A Developer Centered Bug Prediction Model
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Applicable for the Academic Year 2020-21 Batch: 2017
Applicable for the academicyear2018-19 Batch:2015 SCHEME & SYLLABUS OF VII & VIIISEMESTERS B.E. COMPUTER SCIENCE AND ENGINEERING 2020-21 Vision and Mission of theInstitution: Vision: Dept. of CSE, SIT, Tumakuru Applicable for the academic year 2020-21 Batch: 2017 Vision and Mission of the Institution: Vision: “To develop young minds in a learning environment of high academic ambience by synergizing spiritual values and technological competence”. Mission: “To continuously strive for the total development of students by educating them in state-of-the-art technologies and helping them imbibe professional ethics and societal commitment, so that they emerge as competent professionals to meet the global challenges”. Vision and Mission of the Department: Vision: “To work towards the vision of the institution by building a strong teaching and research environment that is capable of responding to the challenges of the 21st century”. Mission: “To prepare under graduate, graduate and research students for productive careers in industry and academia, through comprehensive educational programs, research in collaboration with industry & government, dissemination by scholarly publications and professional society & co- curricular activities”. Program Educational Objectives (PEOs) Engineering graduates (CSE) will be able to: 1. Pursue successful careers in State/National/Multi-National companies as software developers by following sound professional and ethical practices in various cadres in key areas like networking, web design, cloud computing, big data processing, IoT, e-commerce, information security and so on. 2. Work effectively in multi-disciplinary and multi-cultural teams and demonstrate good soft skills. 3. Pursue higher education for a successful career in industry/academics/ research. 4. Pursue life-long learning, by anticipating trends in computer science and engineering, to excel in industry/academia or own a startup for a successful career as entrepreneur. -

Tracking Known Security Vulnerabilities in Third-Party Components
Tracking known security vulnerabilities in third-party components Master’s Thesis Mircea Cadariu Tracking known security vulnerabilities in third-party components THESIS submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in COMPUTER SCIENCE by Mircea Cadariu born in Brasov, Romania Software Engineering Research Group Software Improvement Group Department of Software Technology Rembrandt Tower, 15th floor Faculty EEMCS, Delft University of Technology Amstelplein 1 - 1096HA Delft, the Netherlands Amsterdam, the Netherlands www.ewi.tudelft.nl www.sig.eu c 2014 Mircea Cadariu. All rights reserved. Tracking known security vulnerabilities in third-party components Author: Mircea Cadariu Student id: 4252373 Email: [email protected] Abstract Known security vulnerabilities are introduced in software systems as a result of de- pending on third-party components. These documented software weaknesses are hiding in plain sight and represent the lowest hanging fruit for attackers. Despite the risk they introduce for software systems, it has been shown that developers consistently download vulnerable components from public repositories. We show that these downloads indeed find their way in many industrial and open-source software systems. In order to improve the status quo, we introduce the Vulnerability Alert Service, a tool-based process to track known vulnerabilities in software projects throughout the development process. Its usefulness has been empirically validated in the context of the external software product quality monitoring service offered by the Software Improvement Group, a software consultancy company based in Amsterdam, the Netherlands. Thesis Committee: Chair: Prof. Dr. A. van Deursen, Faculty EEMCS, TU Delft University supervisor: Prof. Dr. A. -

