' HF Bankshot Billiards 2 Marble Blast Ultra UNO® DOOM® Xbox LIVE Arcade- What’s Next? Size Limit increase to 150 MB Additional Achievements and Gamerscore for PDLC (Paid Downloadable Content) 3 Additional achievements available for a total of 50 additional Gamerscore. -

Introducing Windows Azure for IT Professionals
Introducing Windows ServerIntroducing Release 2012 R2 Preview Introducing Windows Azure For IT Professionals Mitch Tulloch with the Windows Azure Team PUBLISHED BY Microsoft Press A Division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2013 Microsoft Corporation All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. Library of Congress Control Number: 2013949894 ISBN: 978-0-7356-8288-7 Microsoft Press books are available through booksellers and distributors worldwide. If you need support related to this book, email Microsoft Press Book Support at [email protected]. Please tell us what you think of this book at http://www.microsoft.com/learning/booksurvey. Microsoft and the trademarks listed at http://www.microsoft.com/about/legal/en/us/IntellectualProperty/ Trademarks/EN-US.aspx are trademarks of the Microsoft group of companies. All other marks are property of their respective owners. The example companies, organizations, products, domain names, email addresses, logos, people, places, and events depicted herein are fictitious. No association with any real company, organization, product, domain name, email address, logo, person, place, or event is intended or should be inferred. This book expresses the author’s views and opinions. The information contained in this book is provided without any express, statutory, or implied warranties. Neither the authors, Microsoft Corporation, nor -

Microsoft Azure Essentials Azure Machine Learning
Azure Machine Learning Microsoft Azure Essentials Jeff Barnes Visit us today at microsoftpressstore.com • Hundreds of titles available – Books, eBooks, and online resources from industry experts • Free U.S. shipping • eBooks in multiple formats – Read on your computer, tablet, mobile device, or e-reader • Print & eBook Best Value Packs • eBook Deal of the Week – Save up to 60% on featured titles • Newsletter and special offers – Be the first to hear about new releases, specials, and more • Register your book – Get additional benefits Hear about it first. Get the latest news from Microsoft Press sent to your inbox. • New and upcoming books • Special offers • Free eBooks • How-to articles Sign up today at MicrosoftPressStore.com/Newsletters Wait, there’s more... Find more great content and resources in the Microsoft Press Guided Tours app. The Microsoft Press Guided Tours app provides insightful tours by Microsoft Press authors of new and evolving Microsoft technologies. • Share text, code, illustrations, videos, and links with peers and friends • Create and manage highlights and notes • View resources and download code samples • Tag resources as favorites or to read later • Watch explanatory videos • Copy complete code listings and scripts Download from Windows Store PUBLISHED BY Microsoft Press A division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2015 Microsoft Corporation. All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. ISBN: 978-0-7356-9817-8 Microsoft Press books are available through booksellers and distributors worldwide. -

