Teaching Cloud Deployment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | Stephenyuan.Urspace.Io Education University of Wisconsin-Madison B.S
WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | stephenyuan.urspace.io Education University of Wisconsin-Madison B.S. in Computer Engineering May 2020 ● GPA: 3.83/4.0 ● Related Coursework: Operating Systems • A rtificial Intelligence • Computer Networks and Communication • Databases • Information Security • Big Data Systems • Android Mobile Development Skills ● Programming Languages: Java • Golang • C++ • Scala • MATLAB • SQL • Julia • C • Python ● Technologies: Git, Linux, Java Spring, Amazon Web Services (AWS), MongoDB, Postgres, React, Node.js, Docker, Jenkins, Play Framework, Hadoop, Spark, Wireshark, Visual Studio Experience Enfusion, Chicago Java Software Developer July 2020 - Current ● Develop the portfolio management software system used by over 500 clients that supports a variety of financial calculation and valuation over 20 financial derivatives as well as back office general ledger and cash flow with more than 10,000 daily positions on average ● Take responsibility in the whole development lifecycle from designing (10%), implementing (40%), running regression & unit testing (40%) to supporting internal and production issues (10%) ● Apply experience of Object-Oriented design patterns and best practices to creating a robust and reliable infrastructure for the system with knowledge of Java SE, Hibernate, JMS, JVM and MySQL and deliver constant results in weekly production release ● Automate development and testing frameworks by writing python and shell scripts to improve overall -

What Is Bluemix
IBM Brings Bluemix to Developers! This document has been prepared for the TMForum Hackathon in Nice, France. The first section of this document shares Bluemix related notes, and it is followed by notes appropriate for viewing content from exposed APIs (provided by TMForum and FIware) then you see the node flows that are available for you. IBM® Bluemix™ is an open-standard, cloud-based platform for building, managing, and running apps of all types, such as web, mobile, big data, and smart devices. Capabilities include Java, mobile back-end development, and application monitoring, as well as features from ecosystem partners and open source—all provided as-a-service in the cloud. Get started with Bluemix: ibm.biz/LearnBluemix Sign up for Bluemix: https://ibm.biz/sitefrbluemix Getting started with run times: http://bluemix.net/docs/# View the catalog and select the mobile cloud boilerplate: http://bluemix.net/#/store/cloudOEPaneId=store Tap into the Internet of Things: http://bluemix.net/#/solutions/solution=internet_of_things Bluemix tutorial in Open Classroom: http://openclassrooms.com/courses/deployez-des-applications- dans-le-cloud-avec-ibm-bluemix This table below can be used for general enablement. It is been useful to developers are previous hackathons. Source Code : Quick Start Technical Asset Name URL/Mobile App Technical Asset Description Guide Uses Node.js runtime, Internet Connected Home Automation ibm.biz/ATTconnhome2 of Things boilerplate, Node-RED ibm.biz/ATTconnhome2qs App editor and MQTT protocol Uses Node.js runtime, Connected -
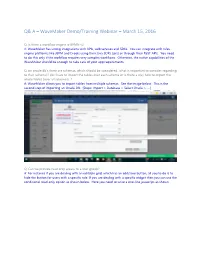
Q& a – Wavemaker Demo/Training Webinar – March 15, 2016
Q& A – WaveMaker Demo/Training Webinar – March 15, 2016 Q: Is there a workflow engine ie BPMN v2 A: WaveMaker has strong integrations with APIs, web services and SDKs. You can integrate with rules engine platforms like JBPM and Drools using their Java SDKs (jars) or through their ReST APIs. You need to do this only if the workflow requires very complex workflows. Otherwise, the native capabilities of the WaveMaker should be enough to take care of your app requirements. Q: on oracle db's there are schemas, which should be considered...what is important to consider regarding to that (schema)? do I have to import the tables over each schema or is there a way how to import the whole tables (over all schemas)...? A: WaveMaker allows you to import tables from multiple schemas. See the image below. This is the second step of importing an Oracle DB. [Steps: Import > Database > Select Oracle > ….] Q: Can we provide read only access to a user group? A: For instance if you are dealing with an editable grid, which has an add/save button, all you to do is to hide the button for users with a specific role. If you are dealing with a specific widget then you can use the conditional read-only option as shown below. Here you need to write a one-line javascript as shown below, where the users with the role “rolename” will be presented a read-only birthdate. Q: Can we integrate the application for SSO ? A: You can configure SSO easily through the following approach. -