IBM Websphere Application Server V8 Concepts, Planning, and Design Guide
IBM® WebSphere® Front cover IBM WebSphere Application Server V8 Concepts, Planning, and Design Guide Includes details about end-to-end planning for WebSphere implementations Defines WebSphere concepts and preferred practices Addresses distributed and z/OS platforms Margaret Ticknor Alan Corcoran Balazs Csepregi-Horvath Addison Goering José Pablo Hernandez Julien Limodin Sergio Straessli Pinto ibm.com/redbooks International Technical Support Organization IBM WebSphere Application Server V8 Concepts, Planning, and Design Guide August 2011 SG24-7957-00 Note: Before using this information and the product it supports, read the information in “Notices” on page xiii. First Edition (August 2011) This edition applies to Version 8.0 of IBM WebSphere Application Server. © Copyright International Business Machines Corporation 2011. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . xiii Trademarks . xiv Preface . .xv The team who wrote this book . .xv Become a published author, too! . xvii Comments welcome. xvii Stay connected to IBM Redbooks publications . xviii Chapter 1. Introduction to WebSphere Application Server V8 . 1 1.1 Java Platform, Enterprise Edition . 2 1.2 Overview of WebSphere Application Server . 3 1.2.1 Application server purpose . 3 1.2.2 Evolving Java application development standards . 4 1.2.3 Enhanced management . 5 1.2.4 Broader integration . 7 1.2.5 Advanced tooling and extensions . 9 1.3 Packaging . 10 1.3.1 WebSphere Application Server - Express V8 . 11 1.3.2 WebSphere Application Server V8 . 11 1.3.3 WebSphere Application Server for Developers V8 . 12 1.3.4 WebSphere Application Server Network Deployment V8 . -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -
UMD) Open Source Software Packages
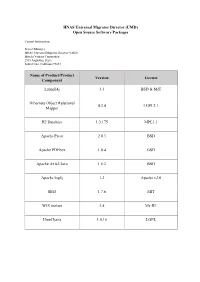
HNAS Universal Migrator Director (UMD) Open Source Software Packages Contact Information: Project Manager HNAS Universal Migrator Director (UMD) Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Launch4j 3.3 BSD & MIT Hibernate Object Relational 4.3.4 LGPL2.1 Mapper H2 Database 1.3.175 MPL1.1 Apache Pivot 2.0.3 BSD Apache PDFbox 1.8.4 BSD Apache Axis2/Java 1.6.2 BSD Apache log4j 1.2 Apache v2.0 Slf4J 1.7.6 MIT WIX toolset 3.8 Ms-RL JfreeCharts 1.0.16 LGPL The text of the open source software licenses listed in this document is provided in the Open Source Software License Terms document on www.hitachivantara.com. Note that the source code for packages licensed under the GNU General Public License or similar type of license that requires the licensor to make the source code publicly available (“GPL Software”) may be available for download as indicated. If the source code for GPL Software is not included in the software or available for download, please send requests for source code for GPL Software to the contact person listed above for this product. The material in this document is provided “AS IS,” without warranty of any kind, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. Unless specified in an applicable open source license, access to this material grants you no right or license, express or implied, statutorily or otherwise, under any patent, trade secret, copyright, or any other intellectual property right of Hitachi Vantara Corporation (“Hitachi”). -

Apache Karaf ${Karaf.Version}
Apache Karaf Version 2.2.5 Apache Karaf Users' Guide 1 Copyright 2011 The Apache Software Foundation The PDF format of the Karaf Manual has been generated by Prince XML (http://www.princexml.com). 2 Table of contents Overview Quick Start Users Guide Developers Guide 3 Overview 4 OVERVIEW Karaf Overview Apache Karaf is a small OSGi based runtime which provides a lightweight container onto which various components and applications can be deployed. Here is a short list of features supported by the Karaf: • Hot deployment: Karaf supports hot deployment of OSGi bundles by monitoring jar files inside the [home]/deploy directory. Each time a jar is copied in this folder, it will be installed inside the runtime. You can then update or delete it and changes will be handled automatically. In addition, Karaf also supports exploded bundles and custom deployers (Blueprint and Spring ones are included by default). • Dynamic configuration: Services are usually configured through the ConfigurationAdmin OSGi service. Such configuration can be defined in Karaf using property files inside the [home]/etc directory. These configurations are monitored and changes on the properties files will be propagated to the services. • Logging System: using a centralized logging back end supported by Log4J, Karaf supports a number of different APIs (JDK 1.4, JCL, SLF4J, Avalon, Tomcat, OSGi) • Provisioning: Provisioning of libraries or applications can be done through a number of different ways, by which they will be downloaded locally, installed and started. • Native OS integration: Karaf can be integrated into your own Operating System as a service so that the lifecycle will be bound to your Operating System. -

