Master's Thesis S.M. Mohsin Reza
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tracking Known Security Vulnerabilities in Third-Party Components
Tracking known security vulnerabilities in third-party components Master’s Thesis Mircea Cadariu Tracking known security vulnerabilities in third-party components THESIS submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in COMPUTER SCIENCE by Mircea Cadariu born in Brasov, Romania Software Engineering Research Group Software Improvement Group Department of Software Technology Rembrandt Tower, 15th floor Faculty EEMCS, Delft University of Technology Amstelplein 1 - 1096HA Delft, the Netherlands Amsterdam, the Netherlands www.ewi.tudelft.nl www.sig.eu c 2014 Mircea Cadariu. All rights reserved. Tracking known security vulnerabilities in third-party components Author: Mircea Cadariu Student id: 4252373 Email: [email protected] Abstract Known security vulnerabilities are introduced in software systems as a result of de- pending on third-party components. These documented software weaknesses are hiding in plain sight and represent the lowest hanging fruit for attackers. Despite the risk they introduce for software systems, it has been shown that developers consistently download vulnerable components from public repositories. We show that these downloads indeed find their way in many industrial and open-source software systems. In order to improve the status quo, we introduce the Vulnerability Alert Service, a tool-based process to track known vulnerabilities in software projects throughout the development process. Its usefulness has been empirically validated in the context of the external software product quality monitoring service offered by the Software Improvement Group, a software consultancy company based in Amsterdam, the Netherlands. Thesis Committee: Chair: Prof. Dr. A. van Deursen, Faculty EEMCS, TU Delft University supervisor: Prof. Dr. A. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Inequalities in Open Source Software Development: Analysis of Contributor’S Commits in Apache Software Foundation Projects
RESEARCH ARTICLE Inequalities in Open Source Software Development: Analysis of Contributor’s Commits in Apache Software Foundation Projects Tadeusz Chełkowski1☯, Peter Gloor2☯*, Dariusz Jemielniak3☯ 1 Kozminski University, Warsaw, Poland, 2 Massachusetts Institute of Technology, Center for Cognitive Intelligence, Cambridge, Massachusetts, United States of America, 3 Kozminski University, New Research on Digital Societies (NeRDS) group, Warsaw, Poland ☯ These authors contributed equally to this work. * [email protected] a11111 Abstract While researchers are becoming increasingly interested in studying OSS phenomenon, there is still a small number of studies analyzing larger samples of projects investigating the structure of activities among OSS developers. The significant amount of information that OPEN ACCESS has been gathered in the publicly available open-source software repositories and mailing- list archives offers an opportunity to analyze projects structures and participant involve- Citation: Chełkowski T, Gloor P, Jemielniak D (2016) Inequalities in Open Source Software Development: ment. In this article, using on commits data from 263 Apache projects repositories (nearly Analysis of Contributor’s Commits in Apache all), we show that although OSS development is often described as collaborative, but it in Software Foundation Projects. PLoS ONE 11(4): fact predominantly relies on radically solitary input and individual, non-collaborative contri- e0152976. doi:10.1371/journal.pone.0152976 butions. We also show, in the first published study of this magnitude, that the engagement Editor: Christophe Antoniewski, CNRS UMR7622 & of contributors is based on a power-law distribution. University Paris 6 Pierre-et-Marie-Curie, FRANCE Received: December 15, 2015 Accepted: March 22, 2016 Published: April 20, 2016 Copyright: © 2016 Chełkowski et al. -
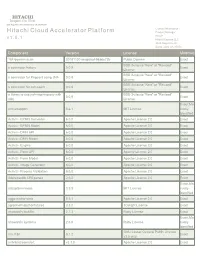
Hitachi Cloud Accelerator Platform Product Manager HCAP V 1