Salesforce Heroku Enterprise: a Cloud Security Overview June 2016
Salesforce Heroku Enterprise: A Cloud Security Overview June 2016 1 Contents INTRODUCTION 3 CASESTUDY:GLIBC 19 Heroku behind the Curtain: Patching SALESFORCETRUSTMODEL 4 the glibc Security Hole What Do We Do When a Security CLOUD COMPUTING AND Vulnerability Lands? THESHAREDSECURITYMODEL 5 Provider Responsibilities How Do We Do This with Minimum Downtime? Tenant Responsibilities What about Data? INFRASTRUCTURE AND What about Heroku Itself? APPLICATIONSECURITY 8 Keep Calm, Carry On Server Hardening Customer Applications BUSINESSCONTINUITY 23 Heroku Platform: High Availability Container Hardening and Disaster Recovery Application Security Customer Applications Heroku Flow Postgres Databases Identity and Access Management Customer Configuration and Identity Federation via Single Sign-On Meta-Information Organizations, Roles, and Permissions Service Resiliency and Availability Business Continuity and Emergency NETWORKSECURITY 14 Preparedness Secure Network Architecture Secure Access Points INCIDENTRESPONSE 27 Data in Motion ELEMENTSMARKETPLACE 28 Private Spaces App Permissions Building Secure Applications with Add-Ons DATASECURITY 16 Heroku Postgres PHYSICALSECURITY 29 Encryption Data Center Access Customer Data Retention and Destruction Environmental Controls Management SECURITYMONITORING 17 Storage Device Decommissioning Logging and Network Monitoring DDoS COMPLIANCEANDAUDIT 31 Man in the Middle and IP Spoofing SUMMARY 33 Patch Management HEROKU ENTERPRISE SECURITY WHITE PAPER 2 Introduction eroku Enterprise, a key component of the Salesforce Platform, is a cloud application platform used by organizations of all sizes to deploy and operate applications throughout Hthe world. The Heroku platform is one of the first cloud application platforms delivered entirely as a service, allowing organizations to focus on application development and business strategy while Salesforce and the Heroku division of Salesforce focus on infrastructure management, scaling, and security. -

Cloud Computing: a Taxonomy of Platform and Infrastructure-Level Offerings David Hilley College of Computing Georgia Institute of Technology
Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley College of Computing Georgia Institute of Technology April 2009 Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley 1 Introduction Cloud computing is a buzzword and umbrella term applied to several nascent trends in the turbulent landscape of information technology. Computing in the “cloud” alludes to ubiquitous and inexhaustible on-demand IT resources accessible through the Internet. Practically every new Internet-based service from Gmail [1] to Amazon Web Services [2] to Microsoft Online Services [3] to even Facebook [4] have been labeled “cloud” offerings, either officially or externally. Although cloud computing has garnered significant interest, factors such as unclear terminology, non-existent product “paper launches”, and opportunistic marketing have led to a significant lack of clarity surrounding discussions of cloud computing technology and products. The need for clarity is well-recognized within the industry [5] and by industry observers [6]. Perhaps more importantly, due to the relative infancy of the industry, currently-available product offerings are not standardized. Neither providers nor potential consumers really know what a “good” cloud computing product offering should look like and what classes of products are appropriate. Consequently, products are not easily comparable. The scope of various product offerings differ and overlap in complicated ways – for example, Ama- zon’s EC2 service [7] and Google’s App Engine [8] partially overlap in scope and applicability. EC2 is more flexible but also lower-level, while App Engine subsumes some functionality in Amazon Web Services suite of offerings [2] external to EC2. -

Google App Engine
Basics of Cloud Computing – Lecture 6 PaaS - Platform as a Service Google App Engine Pelle Jakovits 18 March, 2014, Tartu Outline • Introduction to PaaS • Google Cloud • Google AppEngine – DEMO - Creating applications – Available Google Services – Costs & Quotas • Windows Azure PaaS • PaaS Advantages & Disadvantages 2 Cloud Services 3 Platform as a Service - PaaS • Model of Cloud Computing where users are provided with a full platform for their applications • Enables businesses to build and run web-based, custom applications in on -demand fashion • Eliminates the expense and complexity of selecting , purchasing, configuring , and managing the hardware and software. • Provides access to unlimited computing power, decreasing upfront costs dramatically 4 PaaS Characteristics • Multi-tenant architecture • Built-in scalability of deployed software • Integrated with web services and databases • Users are provided with tools to simplify creating and deploying applications • Simplifies prototyping and deploying startup solutions 5 PaaS Characteristics • Users only pay for the service that they use. • More fine grained cost model • Provides tools to handle billing and subscription management • Using PaaS typically results in a vendor lock-in. 6 Types of PaaS • Stand Alone Application Platforms – Typically built on top of an existing IaaS – Provides development tools for designing and deploying software. – Provide all required computing resources and services needed for hosted applications • Social Application Development Platforms – Used to develop addons and internal applications for social websites like Google+ and Facebook. – Integrated API with the social website platform. – Can be seen as extending a SaaS • Open-Computing Platforms – Not tied to a single IaaS provider. – Supports applications that are written in numerous languages and that use any type of database, operating system, and server. -