Tech Staffing Case Study
TECH STAFFING CASE STUDY A comprehensive analysis of Andiamo’s technology recruiting success with Startups. Stang Success Story Andiamo is the top-rated stang partner for over 30 elite tech startups across the country. Andiamo helps these startup clients build out their technology divisions by finding the best and brightest technologists from top universities and elite companies. Through our data-driven recruiting model, we find success by tackling hiring challenges and placing engineers and developers at the most sought after startup companies. START UP HIRING NEEDS Positions: Full Stack Developer, Software Engineer, Big Data Engineer, SRE, Technical Project Manager, Mobile Developer Technologies: Java, Scala, Ruby, Python, Javascript (Angular.JS, React.JS, Node.JS), MongoDB, AWS, Docker, Chef, Puppet, Spark, OUR DELIVERY To meet our clients’ stang needs, Andiamo helps specific teams attract and hire the POSITIONS FILLED best engineering talent in the country. We leverage massive amounts of data to conduct 49 research analyzing national hiring and salary trends which help fill niche positions. Some of the startup clients we recruit on behalf of include: 25 6 9 5 4 Full Stack TPM Software Mobile UX/UI Database Developer Engineer Dev. FLATIRON DEVELOPERS PLACED The data below represents the profiles of developers that Andiamo has placed with Startups. AVERAGE YEARS FIELD OF STUDY SCHOOLS ATTENDED OF EXPERIENCE: 11 5% • Columbia University 5% Software Information Engineering • RPI Science 3% EDUCATION 5% Economics • University of Texas at Austin Mathematics • Cornell University 8% • University of Chicago at Illinois 34% Electrical Engineering 54% 65% 9% Computer Science TECH SKILLSET 5% Computer Engineering 5% Java 2% Other Front End (Angular/React) Assoc. -

Robert Munteanu, Adobe
Cloud-Native Legacy Applications Robert Munteanu, Adobe Slides revision: 20190922-478c9cc 1 Welcome 2 About me 3 Outline Welcome Cloud-native vs legacy Managing cloud-native applications Cloud-native transformation 4 Cloud-native vs legacy 5 Cloud-native applications 6 Defining cloud-native Using cloud-native services Application-centric design Automation Cloud Native Architectures - Kamal Arora, Erik Farr, Tom Laszewski, Piyum Zonooz 7 Cloud-native services Logging: StackDriver, Centralised Logging, Logging and Auditing Routing: ELB, Azure Load Balancer, Cloud Load Balancing Block storage: Azure Blob Store, S3, Cloud Storage Databases: RDS, Cloud SQL, Azure SQL Database 8 Application-centric design 9 Automation 1. Building 2. Testing 3. Integration 4. Deployment 5. Monitoring 6. Capacity adjustment 10 LLLeeegggaaacccyyy fffooorrr eeevvveeerrryyyooonnneee 11 LLLeeegggaaacccyyy fffooorrr ppprrrooogggrrraaammmmmmeeerrrsss 12 Legacy applications legacy /ˈlɛɡəsi/ 1. an amount of money or property le to someone in a will. 2. soware or hardware that has been superseded but is difficult to replace because of its wide use https://www.lexico.com/en/definition/legacy 13 Managing cloud-native applications 14 Containers, container, containers FROM openjdk:8-jre-alpine MAINTAINER [email protected] RUN mkdir -p /opt/sling COPY target/sling-cloud-ready-*.jar /opt/sling/sling.jar WORKDIR /opt/sling EXPOSE 8080 VOLUME /opt/sling/sling ENV JAVA_OPTS -Xmx512m ENV SLING_OPTS '' CMD exec java $JAVA_OPTS -jar sling.jar $SLING_OPTS 15 Kubernetes 16 Kubernetes -

Apachecon EU 08 Fast Feather Track Presentation on Sling
Apache Sling Felix Meschberger Day Management AG [email protected] General Request Processing request ResourceResolver Resource (resource type) ServletResolver Servlet Script response Virtual Resource Tree · Based on JCR Repository · Integrates with mapped Resources ± Resources from OSGi Bundles ± Servlets and Servlet Filters registered as OSGi Services · Unified access to Data from various sources · Primary Target is the JCR Repository URI Decomposition /content/page.print.a4.html Resource Path Selectors Extension Servlet and Script Resolution · Scripts and Servlets are Equal ± Servlets registered as OSGi Services are mapped into the virtual Resource Tree ± Scripts stored in the Repository · Default Servlets (or Scripts) ± Registerable ± Fallback / Last Ressort ScriptResolver · Path to Script built from ... · Configured Path ( /apps, /libs ) · Resource Type converted to path ( nt/file ) · Selector String ( print/a4) · Request Method & MIME Type ± GET --> Request URL Extension ( html ) ± else --> Method Name ( POST, PUT, ... ) ScriptResolver Example · URI: /content/page.print.a4.html · Resource: /content/page · Resource Type: sample:page · Script for GET: ± /sling/scripts/sample/page/print/a4/html.* · Script for POST: ± /sling/scripts/sample/page/print/a4/POST.* Facts · Sling API ± No Reference to JCR API · Modular and Runtime Configurable ± OSGi Framework · Two Deployment ± Standalone Java Application ± Web Application Standalone Java Application · One single executable JAR file · Small Launcher · Starts OSGi Framework (Apache Felix) · Uses Jetty in an OSGi Bundle Web Application · Extends Standalone Application ± Replaces Command Line Support with a Servlet · Uses a Bridge to connect Sling to the Servlet Container Questions One Last Word Visit http://dev.day.com/ . -

IBM Websphere Application Server Community Edition V3.0 Helps Streamline the Creation of Osgi and Java Enterprise Edition 6 Applications
IBM United States Software Announcement 211-083, dated September 27, 2011 IBM WebSphere Application Server Community Edition V3.0 helps streamline the creation of OSGi and Java Enterprise Edition 6 applications Table of contents 1 Overview 6 Technical information 2 Key prerequisites 8 Ordering information 2 Planned availability date 9 Services 3 Description 9 Order now 6 Product positioning At a glance With WebSphere® Application Server Community Edition V3.0: • Developers can select just the components they need for optimum productivity (using OSGi and a component assembly model). • Developers can get JavaTM Enterprise Edition (Java EE) 6 applications started quickly for no charge. • System administrators are given more deployment and management options. • Organizations can take advantage of world-class, IBM® support options under a socket-based pricing model that can help reduce the cost burden in larger configurations. • You have access to a comprehensive and proven portfolio of middleware products from the WebSphere family. Overview WebSphere Application Server Community Edition V3.0 is the IBM open source- based application server that provides: • Java Enterprise Edition (Java EE) 6 support • An enterprise OSGi application programming model • Java Standard Edition (Java SE) 6 support Version 3 is built on Apache Geronimo and integrated with best-of-breed, open- source technology such as Apache Tomcat, Eclipse Equinox OSGi Framework, Apache Aries, Apache OpenEJB, Apache OpenJPA, Apache OpenWebBeans, and Apache MyFaces. Eclipse-based -

IBM Websphere Application Server Community Edition V3.0 Helps Streamline the Creation of Osgi and Java Enterprise Edition 6 Applications
IBM Canada Ltd. Software Announcement A11-0191, dated September 27, 2011 IBM WebSphere Application Server Community Edition V3.0 helps streamline the creation of OSGi and Java Enterprise Edition 6 applications Table of contents 1 Overview 6 Technical information 2 Key prerequisites 8 Ordering information 2 Planned availability date 9 Services 3 Description 10 Order now 6 Product positioning At a glance With WebSphere® Application Server Community Edition V3.0: • Developers can select just the components they need for optimum productivity (using OSGi and a component assembly model). • Developers can get JavaTM Enterprise Edition (Java EE) 6 applications started quickly for no charge. • System administrators are given more deployment and management options. • Organizations can take advantage of world-class, IBM® support options under a socket-based pricing model that can help reduce the cost burden in larger configurations. • You have access to a comprehensive and proven portfolio of middleware products from the WebSphere family. Overview WebSphere Application Server Community Edition V3.0 is the IBM open source- based application server that provides: • Java Enterprise Edition (Java EE) 6 support • An enterprise OSGi application programming model • Java Standard Edition (Java SE) 6 support Version 3 is built on Apache Geronimo and integrated with best-of-breed, open- source technology such as Apache Tomcat, Eclipse Equinox OSGi Framework, Apache Aries, Apache OpenEJB, Apache OpenJPA, Apache OpenWebBeans, and Apache MyFaces. Eclipse-based development tooling further accelerates your application development. This offering provides a flexible and simplified Java development environment. WebSphere Application Server Community Edition is suitable if your organization needs: • The ability to reduce costs of tactical deployments • Open source solutions for quick, frictionless access to application server technology with no up-front costs • A trusted vendor to provide reliable support and an upgrade path to more advanced capabilities as needed IBM Canada Ltd. -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG.