Arxiv:1705.10120V1 [Cs.CV] 29 May 2017 and Are Close to Human-Level Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PRODUCTION NOTES for Additional Publicity Materials and Artwork, Please Visit
PRODUCTION NOTES For additional publicity materials and artwork, please visit: http://lionsgatepublicity.com/theatrical/draggedacrossconcrete/ Rating: Rated R for strong violence, grisly images, language, and some sexuality/nudity Run Time: 158 minutes U.S. Release Date: March 22, 2019 (In Theaters and On Demand) For more information, please contact: Liz Berger Lionsgate 2700 Colorado Avenue Santa Monica, CA 90404 P: 310-255-3092 E: [email protected] DRAGGED ACROSS CONCRETE SUMMIT ENTERTAINMENT Publicity Materials: http://lionsgatepublicity.com/theatrical/draggedacrossconcrete/ Hashtag: #DraggedAcrossConcrete Genre: Action Thriller Rating: Rated R for strong violence, grisly images, language, and some sexuality/nudity U.S. Release Date: March 22, 2019 (In Theaters and On Demand) Run Time: 158 minutes Cast: Mel Gibson, Vince Vaughn, Tory Kittles, Michael Jai White, Jennifer Carpenter, Laurie Holden, Fred Melamed, with Thomas Kretschmann, and Don Johnson Written and Directed by: S. Craig Zahler Produced by: Keith Kjarval, p.g.a., Dallas Sonnier, p.g.a., Jack Heller, Tyler Jackson, Sefton Fincham SYNOPSIS: DRAGGED ACROSS CONCRETE follows two police detectives who find themselves suspended when a video of their strong-arm tactics is leaked to the media. With little money and no options, the embittered policemen descend into the criminal underworld and find more than they wanted waiting in the shadows. Summit Entertainment presents, a Unified Pictures production, a Cinestate production, in association with Look to the Sky Films and The Fyzz Facility, in association with Realmbuilder Productions. Synopsis DRAGGED ACROSS CONCRETE follows two police detectives who find themselves suspended when a video of their strong-arm tactics is leaked to the media. -

Southwest Gas Corporation A+ Total Care Canyon Construction
Hours of Operation: Monday – Friday, 8:00 am – 4:00 pm Board of Directors MISSION STATEMENT: To provide nutritious meals, socialization, Jennifer Back health screening, and education. We act as a catalyst for access, Chair opportunity, health and independence for older adults. Cindy Hyslop Vice Chair Thank you to everyone who helped spread the word and to those who came to play games, dine with us, and volunteer hours. We Catherine Vosburg Member couldn’t do this without your support and encouragement. Katrinka Russell Member Vicki Salazar Member Center Staff Charnice Gustafson Interim Director Please join me as we publicly recognize the sponsors who generously donated to make this event possible: Carissa Cassadore Program Coordinator Southwest Gas Corporation Marjorie Birdsill Lead Cook A+ Total Care Candi Ashby Kitchen Aide / Driver Canyon Construction Josie O’Donnell Highland Estates Kitchen Aide / Driver Pizza Barn Debbi Constable Kitchen Aide / Driver PACE Coalition Jesse Morgan Dishwasher Maggie Creek Ranch Total Eyecare Nevada Bank & Trust Read & Powell Family Dental Care 1 | P a g e The Terrace at Ruby View | 775-738-3030 1795 Ruby View Dr. Elko | www.elkoseniors.org August 2019 August Birthday Celebrations Paris, Rama 1 Vaughan, Johnnie 10 Hauser, Laura 20 Church, Susan 1 Solari, Gloria 11 Johnson, Diana 20 Mayer, Mary 1 Huston, Sally 11 Stanton, Jim 20 Hankins, Helen 2 Shurtliff, Janis 11 Konakis, Stanley 20 Farnsworth, Susanna 2 Patton, Ann 11 Hartley, David 21 Reitmeier, Donald 2 Reynolds, Dea Ann 11 Parman, Thetis 21 Stone, -

A Serious Man (2009)
A Serious Man (2009) “Receive with simplicity everything that happens” --Rashi Major Credits: Directors: Joel and Ethan Coen Script: Joel and Ethan Coean Cinematography: Roger Deakins Editing: Roderick Jaynes (pseudonym for Joel and Ethan Coen) Music: Carter Burwell Cast: Michael Stuhlbarg (Larry Gopnik); Richard Kind (Uncle Arthur); Fred Melamed (Sy Abelman); Sari Lennick (Judith Gopnik); Amy Landecker (Mrs. Samsky) Background: Following the success of No Country for Old Men (2007), the Coen brothers felt free to return to an uncharacteristically personal story that they had been thinking about for many years. Set in 1967 in an upper Midwest suburbia like the one outside Minneapolis in which they were raised, A Serious Man draws upon Joel’s and Ethan’s memories as it re-tells the Biblical tale of Job. Although generally praised by critics (earning a Best Picture nomination from the Academy under its newly expanded system of selecting ten movies instead of five), the film, perhaps not surprisingly, did not generate the same buzz as their multiple Oscar-winning Western. Nevertheless, it remains one of their most skillfully crafted works, one that manages to be both painfully funny and deeply disturbing. Its reputation will almost surely grow. Cinematic Elements: 1. The Yiddish prologue, with its narrowed frame, sepia tone, and focused lighting, evokes both the style of silent movies and the vernacular language and storytelling of the Yiddish theatre. Although the Coens have explicitly denied any relevance to the modern story, the prologue clearly resonates with the themes and tone of the rest of A Serious Man. 2. Music: The Coens again collaborate with their favorite composer, Carter Burwell, and the film’s eclectic score—from the Jefferson Airplane’s “Don’t You Want Somebody to Love” to Sidor Belarsky’s melancholy Yiddish song “The Miller’s Tears”—reinforces the film’s shifts from hallucination and dream to comedy and melodrama. -

Reminder List of Productions Eligible for the 90Th Academy Awards Alien
REMINDER LIST OF PRODUCTIONS ELIGIBLE FOR THE 90TH ACADEMY AWARDS ALIEN: COVENANT Actors: Michael Fassbender. Billy Crudup. Danny McBride. Demian Bichir. Jussie Smollett. Nathaniel Dean. Alexander England. Benjamin Rigby. Uli Latukefu. Goran D. Kleut. Actresses: Katherine Waterston. Carmen Ejogo. Callie Hernandez. Amy Seimetz. Tess Haubrich. Lorelei King. ALL I SEE IS YOU Actors: Jason Clarke. Wes Chatham. Danny Huston. Actresses: Blake Lively. Ahna O'Reilly. Yvonne Strahovski. ALL THE MONEY IN THE WORLD Actors: Christopher Plummer. Mark Wahlberg. Romain Duris. Timothy Hutton. Charlie Plummer. Charlie Shotwell. Andrew Buchan. Marco Leonardi. Giuseppe Bonifati. Nicolas Vaporidis. Actresses: Michelle Williams. ALL THESE SLEEPLESS NIGHTS AMERICAN ASSASSIN Actors: Dylan O'Brien. Michael Keaton. David Suchet. Navid Negahban. Scott Adkins. Taylor Kitsch. Actresses: Sanaa Lathan. Shiva Negar. AMERICAN MADE Actors: Tom Cruise. Domhnall Gleeson. Actresses: Sarah Wright. AND THE WINNER ISN'T ANNABELLE: CREATION Actors: Anthony LaPaglia. Brad Greenquist. Mark Bramhall. Joseph Bishara. Adam Bartley. Brian Howe. Ward Horton. Fred Tatasciore. Actresses: Stephanie Sigman. Talitha Bateman. Lulu Wilson. Miranda Otto. Grace Fulton. Philippa Coulthard. Samara Lee. Tayler Buck. Lou Lou Safran. Alicia Vela-Bailey. ARCHITECTS OF DENIAL ATOMIC BLONDE Actors: James McAvoy. John Goodman. Til Schweiger. Eddie Marsan. Toby Jones. Actresses: Charlize Theron. Sofia Boutella. 90th Academy Awards Page 1 of 34 AZIMUTH Actors: Sammy Sheik. Yiftach Klein. Actresses: Naama Preis. Samar Qupty. BPM (BEATS PER MINUTE) Actors: 1DKXHO 3«UH] %LVFD\DUW $UQDXG 9DORLV $QWRLQH 5HLQDUW] )«OL[ 0DULWDXG 0«GKL 7RXU« Actresses: $GªOH +DHQHO THE B-SIDE: ELSA DORFMAN'S PORTRAIT PHOTOGRAPHY BABY DRIVER Actors: Ansel Elgort. Kevin Spacey. Jon Bernthal. Jon Hamm. Jamie Foxx. -

See 2016 Guide: That's Voiceover!