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Cloud Accelerator Platform Product Manager HCAP v 1 . 5 . 1 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified 18F/domain-scan 20181130-snapshot-988de72b Public Domain Exact BSD 3-clause "New" or "Revised" a connector factory 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for Pageant using JNA 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for ssh-agent 0.0.9 Exact License a library to use jsch-agent-proxy with BSD 3-clause "New" or "Revised" 0.0.9 Exact sshj License Exact,Ma activesupport 5.2.1 MIT License nually Identified Activiti - BPMN Converter 6.0.0 Apache License 2.0 Exact Activiti - BPMN Model 6.0.0 Apache License 2.0 Exact Activiti - DMN API 6.0.0 Apache License 2.0 Exact Activiti - DMN Model 6.0.0 Apache License 2.0 Exact Activiti - Engine 6.0.0 Apache License 2.0 Exact Activiti - Form API 6.0.0 Apache License 2.0 Exact Activiti - Form Model 6.0.0 Apache License 2.0 Exact Activiti - Image Generator 6.0.0 Apache License 2.0 Exact Activiti - Process Validation 6.0.0 Apache License 2.0 Exact Addressable URI parser 2.5.2 Apache License 2.0 Exact Exact,Ma adzap/timeliness 0.3.8 MIT License nually Identified aggs-matrix-stats 5.5.1 Apache License 2.0 Exact agronholm/pythonfutures 3.3.0 3Delight License Exact ahoward's lockfile 2.1.3 Ruby License Exact Exact,Ma ahoward's systemu 2.6.5 Ruby License nually Identified GNU Lesser General Public License ai's -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Licensing Information User Manual Mysql Enterprise Monitor 3.4
Licensing Information User Manual MySQL Enterprise Monitor 3.4 Table of Contents Licensing Information .......................................................................................................................... 4 Licenses for Third-Party Components .................................................................................................. 5 Ant-Contrib ............................................................................................................................... 10 ANTLR 2 .................................................................................................................................. 11 ANTLR 3 .................................................................................................................................. 11 Apache Commons BeanUtils v1.6 ............................................................................................. 12 Apache Commons BeanUtils v1.7.0 and Later ........................................................................... 13 Apache Commons Chain .......................................................................................................... 13 Apache Commons Codec ......................................................................................................... 13 Apache Commons Collections .................................................................................................. 14 Apache Commons Daemon ...................................................................................................... 14 Apache -
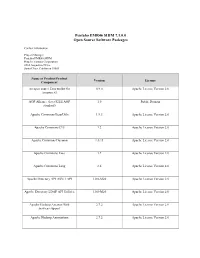
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -
Download Org Apache Commons Beanutils Converters Download Org Apache Commons Beanutils Converters
download org apache commons beanutils converters Download org apache commons beanutils converters. We recommend you use a mirror to download our release builds, but you must verify the integrity of the downloaded files using signatures downloaded from our main distribution directories. Recent releases (48 hours) may not yet be available from all the mirrors. You are currently using https://mirror.checkdomain.de/apache/ . If you encounter a problem with this mirror, please select another mirror. If all mirrors are failing, there are backup mirrors (at the end of the mirrors list) that should be available. It is essential that you verify the integrity of downloaded files, preferably using the PGP signature ( *.asc files); failing that using the SHA256 hash ( *.sha256 checksum files). The KEYS file contains the public PGP keys used by Apache Commons developers to sign releases. Download org apache commons beanutils converters. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 67b01c9ffa0e16a1 • Your IP : 188.246.226.140 • Performance & security by Cloudflare. -

