Real-Time Rendering Algorithm Based on Hybrid Static and Dynamic Simplification Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Table Lens: Merging Graphical and Symbolic Representations in an Interactive Focus+ Context Visualization for Tabular Information
HumanFac(orsinComputingSystems CHI’94 0 “Celebra/i//ghrferdepende)~cc” The Table Lens: Merging Graphical and Symbolic Representations in an Interactive Focus+ Context Visualization for Tabular Information Ramana Rao and Stuart K. Card Xerox Palo Alto Research Center 3333 Coyote Hill Road Palo Alto, CA 94304 Gao,carcM@parc. xerox.com ABSTRACT (at cell size of 100 by 15 pixels, 82dpi). The Table Lens can We present a new visualization, called the Table Lens, for comfortably manage about 30 times as many cells and can visualizing and making sense of large tables. The visual- display up to 100 times as many cells in support of many ization uses a focus+ccmtext (fisheye) technique that works tasks. The scale advantage is obtained by using a so-called effectively on tabular information because it allows display “focus+context” or “fisheye” technique. These techniques of crucial label information and multiple distal focal areas. allow interaction with large information structures by dynam- In addition, a graphical mapping scheme for depicting table ically distorting the spatial layout of the structure according to contents has been developed for the most widespread kind the varying interest levels of its parts. The design of the Table of tables, the cases-by-variables table. The Table Lens fuses Lens technique has been guided by the particular properties symbolic and gaphical representations into a single coherent and uses of tables. view that can be fluidly adjusted by the user. This fusion and A second contribution of our work is the merging of graphical interactivity enables an extremely rich and natural style of representations directly into the process of table visualization direct manipulation exploratory data analysis. -

Army Acquisition Workforce Dependency on E-Mail for Formal
ARMY ACQUISITION WORKFORCE DEPENDENCY ON E-MAIL FOR FORMAL WORK COORDINATION: FINDINGS AND OPPORTUNITIES FOR WORKFORCE PERFORMANCE IMPROVEMENT THROUGH E-MAIL-BASED SOCIAL NETWORK ANALYSIS KENNETH A. LORENTZEN May 2013 PUBLISHED BY THE DEFENSE ACQUISITION UNIVERSITY PRESS PROJECT ADVISOR: BOB SKERTIC CAPITAL AND NORTHEAST REGION, DAU THE SENIOR SERVICE COLLEGE FELLOWSHIP PROGRAM ABERDEEN PROVING GROUND, MD PAGE LEFT BLANK INTENTIONALLY .ARMY ACQUISITION WORKFORCE DEPENDENCY ON E-MAIL FOR FORMAL WORK COORDINATION: FINDINGS AND OPPORTUNITIES FOR WORKFORCE PERFORMANCE IMPROVEMENT THROUGH E-MAIL-BASED SOCIAL NETWORK ANALYSIS KENNETH A. LORENTZEN May 2013 PUBLISHED BY THE DEFENSE ACQUISITION UNIVERSITY PRESS PROJECT ADVISOR: BOB SKERTIC CAPITAL AND NORTHEAST REGION, DAU THE SENIOR SERVICE COLLEGE FELLOWSHIP PROGRAM ABERDEEN PROVING GROUND, MD PAGE LEFT BLANK INTENTIONALLY ii Table of Contents Table of Contents ............................................................................................................................ ii List of Figures ................................................................................................................................ vi Abstract ......................................................................................................................................... vii Chapter 1—Introduction ................................................................................................................. 1 Background and Motivation ................................................................................................. -

Geotime As an Adjunct Analysis Tool for Social Media Threat Analysis and Investigations for the Boston Police Department Offeror: Uncharted Software Inc
GeoTime as an Adjunct Analysis Tool for Social Media Threat Analysis and Investigations for the Boston Police Department Offeror: Uncharted Software Inc. 2 Berkeley St, Suite 600 Toronto ON M5A 4J5 Canada Business Type: Canadian Small Business Jurisdiction: Federally incorporated in Canada Date of Incorporation: October 8, 2001 Federal Tax Identification Number: 98-0691013 ATTN: Jenny Prosser, Contract Manager, [email protected] Subject: Acquiring Technology and Services of Social Media Threats for the Boston Police Department Uncharted Software Inc. (formerly Oculus Info Inc.) respectfully submits the following response to the Technology and Services of Social Media Threats RFP. Uncharted accepts all conditions and requirements contained in the RFP. Uncharted designs, develops and deploys innovative visual analytics systems and products for analysis and decision-making in complex information environments. Please direct any questions about this response to our point of contact for this response, Adeel Khamisa at 416-203-3003 x250 or [email protected]. Sincerely, Adeel Khamisa Law Enforcement Industry Manager, GeoTime® Uncharted Software Inc. [email protected] 416-203-3003 x250 416-708-6677 Company Proprietary Notice: This proposal includes data that shall not be disclosed outside the Government and shall not be duplicated, used, or disclosed – in whole or in part – for any purpose other than to evaluate this proposal. If, however, a contract is awarded to this offeror as a result of – or in connection with – the submission of this data, the Government shall have the right to duplicate, use, or disclose the data to the extent provided in the resulting contract. GeoTime as an Adjunct Analysis Tool for Social Media Threat Analysis and Investigations 1. -