We want to take you higher. NOV 12&13 2016 WARNER BROS STUDIOS Hosted by SCOTT PARKIN and BURBANK CA JOAN BAKER Audition. Learn. Network. Join Celebrated Voice Actors, Creative Directors, Talent Agents and Casting Directors and Ignite Your Career! © 2016 Society of Voice Arts And Sciences™ DAY-AT-A-GLANCE 9:00 am 2:00 pm Registration Backstage Vanguard Award for Outstanding Agenting 10:00 am & Business Leadership Performance Palooza – Voiceover Showcase Presented Celebrate with Super agent Ken Slevin, CEO & President of CESD By the HEAR Now Festival and SueMedia Productions Talent, when he receives the Backstage Vanguard Award for Outstanding Agenting and Business Leadership. Then listen in for a revealing interview about what it takes to provide successful agenting Voice Arts® Award nominated director Sue Zizza and master Foley artist and audio for voice actors. Hear from one of the best in the world about how engineer David Shinn choreograph a live audio theater production, featuring an agents work, what they look for and how voice actors can best acquire All-Voice Arts® Award Nominated Ensemble of voiceover greats: Scott Brick, Hillary agent representation. It’s a conversation that could supercharge your Hubert, PJ Ochlan, Kyla Garcia and the unflappable Phil Proctor. career and inspire your success. 10:45 am Crash Course Audiobook MBA: Getting Smarter About MIDDAY Your Success Sr. Manager of Marketing for ACX, Hannah Wall hosts an all-star team of audiobook award-winners to take you from the ground floor to the top of 3:00 pm – 6:00 pm your game. Bridging the education gap is the magic key for the successful Exhibitors Reception audiobook narrator. -

Psych Film Paper (Honors Project #1).Doc.Docx
Name:_______________________________ Block:____ Date:___________________ PSYCHOLOGY: ANALYTICAL RESEARCH PAPER Objective – Compare & contrast the real effects of the psychological disorder(s) shown in the film. DIRECTIONS: In this assignment you will choose one film related to Psychology and complete a well- developed analytical research paper, based on both the film of your choice, and a profile of the psychological disorder(s) depicted in the film. Pay close attention while taking notes during the film to help you with both assignments. You will also do in depth research on your films topic online to see how the actual events compare to the film. Your paragraphs should correspond to the format below. Format: 1. Introduction with a thesis statement. 2. After viewing the film describe what the movie is about. What is the key plot in the film? Who are the characters in the film? 3. Explain how the psychological disorder(s) in the film are accurately and/or inaccurately portrayed in the film through your in depth online research. 4. Describe (in depth) the causes/effects and other related information associated with the disorder. 5. Conclusion. Explain your own opinion of the film. Would you recommend it? Why or why not? Additional Requirements: 1. Notes taken during movie 2. 3 full pages, MLA format 3. Typed, double spaced, 12 font, Times New Roman, 1 inch margins 4. Well written with proper grammar, spelling etc. 5. Well researched with accurate information 6. Works cited page (minimum of 3 online sources) 7. Presentation of Paper Parental Advisory – Some films on this list are Rated R and need parental permission. -

Marge Simpson (P=0.858966) Fuzzy Lookup: Marge (D=0), Margay (D=2), Margaz (D=2) List of Supporting Harry Potter Characters Marge (Cartoonist) Marge Burns
YodaQA Technology Outline ● Factoid QA & YodaQA ● YodaQA Architecture: ○ Question Analysis ○ Database Search ○ Answer Scoring Factoid QA & YodaQA Factoid QA Extension of search, but: ● naturally phrased question instead of keywords ● output is not a whole document, but just the snippet of information Ideal for voice: ● people ask in whole sentences ● we reply with just what the user needs to know Our work in QA Medialab / eClub Petr Baudiš + several undergrad students (→ ~24 man-months) Jan Pichl YodaQA: ● universal end-to-end QA pipeline with basic functionality ● research vehicle for more advanced strategies ● machine learning instead of hardcoded rules ● Java, Apache UIMA, Apache Solr, RDF/SPARQL ● proof-of-concept web+mobile interface, public live demo Factoid QA Datasets Text data (unstructured): initial focus Wikipedia, websites NLP, information extraction problem Databases (RDF graph): current work, today’s topic DBpedia (Wikipedia infoboxes) Freebase (Google Knowledge Graph) → movie questions Synthesis is possible (and done!) YodaQA Operation Principles ● Question Analysis ● Database Search ● Generate many candidate answers ● Answer Typing & Scoring Question Analysis Who played Marge Example in The Simpsons? NLP Analysis Output: linguistic representation of the question ● OpenNLP segmenter ● StanfordParser (pos + dependencies + constituents) ● LanguageTool lemmatizer ● OpenNLP NER off-the-shelf models: person, place, date, … NLP Analysis Who played Marge in The Simpsons? c ROOT null [Who played Marge in The Simpsons?] c SBARQ null [Who played Marge in The Simpsons?] c WHNP null [Who] t WP who [Who] c SQ null [played Marge in The Simpsons] c VP null [played Marge in The Simpsons] t VBD play [played] c NP null [Marge] t NNP Marge [Marge] c PP null [in The Simpsons] t IN in [in] c NP null [The Simpsons] t DT the [The] t NNP Simpsons [Simpsons] t . -
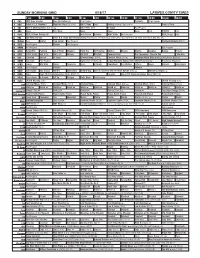
Sunday Morning Grid 6/18/17 Latimes.Com/Tv Times
SUNDAY MORNING GRID 6/18/17 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Paid Program Celebrity Paid Program 4 NBC Today in L.A. Weekend Meet the Press (N) (TVG) NBC4 News Paid Sailing America’s Cup. (N) Å Track & Field 5 CW KTLA 5 Morning News at 7 (N) Å KTLA News at 9 In Touch Paid Program 7 ABC News This Week News News News Paid XTERRA Paid 9 KCAL KCAL 9 News Sunday (N) Joel Osteen Schuller Mike Webb Paid Program REAL-Diego Paid 11 FOX Fox News Sunday 2017 U.S. Open Golf Championship Final Round. The final round of the 2017 U.S. Open tees off. From Erin Hills in Erin, Wis. (N) 13 MyNet Paid Matter Fred Jordan Paid Program Northern Borders (2013) 18 KSCI Paid Program Church Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Paint With Painting Joy of Paint Wyland’s Paint This Oil Painting Kitchen Mexico Martha Cooking Baking Project 28 KCET 1001 Nights Bali (TVG) Bali (TVY) Edisons Biz Kid$ Biz Kid$ Concrete River The Carpenters: Close to You Pavlo Live 30 ION Jeremiah Youseff In Touch Criminal Minds (TV14) Criminal Minds (TV14) Tomorrow Never Dies ››› (1997) Pierce Brosnan. 34 KMEX Conexión Paid Program Como Dice el Dicho (N) El Que No Corre Vuela (1982) María Elena Velasco. República Deportiva 40 KTBN James Win Walk Prince Carpenter Jesse In Touch PowerPoint It Is Written Jeffress Super Kelinda John Hagee 46 KFTR Paid Program Película Película 50 KOCE Odd Squad Odd Squad Martha Cyberchase Clifford-Dog Eat Fat, Get Thin With Dr. -

Completeandleft
MEN WOMEN 1. JA Jason Aldean=American singer=188,534=33 Julia Alexandratou=Model, singer and actress=129,945=69 Jin Akanishi=Singer-songwriter, actor, voice actor, Julie Anne+San+Jose=Filipino actress and radio host=31,926=197 singer=67,087=129 John Abraham=Film actor=118,346=54 Julie Andrews=Actress, singer, author=55,954=162 Jensen Ackles=American actor=453,578=10 Julie Adams=American actress=54,598=166 Jonas Armstrong=Irish, Actor=20,732=288 Jenny Agutter=British film and television actress=72,810=122 COMPLETEandLEFT Jessica Alba=actress=893,599=3 JA,Jack Anderson Jaimie Alexander=Actress=59,371=151 JA,James Agee June Allyson=Actress=28,006=290 JA,James Arness Jennifer Aniston=American actress=1,005,243=2 JA,Jane Austen Julia Ann=American pornographic actress=47,874=184 JA,Jean Arthur Judy Ann+Santos=Filipino, Actress=39,619=212 JA,Jennifer Aniston Jean Arthur=Actress=45,356=192 JA,Jessica Alba JA,Joan Van Ark Jane Asher=Actress, author=53,663=168 …….. JA,Joan of Arc José González JA,John Adams Janelle Monáe JA,John Amos Joseph Arthur JA,John Astin James Arthur JA,John James Audubon Jann Arden JA,John Quincy Adams Jessica Andrews JA,Jon Anderson John Anderson JA,Julie Andrews Jefferson Airplane JA,June Allyson Jane's Addiction Jacob ,Abbott ,Author ,Franconia Stories Jim ,Abbott ,Baseball ,One-handed MLB pitcher John ,Abbott ,Actor ,The Woman in White John ,Abbott ,Head of State ,Prime Minister of Canada, 1891-93 James ,Abdnor ,Politician ,US Senator from South Dakota, 1981-87 John ,Abizaid ,Military ,C-in-C, US Central Command, 2003- -

2012 Twenty-Seven Years of Nominees & Winners FILM INDEPENDENT SPIRIT AWARDS
2012 Twenty-Seven Years of Nominees & Winners FILM INDEPENDENT SPIRIT AWARDS BEST FIRST SCREENPLAY 2012 NOMINEES (Winners in bold) *Will Reiser 50/50 BEST FEATURE (Award given to the producer(s)) Mike Cahill & Brit Marling Another Earth *The Artist Thomas Langmann J.C. Chandor Margin Call 50/50 Evan Goldberg, Ben Karlin, Seth Rogen Patrick DeWitt Terri Beginners Miranda de Pencier, Lars Knudsen, Phil Johnston Cedar Rapids Leslie Urdang, Dean Vanech, Jay Van Hoy Drive Michel Litvak, John Palermo, BEST FEMALE LEAD Marc Platt, Gigi Pritzker, Adam Siegel *Michelle Williams My Week with Marilyn Take Shelter Tyler Davidson, Sophia Lin Lauren Ambrose Think of Me The Descendants Jim Burke, Alexander Payne, Jim Taylor Rachael Harris Natural Selection Adepero Oduye Pariah BEST FIRST FEATURE (Award given to the director and producer) Elizabeth Olsen Martha Marcy May Marlene *Margin Call Director: J.C. Chandor Producers: Robert Ogden Barnum, BEST MALE LEAD Michael Benaroya, Neal Dodson, Joe Jenckes, Corey Moosa, Zachary Quinto *Jean Dujardin The Artist Another Earth Director: Mike Cahill Demián Bichir A Better Life Producers: Mike Cahill, Hunter Gray, Brit Marling, Ryan Gosling Drive Nicholas Shumaker Woody Harrelson Rampart In The Family Director: Patrick Wang Michael Shannon Take Shelter Producers: Robert Tonino, Andrew van den Houten, Patrick Wang BEST SUPPORTING FEMALE Martha Marcy May Marlene Director: Sean Durkin Producers: Antonio Campos, Patrick Cunningham, *Shailene Woodley The Descendants Chris Maybach, Josh Mond Jessica Chastain Take Shelter -