Windows 10-New Features & Apps
Windows 10-New Features & Apps By Tom Krauser This article discusses some of the new features and apps that come packaged in Windows 10. It is only a brief summary of these features. For more information you can search the internet or check YouTube for instructional videos on your topic of interest. The following links provide some good basic information on Windows 10 and should be helpful to you. https://support.microsoft.com/en-us/products/windows?os=windows-10 https://support.microsoft.com/en-us/help/4043948/windows-10-whats-new-in-fall-creators-update-1709 The following article from PC World Magazine provides articles on a lot of new features in Windows 10. https://www.pcworld.com/tag/windows10/ The following article by CNET discusses some of new features in the latest update to Windows 10. https://www.cnet.com/how-to/windows-10-tips-best-features/ Alarms & Clocks: A combination of alarm clock, world clock, timer, and stopwatch. Set alarms and reminders, check times around the world, and time your activities, including laps and splits. The following link discusses how to set timers, alarms, and stopwatches: https://www.howtogeek.com/225211/how-to-set-timers-alarms-and-stopwatches-in-windows-10/ Camera: Many modern devices with Windows include a webcam and, to use it, you need an app that helps you take pictures, record videos or stream video while video chatting. For this purpose, Microsoft has built an app called Camera, which is available by default in Windows 10. Connect: Use Connect App to Cast Your Smartphone Screen to Your PC. -
Quick Guide Page | 1
Quick Guide Page | 1 Contents Welcome to Windows 10 ................................................................................................................................................................................................... 3 Key innovations ...................................................................................................................................................................................................................... 3 Cortana ................................................................................................................................................................................................................................. 3 Microsoft Edge .................................................................................................................................................................................................................. 4 Gaming & Xbox ................................................................................................................................................................................................................ 5 Built-in apps ....................................................................................................................................................................................................................... 7 Enterprise-grade secure and fast ................................................................................................................................................................................... -
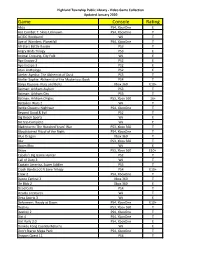
Game Console Rating
Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Abzu PS4, XboxOne E Ace Combat 7: Skies Unknown PS4, XboxOne T AC/DC Rockband Wii T Age of Wonders: Planetfall PS4, XboxOne T All-Stars Battle Royale PS3 T Angry Birds Trilogy PS3 E Animal Crossing, City Folk Wii E Ape Escape 2 PS2 E Ape Escape 3 PS2 E Atari Anthology PS2 E Atelier Ayesha: The Alchemist of Dusk PS3 T Atelier Sophie: Alchemist of the Mysterious Book PS4 T Banjo Kazooie- Nuts and Bolts Xbox 360 E10+ Batman: Arkham Asylum PS3 T Batman: Arkham City PS3 T Batman: Arkham Origins PS3, Xbox 360 16+ Battalion Wars 2 Wii T Battle Chasers: Nightwar PS4, XboxOne T Beyond Good & Evil PS2 T Big Beach Sports Wii E Bit Trip Complete Wii E Bladestorm: The Hundred Years' War PS3, Xbox 360 T Bloodstained Ritual of the Night PS4, XboxOne T Blue Dragon Xbox 360 T Blur PS3, Xbox 360 T Boom Blox Wii E Brave PS3, Xbox 360 E10+ Cabela's Big Game Hunter PS2 T Call of Duty 3 Wii T Captain America, Super Soldier PS3 T Crash Bandicoot N Sane Trilogy PS4 E10+ Crew 2 PS4, XboxOne T Dance Central 3 Xbox 360 T De Blob 2 Xbox 360 E Dead Cells PS4 T Deadly Creatures Wii T Deca Sports 3 Wii E Deformers: Ready at Dawn PS4, XboxOne E10+ Destiny PS3, Xbox 360 T Destiny 2 PS4, XboxOne T Dirt 4 PS4, XboxOne T Dirt Rally 2.0 PS4, XboxOne E Donkey Kong Country Returns Wii E Don't Starve Mega Pack PS4, XboxOne T Dragon Quest 11 PS4 T Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Dragon Quest Builders PS4 E10+ Dragon -

Microsoft Creative Acceptance Policy May 6, 2021
Microsoft Creative Acceptance Policy May 6, 2021 Welcome The Global Microsoft Creative Acceptance Policy is designed to ensure consistently high standards of advertising across all Microsoft media properties and platforms and Microsoft Ad Exchange (MAX) which includes MSN, Windows, Xbox Dash, Outlook.com and syndicated partners worldwide. Consistently high editorial standards align with Microsoft's brand identity and provide a backdrop for quality advertisers and users. Based on this broad charter and a rapidly changing ecosystem, stakeholder engagement across Microsoft drives focus on industry, publisher and brand alignment; resulting in policy definition that ensures a fluid and dynamic approach to high quality ad standards worldwide. Policy Overview The Global Microsoft Creative Acceptance Policy (CAP) applies to advertisements on all Microsoft platforms, Publishers and markets. At any time and for any reason in its sole discretion, Microsoft reserves the right to (i.) refuse any advertising/advertisers; (ii) make exceptions to this policy on a case-by-case basis; and (iii) make changes or add to this policy. Immediate Removal Criteria The following section lists CAP violations that will result in an ad’s immediate removal from the network; all other CAP violations not listed below require a 24-hour SLA to resolve prior to removal. Removal criteria are global unless called out as specific to the US or other country. All publishers/sites Global restrictions for all publishers / sites: • Broken or blank creative • Causing degradation of site performance (ex: excessive animation, file weights) • Misleading or sensationalized messaging, content or images • Illegal materials or content • Morally reprehensible (patently offensive and/or without redeeming social value) • Inappropriate content (ex. -

Xbox Security
Xbox Security The Xbox is a sixth generation video game console produced by Microsoft Corporation. It was Microsoft's first foray into the gaming console market, and competed directly with Sony's PlayStation 2 and the Nintendo GameCube. It was released on November 15, 2001 in North America, February 22, 2002 in Japan, and March 14, 2002 in Europe and Australia. It is the predecessor to Microsoft's Xbox 360 console. The remarkable success of the upstart Sony PlayStation worried Microsoft in late 1990s. The growing video game market seemed to threaten the PC market which Microsoft had dominated and relied upon for most of its revenues. Additionally, a venture into the gaming console market would diversify Microsoft's product line, which up to that time had been heavily concentrated on software. The Xbox was Microsoft's first product that ventured into the video game console market, after having collaborated with Sega in porting Windows CE to the Dreamcast console. Notable launch titles for the console included Halo: Combat Evolved, Amped: Freestyle Snowboarding, Dead or Alive 3, Project Gotham Racing, and Oddworld: Munch's Oddysee. Development The Xbox was initially developed within Microsoft by a small team that included game developer Seamus Blackley (an agent with Creative Artists Agency representing video game creators). Microsoft repeatedly delayed the console, which was revealed at the end of 1999 following interviews of Microsoft CEO Bill Gates. Gates stated that a gaming/multimedia device was essential for multimedia convergence in the new times of digital entertainment. On March 10, 2000 the "X-box Project" was officially confirmed by Microsoft with a press release. -