Cloud Computing Parallel Session Cloud Computing
Cloud Computing Parallel Session Jean-Pierre Laisné Open Source Strategy Bull OW2 Open Source Cloudware Initiative Cloud computing -Which context? -Which road map? -Is it so cloudy? -Openness vs. freedom? -Opportunity for Europe? Cloud in formation Source: http://fr.wikipedia.org/wiki/Fichier:Clouds_edited.jpg ©Bull, 2 ITEA2 - Artemis: Cloud Computing 2010 1 Context 1: Software commoditization Common Specifications Not process specific •Marginal product •Economies of scope differentiation Offshore •Input in many different •Recognized quality end-products or usage standards •Added value is created •Substituable goods downstream Open source •Minimize addition to end-user cost Mature products Volume trading •Marginal innovation Cloud •Economies of scale •Well known production computing •Industry-wide price process levelling •Multiple alternative •Additional margins providers through additional volume Commoditized IT & Internet-based IT usage ©Bull, 3 ITEA2 - Artemis: Cloud Computing 2010 Context 2: The Internet is evolving ©Bull, 4 ITEA2 - Artemis: Cloud Computing 2010 2 New trends, new usages, new business -Apps vs. web pages - Specialized apps vs. HTML5 - Segmentation vs. Uniformity -User “friendly” - Pay for convenience -New devices - Phones, TV, appliances, etc. - Global economic benefits of the Internet - 2010: $1.5 Trillion - 2020: $3.8 Trillion Information Technology and Innovation Foundation (ITIF) Long live the Internet ©Bull, 5 ITEA2 - Artemis: Cloud Computing 2010 Context 3: Cloud on peak of inflated expectations According to -

Openshift Vs Pivotal Cloud Foundry Comparison Red Hat Container Stack - Pivotal Cloud Foundry Stack
OPENSHIFT VS PIVOTAL CLOUD FOUNDRY COMPARISON RED HAT CONTAINER STACK - PIVOTAL CLOUD FOUNDRY STACK 3 AT A GLANCE PIVOTAL CF OPENSHIFT • ●Garden and Diego • ●Docker and Kubernetes • ●.NET and Spring • ●.NET, Spring and JBoss Middleware • ●Only Cloud-native apps (including full Java EE) • ●Container security on Ubuntu • ●Cloud-native and stateful apps • ●Deployment automation • ●Enterprise-grade security on • ●Open Core Red Hat Enterprise Linux • ●Pivotal Labs consulting method • ●Complete Ops Management • ●100% Open Source 5X PRICE • ●Red Hat Innovation Labs consulting method BRIEF COMPARISON PIVOTAL CF OPENSHIFT GARDEN & DIEGO DOCKER & KUBERNETES • ●Garden uses OCI runC backend • ●Portable across all docker platforms • ●Not portable across Cloud Foundry distros • ●IP per container • ●Containers share host IP • ●Integrated image registry • ●No image registry • ●Image build from source and binary • ●Private registries are not supported • ●Adoption in many solutions • ●No image build • ●Adoption only in Cloud Foundry 11 NO NATIVE DOCKER IN CLOUD FOUNDRY Converters Are Terrible Cloud Foundry is based on the Garden container runtime, not Docker, and then has RunC and Windows backends. RunC is not Docker, just the lowest runtime layer Docker Developer Experience Does Not Exist in PCF PCF “cf push” Dev Experience does not exist for Docker. In Openshift v3 we built S2I to provide that same experience on top of native Docker images/containers Diego Is Not Kubernetes Kubernetes has become the defacto standard for orchestrating docker containers. -

What Is Cloud Computing?
Cloud Computing for Nonprofits Executive Summary Written by Afua Bruce February 2020 What is Cloud Computing? Cloud computing can be defined as the rental of someone else‘s computer resources to provide services — applications, infrastructure, security, software, and storage. There are three main categories of cloud computing: infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). CATEGORY INFRASTRUCTURE AS PLATFORM AS A SERVICE SOFTWARE AS A SERVICE A SERVICE Abbreviation IaaS PaaS SaaS Cloud provider Provides the server Maintain system software, Deliver software through an internet responsibilities hardware and a small including upgrades and connection; maintain system amount of storage and patches; tools to manage software and databases; provision networking software to hardware and software user accounts and provide security host applications Example services Amazon Web Services Amazon Web Services (AWS) Office 365, Salesforce, Google Apps, (AWS) Elastic Compute Elastic Beanstalk, Heroku, Asana, Slack, Calendly, Hootsuite Service, Google Microsoft Azure, Cloud Foundry Compute Engine (GCE), Apache CloudStack, OpenStack Positives and Negatives of Cloud Computing The flexibility of cloud computing makes it attractive to nonprofits. As organizations grow or their needs change, rather than continually purchasing new storage capacity to support applications, by leveraging cloud computing, nonprofits can simply request additional space based on current needs and usage. As with all technology, however, -