Canonical View Volumes
University of British Columbia View Volumes Canonical View Volumes Why Canonical View Volumes? CPSC 314 Computer Graphics Jan-Apr 2016 • specifies field-of-view, used for clipping • standardized viewing volume representation • permits standardization • restricts domain of z stored for visibility test • clipping Tamara Munzner perspective orthographic • easier to determine if an arbitrary point is perspective view volume orthographic view volume orthogonal enclosed in volume with canonical view y=top parallel volume vs. clipping to six arbitrary planes y=top x=left x=left • rendering y y x or y x or y = +/- z x or y back • projection and rasterization algorithms can be Viewing 3 z plane z x=right back 1 VCS front reused front plane VCS y=bottom z=-near z=-far x -z x z=-far plane -z plane -1 x=right y=bottom z=-near http://www.ugrad.cs.ubc.ca/~cs314/Vjan2016 -1 2 3 4 Normalized Device Coordinates Normalized Device Coordinates Understanding Z Understanding Z near, far always positive in GL calls • convention left/right x =+/- 1, top/bottom y =+/- 1, near/far z =+/- 1 • z axis flip changes coord system handedness THREE.OrthographicCamera(left,right,bot,top,near,far); • viewing frustum mapped to specific mat4.frustum(left,right,bot,top,near,far, projectionMatrix); • RHS before projection (eye/view coords) parallelepiped Camera coordinates NDC • LHS after projection (clip, norm device coords) • Normalized Device Coordinates (NDC) x x perspective view volume orthographic view volume • same as clipping coords x=1 VCS NDCS y=top • only objects -

Inviwo — a Visualization System with Usage Abstraction Levels
IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL X, NO. Y, MAY 2019 1 Inviwo — A Visualization System with Usage Abstraction Levels Daniel Jonsson,¨ Peter Steneteg, Erik Sunden,´ Rickard Englund, Sathish Kottravel, Martin Falk, Member, IEEE, Anders Ynnerman, Ingrid Hotz, and Timo Ropinski Member, IEEE, Abstract—The complexity of today’s visualization applications demands specific visualization systems tailored for the development of these applications. Frequently, such systems utilize levels of abstraction to improve the application development process, for instance by providing a data flow network editor. Unfortunately, these abstractions result in several issues, which need to be circumvented through an abstraction-centered system design. Often, a high level of abstraction hides low level details, which makes it difficult to directly access the underlying computing platform, which would be important to achieve an optimal performance. Therefore, we propose a layer structure developed for modern and sustainable visualization systems allowing developers to interact with all contained abstraction levels. We refer to this interaction capabilities as usage abstraction levels, since we target application developers with various levels of experience. We formulate the requirements for such a system, derive the desired architecture, and present how the concepts have been exemplary realized within the Inviwo visualization system. Furthermore, we address several specific challenges that arise during the realization of such a layered architecture, such as communication between different computing platforms, performance centered encapsulation, as well as layer-independent development by supporting cross layer documentation and debugging capabilities. Index Terms—Visualization systems, data visualization, visual analytics, data analysis, computer graphics, image processing. F 1 INTRODUCTION The field of visualization is maturing, and a shift can be employing different layers of abstraction. -

COMPUTER GRAPHICS COURSE Viewing and Projections
COMPUTER GRAPHICS COURSE Viewing and Projections Georgios Papaioannou - 2014 VIEWING TRANSFORMATION The Virtual Camera • All graphics pipelines perceive the virtual world Y through a virtual observer (camera), also positioned in the 3D environment “eye” (virtual camera) Eye Coordinate System (1) • The virtual camera or “eye” also has its own coordinate system, the eyeY coordinate system Y Eye coordinate system (ECS) Z eye X Y X Z Global (world) coordinate system (WCS) Eye Coordinate System (2) • Expressing the scene’s geometry in the ECS is a natural “egocentric” representation of the world: – It is how we perceive the user’s relationship with the environment – It is usually a more convenient space to perform certain rendering tasks, since it is related to the ordering of the geometry in the final image Eye Coordinate System (3) • Coordinates as “seen” from the camera reference frame Y ECS X Eye Coordinate System (4) • What “egocentric” means in the context of transformations? – Whatever transformation produced the camera system its inverse transformation expresses the world w.r.t. the camera • Example: If I move the camera “left”, objects appear to move “right” in the camera frame: WCS camera motion Eye-space object motion Moving to Eye Coordinates • Moving to ECS is a change of coordinates transformation • The WCSECS transformation expresses the 3D environment in the camera coordinate system • We can define the ECS transformation in two ways: – A) Invert the transformations we applied to place the camera in a particular pose – B) Explicitly define the coordinate system by placing the camera at a specific location and setting up the camera vectors WCSECS: Version A (1) • Let us assume that we have an initial camera at the origin of the WCS • Then, we can move and rotate the “eye” to any pose (rigid transformations only: No sense in scaling a camera): 퐌푐 퐨푐, 퐮, 퐯, 퐰 = 퐑1퐑2퐓1퐑ퟐ … . -

Interactive Volume Navigation
IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 4, NO. 3, JULY-SEPTEMBER 1998 243 Interactive Volume Navigation Martin L. Brady, Member, IEEE, Kenneth K. Jung, Member, IEEE, H.T. Nguyen, Member, IEEE, and Thinh PQ Nguyen Member, IEEE Abstract—Volume navigation is the interactive exploration of volume data sets by “flying” the viewpoint through the data, producing a volume rendered view at each frame. We present an inexpensive perspective volume navigation method designed to be run on a PC platform with accelerated 3D graphics hardware. The heart of the method is a two-phase perspective raycasting algorithm that takes advantage of the coherence inherent in adjacent frames during navigation. The algorithm generates a sequence of approximate volume-rendered views in a fraction of the time that would be required to compute them individually. The algorithm handles arbitrarily large volumes by dynamically swapping data within the current view frustum into main memory as the viewpoint moves through the volume. We also describe an interactive volume navigation application based on this algorithm. The application renders gray-scale, RGB, and labeled RGB volumes by volumetric compositing, allows trilinear interpolation of sample points, and implements progressive refinement during pauses in user input. Index Terms—Volume navigation, volume rendering, 3D medical imaging, scientific visualization, texture mapping. ——————————F—————————— 1INTRODUCTION OLUME-rendering techniques can be used to create in- the views should be produced at interactive rates. The V formative two-dimensional (2D) rendered views from complete data set may exceed the system’s memory, but the large three-dimensional (3D) images, or volumes, such as amount of data enclosed by the view frustum is assumed to those arising in scientific and medical applications. -

Computer Graphicsgraphics -- Weekweek 33
ComputerComputer GraphicsGraphics -- WeekWeek 33 Bengt-Olaf Schneider IBM T.J. Watson Research Center Questions about Last Week ? Computer Graphics – Week 3 © Bengt-Olaf Schneider, 1999 Overview of Week 3 Viewing transformations Projections Camera models Computer Graphics – Week 3 © Bengt-Olaf Schneider, 1999 VieViewingwing Transformation Computer Graphics – Week 3 © Bengt-Olaf Schneider, 1999 VieViewingwing Compared to Taking Pictures View Vector & Viewplane: Direct camera towards subject Viewpoint: Position "camera" in scene Up Vector: Level the camera Field of View: Adjust zoom Clipping: Select content Projection: Exposure Field of View Computer Graphics – Week 3 © Bengt-Olaf Schneider, 1999 VieViewingwing Transformation Position and orient camera Set viewpoint, viewing direction and upvector Use geometric transformation to position camera with respect to the scene or ... scene with respect to the camera. Both approaches are mathematically equivalent. Computer Graphics – Week 3 © Bengt-Olaf Schneider, 1999 VieViewingwing Pipeline and Coordinate Systems Model Modeling Transformation Coordinates (MC) Modeling Position objects in world coordinates Transformation Viewing Transformation World Coordinates (WC) Position objects in eye/camera coordinates Viewing EC a.k.a. View Reference Coordinates Transformation Eye (Viewing) Perspective Transformation Coordinates (EC) Perspective Convert view volume to a canonical view volume Transformation Also used for clipping Perspective PC a.k.a. clip coordinates Coordinates (PC) Perspective Perspective Division Division Normalized Device Perform mapping from 3D to 2D Coordinates (NDC) Viewport Mapping Viewport Mapping Map normalized device coordinates into Device window/screen coordinates Coordinates (DC) Computer Graphics – Week 3 © Bengt-Olaf Schneider, 1999 Why a special eye coordinate systemsystem ? In prinicipal it is possible to directly project on an arbitray viewplane. However, this is computationally very involved. -
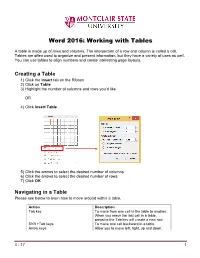
Word 2016: Working with Tables
Word 2016: Working with Tables A table is made up of rows and columns. The intersection of a row and column is called a cell. Tables are often used to organize and present information, but they have a variety of uses as well. You can use tables to align numbers and create interesting page layouts. Creating a Table 1) Click the Insert tab on the Ribbon 2) Click on Table 3) Highlight the number of columns and rows you’d like OR 4) Click Insert Table 5) Click the arrows to select the desired number of columns 6) Click the arrows to select the desired number of rows 7) Click OK Navigating in a Table Please see below to learn how to move around within a table. Action Description Tab key To move from one cell in the table to another. When you reach the last cell in a table, pressing the Tab key will create a new row. Shift +Tab keys To move one cell backward in a table. Arrow keys Allow you to move left, right, up and down. 4 - 17 1 Selecting All or Part of a Table There are times you want to select a single cell, an entire row or column, multiple rows or columns, or an entire table. Selecting an Individual Cell To select an individual cell, move the mouse to the left side of the cell until you see it turn into a black arrow that points up and to the right. Click in the cell at that point to select it. Selecting Rows and Columns To select a row in a table, move the cursor to the left of the row until it turns into a white arrow pointing up and to the right, as shown below. -

Table Understanding Through Representation Learning
TURL: Table Understanding through Representation Learning Xiang Deng∗ Huan Sun∗ Alyssa Lees The Ohio State University The Ohio State University Google Research Columbus, Ohio Columbus, Ohio New York, NY [email protected] [email protected] [email protected] You Wu Cong Yu Google Research Google Research New York, NY New York, NY [email protected] [email protected] ABSTRACT Relational tables on the Web store a vast amount of knowledge. Owing to the wealth of such tables, there has been tremendous progress on a variety of tasks in the area of table understanding. However, existing work generally relies on heavily-engineered task- specific features and model architectures. In this paper, we present TURL, a novel framework that introduces the pre-training/fine- tuning paradigm to relational Web tables. During pre-training, our framework learns deep contextualized representations on relational tables in an unsupervised manner. Its universal model design with pre-trained representations can be applied to a wide range of tasks with minimal task-specific fine-tuning. Specifically, we propose a structure-aware Transformer encoder to model the row-column structure of relational tables, and present a new Masked Entity Recovery (MER) objective for pre-training to capture the semantics and knowledge in large-scale unlabeled data. Figure 1: An example of a relational table from Wikipedia. We systematically evaluate TURL with a benchmark consisting of 6 different tasks for table understanding (e.g., relation extraction, a total of 14.1 billion tables in 2008. More recently, Bhagavatula et al. cell filling). We show that TURL generalizes well to all tasks and [4] extracted 1.6M high-quality relational tables from Wikipedia. -

CSCI 445: Computer Graphics
CSCI 445: Computer Graphics Qing Wang Assistant Professor at Computer Science Program The University of Tennessee at Martin Angel and Shreiner: Interactive Computer Graphics 7E © 1 Addison-Wesley 2015 Classical Viewing Angel and Shreiner: Interactive Computer Graphics 7E © 2 Addison-Wesley 2015 Objectives • Introduce the classical views • Compare and contrast image formation by computer with how images have been formed by architects, artists, and engineers • Learn the benefits and drawbacks of each type of view Angel and Shreiner: Interactive Computer Graphics 7E © 3 Addison-Wesley 2015 Classical Viewing • Viewing requires three basic elements • One or more objects • A viewer with a projection surface • Projectors that go from the object(s) to the projection surface • Classical views are based on the relationship among these elements • The viewer picks up the object and orients it how she would like to see it • Each object is assumed to constructed from flat principal faces • Buildings, polyhedra, manufactured objects Angel and Shreiner: Interactive Computer Graphics 7E © 4 Addison-Wesley 2015 Planar Geometric Projections • Standard projections project onto a plane • Projectors are lines that either • converge at a center of projection • are parallel • Such projections preserve lines • but not necessarily angles • Nonplanar projections are needed for applications such as map construction Angel and Shreiner: Interactive Computer Graphics 7E © 5 Addison-Wesley 2015 Classical Projections Angel and Shreiner: Interactive Computer Graphics 7E -

Openscenegraph 3.0 Beginner's Guide
OpenSceneGraph 3.0 Beginner's Guide Create high-performance virtual reality applications with OpenSceneGraph, one of the best 3D graphics engines Rui Wang Xuelei Qian BIRMINGHAM - MUMBAI OpenSceneGraph 3.0 Beginner's Guide Copyright © 2010 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the authors, nor Packt Publishing and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: December 2010 Production Reference: 1081210 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-849512-82-4 www.packtpub.com Cover Image by Ed Maclean ([email protected]) Credits Authors Editorial Team Leader Rui Wang Akshara Aware Xuelei Qian Project Team Leader Reviewers Lata Basantani Jean-Sébastien Guay Project Coordinator Cedric Pinson