Development Testing Platform Engines for C/C++ User's Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Types of Software Testing
Types of Software Testing We would be glad to have feedback from you. Drop us a line, whether it is a comment, a question, a work proposition or just a hello. You can use either the form below or the contact details on the rightt. Contact details [email protected] +91 811 386 5000 1 Software testing is the way of assessing a software product to distinguish contrasts between given information and expected result. Additionally, to evaluate the characteristic of a product. The testing process evaluates the quality of the software. You know what testing does. No need to explain further. But, are you aware of types of testing. It’s indeed a sea. But before we get to the types, let’s have a look at the standards that needs to be maintained. Standards of Testing The entire test should meet the user prerequisites. Exhaustive testing isn’t conceivable. As we require the ideal quantity of testing in view of the risk evaluation of the application. The entire test to be directed ought to be arranged before executing it. It follows 80/20 rule which expresses that 80% of defects originates from 20% of program parts. Start testing with little parts and extend it to broad components. Software testers know about the different sorts of Software Testing. In this article, we have incorporated majorly all types of software testing which testers, developers, and QA reams more often use in their everyday testing life. Let’s understand them!!! Black box Testing The black box testing is a category of strategy that disregards the interior component of the framework and spotlights on the output created against any input and performance of the system. -

Smoke Testing What Is Smoke Testing?
Smoke Testing What is Smoke Testing? Smoke testing is the initial testing process exercised to check whether the software under test is ready/stable for further testing. The term ‘Smoke Testing’ is came from the hardware testing, in the hardware testing initial pass is done to check if it did not catch the fire or smoked in the initial switch on.Prior to start Smoke testing few test cases need to created once to use for smoke testing. These test cases are executed prior to start actual testing to checkcritical functionalities of the program is working fine. This set of test cases written such a way that all functionality is verified but not in deep. The objective is not to perform exhaustive testing, the tester need check the navigation’s & adding simple things, tester needs to ask simple questions “Can tester able to access software application?”, “Does user navigates from one window to other?”, “Check that the GUI is responsive” etc. Here are graphical representation of Smoke testing & Sanity testing in software testing: Smoke Sanity Testing Diagram The test cases can be executed manually or automated; this depends upon the project requirements. In this types of testing mainly focus on the important functionality of application, tester do not care about detailed testing of each software component, this can be cover in the further testing of application. The Smoke testing is typically executed by testers after every build is received for checking the build is in testable condition. This type of testing is applicable in the Integration Testing, System Testing and Acceptance Testing levels. -

A Framework and Tool Supports for Generating Test Inputs of Aspectj Programs
A Framework and Tool Supports for Generating Test Inputs of AspectJ Programs Tao Xie Jianjun Zhao Department of Computer Science Department of Computer Science & Engineering North Carolina State University Shanghai Jiao Tong University Raleigh, NC 27695 Shanghai 200240, China [email protected] [email protected] ABSTRACT 1. INTRODUCTION Aspect-oriented software development is gaining popularity with Aspect-oriented software development (AOSD) is a new tech- the wider adoption of languages such as AspectJ. To reduce the nique that improves separation of concerns in software develop- manual effort of testing aspects in AspectJ programs, we have de- ment [9, 18, 22, 30]. AOSD makes it possible to modularize cross- veloped a framework, called Aspectra, that automates generation of cutting concerns of a software system, thus making it easier to test inputs for testing aspectual behavior, i.e., the behavior imple- maintain and evolve. Research in AOSD has focused mostly on mented in pieces of advice or intertype methods defined in aspects. the activities of software system design, problem analysis, and lan- To test aspects, developers construct base classes into which the guage implementation. Although it is well known that testing is a aspects are woven to form woven classes. Our approach leverages labor-intensive process that can account for half the total cost of existing test-generation tools to generate test inputs for the woven software development [8], research on testing of AOSD, especially classes; these test inputs indirectly exercise the aspects. To enable automated testing, has received little attention. aspects to be exercised during test generation, Aspectra automati- Although several approaches have been proposed recently for cally synthesizes appropriate wrapper classes for woven classes. -

Parasoft Dottest REDUCE the RISK of .NET DEVELOPMENT
Parasoft dotTEST REDUCE THE RISK OF .NET DEVELOPMENT TRY IT https://software.parasoft.com/dottest Complement your existing Visual Studio tools with deep static INCREASE analysis and advanced PROGRAMMING EFFICIENCY: coverage. An automated, non-invasive solution that the related code, and distributed to his or her scans the application codebase to iden- IDE with direct links to the problematic code • Identify runtime bugs without tify issues before they become produc- and a description of how to fix it. executing your software tion problems, Parasoft dotTEST inte- grates into the Parasoft portfolio, helping When you send the results of dotTEST’s stat- • Automate unit and component you achieve compliance in safety-critical ic analysis, coverage, and test traceability testing for instant verification and industries. into Parasoft’s reporting and analytics plat- regression testing form (DTP), they integrate with results from Parasoft dotTEST automates a broad Parasoft Jtest and Parasoft C/C++test, allow- • Automate code analysis for range of software quality practices, in- ing you to test your entire codebase and mit- compliance cluding static code analysis, unit testing, igate risks. code review, and coverage analysis, en- abling organizations to reduce risks and boost efficiency. Tests can be run directly from Visual Stu- dio or as part of an automated process. To promote rapid remediation, each problem detected is prioritized based on configur- able severity assignments, automatical- ly assigned to the developer who wrote It snaps right into Visual Studio as though it were part of the product and it greatly reduces errors by enforcing all your favorite rules. We have stuck to the MS Guidelines and we had to do almost no work at all to have dotTEST automate our code analysis and generate the grunt work part of the unit tests so that we could focus our attention on real test-driven development. -

Software Engineer Is .Jusiak.Net Kr Is @Jusiak.Net (0) 791-384-1386
Krzysztof (Kris) Jusiak Software Engineer http://kr is .jusiak.net kr is @jusiak.net (0) 791-384-1386 Education 2005 - 2010 Wroclaw University of Technology Wroclaw (Poland) MSc in Computer Science, specialised in Software Engineering (Top grade) Employment 2013 – Present King London (United Kingdom) Game/Software Developer (Mobile) King is a worldwide leader in casual games with more than 30 billion games played per month globally. We are a leading interactive entertainment company for the mobile world. Our mission is to provide highly engaging content to our audience to match their mobile lifestyles: anywhere, anytime, through any platform and on any device. Software Developer in a scrum team responsible for development and releases of mobile games played by millions active daily players. 90% of my job is focused on developing software using C++14 standard for different platforms such as, iOS, Android and Facebook (HTML5 - Emscripten). My core role is to provide high quality features and review/refactor already implemented. I am also involved in recruitment process by being a technical expert on interviews. I have done a lot of improvements to the projects I have been involved in, such as, performance/compile times optimizations, introduction of static analysis tools as well as a replacement of Service Locator pattern by Dependency Injection. • Implementing and releasing multi-platform games played by more than 100 millions active daily players • Reduced time to render the textures by 10% by changing loading files caching mechanism • Implemented an integration test framework which eliminated commonly reoccurring issues 2009 – 2013 Nokia Networks Wroclaw (Poland) Software Engineer Nokia Networks is the world’s specialist in mobile broadband, which helps enable end users to do more than ever before with the world’s most efficient mobile networks, the intelligence to maximize their value and the services to make it all work together. -

Code Structure by Miklos Vajna Senior Software Engineer at Collabora Productivity 2017-10-11
LibreOffice: Code Structure By Miklos Vajna Senior Software Engineer at Collabora Productivity 2017-10-11 @CollaboraOffice www.CollaboraOffice.com About Miklos ● From Hungary ● More blurb: http://vmiklos.hu/ ● Google Summer of Code 2010/2011 ● Rewrite of the Writer RTF import/export ● Writer developer since 2012 ● Contractor at Collabora since 2013 LibreOffice Conference 2017, Rome | Miklos Vajna 2 / 30 Thanks ● This is an updated version of Michael Meeks’ talk from last year LibreOffice Conference 2017, Rome | Miklos Vajna 3 / 30 Overview ● Code-base overview ● Internal core modules, internal leaf ● Ignoring externals ● Building / packaging: gnumake, scp2 ● Code organisation, git bits ● Keep in mind: this is a 20 years old code-base ● The quality is much better than you would expect after knowing its age ● Things continue to improve over time LibreOffice Conference 2017, Rome | Miklos Vajna 4 / 30 Module overview lowest level Internal non-leaf modules: UNO modules ● Module = toplevel dir ● make dumps-deps-png ● Each module has a README ● e.g. sal/README ● sal: at the bottom ● The system abstraction layer ● tools is an obsolete internal (more or less) duplication of this ● salhelper: wrapper code around sal, also part of the URE LibreOffice Conference 2017, Rome | Miklos Vajna 6 / 30 What is the Uno Runtime Environment (URE)? ● We’ll come to UNO in detail a bit later, but for now: ● Uno Runtime Environment ● See also JRE, Java Runtime Env. ● Belongs to the idea that UNO would be reused somewhere else ● Provides an API/ABI-stable abstraction layer for the suite URE ● Allows writing C++ extensions ● Modify carefully: ● Should not change the ABI ● ABI control via C .map files LibreOffice Conference 2017, Rome | Miklos Vajna 7 / 30 UNO modules ● store: legacy .rdb format ● registry: UNO type regisistry ● unoidl: a .idl file compiler ● cppu: C++ UNO ● Implements basic UNO types and infrastructure for C++, e.g. -
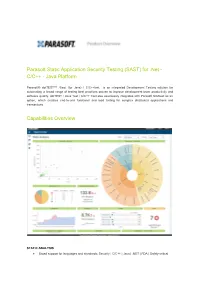
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

