Similarity-Based Visualization of Large Image Collections
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2018-12 Internet/Email SIG Notes Click Here to Return to the Computer Club’S Website
12/6/2018 2018-12 Internet/Email SIG Notes - Google Docs 2018-12 Internet/Email SIG Notes Click here to return to the Computer Club’s Website IT Guy Shares The Funniest Requests He Got That Made Him Laugh Out Loud Sebastian from Germany share s his worst work stories, and they’re so ridiculous, they make grandmas look like hackers. From incompetent managers to clueless users, Sebastian has seen it all. After all, he’s been working in IT for 15 years. Now, he’s an IT administrator for multiple global companies. “If there is one thing that you can count on, then it’s the stupidity of users,” Sebastian told Bored Panda. “Unfortunately, [it’s evident] every day… not kidding!” Why is the Computer Club’s Website marked as “ not secure” Security has been one of Chrome’s core principles since the beginning—we’re constantly working to keep you safe as you browse the web. Nearly two years ago, we announced that Chrome would eventually mark all sites that are not encrypted with HTTPS as “not secure”. This makes it easier to know whether your personal information is safe as it travels across the web, whether you’re checking your bank account or buying concert tickets . Starting today , (July 24, 2018) we’re rolling out these changes to all Chrome users. Chrome’s new password manager stops you from using the same password for every website Google is releasing an entire new design for Chrome today with new features and tweaks to the browser’s overall appearance. -
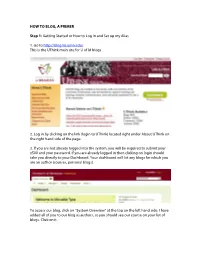
How to Blog, a Primer
HOW TO BLOG, A PRIMER Step 1: Getting Started or How to Log In and Set up my Alias 1. Go to http://blog.lib.umn.edu/ This is the UThink main site for U of M blogs. 2. Log in by clicking on the link (login to UThink) located right under About UThink on the right hand side of the page. 3. If you are not already logged into the system, you will be required to submit your x500 and your password. If you are already logged in then clicking on login should take you directly to your Dashboard. Your dashboard will list any blogs for which you are an author (courses, personal blogs). To access our blog, click on “System Overview” at the top on the left hand side. I have added all of you to our blog as authors, so you should see our course on your list of blogs. Click on it. 4. Now you should be on the author page for our blog. This is where you can create entries, upload files, and edit entries. 5. For those of you who haven’t used UThink before: You can set up your own alias for posting. This means that when you post an entry or a make a comment, only your alias will show (not your email address or your name). As the blog administrator, I will be the only person who knows that it is you posting. If you are a little nervous about posting, this is a good way to stay somewhat anonymous. To set up your alias, click on the link in the upper right-hand corner of the screen that says, Hi x500 number (in the image above, the link says Hi puot0002). -
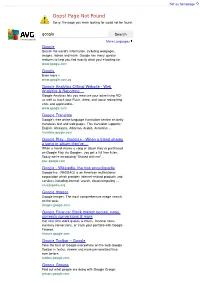
Google Search Secure Search More Languages Google Search the World's Information, Including Webpages, Images, Videos and More
Set as homepage Oops! Page Not Found Sorry, the page you were looking for could not be found. google Search Secure Search More Languages Google Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for. www.google.com Google Even more » www.google.com.sg Google Analytics Official Website - Web Analytics & Reporting ... Google Analytics lets you measure your advertising ROI as well as track your Flash, video, and social networking sites and applications. www.google.com Google Translate Google's free online language translation service instantly translates text and web pages. This translator supports: English, Afrikaans, Albanian, Arabic, Armenian ... translate.google.com Google Play - Google + - When a friend shares a song or album they’ve ... When a friend shares a song or album they’ve purchased on Google Play via Google+, you get a full free listen. Today we’re introducing "Shared with me",… plus.google.com Google - Wikipedia, the free encyclopedia Google Inc. (NASDAQ) is an American multinational corporation which provides Internet-related products and services, including Internet search, cloud computing ... en.wikipedia.org Google Images Google Images. The most comprehensive image search on the web. images.google.com Google Finance: Stock market quotes, news, currency conversions & more Get real-time stock quotes & charts, financial news, currency conversions, or track your portfolio with Google Finance. finance.google.com Google Toolbar – Google Take the best of Google everywhere on the web Google Toolbar is faster, sleeker and more personalized than ever before. toolbar.google.com Google Groups Find out what people are doing with Google Groups groups.google.com Next google Search More Languages © 2012 - Privacy. -

Adding an Image Two Different Ways: 1. Click the Frame Twice A. Choose “Image Only”, Located at the Bottom of the Frame B
Adding an Image Two different ways: 1. Click the frame twice a. Choose “Image only”, located at the bottom of the frame b. Choose “Replace Image” c. You are given two locations to find images; Google Images or browse your folders i. Google images (type your topic into the Google Search Bar) ii. Double click the image that you want to insert OR i. Browse your files to find the image that you want ii. Double click the image that you want to insert d. Make sure that it is added to the path OR 2. Click “Insert” at the top of the Prezi screen a. Choose “Image” b. Again you are given two locations to find images; Google Images or browse your folders i. Google images (type your topic into the Google Search Bar) ii. Double click the image that you want to insert OR i. Browse your files to find the image that you want ii. Double click the image that you want to insert c. Make sure to add it to the path Inserting a Video Two different ways: 1. Click Insert at the top of the Prezi screen a. Select “Youtube Video” b. Insert the Youtube link c. Click “Insert” d. Resize and place the Youtube clip wherever you like e. Make sure that it is added as a path OR 2. Click Insert at the top of the Prezi screen a. Select “From File (PDF, video)…” i. Note: this is how you would insert a PDF b. Navigate to where your video is saved c. -
Using Google Images to Find One of Our Images
Trying to find one of our images Using Google Images to find if either our exclusive image or picture library appears as a source when searching for one of our images… We chose this licensable image as featured on our website, with the tag “wild cocktails” to see where it appeared on Google Images http://www.loupeimages.com/-/galleries/food/wild-cocktails/ 1. Conducting a simple search using the same term “wild cocktails” from a collection of images we have exclusive rights to in our picture library. The search highlights the book covers, followed by the following images: 2 magazine uses; 1 blog use; 1 retail use; 1 Pinterest use (see slides 19-20.) However none show the picture library source, where you can legitimately license the image 2. Google Images - Framing: Frames the image (above), showing image details: tagline; web page; file size 000 x 000 (see slide 3.); Search by image (see slides 4-6.), Image title Plus buttons: Visit page (see slide 7.); View image (see slide 8.); Share (see slide 9.); Related images (see above) Plus footer (with small font size): Images may be subject to copyright | Get help | Send feedback 3. Google Images - File Size: Shows 5 examples and where they point to. The images are ranked by file size showing the largest first Again none show the picture library or image source 4. Google Images - Search by Image: Part 1 shows info, including Visually similar images However none of these are sourced from the picture library website 5. Google Images - Search by Image: Part 2 (3 slides) shows website pages that include matching images (22 examples) showing a mix of magazine & newspaper publishers, retailer, social media sites, and unauthorised commercial sites This is an example of the “framing snowball” for images. -

The Role of Historical Photos in Middle and Secondary History Classes
Georgia State University ScholarWorks @ Georgia State University Middle and Secondary Education Faculty Publications Department of Middle and Secondary Education 2014 Looking at the past for help in the present: The role of historical photos in middle and secondary history classes Jearl Nix Chara H. Bohan Georgia State University Follow this and additional works at: https://scholarworks.gsu.edu/mse_facpub Part of the Curriculum and Instruction Commons, and the Junior High, Intermediate, Middle School Education and Teaching Commons Recommended Citation Nix, Jearl and Bohan, C.H. (2014). Looking at the past for help in the present: The role of historical photos in middle and secondary history classes. Ohio Social Studies Review, 51(2), 13–22. This Article is brought to you for free and open access by the Department of Middle and Secondary Education at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Middle and Secondary Education Faculty Publications by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. LOOKING AT THE PAST FOR HELP IN THE PRESENT: THE ROLE OF HISTORICAL PHOTOS IN MIDDLE AND SECONDARY HISTORY CLASSES Jearl Nix and Chara Bohan, Georgia State University Abstract The purpose of this article is to provide guidance on how teachers can introduce historical photographs to their history class. Werner (2002) argues that visual texts are no longer simple tools that enhance the look of a written text, but are central to student learning. We (one author is a veteran social studies teacher and the other author is an education professor) specifically address Werner’s call for social studies educators to teach students how to be critical readers of visual texts. -

In the United States District Court for the Northern District of Georgia Atlanta Division
Case 1:19-cv-05362-JPB Document 1 Filed 11/25/19 Page 1 of 103 IN THE UNITED STATES DISTRICT COURT FOR THE NORTHERN DISTRICT OF GEORGIA ATLANTA DIVISION INFORM INC., ) ) Plaintiff, ) CIVIL ACTION FILE ) vs. ) ) GOOGLE LLC; ) NO. ______________________ ) GOOGLE INC.; ) ALPHABET INC.; ) YOUTUBE, LLC; ) YOUTUBE, INC.; ) JURY TRIAL DEMANDED and JOHN DOES 1-100; ) ) ) Defendants. ) ) ) COMPLAINT Plaintiff Inform, Inc. (“Inform”), by and through its attorneys, brings this action against Defendants Google LLC, Google Inc., Alphabet Inc., YouTube, LLC, YouTube, Inc., and John Does 1-100 (collectively “Defendants” or “Google”). Inform makes its allegations upon personal knowledge as to its own acts and upon information and belief as to all other matters, as well as based upon the ongoing investigation of its counsel. Plaintiff respectfully shows the Court as follows: Case 1:19-cv-05362-JPB Document 1 Filed 11/25/19 Page 2 of 103 I. INTRODUCTION 1. This is an action under, inter alia, the Sherman Antitrust Act, the Clayton Antitrust Act, and Georgia’s common law tort of tortious interference to restrain the anticompetitive conduct of Defendants, to remedy the effects of the Defendants’ past unlawful conduct, to protect free market competition from continued unlawful manipulation, and to remedy harm to consumers and competitors alike. 2. Plaintiff Inform is a digital media advertising company that for over a decade has directly competed with Google in the online advertising market, specifically online video advertising, by providing a platform of services to online publishers, content creators, and online advertisers. While Inform had revenues in excess of $100 million for its online advertising services between 2014 and 2016, since that time Google has effectively put Inform out of business as a direct result of the illegal conduct described herein. -

August 2021 Userfriendly
August 2021 THE LOS User ANGELES Friendly COMP —UTER The SOCIETY Los Angeles NEWSLETTER Computer Society Volume Page 38 Issue 1 8 August 2021 LACS A Computer and User Friendly Technology User Group IN THIS ISSUE AUGUST 10 GENERAL MEETING Meeting Time: 7:00 – 9 PM – Via Zoom From Your President / Editor 2 General Meeting Report 3 6:30 to 7:00: Socializing and Questions & Answers Topic: Evernote for 2021 Google Voice and Its Many Speaker: Hewie Poplock Uses 5 APCUG Speakers Bureau Interesting Internet Finds 6 Central Florida Computer Society Rubber Bands, Duct Tape, and Sarasota Technology Users Club the Windows Registry 6 LACS Notices 8 Evernote gives you everything you need to keep life orga- LACS Calendar 9 nized—great note-taking, project planning, and easy ways to find what you need, when you need it. You can capture Members Helping Member s 10 anything by adding your notes, photos, files, and to-do Officers, Directors & Leaders 11 lists. You can keep it together by creating a personal Hands-on with Windows 11 12 space for all of your most important ideas and information. CAPTCHA 14 You can find it fast and get the right note, right away with its powerful search and keyword tags. You are able to Casting, Not in the Theatrical sync your notes to all your devices, so they stay with you, Sense 15 even if you are offline. Computer Trivia 16 Meet Our Presenter Special Offers 18 Hewie Poplock is a former APCUG Vice President. He Laughing Out Loud 18 leads the monthly Central Florida Computer Society’s Membership Information 19 online Windows SIG, and he is the CFCS’s APCUG Rep- LACS on Zoom 20 resentative. -

How to Optimize Your Images for Better Seo
HOW TO OPTIMIZE YOUR IMAGES FOR BETTER SEO WHITE PAPER WHITE PAPER How To Optimize Your Images For Better SEO To give your site’s search engine ranking a massive boost, it’s imperative When creating content, it’s important to keep this in mind. The to optimize your images for SEO. In this paper, we’ll take a look at human brain processes visuals 60,000 times faster than text. several SEO tips for your visual content that’ll help drive more traffic to Since our attention spans have become shorter due to our need for your website, ultimately increasing your bottom line. instant gratification, splitting up text-heavy articles with images will But first, here’s a brief explanation why visual content is integral to your increase your chances of a visitor staying on your site rather than web strategy. losing attention and abandoning it. The Importance Of Visual Content Visuals can also help your site’s A picture is not only worth a thousand words, it can be worth SEO, that is, if you do it right. thousands of pageviews. Let’s take a look at some simple We live in a world where visuals dominate. Cameras are more accessible than ever and visual content is a key element on the web SEO tricks you can put into — it adds pizzazz to your content and keep users engaged. In fact, articles with visuals get 94 percent more views than those without. practice to easily enhance the Thanks to the emergence of billions of smartphones worldwide, our SEO of your content. -

GOOGLE MEDIA Education and Skills for the Professional Advertiser
AN INDUSTRY GUIDE TO GOOGLE MEDIA Education and Skills For The Professional Advertiser MODULE 1 American Advertising Federation The Unifying Voice of Advertising OVERVIEW CONTENTS MODULE 1: GOOGLE MEDIA Overview The Marketing Funnel ..................................... 2 The Three Google ............................................ 3 Search ........................................................ 4 LEARNING OBJECTIVES Earned Owned • Have students embrace full scope of world’s largest Paid digital advertising vendor Display Network .......................................... 5 Text Ads Image Ads • Create first-hand understanding of individual Google Rich Media Ads advertising mediums Video Ads ................................................ 6 Video/YouTube ............................................ 7 • Begin to develop a global platform strategy focus for Review ........................................................... 10 digital media Media Platforms ............................................ 15 Google Media Strategies............................... 16 Why You Need to Know This Google Media Pricing .................................... 11 Case Study: JCPenney Optical ..................... 12 It is advertising–with accountability. Student Exercise ........................................... 17 How You Will Use It Google, like most digital media can amplify a traditional advertising media plan or become the entire media effort. Everything you can do in traditional broadcast, print and out-of-home advertising is possible online with -

Canonical Image Selection from the Web
Canonical Image Selection from the Web Yushi Jing1,2 Shumeet Baluja2 Henry Rowley2 [email protected] [email protected] [email protected] College of Computing 1 Google Inc.2 Georgia Institute of Technology 1600 Amphitheater Parkway Atlanta, GA Mountain View, CA ABSTRACT The vast majority of the features used in today’s commer- cially deployed image search systems employ techniques that are largely indistinguishable from text-document search – the images returned in response to a query are based on the text of the web pages from which they are linked. Unfor- tunately, depending on the query type, the quality of this approach can be inconsistent. Several recent studies have demonstrated the effectiveness of using image features to refine search results. However, it is not clear whether (or how much) image-based approach can generalize to larger samples of web queries. Also, the previously used global features often only capture a small part of the image in- formation, which in many cases does not correspond to the distinctive characteristics of the category. This paper ex- plores the use of local features in the concrete task of find- ing the single canonical images for a collection of commonly searched-for products. Through large-scale user testing, the canonical images found by using only local image features significantly outperformed the top results from Yahoo, Mi- crosoft and Google, highlighting the importance of having (a) search results for “d80” these image features as an integral part of future image search engines. Categories and Subject Descriptors H.3.3 [Information Storage and Retrieval]: Informa- tion Search and Retrieval; H.4.m [Information System Applications]: Miscellaneous Keywords web image retrieval, local features 1. -

Complete SEO Training for Photographers
FOREGROUNDWEB Complete SEO training for photographers ALL MY SEO-RELATED CONTENT IN ONE SINGLE PDF: EVERYTHING YOU NEED TO KNOW ABOUT MAKING GOOGLE HAPPY CONTENTS: 2 The complete SEO guide for photographers: 50 tips to maximize your Google rankings & get found online 63 One single SEO tip to rule them all 66 A simpler approach to writing your SEO titles and meta-descriptions 72 Image SEO essentials: How to optimize for Google Image search to drive more traffic to your photography website 92 The photographer’s mini-guide to backlinks: how to create, gain & track links back to your site 97 SEO is no longer a game you can “win” with tags & keywords 99 20 quick tips to reduce your bounce rate & keep visitors on your site longer 104 ForegroundWeb Q&As FOREGROUNDWEB The complete SEO guide for photographers 50 TIPS TO MAXIMIZE YOUR GOOGLE RANKINGS AND GET FOUND ONLINE This is not a shallow list of Google’s ranking factors; that would have been too vague. I wanted to instead gather all photography SEO ideas and turn them into straightforward actions to improve your site in Google’s eyes. Prepare to take some time to go through this entire list and put in the hard work, all toward a photo website that both users and Google will love! This article covers 50 (yes, fifty) SEO actions to go through: • on-site & off-site SEO factors • getting backlinks • website performance & mobile-friendliness • image optimization best practices • free SEO tools • examples & graphics • links to other relevant articles & resources Some of the actions are gathered from my 60+ Photography Website Mistakes guide while others are the result of tens of hours of extensive research.