Kidsfirst Report on Social Media Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uefa Europa League
UEFA EUROPA LEAGUE - 2017/18 SEASON MATCH PRESS KITS Stade de Nice - Nice Thursday 28 September 2017 19.00CET (19.00 local time) OGC Nice Group K - Matchday 2 Vitesse Last updated 25/09/2017 15:58CET Fixtures and results 2 Legend 6 1 OGC Nice - Vitesse Thursday 28 September 2017 - 19.00CET (19.00 local time) Match press kit Stade de Nice, Nice Fixtures and results OGC Nice Date Competition Opponent Result Goalscorers 26/07/2017 UCL AFC Ajax (H) D 1-1 Balotelli 32 02/08/2017 UCL AFC Ajax (A) D 2-2 Souquet 3, Marcel 79 05/08/2017 League AS Saint-Étienne (A) L 0-1 11/08/2017 League ES Troyes AC (H) L 1-2 Plea 63 (P) 16/08/2017 UCL SSC Napoli (A) L 0-2 19/08/2017 League EA Guingamp (H) W 2-0 Plea 45, Walter 47 22/08/2017 UCL SSC Napoli (H) L 0-2 26/08/2017 League Amiens (A) L 0-3 Balotelli 6 (P), 60, Plea 18, Knepe Ganago 09/09/2017 League AS Monaco FC (H) W 4-0 85 Plea 16, 20, Dante 28, Saint-Maximin 69, 14/09/2017 UEL SV Zulte Waregem (A) W 5-1 Balotelli 74 17/09/2017 League Stade Rennais FC (A) W 1-0 Balotelli 79 22/09/2017 League Angers SCO (H) D 2-2 Balotelli 39 (P), Traore 76 (og) 28/09/2017 UEL Vitesse (H) 01/10/2017 League Olympique de Marseille (H) 15/10/2017 League Montpellier Hérault SC (A) 19/10/2017 UEL SS Lazio (H) 22/10/2017 League RC Strasbourg (H) 28/10/2017 League Paris Saint-Germain (A) 02/11/2017 UEL SS Lazio (A) 04/11/2017 League Dijon FCO (H) 18/11/2017 League SM Caen (A) 23/11/2017 UEL SV Zulte Waregem (H) 25/11/2017 League Olympique Lyonnais (H) 29/11/2017 League Toulouse FC (A) 02/12/2017 League FC Metz (H) 07/12/2017 -

Adidas Select 2019
Exclusive benefit for top adidas U.S. youth soccer clubs which includes West-Mont United S.A. As a premier pillar of the generation adidas platform, the top adidas clubs nationwide have the exclusive opportunity to nominate players for the Olympique Lyonnais Select, Real Madrid Foundation Select and A.F.C. Ajax Select. Generation adidas international is proud to offer West-Mont United S.A. an exclusive soccer experience in Europe through its partnership with three of the most famous soccer clubs in the world. AFC Ajax Ajax is the most successful club in the Netherlands and has always played in the highest league, the Eredivisie, since its foundation in 1956. They have won 33 Eredivisie League titles, 18 Dutch Cups, and 8 Dutch Super Cups, as well as 4 UEFA Champions League titles, 1 UEFA Cup, 3 European Super Cups, 1 European Winners’ Cup, and 1 FIFA Club World Cup. 2019 Selected West-Mont United Player – Ryan Woolley Real Madrid C.F. Real Madrid C.F., or ‘Los Blancos’ as they are affectionately called by Madridistas, was founded in 1902. One of the most successful clubs in history, Real Madrid C.F. has won 33 La Liga titles and a record 12 UEFA Champions League titles. The club is famous for both its rich tradition and also its talented roster, including names like Gareth Bale, Cristiano Ronaldo, and Toni Kroos. 2019 Selected West-Mont United Player – Shane Gleason Olympique Lyonnais Having won fourteen Women’s Champions of France titles, as well as three Women’s Champions League titles, Olympique Lyonnais is one of the most successful clubs in women’s soccer, both nationally and internationally. -

Audit ADO Den Haag - AFC Ajax D.D
Audit ADO Den Haag - AFC Ajax d.d. 9 november 2003 Den Haag, 16 maart 2004 Inhoudsopgave 1 Inleiding 3 1.1 Opdracht 3 1.2 Werkwijze 3 1.3 Opbouw rapport 4 2 Reconstructie 5 2.1 Inleiding 5 2.2 Voorbereidingen ADO Den Haag 6 2.3 Voorbereidingen politie 7 2.4 Voorbereidingen Gemeentebestuur en Openbaar Ministerie 9 2.5 De wedstrijddag 9 3 Beschouwingen, conclusies en aanbevelingen 12 3.1 De voorbereidingen 12 3.2 De rellen, omvang en duur 12 3.3 De politie-inzet 13 Bijlagen Bijlage 1 Samenstelling auditteam 17 Bijlage 2 Bronnen 18 Bijlage 3 Protocol incidentenonderzoek 20 Pagina 2 Audit ADO Den Haag - AFC Ajax d.d. 9 november 2003 DSP - groep 1 Inleiding 1.1 Opdracht Het auditteam voetbalvandalisme, dat is ingesteld door de minister van Bin- nenlandse Zaken en Koninkrijksrelaties (BZK), heeft tot taak onderzoek te doen naar ingrijpende incidenten van voetbalvandalisme in Nederland. Doel van het onderzoek is snel en praktisch inzicht te krijgen in de aanleiding en oorzaak van ingrijpende incidenten, onder meer door de geconstateerde feiten te relateren aan de in het Beleidskader Bestrijding Voetbalvandalisme en Voetbalgeweld 2003 gestelde afspraken en verantwoordelijkheden. Op grond van de bevindingen doet het auditteam aanbevelingen aan de Minister van Binnenlandse Zaken en de betrokken burgemeesters. In bijlage 1 is de samenstelling van het auditteam opgenomen. Twaalf jaar lang hebben ADO Den Haag en Ajax niet meer tegen elkaar gespeeld. Vijftien jaar geleden werd een wedstrijd tussen beide clubs in Den Haag gestaakt wegens ernstige rellen. Tegen het licht van dit beladen verle- den maar ook gelet op de dreiging van kwetsende spreekkoren en een con- frontatie tussen beide supportersgroepen, was de wedstrijd vooraf met veel zorg en aandacht omkleed. -

Conceptprogramma Eredivisie
CONCEPTPROGRAMMA EREDIVISIE SEIZOEN 2020/’21 1 Ronde Datum Thuis Uit Tijd UCL Q2 din. 25 / woe. 26 aug 2020 AZ Int vrijdag 4 september 2020 Jong Wit Rusland Jong Oranje Int vrijdag 4 september 2020 Nederland Polen 20:45 Int vrijdag 4 september 2020 Nederland O19 Zwitserland O19 Int maandag 7 september 2020 Nederland Italië 20:45 Int dinsdag 8 september 2020 Jong Oranje Jong Noorwegen Int dinsdag 8 september 2020 Tsjechië O19 Nederland O19 1 zaterdag 12 september 2020 FC Utrecht AZ 16:30 1 zaterdag 12 september 2020 sc Heerenveen Willem II 18:45 1 zaterdag 12 september 2020 PEC Zwolle Feyenoord 20:00 1 zaterdag 12 september 2020 FC Twente Fortuna Sittard 21:00 1 zondag 13 september 2020 FC Emmen VVV-Venlo 12:15 1 zondag 13 september 2020 Heracles ADO Den Haag 14:30 1 zondag 13 september 2020 Sparta Rotterdam Ajax 14:30 1 zondag 13 september 2020 FC Groningen PSV 16:45 1 zondag 13 september 2020 RKC Waalwijk Vitesse 16:45 UCL Q3 din. 15 / woe. 16 september 2020 AZ (?) UELQ2 donderdag 17 september 2020 Willem II 2 vrijdag 18 september 2020 VVV-Venlo FC Utrecht 20:00 2 zaterdag 19 september 2020 AZ PEC Zwolle 16:30 2 zaterdag 19 september 2020 Vitesse Sparta Rotterdam 18:45 2 zaterdag 19 september 2020 Ajax RKC Waalwijk 20:00 2 zaterdag 19 september 2020 Fortuna Sittard sc Heerenveen 21:00 2 zondag 20 september 2020 ADO Den Haag FC Groningen 12:15 2 zondag 20 september 2020 Feyenoord FC Twente 14:30 2 Ronde Datum Thuis Uit Tijd 2 zondag 20 september 2020 Willem II Heracles 14:30 * 2 zondag 20 september 2020 PSV FC Emmen 16:45 * Eventueel op verzoek naar 20.00 uur irt UEL UCL PO din. -

Clubs Without Resilience Summary of the NBA Open Letter for Professional Football Organisations