2017 Sxsw Feature Release Final
SXSW FILM FESTIVAL ANNOUNCES 2017 FEATURES Interactive, Film and Music Badges get Expanded Access to Most Programming Austin, Texas, January 31, 2017 – The South by Southwest® (SXSW®) Conference and Festivals announced the features lineup for the 24th edition of the Film Festival, running March 10-19, 2017 in Austin, Texas. The acclaimed program draws thousands of fans, filmmakers, press and industry leaders every year to immerse themselves in the most innovative, smart and entertaining new films of the year. During the nine days of SXSW 125 features will be shown, with additional titles yet to be announced. The full lineup will include 51 films from first-time filmmakers, 85 World Premieres, 11 North American Premieres and 5 U.S. Premieres. These films were selected from 2,432 feature-length film submissions, with a total of 7,651 films submitted this year. “It's exciting for us to unveil the talent reflected in this year's line up. We intentionally curate a wide-ranging program reflecting unique and new voices that examine, explore, and celebrate the creative process, the cultural zeitgeist, and glimpses of the universal through deeply personal stories,” said Janet Pierson, Director of Film. “Whether genre, big crowd pleasers, quiet meditations, hard hitting docs, or microbudget indies, we can't wait to share these films with our smart, passionate audiences.” New for 2017, the Interactive, Film, and Music badges will now include expanded access to more of the SXSW Conference and Festivals experience. Attendees will still receive primary entry to programming associated with their badge type, but can now enjoy secondary access to most other SXSW events. -

Emmy Award Winners
CATEGORY 2035 2034 2033 2032 Outstanding Drama Title Title Title Title Lead Actor Drama Name, Title Name, Title Name, Title Name, Title Lead Actress—Drama Name, Title Name, Title Name, Title Name, Title Supp. Actor—Drama Name, Title Name, Title Name, Title Name, Title Supp. Actress—Drama Name, Title Name, Title Name, Title Name, Title Outstanding Comedy Title Title Title Title Lead Actor—Comedy Name, Title Name, Title Name, Title Name, Title Lead Actress—Comedy Name, Title Name, Title Name, Title Name, Title Supp. Actor—Comedy Name, Title Name, Title Name, Title Name, Title Supp. Actress—Comedy Name, Title Name, Title Name, Title Name, Title Outstanding Limited Series Title Title Title Title Outstanding TV Movie Name, Title Name, Title Name, Title Name, Title Lead Actor—L.Ser./Movie Name, Title Name, Title Name, Title Name, Title Lead Actress—L.Ser./Movie Name, Title Name, Title Name, Title Name, Title Supp. Actor—L.Ser./Movie Name, Title Name, Title Name, Title Name, Title Supp. Actress—L.Ser./Movie Name, Title Name, Title Name, Title Name, Title CATEGORY 2031 2030 2029 2028 Outstanding Drama Title Title Title Title Lead Actor—Drama Name, Title Name, Title Name, Title Name, Title Lead Actress—Drama Name, Title Name, Title Name, Title Name, Title Supp. Actor—Drama Name, Title Name, Title Name, Title Name, Title Supp. Actress—Drama Name, Title Name, Title Name, Title Name, Title Outstanding Comedy Title Title Title Title Lead Actor—Comedy Name, Title Name, Title Name, Title Name, Title Lead Actress—Comedy Name, Title Name, Title Name, Title Name, Title Supp. Actor—Comedy Name, Title Name, Title Name, Title Name, Title Supp.