A Case Study on Merger of Skype and Microsoft
European Journal of Business, Economics and Accountancy Vol. 8, No. 1, 2020 ISSN 2056-6018 VALUATION OF TARGET FIRMS IN MERGERS AND ACQUISITIONS: A CASE STUDY ON MERGER OF SKYPE AND MICROSOFT Nguyen Vuong Bang Tam Thu Dau Mot University VIETNAM [email protected] ABSTRACT Mergers and acquisitions have become the most popular used methods of growth for the company and it’s one of the best ways to make a shortcut to get the success. They create the larger potential market share and open it up to a more diversified market, increase competitive advantage against competitors. It also allows firms to operate more efficiently and benefit both competition and consumers. However, there are also many cases that the synergy between acquiring company and acquired company failed. The most common reason is to not create synergy between both of them. In recent months, the merger between Microsoft and Skype is a very hot topic of analysts and viewers…etc. This acquisition presents a big opportunity for both firms, Skype give Microsoft a boost in the enterprise collaboration. To exchange for this synergy, Microsoft paid $8.5 billion in cash for Skype, the firm is not yet profitable. Skype revenue totaling $860 million last year and operating profit of $264 million, the company lost $6.9 million overall, according to documents filed with the SEC. Is that a good deal for Microsoft? Many analysts have different point of view but most of them have negative perspective. Research was to provide the analysis of Skype’s intrinsic value with an optimistic view of point about Skype’s future, Microsoft overpaid for Skype. -

Games Play Better on Xbox One X | the World's Most Powerful Console
Fact Sheet | June 2017 Games play better on Xbox One X | The world’s most powerful console For gamers that demand the ultimate in graphics performance, Xbox One X is the world’s most powerful console with 40 percent more power than any other console. Games play better on Xbox One X. Xbox One X offers true 4K gaming, HDR and wide color gamut, and default supersampling means even new 4K games will look great on a 1080p screen. Existing Xbox One titles on Xbox One X will look great, run smoothly, and load quickly. Xbox One X works with all your Xbox One games and accessories as well as Xbox Live, the most advanced gaming network, giving you more ways to play. Xbox One X: built for 4K. Xbox One X is built to take advantage of 4K. Watch 4K Ultra HD Blu-ray movies on Xbox One X. Record clips in 4K resolution at 60 frames per second. Experience premiere sound that puts you in the center of spatial audio. High Dynamic Range and Wide Color Gamut provide brilliant graphic details in light, shadow and reflections and 6 teraflops of processing power means games play better than ever before on Xbox One X. Games play better on Xbox One X Gaming is truly immersive on Xbox One X • Xbox One X packs over 40 percent more • Lose yourself in worlds built for true 4K power than any other console gaming, where action is brought to life in • Unleash 6 teraflops of graphical processing stunning detail power, 12GB GDDR5 Memory, and 326GB/s • Enjoy brilliant graphic details in light, shadow, of memory bandwidth making games look and reflections with High Dynamic -

3,000 Xbox 360S on Pre-Sale at Ebay 21 November 2005
3,000 Xbox 360s on pre-sale at eBay 21 November 2005 eBay said Monday almost 3,000 Xbox 360 games are available for pre-sale, ahead of the official sale of the product at midnight Tuesday. The much-anticipated Microsoft game console will be going on sale when the clock strikes midnight nationwide, but the online auction house said about 9,000 Xbox 360s have been pre-sold for the past two weeks. eBay said that the average price sold was $550. Many have been bundled with game cartridges, the company said. Microsoft said Monday over 4,500 retailers nationwide will be opening at midnight Tuesday to sell the Xbox 360 game console. "The debut of Xbox 360 marks one of the biggest consumer launches in Microsoft's history," Robbie Bach, president of the entertainment division, said in a news release. The company said that Best Buy is its retail partner for the Xbox 360 launch events, and its stores will open at 9 a.m. on Nov. 22. In addition, Microsoft said more than 3,500 gamers from around the world descended on an Xbox 360 oasis in California's Mojave Desert Monday night to celebrate the arrival of the console at an exclusive launch party called Xbox 360: Zero Hour. The system launches Dec. 2 in Europe and Dec. 10 in Japan. Copyright 2005 by United Press International APA citation: 3,000 Xbox 360s on pre-sale at eBay (2005, November 21) retrieved 23 September 2021 from https://phys.org/news/2005-11-xbox-360s-pre-sale-ebay.html This document is subject to copyright.