Big Data Analytics Options on AWS AWS Whitepaper Big Data Analytics Options on AWS AWS Whitepaper
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reliability and Security of Large Scale Data Storage in Cloud Computing C.W
This article is part of the Reliability Society 2010 Annual Technical Report Reliability and Security of Large Scale Data Storage in Cloud Computing C.W. Hsu ¹¹¹ C.W. Wang ²²² Shiuhpyng Shieh ³³³ Department of Computer Science Taiwan Information Security Center at National Chiao Tung University NCTU (TWISC@NCTU) Email: ¹[email protected] ³[email protected] ²[email protected] Abstract In this article, we will present new challenges to the large scale cloud computing, namely reliability and security. Recent progress in the research area will be briefly reviewed. It has been proved that it is impossible to satisfy consistency, availability, and partitioned-tolerance simultaneously. Tradeoff becomes crucial among these factors to choose a suitable data access model for a distributed storage system. In this article, new security issues will be addressed and potential solutions will be discussed. Introduction “Cloud Computing ”, a novel computing model for large-scale application, has attracted much attention from both academic and industry. Since 2006, Google Inc. Chief Executive Eric Schmidt introduced the term into industry, and related research had been carried out in recent years. Cloud computing provides scalable deployment and fine-grained management of services through efficient resource sharing mechanism (most of them are for hardware resources, such as VM). Convinced by the manner called “ pay-as-you-go ” [1][2], companies can lower the cost of equipment management including machine purchasing, human maintenance, data backup, etc. Many cloud services rapidly appear on the Internet, such as Amazon’s EC2, Microsoft’s Azure, Google’s Gmail, Facebook, and so on. However, the well-known definition of the term “Cloud Computing ” was first given by Prof. -

Commvault on AWS Comprehensive Cloud Data Management for Hybrid IT Table of Contents
Commvault on AWS Comprehensive Cloud Data Management for Hybrid IT Table of Contents The Data Management Challenge 3 Commvault and Amazon Web Services 4 Benefits 7 Case Study: Dow Jones 8 Getting Started 9 2 The Data Management Challenge Today, more data is being generated than ever before. Keeping up with the rapid pace of data growth presents a series of challenges. Enterprise organizations are collecting petabytes of customer and application data that must be backed up and accessible to meet compliance requirements. Increased regulation around data retention policies make it more difficult to manage backup and archive storage, as critical data may be required to be kept for years and maybe difficult to find. Further complicating matters, point solutions often overlap and leave gaps where data is unprotected and require additional staff to manage them. These issues lead to increased costs, yet many IT departments are facing budget cuts and cannot expand upon their capital to meet increased performance demands. Today’s hybrid IT organizations realize cloud can help solve many data storage issues. With cloud storage comes the need for a comprehensive data management platform to manage data both on-premises and in the cloud. Savvy organizations streamline IT operations and reduce cloud waste with flexible orchestration to automate resource provisioning, policies and routine tasks. This eBook will demonstrate how Commvault and Amazon Web Services (AWS) deliver a cost-effective data management solution that addresses all of these challenges with a single, scalable solution. 3 Commvault and Amazon Web Services Unlike most backup and recovery solutions, Commvault offers a single data platform solution for all backup and recovery needs; as opposed to having to several point solutions for each use case (i.e. -

Amazon Dynamodb
Dynamo Amazon DynamoDB Nicolas Travers Inspiré de Advait Deo Vertigo N. Travers ESILV : Dynamo Amazon DynamoDB – What is it ? • Fully managed nosql database service on AWS • Data model in the form of tables • Data stored in the form of items (name – value attributes) • Automatic scaling ▫ Provisioned throughput ▫ Storage scaling ▫ Distributed architecture • Easy Administration • Monitoring of tables using CloudWatch • Integration with EMR (Elastic MapReduce) ▫ Analyze data and store in S3 Vertigo N. Travers ESILV : Dynamo Amazon DynamoDB – What is it ? key=value key=value key=value key=value Table Item (64KB max) Attributes • Primary key (mandatory for every table) ▫ Hash or Hash + Range • Data model in the form of tables • Data stored in the form of items (name – value attributes) • Secondary Indexes for improved performance ▫ Local secondary index ▫ Global secondary index • Scalar data type (number, string etc) or multi-valued data type (sets) Vertigo N. Travers ESILV : Dynamo DynamoDB Architecture • True distributed architecture • Data is spread across hundreds of servers called storage nodes • Hundreds of servers form a cluster in the form of a “ring” • Client application can connect using one of the two approaches ▫ Routing using a load balancer ▫ Client-library that reflects Dynamo’s partitioning scheme and can determine the storage host to connect • Advantage of load balancer – no need for dynamo specific code in client application • Advantage of client-library – saves 1 network hop to load balancer • Synchronous replication is not achievable for high availability and scalability requirement at amazon • DynamoDB is designed to be “always writable” storage solution • Allows multiple versions of data on multiple storage nodes • Conflict resolution happens while reads and NOT during writes ▫ Syntactic conflict resolution ▫ Symantec conflict resolution Vertigo N. -

