A Categorization Scheme for Concurrency Control Protocols in Distributed Databases Yunyong Teng-Amnuay Iowa State University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SD-SQL Server: Scalable Distributed Database System
The International Arab Journal of Information Technology, Vol. 4, No. 2, April 2007 103 SD -SQL Server: Scalable Distributed Database System Soror Sahri CERIA, Université Paris Dauphine, France Abstract: We present SD -SQL Server, a prototype scalable distributed database system. It let a relational table to grow over new storage nodes invis ibly to the application. The evolution uses splits dynamically generating a distributed range partitioning of the table. The splits avoid the reorganization of a growing database, necessary for the current DBMSs and a headache for the administrators. We il lustrate the architecture of our system, its capabilities and performance. The experiments with the well -known SkyServer database show that the overhead of the scalable distributed table management is typically minimal. To our best knowledge, SD -SQL Server is the only DBMS with the discussed capabilities at present. Keywords: Scalable distributed DBS, scalable table, distributed partitioned view, SDDS, performance . Received June 4 , 2005; accepted June 27 , 2006 1. Introduction or k -d based with respect to the partitioning key(s). The application sees a scal able table through a specific The explosive growth of the v olume of data to store in type of updateable distributed view termed (client) databases makes many of them huge and permanently scalable view. Such a view hides the partitioning and growing. Large tables have to be hash ed or partitioned dynamically adjusts itself to the partitioning evolution. over several storage sites. Current DBMSs, e. g., SQL The adjustment is lazy, in the sense it occurs only Server, Oracle or DB2 to name only a few, provide when a query to the scalable table comes in and the static partitioning only. -

Socrates: the New SQL Server in the Cloud
Socrates: The New SQL Server in the Cloud Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, Vikram Wakade Microsoft Azure & Microsoft Research ABSTRACT 1 INTRODUCTION The database-as-a-service paradigm in the cloud (DBaaS) The cloud is here to stay. Most start-ups are cloud-native. is becoming increasingly popular. Organizations adopt this Furthermore, many large enterprises are moving their data paradigm because they expect higher security, higher avail- and workloads into the cloud. The main reasons to move ability, and lower and more flexible cost with high perfor- into the cloud are security, time-to-market, and a more flexi- mance. It has become clear, however, that these expectations ble “pay-as-you-go” cost model which avoids overpaying for cannot be met in the cloud with the traditional, monolithic under-utilized machines. While all these reasons are com- database architecture. This paper presents a novel DBaaS pelling, the expectation is that a database runs in the cloud architecture, called Socrates. Socrates has been implemented at least as well as (if not better) than on premise. Specifically, in Microsoft SQL Server and is available in Azure as SQL DB customers expect a “database-as-a-service” to be highly avail- Hyperscale. This paper describes the key ideas and features able (e.g., 99.999% availability), support large databases (e.g., of Socrates, and it compares the performance of Socrates a 100TB OLTP database), and be highly performant. -

An Overview of Distributed Databases
International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 4, Number 2 (2014), pp. 207-214 © International Research Publications House http://www. irphouse.com /ijict.htm An Overview of Distributed Databases Parul Tomar1 and Megha2 1Department of Computer Engineering, YMCA University of Science & Technology, Faridabad, INDIA. 2Student Department of Computer Science, YMCA University of Science and Technology, Faridabad, INDIA. Abstract A Database is a collection of data describing the activities of one or more related organizations with a specific well defined structure and purpose. A Database is controlled by Database Management System(DBMS) by maintaining and utilizing large collections of data. A Distributed System is the one in which hardware and software components at networked computers communicate and coordinate their activity only by passing messages. In short a Distributed database is a collection of databases that can be stored at different computer network sites. This paper presents an overview of Distributed Database System along with their advantages and disadvantages. This paper also provides various aspects like replication, fragmentation and various problems that can be faced in distributed database systems. Keywords: Database, Deadlock, Distributed Database Management System, Fragmentation, Replication. 1. Introduction A Database is systematically organized or structuredrepository of indexed information that allows easy retrieval, updating, analysis, and output of data. Each database may involve different database management systems and different architectures that distribute the execution of transactions [1]. A distributed database is a database in which storage devices are not all attached to a common processing unit such as the CPU. It may be stored in multiple computers, located in the same physical location; or may be dispersed over a network of interconnected computers. -

Failures in DBMS
Chapter 11 Database Recovery 1 Failures in DBMS Two common kinds of failures StSystem filfailure (t)(e.g. power outage) ‒ affects all transactions currently in progress but does not physically damage the data (soft crash) Media failures (e.g. Head crash on the disk) ‒ damagg()e to the database (hard crash) ‒ need backup data Recoveryyp scheme responsible for handling failures and restoring database to consistent state 2 Recovery Recovering the database itself Recovery algorithm has two parts ‒ Actions taken during normal operation to ensure system can recover from failure (e.g., backup, log file) ‒ Actions taken after a failure to restore database to consistent state We will discuss (briefly) ‒ Transactions/Transaction recovery ‒ System Recovery 3 Transactions A database is updated by processing transactions that result in changes to one or more records. A user’s program may carry out many operations on the data retrieved from the database, but the DBMS is only concerned with data read/written from/to the database. The DBMS’s abstract view of a user program is a sequence of transactions (reads and writes). To understand database recovery, we must first understand the concept of transaction integrity. 4 Transactions A transaction is considered a logical unit of work ‒ START Statement: BEGIN TRANSACTION ‒ END Statement: COMMIT ‒ Execution errors: ROLLBACK Assume we want to transfer $100 from one bank (A) account to another (B): UPDATE Account_A SET Balance= Balance -100; UPDATE Account_B SET Balance= Balance +100; We want these two operations to appear as a single atomic action 5 Transactions We want these two operations to appear as a single atomic action ‒ To avoid inconsistent states of the database in-between the two updates ‒ And obviously we cannot allow the first UPDATE to be executed and the second not or vice versa. -

Blockchain Database for a Cyber Security Learning System
Session ETD 475 Blockchain Database for a Cyber Security Learning System Sophia Armstrong Department of Computer Science, College of Engineering and Technology East Carolina University Te-Shun Chou Department of Technology Systems, College of Engineering and Technology East Carolina University John Jones College of Engineering and Technology East Carolina University Abstract Our cyber security learning system involves an interactive environment for students to practice executing different attack and defense techniques relating to cyber security concepts. We intend to use a blockchain database to secure data from this learning system. The data being secured are students’ scores accumulated by successful attacks or defends from the other students’ implementations. As more professionals are departing from traditional relational databases, the enthusiasm around distributed ledger databases is growing, specifically blockchain. With many available platforms applying blockchain structures, it is important to understand how this emerging technology is being used, with the goal of utilizing this technology for our learning system. In order to successfully secure the data and ensure it is tamper resistant, an investigation of blockchain technology use cases must be conducted. In addition, this paper defined the primary characteristics of the emerging distributed ledgers or blockchain technology, to ensure we effectively harness this technology to secure our data. Moreover, we explored using a blockchain database for our data. 1. Introduction New buzz words are constantly surfacing in the ever evolving field of computer science, so it is critical to distinguish the difference between temporary fads and new evolutionary technology. Blockchain is one of the newest and most developmental technologies currently drawing interest. -

Guide to Design, Implementation and Management of Distributed Databases
NATL INST OF STAND 4 TECH H.I C NIST Special Publication 500-185 A111D3 MTfiDfi2 Computer Systems Guide to Design, Technology Implementation and Management U.S. DEPARTMENT OF COMMERCE National Institute of of Distributed Databases Standards and Technology Elizabeth N. Fong Nisr Charles L. Sheppard Kathryn A. Harvill NIST I PUBLICATIONS I 100 .U57 500-185 1991 C.2 NIST Special Publication 500-185 ^/c 5oo-n Guide to Design, Implementation and Management of Distributed Databases Elizabeth N. Fong Charles L. Sheppard Kathryn A. Harvill Computer Systems Laboratory National Institute of Standards and Technology Gaithersburg, MD 20899 February 1991 U.S. DEPARTMENT OF COMMERCE Robert A. Mosbacher, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director Reports on Computer Systems Technology The National institute of Standards and Technology (NIST) has a unique responsibility for computer systems technology within the Federal government, NIST's Computer Systems Laboratory (CSL) devel- ops standards and guidelines, provides technical assistance, and conducts research for computers and related telecommunications systems to achieve more effective utilization of Federal Information technol- ogy resources. CSL's responsibilities include development of technical, management, physical, and ad- ministrative standards and guidelines for the cost-effective security and privacy of sensitive unclassified information processed in Federal computers. CSL assists agencies in developing security plans and in improving computer security awareness training. This Special Publication 500 series reports CSL re- search and guidelines to Federal agencies as well as to organizations in industry, government, and academia. National Institute of Standards and Technology Special Publication 500-185 Natl. Inst. Stand. Technol. -
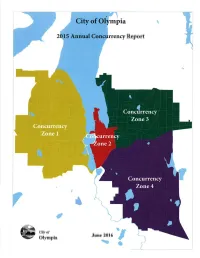
Annual Concurrency Report
pra Report Ciry of June 2016 Olympia I TABLE OF CONTENTS Introduction 1 .2 A. Actual Traffic Growth and Six Year Forecast .J B. Level of Service (LOS) Analysis .8 Conclusions .......9 A. Conformance with Adopted LOS Standards 9 B. Marginal Projects.... .....10 C. Level of Service on State Facilities .....1 I Summary .... ....1 1 Appendix A: Maps of Traffic Growth in the Four Concurrency Analysis Zones..... 1 Appendix B: Intersection Level of Service Analysis vs. Project Needs .. Appendix C: Unsignalized Intersection Warrant Analysis ................. vll Appendix D: Link Level of Service Analysis .....................xi Olympia 2OtS Concurrency Report INTRODUCTION ln 1995, the City of Olympia (City), in compliance with the Growth Management Act's (GMA) internal consistency requirement, adopted the Transportation Concurrency Ordinance (No. 55aO). One objective of GMA's internal consistency requirement is to maintain concurrency between a jurisdiction's infrastructure investments and growth. Following this objective, the City's Ordinance prohibits development approval if the development causes the Level of Service (LOS) on a transportation facility to declíne below the standards adopted in the transportation element of the Olympia's Comprehensive Plon (Comp Plan). The ordinance contains two features, as follows: a Development is not allowed unless (or until) transportation improvements or strategies to provide for the impacts of the development are in place at the time of development or withín six years of the time the project comes on line. a Annual review of the concurrency management system is required along with the annual review and update of the Copital Facilíties Plon (CFP) and transportation element of the Comp Plan. -

Concurrency Control
Concurrency Control Instructor: Matei Zaharia cs245.stanford.edu Outline What makes a schedule serializable? Conflict serializability Precedence graphs Enforcing serializability via 2-phase locking » Shared and exclusive locks » Lock tables and multi-level locking Optimistic concurrency with validation Concurrency control + recovery CS 245 2 Lock Modes Beyond S/X Examples: (1) increment lock (2) update lock CS 245 3 Example 1: Increment Lock Atomic addition action: INi(A) {Read(A); A ¬ A+k; Write(A)} INi(A), INj(A) do not conflict, because addition is commutative! CS 245 4 Compatibility Matrix compat S X I S T F F X F F F I F F T CS 245 5 Update Locks A common deadlock problem with upgrades: T1 T2 l-S1(A) l-S2(A) l-X1(A) l-X2(A) --- Deadlock --- CS 245 6 Solution If Ti wants to read A and knows it may later want to write A, it requests an update lock (not shared lock) CS 245 7 Compatibility Matrix New request compat S X U S T F Lock already X F F held in U CS 245 8 Compatibility Matrix New request compat S X U S T F T Lock already X F F F held in U F F F Note: asymmetric table! CS 245 9 How Is Locking Implemented In Practice? Every system is different (e.g., may not even provide conflict serializable schedules) But here is one (simplified) way ... CS 245 10 Sample Locking System 1. Don’t ask transactions to request/release locks: just get the weakest lock for each action they perform 2. -

Transportation Concurrency Requirements Level of Service
Assistance Bulletin Transportation Concurrency Snohomish County #59 Planning and Development Services Requirements Updated April 2016 WWW.SNOCO.ORG Keyword: Assistance Bulletins Concurrency Visit us at : 2nd Floor Robert J. Drewel Bldg. Q: What is Chapter 30.66B SCC? 3000 Rockefeller Avenue Everett, WA 98201 A: Chapter 30.66B SCC is the chapter in Title 30 SCC, the County’s Unified Develop- 425-388-3311 ment Code (UDC), that contains the Concurrency and Road Impact Mitigation require- 1-800-562-4367, ext. 3311 ments relating to new development. Chapter 30.66B SCC includes requirements for con- currency to comply with the Washington State Growth Management Act (GMA) and re- quires developers to mitigate the traffic impacts on the County’s arterial road network from new development. Q: What is the concurrency management system? A: The Snohomish County concurrency management system provides the basis for moni- toring the traffic impacts of land development, and helps determine if transportation im- provements are keeping pace with the prevailing rate of land development. In order for a development to be granted approval it must obtain a concurrency determination. Q: What is a “ concurrency determination” ? A: Each development application is reviewed to determine whether or not there is enough PERMIT SUBMITTAL capacity on the County’s arterial road network in the vicinity of the development to ac- Appointment commodate the new traffic that will be generated by the development, without having traf- 425.388.3311 fic congestion increase to levels beyond that allowed in Chapter 30.66B SCC. Simply Ext. 2790 stated, if there is sufficient arterial capacity, the development is deemed concurrent and can proceed. -

Sundial: Harmonizing Concurrency Control and Caching in a Distributed OLTP Database Management System
Sundial: Harmonizing Concurrency Control and Caching in a Distributed OLTP Database Management System Xiangyao Yu, Yu Xia, Andrew Pavlo♠ Daniel Sanchez, Larry Rudolph|, Srinivas Devadas Massachusetts Institute of Technology, ♠Carnegie Mellon University, |Two Sigma Investments, LP [email protected], [email protected], [email protected] [email protected], [email protected], [email protected] ABSTRACT and foremost, long network delays lead to long execution time of Distributed transactions suffer from poor performance due to two distributed transactions, making them slower than single-partition major limiting factors. First, distributed transactions suffer from transactions. Second, long execution time increases the likelihood high latency because each of their accesses to remote data incurs a of contention among transactions, leading to more aborts and per- long network delay. Second, this high latency increases the likeli- formance degradation. hood of contention among distributed transactions, leading to high Recent work on improving distributed concurrency control has abort rates and low performance. focused on protocol-level and hardware-level improvements. Im- We present Sundial, an in-memory distributed optimistic concur- proved protocols can reduce synchronization overhead among trans- rency control protocol that addresses these two limitations. First, to actions [22, 35, 36, 46], but can still limit performance due to high reduce the transaction abort rate, Sundial dynamically determines coordination overhead (e.g., lock blocking). Hardware-level im- the logical order among transactions at runtime, based on their data provements include using special hardware like optimized networks access patterns. Sundial achieves this by applying logical leases to that enable low-latency remote memory accesses [20, 48, 55], which each data element, which allows the database to dynamically calcu- can increase the overall cost of the system. -

Sr 826/Palmetto Expressway Project Development & Environment Study from Sr 93/I‐75 to Golden Glades Interchange
METHODOLOGY LETTER OF UNDERSTANDING SR 826/PALMETTO EXPRESSWAY PROJECT DEVELOPMENT & ENVIRONMENT STUDY FROM SR 93/I‐75 TO GOLDEN GLADES INTERCHANGE SYSTEMS INTERCHANGE MODIFICATION REPORT (SIMR) Financial Project ID: 418423‐1‐22‐01 FAP No.: 4751 146 P / ETDM No.: 11241 Miami‐Dade County Prepared For: FDOT District Six 1000 NW 111th Avenue Miami, Florida 33172 Prepared by: Reynolds, Smith and Hills, Inc. 6161 Blue Lagoon Drive, Suite 200 Miami, Florida 33126 March 9, 2012 SR 826/Palmetto Expressway PD&E Study METHODOLOGY LETTER OF UNDERSTANDING MEMORANDUM DATE: March 9, 2012 TO: Phil Steinmiller, AICP Florida Department of Transportation District Six Interchange Review Committee Chair FROM: Dat Huynh, PE FDOT, District Six Project Manager SUBJECT: Methodology Letter of Understanding (MLOU) SR 826/Palmetto Expressway PD&E Study Systems Interchange Modification Report (SIMR) FDOT, District Six FM No.: 418423‐1‐22‐01 Dear Interchange Coordinator: This document serves as the Methodology Letter of Understanding (MLOU) between the Federal Highway Administration (FHWA), the Florida Department of Transportation (FDOT) Systems Planning Office, Florida’s Turnpike Enterprise (Cooperating Approval Authority) and FDOT District Six Interchange Review Committee (Applicant) regarding the preparation of a Systems Interchange Modification Report (SIMR) for a portion of SR 826/Palmetto Expressway located in Miami‐Dade County, Florida. The SIMR relates to the proposed improvements for the segment of SR 826 between I‐75 and the Golden Glades Interchange (GGI). The project proposes to widen SR 826 mainline from I‐75 to Golden Glades Interchange to provide additional lanes that could serve as general use lanes or special use lanes (managed lanes). -

A Transaction Processing Method for Distributed Database
Advances in Computer Science Research, volume 87 3rd International Conference on Mechatronics Engineering and Information Technology (ICMEIT 2019) A Transaction Processing Method for Distributed Database Zhian Lin a, Chi Zhang b School of Computer and Cyberspace Security, Communication University of China, Beijing, China [email protected], [email protected] Abstract. This paper introduces the distributed transaction processing model and two-phase commit protocol, and analyses the shortcomings of the two-phase commit protocol. And then we proposed a new distributed transaction processing method which adds heartbeat mechanism into the two- phase commit protocol. Using the method can improve reliability and reduce blocking in distributed transaction processing. Keywords: distributed transaction, two-phase commit protocol, heartbeat mechanism. 1. Introduction Most database services of application systems will be distributed on several servers, especially in some large-scale systems. Distributed transaction processing will be involved in the execution of business logic. At present, two-phase commit protocol is one of the methods to distributed transaction processing in distributed database systems. The two-phase commit protocol includes coordinator (transaction manager) and several participants (databases). In the process of communication between the coordinator and the participants, if the participants without reply for fail, the coordinator can only wait all the time, which can easily cause system blocking. In this paper, heartbeat mechanism is introduced to monitor participants, which avoid the risk of blocking of two-phase commit protocol, and improve the reliability and efficiency of distributed database system. 2. Distributed Transactions 2.1 Distributed Transaction Processing Model In a distributed system, each node is physically independent and they communicates and coordinates each other through the network.