Entitlement Control Message Generator
Open Source Used In ECMG 4.5.3 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-156819513 Open Source Used In ECMG 4.5.3 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-156819513 Contents 1.1 ACE+TAO 5.5.10 + 1.5.10 1.1.1 Available under license 1.2 Apache Commons Codec 1.3. 1.2.1 Available under license 1.3 Apache Commons Lib Apache 2.0 1.3.1 Available under license 1.4 Apache Jakarta Commons Configuration 1.9 1.4.1 Available under license 1.5 Apache Jakarta Commons DBCP 1.4 1.5.1 Available under license 1.6 Apache Jakarta Commons Lang 3.1 1.6.1 Available under license 1.7 Apache Log4j 1.2.16 1.7.1 Available under license 1.8 apache-ant_within-cglib 1.6.5 1.8.1 Available under license 1.9 apache-log4j 1.2.15 1.9.1 Available under license 1.10 apache-log4j 1.2.15 :DUPLICATE 1.10.1 Available under license 1.11 args4j 2.0.12 1.11.1 Available under license 1.12 asm-all-3.3.1_within-cglib 3.3.1 1.12.1 Available under license 1.13 bcprov-jdk16 -

Red Hat Build of Quarkus 1.11 Configuring Logging with Quarkus Legal Notice
Red Hat build of Quarkus 1.11 Configuring logging with Quarkus Last Updated: 2021-06-24 Red Hat build of Quarkus 1.11 Configuring logging with Quarkus Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -
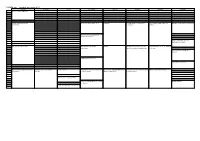
FOSDEM 2013 Schedule
FOSDEM 2013 - Saturday 2013-02-02 (1/9) Janson K.1.105 Ferrer Chavanne Lameere H.1301 H.1302 H.1308 10:30 Welcome to FOSDEM 2013 10:45 11:00 How we made the Jenkins QEMU USB status report 2012 Rockbuild The neat guide to Fedora RPM LinuxonAndroid and SlapOS on Wayland for Application Developers community Packaging Android 11:15 11:30 CRIU: Checkpoint and Restore (mostly) In Userspace 11:45 Ubuntu Online Accounts for application developers 12:00 The Devil is in the Details Vtrill: Rbridges for Virtual PTXdist Building RPM packages from Git Emdedded distro shootout: buildroot Networking repositories with git-buildpackage vs. Debian Better software through user 12:15 research 12:30 Bringing Xen to CentOS-6 Sketching interactions 12:45 13:00 The Open Observatory of Network Porting Fedora to 64-bit ARM Coding Goûter A brief tutorial on Xen's advanced Guacamayo -- Building Multimedia Package management and creation ARM v7 State of the Body ↴ Interference systems security features Appliance with Yocto ↴ in Gentoo Linux ↴ 13:15 Spoiling and Counter-spoiling 13:30 oVirt Live Storage Migration - Under Modern CMake ↴ the Hood ↴ ZONE: towards a better news feed ↴ 13:45 FOSDEM 2013 - Saturday 2013-02-02 (2/9) H.1309 H.2213 H.2214 AW1.120 AW1.121 AW1.125 AW1.126 Guillissen 10:30 10:45 11:00 Metaphor and BDD XMPP 101 Storytelling FLOSS Welcome and Introduction The room open() process Scripting Apache OpenOffice: Welcome to the Perl d… Introductory Nutshell Programs Inheritance versus Roles (Writer, Calc, Impress) 11:15 Signal/Collect: Processing Large -

Fairplay License Server
Open Source Used In Fairplay DRM License 1.0.4 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-142022930 Open Source Used In Fairplay DRM License 1.0.4 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-142022930 Contents 1.1 Apache Commons Codec 1.3. 1.1.1 Available under license 1.2 Apache Commons Lib Apache 2.0 1.2.1 Available under license 1.3 Apache Commons Lib Apache 2.0 1.3.1 Available under license 1.4 Apache Derby 10.10.1.1 1.4.1 Available under license 1.5 Apache HTTP Server 2.2.9 1.5.1 Available under license 1.6 Apache Jakarta Commons Configuration 1.9 1.6.1 Available under license 1.7 Apache Jakarta Commons HttpClient 3.1 1.7.1 Available under license 1.8 Apache Jakarta Commons Lang 3.1 1.8.1 Available under license 1.9 Apache Log4j 1.2.16 1.9.1 Available under license 1.10 apache-log4j 1.2.15 1.10.1 Available under license 1.11 apache-log4j 1.2.15 :DUPLICATE 1.11.1 Available under license 1.12 args4j 2.0.12 1.12.1 Available under