Finding Fraud in Large and Diverse Data Sets
Business white paper Finding fraud in large and diverse data sets Applying real-time, next-generation analytics to fraud detection and prevention using the HP Vertica Analytics Platform Developments in data mining In the effort to identify and deter fraud, conventional wisdom still applies: Follow the money. That simple adage notwithstanding, the task of tracking fraud and its perpetrators continues to vex both private and public organizations. Clearly, advancements in information technology have made it possible to capture transaction data at the most granular level. For instance, in the retail trade alone, transmissions of up to 500 megabytes daily between individual point-of-sale sites and their data centers are typical.2 Logically, such detail should result in greater transparency and greater capacity to fight fraud. Yet, the sheer volume of data that organizations now maintain, pulled from so many sources and stored across a range of locations has made the same organizations more vulnerable.3 More points of entry amount to more opportunities for fraud. In its annual Global Fraud Report, The Economist found that 50% of all businesses surveyed acknowledged they were vulnerable to fraud; 35% of North American companies specifically cited IT complexity for increasing their exposure to risk. Accordingly, the application of data mining as a security measure A solution for real-time fraud detection has become increasingly germane to modern fraud detection. Historically, data mining as a means of identifying trends from raw Fraud saps hundreds of billions of dollars each year from the statistics can be traced back to the 1700s with the introduction of bottom line of industries such as banking, insurance, retail, Bayes’ theorem. -

The Vertica Analytic Database: C-Store 7 Years Later
The Vertica Analytic Database: C-Store 7 Years Later Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan Nga Tran, Ben Vandiver, Lyric Doshi, Chuck Bear Vertica Systems, An HP Company Cambridge, MA {alamb, mfuller, rvaradarajan, ntran, bvandiver, ldoshi, cbear} @vertica.com ABSTRACT that they were designed for transactional workloads on late- This paper describes the system architecture of the Ver- model computer hardware 40 years ago. Vertica is designed tica Analytic Database (Vertica), a commercialization of the for analytic workloads on modern hardware and its success design of the C-Store research prototype. Vertica demon- proves the commercial and technical viability of large scale strates a modern commercial RDBMS system that presents distributed databases which offer fully ACID transactions a classical relational interface while at the same time achiev- yet efficiently process petabytes of structured data. ing the high performance expected from modern “web scale” This main contributions of this paper are: analytic systems by making appropriate architectural choices. 1. An overview of the architecture of the Vertica Analytic Vertica is also an instructive lesson in how academic systems Database, focusing on deviations from C-Store. research can be directly commercialized into a successful product. 2. Implementation and deployment lessons that led to those differences. 1. INTRODUCTION 3. Observations on real-world experiences that can in- The Vertica Analytic Database (Vertica) is a distributed1, form future research directions for large scale analytic massively parallel RDBMS system that commercializes the systems. ideas of the C-Store[21] project. It is one of the few new commercial relational database systems that is widely used We hope that this paper contributes a perspective on com- in business critical systems. -

AWS Managed Services (AMS)
AWS Managed Services (AMS) Application Developer's Guide AMS Advanced Operations Plan Version September 16, 2020 AWS Managed Services (AMS) Application Developer's Guide AMS Advanced Operations Plan AWS Managed Services (AMS) Application Developer's Guide: AMS Advanced Operations Plan Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. AWS Managed Services (AMS) Application Developer's Guide AMS Advanced Operations Plan Table of Contents Application Onboarding to AMS Introduction ........................................................................................ 1 What is Application Onboarding? ................................................................................................. 1 What we do, what we do not do .................................................................................................. 1 AMS Amazon Machine Images (AMIs) ............................................................................................ 2 Security enhanced AMIs ...................................................................................................... 4 Key terms ................................................................................................................................. -
![[XIAY]⋙ Big Data Science & Analytics: a Hands-On Approach By](https://docslib.b-cdn.net/cover/4352/xiay-big-data-science-analytics-a-hands-on-approach-by-354352.webp)
[XIAY]⋙ Big Data Science & Analytics: a Hands-On Approach By
Big Data Science & Analytics: A Hands-On Approach Arshdeep Bahga, Vijay Madisetti Click here if your download doesn"t start automatically Big Data Science & Analytics: A Hands-On Approach Arshdeep Bahga, Vijay Madisetti Big Data Science & Analytics: A Hands-On Approach Arshdeep Bahga, Vijay Madisetti We are living in the dawn of what has been termed as the "Fourth Industrial Revolution", which is marked through the emergence of "cyber-physical systems" where software interfaces seamlessly over networks with physical systems, such as sensors, smartphones, vehicles, power grids or buildings, to create a new world of Internet of Things (IoT). Data and information are fuel of this new age where powerful analytics algorithms burn this fuel to generate decisions that are expected to create a smarter and more efficient world for all of us to live in. This new area of technology has been defined as Big Data Science and Analytics, and the industrial and academic communities are realizing this as a competitive technology that can generate significant new wealth and opportunity. Big data is defined as collections of datasets whose volume, velocity or variety is so large that it is difficult to store, manage, process and analyze the data using traditional databases and data processing tools. Big data science and analytics deals with collection, storage, processing and analysis of massive-scale data. Industry surveys, by Gartner and e-Skills, for instance, predict that there will be over 2 million job openings for engineers and scientists trained in the area of data science and analytics alone, and that the job market is in this area is growing at a 150 percent year-over-year growth rate. -

Data Warehousing on AWS
Data Warehousing on AWS March 2016 Amazon Web Services – Data Warehousing on AWS March 2016 © 2016, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only. It represents AWS’s current product offerings and practices as of the date of issue of this document, which are subject to change without notice. Customers are responsible for making their own independent assessment of the information in this document and any use of AWS’s products or services, each of which is provided “as is” without warranty of any kind, whether express or implied. This document does not create any warranties, representations, contractual commitments, conditions or assurances from AWS, its affiliates, suppliers or licensors. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers. Page 2 of 26 Amazon Web Services – Data Warehousing on AWS March 2016 Contents Abstract 4 Introduction 4 Modern Analytics and Data Warehousing Architecture 6 Analytics Architecture 6 Data Warehouse Technology Options 12 Row-Oriented Databases 12 Column-Oriented Databases 13 Massively Parallel Processing Architectures 15 Amazon Redshift Deep Dive 15 Performance 15 Durability and Availability 16 Scalability and Elasticity 16 Interfaces 17 Security 17 Cost Model 18 Ideal Usage Patterns 18 Anti-Patterns 19 Migrating to Amazon Redshift 20 One-Step Migration 20 Two-Step Migration 20 Tools for Database Migration 21 Designing Data Warehousing Workflows 21 Conclusion 24 Further Reading 25 Page 3 of 26 Amazon Web Services – Data Warehousing on AWS March 2016 Abstract Data engineers, data analysts, and developers in enterprises across the globe are looking to migrate data warehousing to the cloud to increase performance and lower costs. -

Performance at Scale with Amazon Elasticache
Performance at Scale with Amazon ElastiCache July 2019 Notices Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents current AWS product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers. © 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved. Contents Introduction .......................................................................................................................... 1 ElastiCache Overview ......................................................................................................... 2 Alternatives to ElastiCache ................................................................................................. 2 Memcached vs. Redis ......................................................................................................... 3 ElastiCache for Memcached ............................................................................................... 5 Architecture with ElastiCache for Memcached ............................................................... -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -

Performance Efficiency Pillar
Performance Efficiency Pillar AWS Well-Architected Framework Performance Efficiency Pillar AWS Well-Architected Framework Performance Efficiency Pillar: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Performance Efficiency Pillar AWS Well-Architected Framework Table of Contents Abstract and Introduction ................................................................................................................... 1 Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Performance Efficiency ....................................................................................................................... 2 Design Principles ........................................................................................................................ 2 Definition ................................................................................................................................. -
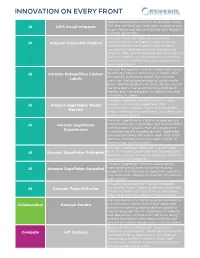
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility.