Using Software Execution Models to Prevent, Localize and Fix Bugs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Source Used in Cisco Unity Connection 11.5 SU 1
Open Source Used In Cisco Unity Connection 11.5 SU 1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-132949842 Open Source Used In Cisco Unity Connection 11.5 SU 1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-132949842 Contents 1.1 ace 5.3.5 1.1.1 Available under license 1.2 Apache Commons Beanutils 1.6 1.2.1 Notifications 1.2.2 Available under license 1.3 Apache Derby 10.8.1.2 1.3.1 Available under license 1.4 Apache Mina 2.0.0-RC1 1.4.1 Available under license 1.5 Apache Standards Taglibs 1.1.2 1.5.1 Available under license 1.6 Apache STRUTS 1.2.4. 1.6.1 Available under license 1.7 Apache Struts 1.2.9 1.7.1 Available under license 1.8 Apache Xerces 2.6.2. 1.8.1 Notifications 1.8.2 Available under license 1.9 axis2 1.3 1.9.1 Available under license 1.10 axis2/cddl 1.3 1.10.1 Available under license 1.11 axis2/cpl 1.3 1.11.1 Available under license 1.12 BeanUtils(duplicate) 1.6.1 1.12.1 Notifications Open Source Used In Cisco Unity Connection -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -
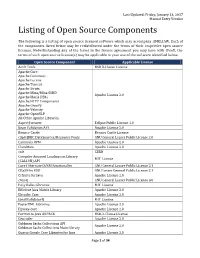
Listing of Open Source Components
Last Updated: Friday, January 13, 2017 Manual Entry Version Listing of Open Source Components The following is a listing of open source licensed software which may accompany AMELIA®. Each of the components listed below may be redistributed under the terms of their respective open source licenses. Notwithstanding any of the terms in the license agreement you may have with IPsoft, the terms of such open source license(s) may be applicable to your use of the software identified below. Open Source Component Applicable License Antlr Tools BSD 3-Clause License Apache Core Apache Commons Apache Lucene Apache Tomcat Apache Struts Apache Mina/Mina SSHD Apache License 2.0 Apache Maria DB4j Apache HTTP Components Apache Groovy Apache Velocity Apache OpenNLP All Other Apache Libraries AspectJ weaver Eclipse Public License 1.0 Bean Validation API Apache License 2.0 Bouncy Castle Bouncy Castle License c3p0:JDBC DataSources/Resource Pools GNU General Lesser Public License 2.0 Camunda BPM Apache License 2.0 ClassMate Apache License 2.0 colt CERN Compiler Assisted Localization Library MIT License (CAL10N) API Core Hibernate O/RM functionality GNU General Lesser Public License 2.1 CRaSH by EXO GNU Lesser General Public License 2.1 Crfsuite for Java Apache License 2.0 cron4j GNU General Lesser Public License 3.0 Easy Rules Libraries MIT License Efficient Java Matrix Library Apache License 2.0 Ehcache Core Apache License 2.0 EmailValidator4J MIT License FasterXML Libraries Apache License 2.0 Flyway-core Apache License 2.0 Fortran to Java ARPACK BSD-2-Clause -
Apache Directory Studio™
Main | ApacheDS | Studio | LDAP API | Mavibot | eSCIMo | Fortress | Kerby Apache Directory Studio Apache Directory Studio™ Home News The Eclipse-based LDAP browser and directory client Screenshots Apache Directory Studio is a complete directory tooling platform Downloads intended to be used with any LDAP server however it is particularly Version 2.0.0-M10 designed for use with ApacheDS. It is an Eclipse RCP application, Older Versions composed of several Eclipse (OSGi) plugins, that can be easily upgraded with additional ones. These plugins can even run within Documentation Eclipse itself. User's Guide Developer's Guide Download Apache FAQs Directory Studio 2.0.0-M10 Resources ChangeLog Testimonials LDAP Browser LDIF Editor Support Mailing Lists & IRC The LDAP Browser has been designed to work with almost any The LDIF Editor is a tool for editing LDIF files. It provides syntax Sources LDAP server available. It not only permits to read and display the highlighting and content assistance. Issue Tracking tree of your LDAP Server but also allows you to modify it by creating, editing or removing entries. Commercial Support Community How to Contribute Schema Editor Embedded ApacheDS Team The Schema Editor has been designed to edit the schema files Apache Directory Studio bundles the latest version of the Original Project Proposal in the OpenLDAP format. It allows you to edit easily attribute LDAPV3 certified ApacheDS. Creating and launching a new Special Thanks types and object classes for Apache Directory Server and LDAP server now takes less than 10 seconds! OpenLDAP. About Apache Apache License ApacheDS Configuration ACI Editor Sponsorship Thanks The ApacheDS Configuration Editor can be used to edit the The ACI Editor allows you to define, for an entry or a set of Security server configuration ('server.xml' and 'config.ldif' files) of an entries, graphically or manually (in souce code mode), an ACI Apache Directory Server installation. -

