Modern Portfolio Theory – Asset Allocation with Matlab I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Portfolio Currency-Hedging Decision, by Objective and Block by Block
The portfolio currency-hedging decision, by objective and block by block Vanguard Research August 2018 Daren R. Roberts; Paul M. Bosse, CFA; Scott J. Donaldson, CFA, CFP ®; Matthew C. Tufano ■ Investors typically make currency-hedging decisions at the asset class rather than the portfolio level. The result can be an incomplete and even misleading perspective on the relationship between hedging strategy and portfolio objectives. ■ We present a framework that puts the typical asset-class approach in a portfolio context. This approach makes clear that the hedging decision depends on the strategic asset allocation decision that aligns a portfolio’s performance with an investor’s objectives. ■ A number of local market and idiosyncratic variables can modify this general rule, but this approach is a valuable starting point. It recognizes that the strategic asset allocation decision is the most important step toward meeting a portfolio’s goals. And hedging decisions that preserve the risk-and-return characteristics of the underlying assets lead to a portfolio-level hedging strategy that is consistent with the portfolio’s objectives. Investors often look at currency hedging from an asset- • The hedging framework begins with the investor’s class perspective—asking, for example, “Should I hedge risk–return preference. This feeds into the asset-class my international equity position?”1 Combining individual choices, then down to the decisions on diversification portfolio component hedging decisions results in and currency hedging. a portfolio hedge position. This begs the question: Is • Those with a long investment horizon who are a building-block approach the right way to arrive at the comfortable with equity’s high potential return and currency-hedging view for the entire portfolio? Does volatility will allocate more to that asset class. -

Six Steps to an Effective Asset Allocation Step 1
SIX STEPS TO AN EFFECTIVE ASSET ALLOCATION STEP 1 Define Your Goals Just as important as what you’re saving for is when you’ll need the money. Whether your goal is short term (up to three years), intermediate term (three to 10 years) or long term (10 years or longer) you will need to balance the amount of risk you are willing to assume with an investment strategy designed to meet your goal. The longer your time horizon, the more you should lean towards equities to take advantage of the potential returns historically associated with stock investments. The shorter your time horizon, the more you will need to weight your allocation toward fixed and cash investments to avoid the short- term volatility associated with stocks. If your aim is building retirement security, it’s important to remember that your time horizon extends far beyond the day you retire. Depending on when you retire, it is possible that your retirement will span 30 years or longer, which means your investments will need to keep working to provide future income and keep pace with inflation. Consider leaving some of your money invested in stocks, which provide the potential of growth to support your future needs. STEP 2 Gauge Your Risk Tolerance With investing, your risk tolerance should be based on two factors: your time horizon (see Step 1) and your attitude toward investment volatility. For example, if you’re not comfortable with the stock market’s inevitable ups and downs, you may be inclined to weight your portfolio toward fixed-income investments such as bonds and money markets. -

FX Effects: Currency Considerations for Multi-Asset Portfolios
Investment Research FX Effects: Currency Considerations for Multi-Asset Portfolios Juan Mier, CFA, Vice President, Portfolio Analyst The impact of currency hedging for global portfolios has been debated extensively. Interest on this topic would appear to loosely coincide with extended periods of strength in a given currency that can tempt investors to evaluate hedging with hindsight. The data studied show performance enhancement through hedging is not consistent. From the viewpoint of developed markets currencies—equity, fixed income, and simple multi-asset combinations— performance leadership from being hedged or unhedged alternates and can persist for long periods. In this paper we take an approach from a risk viewpoint (i.e., can hedging lead to lower volatility or be some kind of risk control?) as this is central for outcome-oriented asset allocators. 2 “The cognitive bias of hindsight is The Debate on FX Hedging in Global followed by the emotion of regret. Portfolios Is Not New A study from the 1990s2 summarizes theoretical and empirical Some portfolio managers hedge papers up to that point. The solutions reviewed spanned those 50% of the currency exposure of advocating hedging all FX exposures—due to the belief of zero expected returns from currencies—to those advocating no their portfolio to ward off the pain of hedging—due to mean reversion in the medium-to-long term— regret, since a 50% hedge is sure to and lastly those that proposed something in between—a range of values for a “universal” hedge ratio. Later on, in the mid-2000s make them 50% right.” the aptly titled Hedging Currencies with Hindsight and Regret 3 —Hedging Currencies with Hindsight and Regret, took a behavioral approach to describe the difficulty and behav- Statman (2005) ioral biases many investors face when incorporating currency hedges into their asset allocation. -
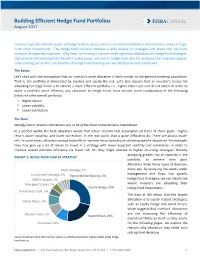
Building Efficient Hedge Fund Portfolios August 2017
Building Efficient Hedge Fund Portfolios August 2017 Investors typically allocate assets to hedge funds to access return, risk and diversification characteristics they can’t get from other investments. The hedge fund universe includes a wide variety of strategies and styles that can help investors achieve this objective. Why then, do so many investors make significant allocations to hedge fund strategies that provide the least portfolio benefit? In this paper, we look to hedge fund data for evidence that investors appear to be missing out on the core benefits of hedge fund investing and we attempt to understand why. The. Basics Let’s start with the assumption that an investor’s asset allocation is fairly similar to the general investing population. That is, the portfolio is dominated by equities and equity‐like risk. Let’s also assume that an investor’s reason for allocating to hedge funds is to achieve a more efficient portfolio, i.e., higher return per unit of risk taken. In order to make a portfolio more efficient, any allocation to hedge funds must include some combination of the following (relative to the overall portfolio): Higher return Lower volatility Lower correlation The Goal Identify return streams that deliver any or all of the three characteristics listed above. In a perfect world, the best allocators would find return streams that accomplish all three of these goals ‐ higher return, lower volatility, and lower correlation. In the real world, that is quite difficult to do. There are always trade‐ offs. In some cases, allocators accept tradeoffs to increase the probability of achieving specific objectives. -

Beyond Asset Allocation: Three Pillars of a Robust Retirement Josh Davis Managing Director Head of Client Analytics Executive Summary
IN DEPTH • JUNE 2020 AUTHORS Beyond Asset Allocation: Three Pillars of a Robust Retirement Josh Davis Managing Director Head of Client Analytics Executive Summary • Common wisdom holds that asset allocation has the biggest impact on portfolio returns. Yet for retirees, a far bigger factor is the sequence of returns in their portfolio. An uncooperative asset market early in retirement can have lifelong repercussions. • Fortunately, retirees can manage this risk with three pillars of retirement planning: a realistic, goal-oriented spending strategy; careful management of withdrawals to minimize Sean Klein Executive Vice President lifetime taxes; and an effort to maximize the value of their Social Security benefits. Client Solutions & Analytics • The effect of these three strategies, though small individually, is significant when they are combined. We estimate that a 65-year-old retiree with $1 million could enjoy up to 50% higher initial consumption and 30% higher lifetime consumption on an after-tax basis with the same level of risk. Introduction THE UNPREDICTABLE EFFECT OF ASSET ALLOCATION Despite the heavy focus it receives in the financial industry, asset allocation does not typically have the biggest impact on overall wealth in retirement. In general, additional investment risk is associated with a modestly higher chance of running out of money early in retirement, but investors should seek to offset risk with higher overall portfolio returns, which will be relied upon to sustain spending later in life. For retirees, though, this familiar investment relationship is distorted over time by taking distributions and thus spending down the portfolio. This small change can lead to many unintuitive results. -

Hedge Funds: Finding the Right Allocation
Hedge Funds: Finding the Right Allocation Some hedge funds have garnered outstanding returns in recent years, but it’s crucial to consider a number of key factors before deciding how much to invest HEDGE FUNDS REPRESENT A NEW FRONTIER FOR going to go up—the longs—but also sell short the stocks much of the broad investing public. Recent newspaper he thinks are going to go down. And hedge fund man- headlines have trumpeted their spectacular successes agers can access a variety of financial instruments, like and equally spectacular failures. So the question invest- stock and bond index futures and options, and other ment managers hear most frequently from their clients financial derivatives such as swaps, caps and floors, and comes as no surprise: How much should I invest in currency forwards. They also have the ability to tap into hedge funds? some unique investment strategies in which performance may have little to do with the general ups and downs of In order to answer that question, it’s imperative to sepa- the markets. rate the facts from the hype. There’s no question that hedge fund investments have grown tremendously, from For example, a number of hedge funds seek out returns $200 billion in 1995 to $1.1 trillion just 10 years later.1 by betting on events. Merger arbitrage funds focus on They’ve attracted investors from across the wealth spec- the outcome of mergers following this logic: Shares of trum—from professional investors like large university stocks about to be acquired can trade at a discount to endowments and pension plans to some of the world’s the offer price, reflecting the risk that the deal won’t go wealthiest families and, more and more, the so-called through. -

Is Modern Portfolio Theory Still Modern?
A reprinted article from July/August 2020 Is Modern Portfolio Theory Still Modern? By Anthony B. Davidow, CIMA® © 2020 Investments & Wealth Institute®. Reprinted with permission. All rights reserved. JULY AUGUST FEATURE 2020 Is Modern Portfolio Theory Still Modern? By Anthony B. Davidow, CIMA® odern portfolio theory (MPT) This article addresses some of the identifies a few of the more popular assumes that investors are limitations of MPT and evaluates alter- approaches and the corresponding Mrisk averse, meaning that native techniques for allocating capital. limitations. For MPT and PMPT (post- given two portfolios that offer the same Specifically, it will delve into the follow- modern portfolio theory), the biggest expected return, investors will prefer ing issues: limitation is with respect to the robust- the less risky portfolio. The implication ness and accuracy of the data used to is that a rational investor will not invest A What are the various asset allocation optimize. Using only long-term histori- in a portfolio if a second portfolio exists approaches? cal averages of the underlying asset with a more favorable profile of risk A What are the limitations of each classes is a flawed approach.Long -term versus expected return.1 approach? data should certainly be considered—but A How should advisors evolve their what if the future isn’t like the past? MPT has a number of inherent limita- approaches? tions. Investors aren’t always rational— A What is the appeal of a goals-based The long-term historical annual return and they don’t always select the right approach? of the S&P 500 has been 10.3 percent portfolio. -

Financial Analysis, Asset Allocation, and Portfolio Construction: Theory & Practice
Financial Analysis, Asset Allocation, and Portfolio Construction: Theory & Practice Hany Fahmy1, Ph.D. October 2014 1 [email protected] or [email protected]; www.hf-consulting.ca. i Copyright @ 2014 by HF Consulting Financial Analysis, Asset Allocation, and Portfolio Construction: Theory & Practice Hany Fahmy, Ph.D. This material is copyrighted and the author retains all rights. No part of this material may be reproduced or transmitted in any forms or by any means now known or later devised, or sorted in a data base or retrieval system without the prior written permission of HF Consulting, ON, Canada. W. www.hf-consulting.ca E. [email protected] Printed in Canada ISBN: 978-0-9917975-6-1 ii Acknowledgment The …nancial support of the Math Endowment Fund at University of Waterloo is gratefully acknowledged. I am indebted to Denis Chichkine1 for all his e¤orts in producing this study. In particular, his signi…cant contribution to the practical parts of Chapters 4 and 5 is highly appreciated. 1 Denis has many years of experience in the …nancial services industry. He graduated from the mathematics and business double degree program at University of Waterloo in 2009. He worked as a cross-asset fund structurer at Barclays Capital in Tokyo, Japan. Contents 1 Preface 2 2 Introduction to Investment Management 4 2.1 The Economics of Investment Management . 4 2.1.1 The Meaning of Investing . 4 2.1.2 Proprietary Investing . 6 2.1.3 Investment Managers . 6 2.2 The Portfolio Management Process . 7 3 Portfolio Planning 8 3.1 Understanding the Investor . -

Vaneck NDR Managed Allocation Fund Let's Mingle
June 2016 Let’s Mingle Get to Know the Combination of Market Indicators in the VanEck NDR Managed Allocation Fund In general, there are three broad styles of research used to assess market conditions and identify potential investment opportunities. Some people use macroeconomic research which examines the forces that impact markets or economies as a whole. Others prefer fundamental research, which aims to determine a security’s value by using company- and sector-level analysis. And lastly, there are those who rely exclusively on technical analysis, which looks at present and historical market activity, such as price levels and trading volume, to determine trends and patterns in the markets. So, which type of research should you use to guide your investment decisions? As with most questions when it comes to investing, there’s tremendous debate among the proponents of each school of thought. What is not in dispute, however, is that each of these disciplines has its advantages and, when used in conjunction, can provide complementary insight that may help effectively position a well-diversified portfolio across all market cycles. By combining macroeconomic, fundamental, and technical research, the VanEck NDR Managed Allocation Fund seeks to enhance portfolio return potential by overweighting asset classes expected to outperform and underweighting or exiting those expected to underperform. Many asset allocation strategies rely on just one type of analysis for their allocation and timing decisions. The VanEck NDR Managed Allocation Fund combines three research disciplines (macroeconomic, fundamental, and technical) using over 130 indicators to provide dynamic and thorough market analysis. vaneck.com | 800.826.2333 VanEck NDR Managed Allocation Fund A Tactical Solution to Core Asset Allocation VanEck has partnered with Ned Davis Research (NDR), a recognized leader in objective data analysis with a long history of researching financial market cycles and using technical signals to supplement macroeconomic and fundamental research. -

All About Asset Allocation
Bonds Gold All about Asset Allocation Real Estate Stock Disclaimer ‘As part of its Investor Education and Awareness Initiative, Invesco Mutual Fund has sponsored this booklet. The contents of this booklet, views, opinions and recommendations are of the publication and do not necessarily state or reflect views of Invesco Mutual Fund. The illustrations/simulations given in this booklet are for the purpose of explaining the concept of asset allocations and should not be construed as an investment advice to any party. The actual results, performance may differ from those expressed or implied in such illustrations/simulations. Invesco Mutual Fund does not accept any liability arising out of the use of this information. Mutual Fund investments are subject to market risks, read all scheme related documents carefully. Contents Basics of asset allocation .................................................................................................... 2 Finding the right mix ............................................................................................................. 3 Different assets, different risks ..................................................................................... 4 Risk profile and returns ....................................................................................................... 5 Maintaining asset allocation ............................................................................................. 6 Goal-based asset allocation ����������������������������������������������������������������������������������������������8 -

Asset Allocation
Asset Allocation Investment Advisor Strategy Group (IASG) July 2021 Quarterly Outlook: Remain OW Equities, UW Bonds, and UW Cash We all experienced a lot of change during the pandemic, including events planned for 2020 Nadeem Kassam, MBA, CFA (like the Olympic Games) being postponed until 2021. The yearlong wait for the Olympic Head of Investment Strategy Games in Tokyo is almost over, but the delay has increased the hosting price tag by about US$5.8 billion. Similarly, investors have seen quite a bit of change in the markets; however, Tavis C. McCourt, CFA with vaccination efforts picking up momentum, there is light at the end of the tunnel. Below, Institutional Equity Strategist we discuss the IASG committee’s outlook for the global economy and outline our tactical asset allocation recommendations for the next 9-12 months. Scott J. Brown, Ph.D. Chief Economist Key takeaways: Douglas Drabik . Not all countries are at the same starting line, but more and more countries are Senior Retail Fixed Income entering the race. We believe the upward revision by the Organization for Economic Strategist Co-operation and Development (OECD) for global real GDP growth to ~6% year-over- year (YoY) in 2021 is being powered largely by strength across advanced economies Ajay Virk, CFA, CMT (e.g., US, UK, Canada, etc.), which we believe are tracking ahead of their emerging Fixed Income & Foreign Exchange market peers on vaccination/reopening efforts. It also relates to fiscal/monetary policy Specialist measures. In terms of vaccinations, Canada started slow but has not only caught up to the pack but also begun to pace the race. -

ASSET ALLOCATION SOLUTIONS Build a Diversified Portfolio with One Fund
ASSET ALLOCATION SOLUTIONS Build a diversified portfolio with one fund Key benefits: 1. Simply build a diversified 2. Harness the experience of 3. Use to establish a long-term, portfolio based on risk BlackRock and the efficiency of balanced portfolio that aligns considerations, using one fund. iShares ETFs to get a broad mix with an investor's specific goals of bonds and global stocks. and risk considerations. iShares provides two simple solutions - Core and Sustainable Each iShares Asset Allocation fund offers exposure to US stocks, global stocks and bonds that rebalance back to fixed weights. iShares Core Allocation Funds iShares ESG Aware Allocation Funds Each fund holds an underlying portfolio of iShares Core Each fund holds an underlying portfolio of iShares ESG Funds (Figure 2). iShares Core ETFs are broad stock and Aware funds (Figure 3). iShares ESG Aware ETFs balance bond exposures that seek to track quality, seeking similar risk and return to the relevant broad established indexes. market with seeking a more sustainable outcome. iShares Core Conservative Allocation ETF iShares ESG Aware Conservative Allocation ETF AOK Expense ratio1: 0.25% EAOK Expense ratio1: 0.18% Index: S&P Target Risk Conservative Index Index:BlackRock ESG Aware Conservative Allocation Index iShares Core Moderate Allocation ETF iShares ESG Aware Moderate Allocation ETF AOM Expense ratio1: 0.25% EAOM Expense ratio1: 0.18% Index: S&P Target Risk Moderate Index Index:BlackRock ESG Aware Moderate Allocation Index iShares Core Growth Allocation ETF iShares Core Growth Allocation ETF AOR Expense ratio1: 0.25% EAOR Expense ratio1: 0.18% Index: S&P Target Risk Growth Index Index:BlackRock ESG Aware Growth Allocation Index iShares Core Aggressive Allocation ETF iShares Core Aggressive Allocation ETF AOA Expense ratio1: 0.25% EAOA Expense ratio1: 0.18% Index: S&P Target Risk Aggressive Index Index:BlackRock ESG Aware Aggressive Allocation Index 1 Net expense ratios shown.