A Vision Based Tool for Playing Games
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Scripting Engine for Execution of Experimental Scripts on Ttü Nanosatellite
TALLINN UNIVERSITY OF TECHNOLOGY School of Information Technologies Department of Software Science Sander Aasaväli 142757IAPB SCRIPTING ENGINE FOR EXECUTION OF EXPERIMENTAL SCRIPTS ON TTÜ NANOSATELLITE Bachelor’s thesis Supervisor: Martin Rebane MSc Lecturer Co-Supervisor: Peeter Org Tallinn 2017 TALLINNA TEHNIKAÜLIKOOL Infotehnoloogia teaduskond Tarkvarateaduse instituut Sander Aasaväli 142757IAPB INTERPRETAATOR TTÜ NANOSATELLIIDIL EKSPERIMENTAALSETE SKRIPTIDE KÄIVITAMISEKS Bakalaureusetöö Juhendaja: Martin Rebane MSc Lektor Kaasjuhendaja: Peeter Org Tallinn 2017 Author’s declaration of originality I hereby certify that I am the sole author of this thesis. All the used materials, references to the literature and the work of others have been referred to. This thesis has not been presented for examination anywhere else. Author: Sander Aasaväli 22.05.2017 3 Abstract Main subject for this thesis is choosing a scripting engine for TTÜ (Tallinna Tehnikaülikool) nanosatellite. The scripting engine must provide functionality, like logging, system debugging, determination, and perform certain tasks, like communicating with the bus, file writing and reading. The engine’s language must be powerful enough to fill our needs, yet small and simple enough to have as small flash and RAM (Random Access Memory) footprint as possible. The scripting engine should also be implemented on an external board (STM32f3discovery). This way the engine’s flash footprint, RAM footprint and performance can be tested in our conditions. The outcome was that, both Pawn and My-Basic were implemented on the external board. The flash and RAM footprint tests along with performance tests were executed and results were analysed. This thesis is written in English and is 38 pages long, including 5 chapters, 6 figures and 2 tables. -

Tomasz Dąbrowski / Rockhard GIC 2016 Poznań WHAT DO WE WANT? WHAT DO WE WANT?
WHY (M)RUBY SHOULD BE YOUR NEXT SCRIPTING LANGUAGE? Tomasz Dąbrowski / Rockhard GIC 2016 Poznań WHAT DO WE WANT? WHAT DO WE WANT? • fast iteration times • easy modelling of complex gameplay logic & UI • not reinventing the wheel • mature tools • easy to integrate WHAT DO WE HAVE? MY PREVIOUS SETUP • Lua • not very popular outside gamedev (used to be general scripting language, but now most applications seem to use python instead) • even after many years I haven’t gotten used to its weird syntax (counting from one, global variables by default, etc) • no common standard - everybody uses Lua differently • standard library doesn’t include many common functions (ie. string.split) WHAT DO WE HAVE? • as of 2016, Lua is still a gold standard of general game scripting languages • C# (though not scripting) is probably even more popular because of the Unity • Unreal uses proprietary methods of scripting (UScript, Blueprints) • Squirrel is also quite popular (though nowhere near Lua) • AngelScript, Javascript (V8), Python… are possible yet very unpopular choices • and you can always just use C++ MY CRITERIA POPULARITY • popularity is not everything • but using a popular language has many advantages • most problems you will encounter have already been solved (many times) • more production-grade tools • more documentation, tutorials, books, etc • most problems you will encounter have already been solved (many times) • this literally means, that you will be able to have first prototype of anything in seconds by just copying and pasting code • (you can -

Master List of Games This Is a List of Every Game on a Fully Loaded SKG Retro Box, and Which System(S) They Appear On
Master List of Games This is a list of every game on a fully loaded SKG Retro Box, and which system(s) they appear on. Keep in mind that the same game on different systems may be vastly different in graphics and game play. In rare cases, such as Aladdin for the Sega Genesis and Super Nintendo, it may be a completely different game. System Abbreviations: • GB = Game Boy • GBC = Game Boy Color • GBA = Game Boy Advance • GG = Sega Game Gear • N64 = Nintendo 64 • NES = Nintendo Entertainment System • SMS = Sega Master System • SNES = Super Nintendo • TG16 = TurboGrafx16 1. '88 Games ( Arcade) 2. 007: Everything or Nothing (GBA) 3. 007: NightFire (GBA) 4. 007: The World Is Not Enough (N64, GBC) 5. 10 Pin Bowling (GBC) 6. 10-Yard Fight (NES) 7. 102 Dalmatians - Puppies to the Rescue (GBC) 8. 1080° Snowboarding (N64) 9. 1941: Counter Attack ( Arcade, TG16) 10. 1942 (NES, Arcade, GBC) 11. 1943: Kai (TG16) 12. 1943: The Battle of Midway (NES, Arcade) 13. 1944: The Loop Master ( Arcade) 14. 1999: Hore, Mitakotoka! Seikimatsu (NES) 15. 19XX: The War Against Destiny ( Arcade) 16. 2 on 2 Open Ice Challenge ( Arcade) 17. 2010: The Graphic Action Game (Colecovision) 18. 2020 Super Baseball ( Arcade, SNES) 19. 21-Emon (TG16) 20. 3 Choume no Tama: Tama and Friends: 3 Choume Obake Panic!! (GB) 21. 3 Count Bout ( Arcade) 22. 3 Ninjas Kick Back (SNES, Genesis, Sega CD) 23. 3-D Tic-Tac-Toe (Atari 2600) 24. 3-D Ultra Pinball: Thrillride (GBC) 25. 3-D WorldRunner (NES) 26. 3D Asteroids (Atari 7800) 27. -
![[Japan] SALA GIOCHI ARCADE 1000 Miglia](https://docslib.b-cdn.net/cover/3367/japan-sala-giochi-arcade-1000-miglia-393367.webp)
[Japan] SALA GIOCHI ARCADE 1000 Miglia
SCHEDA NEW PLATINUM PI4 EDITION La seguente lista elenca la maggior parte dei titoli emulati dalla scheda NEW PLATINUM Pi4 (20.000). - I giochi per computer (Amiga, Commodore, Pc, etc) richiedono una tastiera per computer e talvolta un mouse USB da collegare alla console (in quanto tali sistemi funzionavano con mouse e tastiera). - I giochi che richiedono spinner (es. Arkanoid), volanti (giochi di corse), pistole (es. Duck Hunt) potrebbero non essere controllabili con joystick, ma richiedono periferiche ad hoc, al momento non configurabili. - I giochi che richiedono controller analogici (Playstation, Nintendo 64, etc etc) potrebbero non essere controllabili con plance a levetta singola, ma richiedono, appunto, un joypad con analogici (venduto separatamente). - Questo elenco è relativo alla scheda NEW PLATINUM EDITION basata su Raspberry Pi4. - Gli emulatori di sistemi 3D (Playstation, Nintendo64, Dreamcast) e PC (Amiga, Commodore) sono presenti SOLO nella NEW PLATINUM Pi4 e non sulle versioni Pi3 Plus e Gold. - Gli emulatori Atomiswave, Sega Naomi (Virtua Tennis, Virtua Striker, etc.) sono presenti SOLO nelle schede Pi4. - La versione PLUS Pi3B+ emula solo 550 titoli ARCADE, generati casualmente al momento dell'acquisto e non modificabile. Ultimo aggiornamento 2 Settembre 2020 NOME GIOCO EMULATORE 005 SALA GIOCHI ARCADE 1 On 1 Government [Japan] SALA GIOCHI ARCADE 1000 Miglia: Great 1000 Miles Rally SALA GIOCHI ARCADE 10-Yard Fight SALA GIOCHI ARCADE 18 Holes Pro Golf SALA GIOCHI ARCADE 1941: Counter Attack SALA GIOCHI ARCADE 1942 SALA GIOCHI ARCADE 1943 Kai: Midway Kaisen SALA GIOCHI ARCADE 1943: The Battle of Midway [Europe] SALA GIOCHI ARCADE 1944 : The Loop Master [USA] SALA GIOCHI ARCADE 1945k III SALA GIOCHI ARCADE 19XX : The War Against Destiny [USA] SALA GIOCHI ARCADE 2 On 2 Open Ice Challenge SALA GIOCHI ARCADE 4-D Warriors SALA GIOCHI ARCADE 64th. -
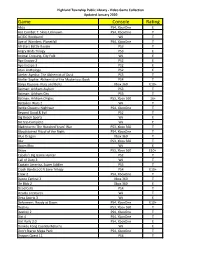
Game Console Rating
Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Abzu PS4, XboxOne E Ace Combat 7: Skies Unknown PS4, XboxOne T AC/DC Rockband Wii T Age of Wonders: Planetfall PS4, XboxOne T All-Stars Battle Royale PS3 T Angry Birds Trilogy PS3 E Animal Crossing, City Folk Wii E Ape Escape 2 PS2 E Ape Escape 3 PS2 E Atari Anthology PS2 E Atelier Ayesha: The Alchemist of Dusk PS3 T Atelier Sophie: Alchemist of the Mysterious Book PS4 T Banjo Kazooie- Nuts and Bolts Xbox 360 E10+ Batman: Arkham Asylum PS3 T Batman: Arkham City PS3 T Batman: Arkham Origins PS3, Xbox 360 16+ Battalion Wars 2 Wii T Battle Chasers: Nightwar PS4, XboxOne T Beyond Good & Evil PS2 T Big Beach Sports Wii E Bit Trip Complete Wii E Bladestorm: The Hundred Years' War PS3, Xbox 360 T Bloodstained Ritual of the Night PS4, XboxOne T Blue Dragon Xbox 360 T Blur PS3, Xbox 360 T Boom Blox Wii E Brave PS3, Xbox 360 E10+ Cabela's Big Game Hunter PS2 T Call of Duty 3 Wii T Captain America, Super Soldier PS3 T Crash Bandicoot N Sane Trilogy PS4 E10+ Crew 2 PS4, XboxOne T Dance Central 3 Xbox 360 T De Blob 2 Xbox 360 E Dead Cells PS4 T Deadly Creatures Wii T Deca Sports 3 Wii E Deformers: Ready at Dawn PS4, XboxOne E10+ Destiny PS3, Xbox 360 T Destiny 2 PS4, XboxOne T Dirt 4 PS4, XboxOne T Dirt Rally 2.0 PS4, XboxOne E Donkey Kong Country Returns Wii E Don't Starve Mega Pack PS4, XboxOne T Dragon Quest 11 PS4 T Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Dragon Quest Builders PS4 E10+ Dragon -

Master List of Games This Is a List of Every Game on a Fully Loaded SKG Retro Box, and Which System(S) They Appear On
Master List of Games This is a list of every game on a fully loaded SKG Retro Box, and which system(s) they appear on. Keep in mind that the same game on different systems may be vastly different in graphics and game play. In rare cases, such as Aladdin for the Sega Genesis and Super Nintendo, it may be a completely different game. System Abbreviations: • GB = Game Boy • GBC = Game Boy Color • GBA = Game Boy Advance • GG = Sega Game Gear • N64 = Nintendo 64 • NES = Nintendo Entertainment System • SMS = Sega Master System • SNES = Super Nintendo • TG16 = TurboGrafx16 1. '88 Games (Arcade) 2. 007: Everything or Nothing (GBA) 3. 007: NightFire (GBA) 4. 007: The World Is Not Enough (N64, GBC) 5. 10 Pin Bowling (GBC) 6. 10-Yard Fight (NES) 7. 102 Dalmatians - Puppies to the Rescue (GBC) 8. 1080° Snowboarding (N64) 9. 1941: Counter Attack (TG16, Arcade) 10. 1942 (NES, Arcade, GBC) 11. 1942 (Revision B) (Arcade) 12. 1943 Kai: Midway Kaisen (Japan) (Arcade) 13. 1943: Kai (TG16) 14. 1943: The Battle of Midway (NES, Arcade) 15. 1944: The Loop Master (Arcade) 16. 1999: Hore, Mitakotoka! Seikimatsu (NES) 17. 19XX: The War Against Destiny (Arcade) 18. 2 on 2 Open Ice Challenge (Arcade) 19. 2010: The Graphic Action Game (Colecovision) 20. 2020 Super Baseball (SNES, Arcade) 21. 21-Emon (TG16) 22. 3 Choume no Tama: Tama and Friends: 3 Choume Obake Panic!! (GB) 23. 3 Count Bout (Arcade) 24. 3 Ninjas Kick Back (SNES, Genesis, Sega CD) 25. 3-D Tic-Tac-Toe (Atari 2600) 26. 3-D Ultra Pinball: Thrillride (GBC) 27. -

Ultimate++ Forum
Subject: AngelScript - AngelCode Scripting Library Posted by Sender Ghost on Fri, 18 Nov 2011 09:37:26 GMT View Forum Message <> Reply to Message Homepage: http://www.angelcode.com/angelscript/ License: zlib Version: 2.30.0 (February 22nd, 2015) Description: The AngelCode Scripting Library, or AngelScript as it is also known, is an extremely flexible cross-platform scripting library designed to allow applications to extend their functionality through external scripts. It has been designed from the beginning to be an easy to use component, both for the application programmer and the script writer. Efforts have been made to let it call standard C functions and C++ methods with little to no need for proxy functions. The application simply registers the functions, objects, and methods that the scripts should be able to work with and nothing more has to be done with your code. The same functions used by the application internally can also be used by the scripting engine, which eliminates the need to duplicate functionality. For the script writer the scripting language follows the widely known syntax of C/C++, but without the need to worry about pointers and memory leaks. Contrary to most scripting languages, AngelScript uses the common C/C++ datatypes for more efficient communication with the host application. Documentation: http://www.angelcode.com/angelscript/documentation.html In the attachments you could find AngelScript source code, add-ons, samples, converted to U++ packages and documentation. To note: There were minor changes for include files for original sources to adapt for U++ package structure. Edit: Updated to 2.30.0 version. -

Opera Acquires Yoyo Games, Launches Opera Gaming
Opera Acquires YoYo Games, Launches Opera Gaming January 20, 2021 - [Tuck-In] Acquisition forms the basis for Opera Gaming, a new division focused on expanding Opera's capabilities and monetization opportunities in the gaming space - Deal unites Opera GX, world's first gaming browser and popular game development engine, GameMaker - Opera GX hit 7 million MAUs in December 2020, up nearly 350% year-over-year DUNDEE, Scotland and OSLO, Norway, Jan. 20, 2021 /PRNewswire/ -- Opera (NASDAQ: OPRA), the browser developer and consumer internet brand, today announced its acquisition of YoYo Games, creator of the world's leading 2D game engine, GameMaker Studio 2, for approximately $10 million. The tuck-in acquisition represents the second building block in the foundation of Opera Gaming, a new division within Opera with global ambitions and follows the creation and rapid growth of Opera's innovative Opera GX browser, the world's first browser built specifically for gamers. Krystian Kolondra, EVP Browsers at Opera, said: "With Opera GX, Opera had adapted its proven, innovative browser tech platform to dramatically expand its footprint in gaming. We're at the brink of a shift, when more and more people start not only playing, but also creating and publishing games. GameMaker Studio2 is best-in-class game development software, and lowers the barrier to entry for anyone to start making their games and offer them across a wide range of web-supported platforms, from PCs, to, mobile iOS/Android devices, to consoles." Annette De Freitas, Head of Business Development & Strategic Partnerships, Opera Gaming, added: "Gaming is a growth area for Opera and the acquisition of YoYo Games reflects significant, sustained momentum across both of our businesses over the past year. -

Middleware and European Standardisation” Köln, 17.8.2011
” Middleware and European Standardisation” Köln, 17.8.2011 Event supported by NEM initative Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu THROUGH more than in that employ over EGDF 12 17000 YOU CAN 600 game studios European game industry REACH countries professionals UK, AT, DE, FR, DK, FI, NO, BE, NL, LU, ES, IT Policy EGDF IS A development Dissemination Elaboration TRADE- participates proc- disseminates elaborates game ASSOCIATION esses developing the best developers’ policy recommen- practices, new mutual positions (SME) THAT dations that sup- standards, (technology, FOCUSES ON port game devel- new tools etc. content) opers Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu Source: © IHS Screen Digest, 2011 Consumer spending on entertainment media (€m) Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu Source: © IHS Screen Digest, 2011 European consumer spending on games (€m) Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu Value chains of video game industry Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu Viral innovation process Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu www.GameMiddleware.org Game Middleware Platform Dr. Malte Behrmann Secretary General [email protected] www.egdf.eu Standardization and Middelware Examples of European Standardization: Metric system, GSM Game Development uses increasingly specific middleware technologies. Developers tend less and less to reinvent the wheel. Europe is more and more the home of middleware of global relevance. Different aspects of the value chain are represented and the healthy competition shows also the commercial relevance. -

1. with Examples of Different Programming Languages Show How Programming Languages Are Organized Along the Given Rubrics: I
AGBOOLA ABIOLA CSC302 17/SCI01/007 COMPUTER SCIENCE ASSIGNMENT 1. With examples of different programming languages show how programming languages are organized along the given rubrics: i. Unstructured, structured, modular, object oriented, aspect oriented, activity oriented and event oriented programming requirement. ii. Based on domain requirements. iii. Based on requirements i and ii above. 2. Give brief preview of the evolution of programming languages in a chronological order. 3. Vividly distinguish between modular programming paradigm and object oriented programming paradigm. Answer 1i). UNSTRUCTURED LANGUAGE DEVELOPER DATE Assembly Language 1949 FORTRAN John Backus 1957 COBOL CODASYL, ANSI, ISO 1959 JOSS Cliff Shaw, RAND 1963 BASIC John G. Kemeny, Thomas E. Kurtz 1964 TELCOMP BBN 1965 MUMPS Neil Pappalardo 1966 FOCAL Richard Merrill, DEC 1968 STRUCTURED LANGUAGE DEVELOPER DATE ALGOL 58 Friedrich L. Bauer, and co. 1958 ALGOL 60 Backus, Bauer and co. 1960 ABC CWI 1980 Ada United States Department of Defence 1980 Accent R NIS 1980 Action! Optimized Systems Software 1983 Alef Phil Winterbottom 1992 DASL Sun Micro-systems Laboratories 1999-2003 MODULAR LANGUAGE DEVELOPER DATE ALGOL W Niklaus Wirth, Tony Hoare 1966 APL Larry Breed, Dick Lathwell and co. 1966 ALGOL 68 A. Van Wijngaarden and co. 1968 AMOS BASIC FranÇois Lionet anConstantin Stiropoulos 1990 Alice ML Saarland University 2000 Agda Ulf Norell;Catarina coquand(1.0) 2007 Arc Paul Graham, Robert Morris and co. 2008 Bosque Mark Marron 2019 OBJECT-ORIENTED LANGUAGE DEVELOPER DATE C* Thinking Machine 1987 Actor Charles Duff 1988 Aldor Thomas J. Watson Research Center 1990 Amiga E Wouter van Oortmerssen 1993 Action Script Macromedia 1998 BeanShell JCP 1999 AngelScript Andreas Jönsson 2003 Boo Rodrigo B. -

22012021 Pleniere French Gaia
P l é n i è r e 1 22 JANVIER 2021 P l é n i è r e 2 Par Henri d’Agrain Délégué général du Cigref P l é n i è r e 3 22 JANVIER 2021 P l é n i è r e 4 Par Cédric O Secrétaire d’État chargé de la Transition numérique et des Communications électroniques P l é n i è r e 5 22 JANVIER 2021 P l é n i è r e 6 Par Bernard Duverneuil, Président du Cigref Gérard Roucairol, Président honoraire de l’Académie des technologies Jean-Luc Beylat, Président du pôle de compétitivité Systematic Paris-Région Mathieu Weill, Chef du service de l’économie numérique à la Direction Générale des Entreprises P l é n i è r e 7 22 JANVIER 2021 P l é n i è r e 8 Par Hubert Tardieu CEO AISBL GAIA-X Agenda 01 Introduction GAIA-X 02 Data Space Facilitation and the role of National Hubs 03 The AISBL Status and Organization 04 Outlook – 100 Days ahead 05 Summary 9 Overview: GAIA-X provides a user-friendly and homogenous ecosystem Joint Development of a user friendly and homogenous European ecosystem. Bringing together data spaces and their specific requirements with the provider side. 10 The GAIA-X objectives Objectives 11 The GAIA-X objectives Objectives Policy Rules Application portability Data & Software Infrastructure portability Infrastructure 12 The GAIA-X objectives Objectives Policy Rules Architecture of Standards Application portability Data Ontology Data Information API PaaS Data & Software By Industry vertical X-CSP Infrastructure portability IAM IaaS Self Description Network & Interconnects Infrastructure 13 The GAIA-X objectives Objectives Policy Rules Architecture of Standards GAIA-X Federation services Application portability Identity & Trust Data Ontology Data Information API PaaS Federated Catalogue Data & Software By Industry vertical X-CSP Infrastructure portability Data Sovereignty Services IAM IaaS Self Description Compliance Network & Interconnects Infrastructure 14 GAIA-X Federation Services – The Core Data Ecosystem …the implementation of secure Federated Identity …Sovereign Data Services which ensure the identity and trust mechanisms (security and privacy by design). -

A Classification of Scripting Systems for Entertainment and Serious
Published in Proceedings of VS-GAMES 2011: 3rd International Conference on Games and Virtual Worlds for Serious Applications, pages 47-54; definitive version available from http://dx.doi.org/10.1109/VS-GAMES.2011.13 A Classification of Scripting Systems for Entertainment and Serious Computer Games Eike Falk Anderson Interactive Worlds ARG Coventry University Coventry, UK [email protected] Abstract—The technology base for modern computer games is usually provided by a game engine. Many game engines have built-in dedicated scripting languages that allow the development of complete games that are built using those engines, as well as extensive modification of existing games through scripting alone. While some of these game engines implement propri- etary languages, others use existing scripting systems that have been modified according to the game engine’s requirements. Scripting languages generally provide a very high level of abstraction method for syntactically controlling the behaviour of their host applications and different types of scripting system allow different types of modification of their underlying host application. In this paper we propose a simple classification for scripting systems used in computer games for entertainment and serious purposes. Index Terms—Data-Driven Game Development, Scripting Language Classification. Fig. 1. A typical game engine. If the engine core includes a scripting system, then application specific scripts are loaded as external game assets and there I. INTRODUCTION may be no other application specific code. The computer games industry is still a young industry which continues to have a lot of potential for growth. This is especially so, since games have broken out of the domain Consequently it is no surprise that scripting systems are of pure entertainment and are now used in a wide variety of considered one of the most important developer tools that are different situations.