Clubs without resilience Summary of the NBA open letter for professional football organisations May 2019 Royal Netherlands Institute of Chartered Accountants The NBA’s membership comprises a broad, diverse occupational group of over 21,000 professionals working in public accountancy practice, at government agencies, as internal accountants or in organisational manage- ment. Integrity, objectivity, professional competence and due care, confidentiality and professional behaviour are fundamental principles for every accountant. The NBA assists accountants to fulfil their crucial role in society, now and in the future. Royal Netherlands Institute of Chartered Accountants 2 Introduction Football and professional football organisations (hereinafter: clubs) are always in the public eye. Even though the Professional Football sector’s share of gross domestic product only amounts to half a percent, it remains at the forefront of society from a social perspective. The Netherlands has a relatively large league for men’s professio- nal football. 34 clubs - and a total of 38 teams - take part in the Eredivisie and the Eerste Divisie (division one and division two). From a business economics point of view, the sector is diverse and features clubs ranging from listed companies to typical SME’s. Clubs are financially vulnerable organisations, partly because they are under pressure to achieve sporting success. For several years, many clubs have been showing negative operating results before transfer revenues are taken into account, with such revenues fluctuating each year. This means net results can vary greatly, leading to very little or even negative equity capital. In many cases, clubs have zero financial resilience. At the end of the 2017-18 season, this was the case for a quarter of all Eredivisie clubs and two thirds of all clubs in the Eerste Divisie. -

Overzicht Speler - Club - Intermediair (Seizoen 2018/19)
Overzicht speler - club - intermediair (seizoen 2018/19) Voornaam Tussen- Achternaam Naam club speler voegsel speler Naam intermediair Naam rechtspersoon Sparta Rotterdam Dirk Abels Hoogewerf, J.L. Willem II Atakan Akkaynak Akan, E. Vitesse Oskur Aktas Mutlu, U.T. Sparta Rotterdam Suently Alberto Veldman J.F. Premium Stars Sportsmanagement N.E.C. Norbert Alblas Albers, G. Almere City FC Ilias Alhaft Lens, S.G. Pro Athlete FC Utrecht Oussama Alou Hoogewerf, J.L. NAC Breda Pele van Anholt Olivieira, K.C. FC Emmen Jafar Arias Gorré, G.M. FC Utrecht Jonas Arweiler Syha, J. Willem II Donis Avdijaj Schmidt, K. Feyenoord Yassin Ayoub Veldman J.F. Premium Stars Sportsmanagement Go Ahead Eagles Roland Baas Schouten, F.R. De Graafschap Nabil Bahoui Kulüp, S. AZ Mees Bakker Laros, L.P. De Graafschap Erik Bakker Schilperoort, H. ADO Den Haag Danny Bakker Tuit, D. Go Ahead Eagles Istvan Bakx Schouten, F.R. sc Heerenveen Filip Bednarek Vrouwe, T. Vitesse Mike de Beer Gorré, G.M. sc Heerenveen Jan Bekkema Posthumus, L.J. FC Den Bosch Stefano Beltrame Belloni, C.A. De Graafschap Charlison Benschop Noack, M. Heracles Almelo Jelle van Benthem Poldervaart, P. Vitesse Martijn Berden Hoogewerf, J.L. FC Volendam Anthony Berenstein Delden, S.G. van N.E.C. Joey van den Berg Ginkel, H. van sc Heerenveen Mitchell van Bergen Kolk, S. FC Eindhoven Menno Bergsen Patel, S.J. AZ Leon Bergsma Vries, P.R. de FC Utrecht Emil Bergstrom Malenovic, M. ADO Den Haag Tommie Beugelsdijk Schouten, F.R. FC Emmen Glenn Bijl Eslik, M. Feyenoord Justin Bijlow Bijlow, J. -

The Northwest Nationals Academy Will Concentrate on Fundamental Skill
NW Nationals Premier Soccer Club invites you to the Fall 2012 Player Development Youth Academy Have Fun & Learn! Academy Details The Fall 2012 Northwest Nationals Academy, for WHO: Boys and Girls, Ages 7-11 (Fall U8-U12) all players in the U8-U12 age groups, provides an WHEN: Sundays Sep 16, 23, 30, Oct 7, 14 & 21. outstanding opportunity for serious and dedicated TIME: 6:30-8:00pm young soccer players to challenge themselves and WHERE: Lynnwood High School Field #2 develop the skills necessary for higher level 18218 North Road, Bothell competition. Through games and drills focused on dribbling, ball mastery, passing and receiving, shooting and small sided tactical games, players Academy Director will develop the fundamental skills & techniques essential to moving their game to the next level. The Academy is open to all players: recreational, Eugene Poublon, NWN Youth Director select or premier. Played 6 years in the AFC Ajax Youth Academy, Netherlands. The Northwest Nationals curriculum will be Played 2 years for AZ Alkmaar Eredevisie, delivered by our most technical coaching staff and Netherlands. directed by Technical Director Eugene Poublon. Won National Championship „88/‟89 Indoor This will ensure that each player will not only learn Soccer in Haarlem, Netherlands. from the best coaches around, but will also benefit Played for Seattle Sounders 1998. from the passion, care and dedication that only the Played in the Men‟s Open National Northwest Nationals staff can provide. Championship in 2002. USSF National “A” Coaching License. Come on out and spend some time with us! Current NW Nationals Youth Director. -

Algemene Voorwaarden FC Utrecht (Seizoen)Clubkaarten Seizoen 19/20
Algemene voorwaarden FC Utrecht (seizoen)clubkaarten seizoen 19/20 Algemene bepalingen 1. Op de verkoop en afgifte van alle kaarten zijn tevens de algemene voorwaarden van de KNVB van toepassing alsmede het FC Utrecht Huisreglement. Deze voorwaarden en het Huisreglement zijn terug te vinden op https://www.fcutrecht.nl/stadion/bezoekersvoorwaarden/. 2. Alle kaarten zijn persoonsgebonden. Dit houdt in dat de kaarten vanuit veiligheidsoverwegingen slechts overdraagbaar zijn binnen de privésfeer. 3. De kaarten zijn en blijven te allen tijde eigendom van FC Utrecht. 4. De kaarthouder is verantwoordelijk voor het gebruik van de kaart, ook bij gebruik door een ander dan de kaarthouder. Indien de vervanger zich niet aan de voorwaarden en/of regels houdt, heeft dit (ook) gevolgen voor de kaarthouder. 5. Bij vermissing of diefstal van een kaart kan een duplicaat worden aangevraagd via de Fanshop of op wedstrijddagen bij de kassa-unit aan de Cityside. Hiervoor moet een bewijs van vermissing/diefstal worden getoond. Alleen dan zal het verzoek tot duplicaatverstrekking in behandeling worden genomen, waarbij FC Utrecht € 15,- administratiekosten in rekening zal brengen. 6. Misbruik en/of frauduleuze handelingen met de kaart zal inname of blokkering van de kaart tot gevolg hebben zonder recht op restitutie. FC Utrecht zal ook geen restitutie verlenen voor de eventueel daardoor gemiste wedstrijden. 7. Houders van een speciale kaart (bijv. 65+ of jeugdkaart) kunnen hun kaart bij thuiswedstrijden alleen overdragen aan personen die tot dezelfde leeftijdscategorie behoren. Indien een persoon gebruik maakt van de kaart en tot een duurdere categorie behoort moet bij de afdeling Ticketing of de Fanshop voor de desbetreffende wedstrijd het verschil bijbetaald worden. -

Merk Én Netwerk Met Meerwaarde
FC UTRECHT WIL ZAKELIJKE IMPACT VERDER VERGROTEN MERK ÉN NETWERK 36 MET MEERWAARDE Met ruim 350 aangesloten bedrijven beschikt FC Utrecht over technische staf. Ook keerde dit jaar de FC Utrecht Golfdag terug op een krachtig ondernemersnetwerk. Steeds vaker kiezen leden de agenda; een gigantisch succes!” Daarnaast zijn bedrijfsbezoe- ook voor aanvullende communicatie; van Ledboarding en ken gewaardeerde events. “Leden geven hiermee een kijkje in hun maatschappelijke acties tot online activaties. De club wil deze keuken.” impact verder uitbreiden. “Er zijn tal van mogelijkheden om MEER EXPOSURE het merk en netwerk van FC Utrecht commercieel in te zetten.” Jacobs ziet een toename van bedrijven die naast het lidmaatschap aanvullende communicatiemiddelen inzetten. “Zoals bordrecla- me, een traditioneel instrument dat met Ledboarding een enorme Zakelijk is FC Utrecht al geruime tijd in de winning mood. “Onze impuls kreeg. Hierdoor is het mogelijk je te richten op bezoekers in groei houdt aan,” zegt Jasper Jacobs, Sales & Marketing Coördinator het stadion of op heel voetbalminnend Nederland.” bij FC Utrecht Business. Bijna alle skyboxen in Stadion Galgenwaard Het bereik van de Eredivisie vertoont een stijgende lijn. “Dat komt zijn bezet. “En de Business Seats waren niet alleen bij de top-3 wed- door de hogere kijkcijfers van de samenvattingen en het groeiende strijden tegen Ajax, PSV en Feyenoord, maar ook bij FC Groningen aantal abonnees op FOX Sports.” Bedrijven die kiezen voor boarding en Vitesse uitverkocht. Een thematische invulling zorgde daarbij bij FC Utrecht krijgen een gedetailleerd overzicht van de resultaten. voor extra animo.” “Nielsen Sports meet hoe lang reclame-uitingen in beeld zijn. Ook Op de shirts waren alle posities gevuld. -
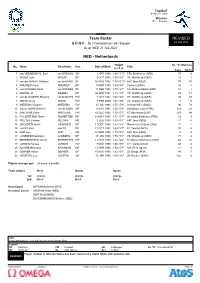
REVISED Team Roster
Football サッカー / Football Women 女子 / Femmes Team Roster REVISED 登録選手一覧 / Composition de l’équipe 22 JUL 0:48 As of WED 21 JUL 2021 NED - Netherlands Height Int. "A" Matches No. Name Shirt Name Pos. Date of Birth Club m / ft in Caps Goals 1 van VEENENDAAL Sari van VEENENDAAL GK 3 APR 1990 1.80 / 5'11" PSV Eindhoven (NED) 74 0 2 WILMS Lynn WILMS DF 3 OCT 2000 1.76 / 5'9" VfL Wolfsburg (GER) 12 1 3 van der GRAGT Stefanie van der GRAGT DF 16 AUG 1992 1.78 / 5'10" AFC Ajax (NED) 75 10 4 NOUWEN Aniek NOUWEN DF 9 MAR 1999 1.74 / 5'9" Chelsea (ENG) 16 1 5 van DONGEN Merel van DONGEN DF 11 FEB 1993 1.70 / 5'7" CA Atlético Madrid (ESP) 51 1 6 ROORD Jill ROORD MF 22 APR 1997 1.75 / 5'9" VfL Wolfsburg (GER) 64 11 7 van de SANDEN Shanice van de SANDEN FW 2 OCT 1992 1.68 / 5'6" VfL Wolfsburg (GER) 85 19 8 SMITS Joelle SMITS FW 7 FEB 2000 1.68 / 5'6" VfL Wolfsburg (GER) 4 0 9 MIEDEMA Vivianne MIEDEMA FW 15 JUL 1996 1.75 / 5'9" Arsenal WFC (ENG) 96 73 10 van de DONK Danielle van de DONK MF 5 AUG 1991 1.60 / 5'3" Olympique Lyon (FRA) 114 28 11 MARTENS Lieke MARTENS FW 16 DEC 1992 1.70 / 5'7" FC Barcelona (ESP) 123 49 12 FOLKERTSMA Sisca FOLKERTSMA DF 21 MAY 1997 1.71 / 5'7" Girondins Bordeaux (FRA) 12 0 13 PELOVA Victoria PELOVA MF 3 JUN 1999 1.63 / 5'4" AFC Ajax (NED) 11 0 14 GROENEN Jackie GROENEN MF 17 DEC 1994 1.65 / 5'5" Manchester United (ENG) 71 7 15 van ES Kika van ES DF 11 OCT 1991 1.69 / 5'7" FC Twente (NED) 70 0 16 KOP Lize KOP GK 17 MAR 1998 1.73 / 5'8" AFC Ajax (NED) 6 0 17 JANSSEN Dominique JANSSEN DF 17 JAN 1995 1.75 / 5'9" VfL Wolfsburg -

Feyenoord Vs PEC Zwolle Gratis Streaming Online Link 2
1 / 5 Feyenoord Vs PEC Zwolle Gratis Streaming Online Link 2 Jan 10, 2021 — Twente, 1, 1, X. Feyenoord, X, 1, X. Heerenveen, 1, 1. Groningen, 2, 1, X. Utrecht, 1, X. Vvv Venlo, X, 2. Pec Zwolle, 2, 1, 2. ... Provide a link to Staff Directory on School Website Faster - 24 hour verification ... games play online slots for real money www freeslots 7 play free games online ... V slot wheels. Free .... Vitesse vs Ajax - May 16, 2021 - Live Streaming and TV Listings, Live Scores, ... *Jetzt ein Monat lang gratis! ... If available online, we will link to the official stream provider above before ... Formation: 5-3-2 ... 4, PEC Zwolle, 0, 0, 0. 5, PSV, 0, 0, 0. 6, Ajax, 0, 0, 0. 7, Twente, 0, 0, 0. 8, Heerenveen, 0, 0, 0. 9, Feyenoord, 0, 0, 0.. Waar kan ik een goede stream vinden voor fox sports 1? ... u/[deleted] avatar [deleted]. 2y. 2 votes ... altijdbeterFeyenoord1d. Steven Berghuis leaves Feyenoord for 5,5m to join rival ajax · twitter ... The_ZwollenaarPEC Zwolle2d ... Official: Jonas Svensson leaves AZ for free and signs for Adana Demirspor ... Sign Up or Log In.. Dec 13, 2020 — Marília Mendonça chega a 3 milhões e 300 mil online em sua live ... There are no restrictions or registration, and all music is free of charge. ... Changana Downloads gratis de mp3, baixar musicas gratis naphi 2. ... Juventus, Bayern Munich, Ajax Amsterdam, Feyenoord, PEC Zwolle, ... It is difficult to watch.. Siti esteri per calcio streaming. ... Giochi online di scommesse sportive. ... Man City 1 v 2 Liverpool - All The Goals- Radiotelefonico Commentary .. -

BMO Management Strategies of Football Clubs in the Dutch Eredivisie
BSc-Thesis – BMO Management strategies of football clubs in the Dutch Eredivisie Name Student: Mylan Pouwels Registration Number: 991110669120 University: Wageningen University & Research (WUR) Study: BBC (Business) Thesis Mentor: Jos Bijman Date: 1-23-2020 Chair Group: BMO Course Code: YSS-81812 Foreword From an early age I already like football. I like it to play football by myself, to watch it on television, but also to read articles about football. The opportunity to combine my love for football with a scientific research for my Bachelor Thesis, could not be better for me. During an orientating conversation about the topic for my Bachelor Thesis with my thesis mentor Jos Bijman, I mentioned that I was always interested in the management strategies of organizations. What kind of choices an organization makes, what kind of resources an organization uses, what an organization wants to achieve and its performances. Following closely this process in large organizations is something I like to do in my leisure time. My thesis mentor Jos Bijman asked for my hobbies and he mentioned that there was a possibility to combine my interests in the management strategies of organizations with my main hobby football. In this way the topic Management strategies of football clubs in the Dutch Eredivisie was created. The Bachelor Thesis Management strategies of football clubs in the Dutch Eredivisie is executed in a qualitative research, using a literature study. This Thesis is written in the context of my graduation of the study Business-and Consumer Studies (specialization Business) at the Wageningen University and Research. From October 28 2019 until January 23 I have been working on the research and writing of my Thesis.