Realization of EAI Patterns with Apache Camel
Institut für Architektur von Anwendungssystemen Universität Stuttgart Universitätsstraße 38 70569 Stuttgart Studienarbeit Nr. 2127 Realization of EAI Patterns with Apache Camel Pascal Kolb Studiengang: Informatik Prüfer: Prof. Dr. Frank Leymann Betreuer: Dipl.‐Inf. Thorsten Scheibler begonnen am: 26.10.2007 beendet am: 26.04.2008 CR‐Klassifikation D.2.11, D.3, H.4.1 Table of Contents Table of Listings ............................................................................................................. vii 1 Introduction ............................................................................................................. 1 1.1 Task Description ................................................................................................................................. 1 1.2 Structure of this thesis ....................................................................................................................... 2 2 Apache Camel Fundamentals ................................................................................... 3 2.1 Introduction into Apache Camel ........................................................................................................ 3 2.2 Apache Camel’s Architecture ............................................................................................................. 4 2.2.1 Camel Components and Endpoints............................................................................................ 4 2.2.2 Camel Exchange and Message .................................................................................................. -

Licensing Information User Manual Mysql Enterprise Monitor 3.4
Licensing Information User Manual MySQL Enterprise Monitor 3.4 Table of Contents Licensing Information .......................................................................................................................... 4 Licenses for Third-Party Components .................................................................................................. 5 Ant-Contrib ............................................................................................................................... 10 ANTLR 2 .................................................................................................................................. 11 ANTLR 3 .................................................................................................................................. 11 Apache Commons BeanUtils v1.6 ............................................................................................. 12 Apache Commons BeanUtils v1.7.0 and Later ........................................................................... 13 Apache Commons Chain .......................................................................................................... 13 Apache Commons Codec ......................................................................................................... 13 Apache Commons Collections .................................................................................................. 14 Apache Commons Daemon ...................................................................................................... 14 Apache -

Apache Mina Case Study
Case Study: ThreadSafe Identifies Apache MINA Bug Executive Summary Contemplate is developing next-generation static analysis tools for finding concurrency problems. As part of our testing, we have been analysing open source projects that use concurrency. One project that we have used for testing is Apache MINA. Our ThreadSafe tool identified an issue related to concurrency in part of the framework that can be used for building a TCP server based on the Java non-blocking I/O libraries (java.nio). The way in which a Java library was used could lead to undefined behaviour, potentially including an infinite loop, crash or resource leak. The issue was reported to the developers, who committed to fixing the bug in the next release. As the issue was detected in a pre-release snapshot and is in recently added code, it has been caught before making it into a release version. Apache MINA Apache MINA is a ‘network application framework’ intended to support the development of high- performance, scalable network applications. There are several projects hosted by the Apache Software Foundation that use Apache MINA, including clients and servers for HTTP, FTP, SSH, and XMPP. Apache MINA is also used in QuickFix/J: an open-source implementation of the FIX (Financial Information Exchange) protocol. The Problem The issue identified is in a snapshot version of code prior to the release of 3.0.0 M1. The class containing the issue did not exist in previous versions of MINA. Thus the issue was identified and could be corrected before the relevant code was released. -

Apache Flume™
™ Apache Flume™ Flume 1.7.0 User Guide Introduction Overview Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store. The use of Apache Flume is not only restricted to log data aggregation. Since data sources are customizable, Flume can be used to transport massive quantities of event data including but not limited to network traffic data, social-media-generated data, email messages and pretty much any data source possible. Apache Flume is a top level project at the Apache Software Foundation. There are currently two release code lines available, versions 0.9.x and 1.x. Documentation for the 0.9.x track is available at the Flume 0.9.x User Guide. This documentation applies to the 1.4.x track. New and existing users are encouraged to use the 1.x releases so as to leverage the performance improvements and configuration flexibilities available in the latest architecture. System Requirements 1. Java Runtime Environment - Java 1.7 or later 2. Memory - Sufficient memory for configurations used by sources, channels or sinks 3. Disk Space - Sufficient disk space for configurations used by channels or sinks 4. Directory Permissions - Read/Write permissions for directories used by agent Architecture Data flow model A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop). -

OFSAA Licensing Information User Manual Release
Oracle® Financial Services Analytical Applications Licensing Information User Manual Release 8.0.6.0.0 May 2018 Document Control VERSION NUMBER REVISION DATE CHANGE LOG 1.0 May 2018 First release 2.0 December 2018 Added licensing information for Price Creation and Discovery 3.0 January 2019 Updated information for FSDF and OIDF 4.0 February 2019 Updated information for Sanctions, EDQ and UCS 5.0 February 2019 Added information for Oracle Data Integrator 6.0 November 2020 Updated versions for POI, Jackson, Jackson databind, jQuery, Log4J LICENSING INFORMATION USER MANUAL RELEASE 8.0.6.0.0 Copyright © 2019 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. -
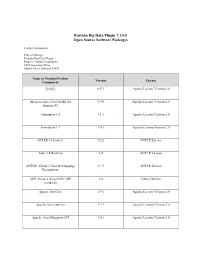
Pentaho Big Data Plugin 7.1.0.0 Open Source Software Packages
Pentaho Big Data Plugin 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho Big Data Plugin Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component [ini4j] 0.5.1 Apache License Version 2.0 An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 Annotation 1.0 1.1.1 Apache License Version 2.0 Annotation 1.1 1.0.1 Apache License Version 2.0 ANTLR 3 Complete 3.5.2 ANTLR License Antlr 3.4 Runtime 3.4 ANTLR License ANTLR, ANother Tool for Language 2.7.7 ANTLR License Recognition AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Ant Core 1.9.1 Apache License Version 2.0 Apache Ant Launcher 1.9.1 Apache License Version 2.0 Apache Aries Blueprint API 1.0.1 Apache License Version 2.0 Name of Product/Product Version License Component Apache Aries Blueprint CM 1.0.5 Apache License Version 2.0 Apache Aries Blueprint Core 1.4.2 Apache License Version 2.0 Apache Aries Blueprint Core 1.0.0 Apache License Version 2.0 Compatiblity Fragment Bundle Apache Aries JMX API 1.1.1 Apache License Version 2.0 Apache Aries JMX Blueprint API 1.1.0 Apache License Version 2.0 Apache Aries JMX Blueprint Core 1.1.0 Apache License Version 2.0 Apache Aries JMX Core 1.1.2 Apache License Version 2.0 Apache Aries JMX Whiteboard 1.0.0 Apache License Version 2.0 Apache Aries Proxy API 1.0.1 Apache License Version 2.0 Apache Aries Proxy Service 1.0.4 Apache License Version 2.0 Apache Aries Quiesce API 1.0.0 Apache License Version 2.0 Apache -

Talend Open Studio for ESB Installation and Upgrade Guide for Mac
Talend Open Studio for ESB Installation and Upgrade Guide for Mac 7.2.1M6 Contents Copyleft...........................................................................................................................3 Talend Open Studio for ESB: Prerequisites...............................................................5 Preparing your installation............................................................................................................................................. 5 Hardware requirements.................................................................................................................................................... 5 Software requirements......................................................................................................................................................6 Setting up JAVA_HOME.................................................................................................................................................. 13 Installing your Talend Open Studio for ESB manually.......................................... 14 Installing and configuring your Talend Studio.....................................................................................................14 Upgrading your Talend products..............................................................................21 Backing up the environment....................................................................................................................................... 21 Upgrading the Talend projects in -

Performance Management Advisors 8.1 Contact Center Advisor & Workforce Advisor
Supported Languages CSY CHS CHT DEU ENG ESN FRA ITA JPN KOR PTB RUS By Release 8.1.5 XX 8.1.4 XX X 8.1.3 XX 8.1.2 XX X 8.1.1 XX About This Software Contact Center Advisor (CCAdv) and Workforce Advisor (WA) are Web-based products: Contact Center Advisor—Enables the proactive management of contact center issues by consolidating information from disparate data sources, correlating events and determining relationships between them, identifying the root causes of an event, and communicating issues directly to appropriate management for immediate action. Workforce Advisor—Consolidates data from multiple switches, workforce management systems and other infrastructure components in order to monitor agent schedule adherence, correlating actual staffing levels to those forecasted, identifying unusual activity or discrepancies via an advanced rules engine, and communicating events immediately and directly to appropriate management and front line personnel. Call-data sources currently used include Genesys Stat Server and Cisco ICM/IPCC. Workforce data sources include Genesys Workforce Management, Aspect eWFM, and IEX Totalview. New Features in 8.1.x The primary new features in release 8.1.5 are: Administration changes: Previously, Workforce Advisor was dependent on Contact Center Advisor rollups. Using the new configuration option on the System Configuration page in the Administration module, you can choose to use independent Workforce Advisor hierarchies. The Contact Group Configuration page in the Administration module now shows the network contact center (NCC) name with the agent group contact center (AGCC) name, and uses the format NCC:AGCC. You can perform bulk configuration of Contact Center Advisor application rollups and bulk configuration of Workforce Advisor contact group rollups.