The Line Download Torrent Spec Ops: the Line Torrent PC Game Free Download
the line download torrent Spec Ops: The Line Torrent PC Game Free Download. Spec Ops: The Line Download For PC. Spec Ops: The Line Download For PC is an action shooter game, That you will play from the point of view of a third person. It is the 10th game in the series of Spec Ops games. The game is set in a virtual open world. And is based on war battels. This game has both single-player and multiplayer modes. Furthermore, it also has an online multiplayer mode. The main character of the game is Captain Martin. In the game, the captain was given a mission after the end of the war. The mission is called the Recon mission. Captain Martin creates his force and goes for the mission. Gameplay Of Spec Ops: The Line Highly Compressed. Gameplay Of Spec Ops: The Line Highly Compressed is like war battels gameplay. In which players take control of the main character Captian Martin. The gameplay is set on different levels. The main four difficult missions of the game are Fubar, Combat Op, Walk on the beach, and a Suicide mission. At the start of the game, the player can select only one mission to play. As he passes on a mission then he can unlock other missions. This game also includes various types of powerful weapons. That also helps the player to fight against enemies. The weapons include pistols, Machine guns firearms, and many more. But the player can take two weapons at a time. And can quickly change them during the fight. -

Annual Report 2018
Annual Report 2018 January 2019 In 2018, the Foundation expanded its definition of Cloud Foundry, shifting away from prioritizing the Application Runtime in order to spread awareness of the many projects that comprise Cloud Foundry technologies. This new messaging aligned with the 2018 vision for interoperability, a theme that underpinned all Foundation content. The interoperability of Cloud Foundry was evident across the ecosystem -- in the technologies integrated into the platform itself to the technologies with which Cloud Foundry integrates to form a multi-platform strategy. This year, the Foundation launched a Certified Systems Integrators program, announced new Certified Providers Cloud.gov and SUSE, accepted interoperable projects Eirini and CF Containerization into the Project Management Council and published four research reports -- while planning and hosting two major Summits and six Cloud Foundry Days. Like the platform itself, the Cloud Foundry Foundation has reached a new level of maturity and continues to evolve. Cloud Foundry Foundation Annual Report 2018 2 2018 Highlights TECHNICAL & COMMUNITY • Interoperability: Two new projects were accepted by the Project Management Committees in order to further integrate Kubernetes with Cloud Foundry technologies. CF Containerization, initially developed and donated to the Foundation by SUSE, is designed to package Cloud Foundry BOSH releases into containers and deploy those containers into Kubernetes. Eirini, proposed by IBM and seeing contributions from IBM, SUSE and SAP, is working towards allowing operators and product vendors to use Kubernetes as the underlying container scheduler for the Cloud Foundry Application Runtime. • 2018 Certified Providers: In 2018, Cloud.gov and SUSE joined the list of certified providers of Cloud Foundry, bringing the total to eight -- the other six being Atos, Huawei, IBM, Pivotal, SAP and Swisscom. -

Guide to the Open Cloud Open Cloud Projects Profiled
Guide to the Open Cloud Open cloud projects profiled A Linux Foundation publication January 2015 www.linuxfoundation.org Introduction The open source cloud computing landscape has changed significantly since we published our first cloud guide in October 2013. This revised version adds new projects See also the rise of Linux container and technology categories that have since technology with the advent of Docker gained importance, and in some cases and its emerging ecosystem. You will be radically change how companies approach hard pressed to find an enterprise Linux building and deploying an open source distribution that isn’t yet working on Docker cloud architecture. integration and touting its new container strategy. Even VMware vSphere, Google In 2013, many cloud projects were still Cloud Platform, and Microsoft Azure are working out their core enterprise features rushing to adapt their cloud platforms to the and furiously building in functionality. And open source Docker project. enterprises were still very much in the early stages of planning and testing their public, This rapid pace of innovation and resulting private or hybrid clouds–and largely at the disruption of existing platforms and vendors orchestration layer. can now serve as a solid case study for the role of open source software and Now, not only have cloud projects collaboration in advancing the cloud. consistently (and sometimes dramatically) grown their user and developer Other components of the cloud infrastructure communities, lines of code and commits have also followed suit, hoping to harness over the past year, their software is the power of collaboration. The Linux increasingly enterprise-ready.