Case Study Test the Untestable: Alaska Airlines Solves
CASE STUDY Testing the Untestable Alaska Airlines Solves the Test Environment Dilemma Case Study Testing the Untestable Alaska Airlines Solves the Test Environment Dilemma OVERVIEW Alaska Airlines is primarily a West Coast carrier that services the states of Alaska and Hawaii with mid-continent and destinations in Canada and Mexico. Alaska Airlines received J.D. Powers' “Highest in Customer Satisfaction Among Traditional Carriers” recognition for twelve years in a row even recently winning first in all but one of the seven categories. A large part of the credit belongs to their software testing team. Their industry-leading, proactive approach to disrupting the traditional software testing process ensures that testers can test faster, earlier, and more completely. Learn how Ryan Papineau and his team used advanced automation in concert with service virtualization to rigorously test their complex flight operations manager software. The result: operations that run smoothly— even if they encounter a snowstorm in July. RELIABLE & ON-DEMAND FALSE REPEATABLE TESTS AUTOMATED TEST CASES POSITIVES 100欥 500 ELIMINATED 2 Case Study Testing the Untestable Alaska Airlines Solves the Test Environment Dilemma THE CHALLENGES At Alaska Airlines, the flight operations manager software is ultimately responsible for transporting 46 million customers to 115 global destinations via approximately 440,000 flights per year, safely and efficiently. This software coordinates a highly complex set of inputs from systems around the organization to ensure flights are on time while evaluating and managing fuel, cargo, baggage, and passenger requirements. In addition to the previously mentioned requirements, the system considers many factors including weather, aircraft characteristics, market, and fuel costs. -

Erik Lindahl
HPC Software Engineering Erik Lindahl XSEDE/PRACE/RIKEN/SciNet HPC Summer School Ostrava, CZ, 2018 Extra Q & A session: Here (or outside at the tables) 12.45 today! “The application of a systematic, disciplined, quantifiable approach to the development, operation and maintenance of software, and the study of these approaches, that is, the application of engineering to software.” Experiences from 20 years of GROMACS development The GROMACS picture until early 2011 Source code repository: • Simulation hardware project, turned software CVS • Early development based on our own needs • Turned GPL in 2001, LGPL in 2012 Build Chain: • Organic growth of development Automake/Autoconf/libtool • Roughly 10-15 core developers Bug Tracking: • Another 15-20 active contributors Bugzilla • Currently 3,076,420 lines of C++11 code (“C++11”) • Over the years we have used Fortran, C, Assembly Testing: • Lots of old code. Lots of new code. Lots of complicated (read: bad) code written by scientists Software Scientist engineer • Trained in physics, • Trained in CS/software chemistry, etc. • Care about their problem • Care about their code • Care about short-term • Care about long-term deadlines maintenance • New code = asset • New code = liability • Writes more code than • Reads much more code she reads than she writes Without proper software engineering, we are building a technical debt that sooner or later will have to be paid. “Technical Debt is a wonderful metaphor developed by Ward Cunningham to help us think about this problem. In this metaphor, doing things the quick and dirty way sets us up with a technical debt, which is similar to a financial debt. -

Art-Workbook-V0 84
Intensity Frontier Common Offline Documentation: art Workbook and Users Guide Alpha Release 0.84 August 18, 2014 This version of the documentation is written for version v0_00_27 of the art-workbook code. Scientific Computing Division Future Programs and Experiments Department Scientific Software Infrastructure Group Principal Author: Rob Kutschke Editor: Anne Heavey art Developers: L. Garren, C. Green, J. Kowalkowski, M. Paterno and P. Russo 1 2 List of Chapters Detailed Table of Contents iv List of Figures xx List of Tables xxii List of Code and Output Listings xxii art Glossary xxvii I Introduction 1 1 How to Read this Documentation 2 2 Conventions Used in this Documentation 4 3 Introduction to the art Event Processing Framework 7 4 Unix Prerequisites 34 5 Site-Specific Setup Procedure 45 i 6 Get your C++ up to Speed 47 7 Using External Products in UPS 107 II Workbook 119 8 Preparation for Running the Workbook Exercises 120 9 Exercise 1: Running Pre-built art Modules 124 10 Exercise 2: Building and Running Your First Module 163 11 General Setup for Login Sessions 220 12 Keeping Up to Date with Workbook Code and Documentation 222 13 Exercise 3: Some other Member Functions of Modules 228 14 Exercise 4: A First Look at Parameter Sets 240 15 Exercise 5: Making Multiple Instances of a Module 265 16 Exercise 6: Accessing Data Products 272 17 Exercise 7: Making a Histogram 291 18 Exercise 8: Looping Over Collections 317 19 3D Event Displays 341 20 Troubleshooting 377 ii III User’s Guide 379 21 Obtaining Credentials to Access Fermilab Computing Resources 380 22 git 382 23 art Run-time and Development Environments 391 24 art Framework Parameters 399 25 Job Configuration in art: FHiCL 405 IV Appendices 424 A art Completion Codes 425 B Viewing and Printing Figure Files 428 C CLHEP 430 D Include Guards 446 V Index 448 Index 449 iii Detailed Table of Contents Detailed Table of Contents iv List of Figures xx List of Tables xxii List of Code and Output Listings xxii art Glossary xxvii I Introduction 1 1 How to Read this Documentation 2 1.1 If you are new to HEP Software.. -

How Google Tests Software
How Google Tests Software James Whittaker Jason Arbon Jeff Carollo • nTr Addison-Wesley Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City ' ' ^ : Г: С : '. , Table of Contents Foreword by Alberto Savoia Xlll Foreword by Patrick Copeland xvii Preface ХХШ Chapter 1 Introduction to Google Software Testing 1 Quality^Test 5 Roles 6 Organizational Structure 8 Crawl, Walk, Run 10 Types of Tests 12 Chapter 2 The Software Engineer in Test 15 The Life of an SET 17 Development and Test Workflow 17 Who Are These SETs Anyway? 22 The Early Phase of a Project 22 Team Structure 24 Design Docs 25 Interfaces and Protocols 27 Automation Planning 28 Testability 29 SET Workflow: An Example 32 Test Execution 40 Test Size Definitions 41 Use of Test Sizes in Shared Infrastructure 44 Benefits of Test Sizes 46 Test Runtime Requirements 48 Case 1: Change in Common Library 52 Test Certified 54 An Interview with the Founders of the Test Certified Program 57 Interviewing SETs 62 An Interview with Tool Developer Ted Mao 68 An Interview with Web Driver Creator Simon Stewart 70 How Google Tests Software Chapter 3 The Test Engineer 75 A User-Facing Test Role 75 The Life of а ТЕ 76 Test Planning 79 Risk 97 Life of a Test Case 108 Life of a Bug 113 Recruiting TEs 127 Test Leadership at Google 134 Maintenance Mode Testing 137 Quality Bots Experiment 141 BITE Experiment 153 Google Test Analytics 163 Free Testing Workflow 169 External Vendors 173 -

Software Testing: Essential Phase of SDLC and a Comparative Study Of
International Journal of System and Software Engineering Volume 5 Issue 2, December 2017 ISSN.: 2321-6107 Software Testing: Essential Phase of SDLC and a Comparative Study of Software Testing Techniques Sushma Malik Assistant Professor, Institute of Innovation in Technology and Management, Janak Puri, New Delhi, India. Email: [email protected] Abstract: Software Development Life-Cycle (SDLC) follows In the software development process, the problem (Software) the different activities that are used in the development of a can be dividing in the following activities [3]: software product. SDLC is also called the software process ∑ Understanding the problem and it is the lifeline of any Software Development Model. ∑ Decide a plan for the solution Software Processes decide the survival of a particular software development model in the market as well as in ∑ Coding for the designed solution software organization and Software testing is a process of ∑ Testing the definite program finding software bugs while executing a program so that we get the zero defect software. The main objective of software These activities may be very complex for large systems. So, testing is to evaluating the competence and usability of a each of the activity has to be broken into smaller sub-activities software. Software testing is an important part of the SDLC or steps. These steps are then handled effectively to produce a because through software testing getting the quality of the software project or system. The basic steps involved in software software. Lots of advancements have been done through project development are: various verification techniques, but still we need software to 1) Requirement Analysis and Specification: The goal of be fully tested before handed to the customer.