Optimized Interval Splitting in a Linear Scan Register Allocator∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Attacking Client-Side JIT Compilers.Key
Attacking Client-Side JIT Compilers Samuel Groß (@5aelo) !1 A JavaScript Engine Parser JIT Compiler Interpreter Runtime Garbage Collector !2 A JavaScript Engine • Parser: entrypoint for script execution, usually emits custom Parser bytecode JIT Compiler • Bytecode then consumed by interpreter or JIT compiler • Executing code interacts with the Interpreter runtime which defines the Runtime representation of various data structures, provides builtin functions and objects, etc. Garbage • Garbage collector required to Collector deallocate memory !3 A JavaScript Engine • Parser: entrypoint for script execution, usually emits custom Parser bytecode JIT Compiler • Bytecode then consumed by interpreter or JIT compiler • Executing code interacts with the Interpreter runtime which defines the Runtime representation of various data structures, provides builtin functions and objects, etc. Garbage • Garbage collector required to Collector deallocate memory !4 A JavaScript Engine • Parser: entrypoint for script execution, usually emits custom Parser bytecode JIT Compiler • Bytecode then consumed by interpreter or JIT compiler • Executing code interacts with the Interpreter runtime which defines the Runtime representation of various data structures, provides builtin functions and objects, etc. Garbage • Garbage collector required to Collector deallocate memory !5 A JavaScript Engine • Parser: entrypoint for script execution, usually emits custom Parser bytecode JIT Compiler • Bytecode then consumed by interpreter or JIT compiler • Executing code interacts with the Interpreter runtime which defines the Runtime representation of various data structures, provides builtin functions and objects, etc. Garbage • Garbage collector required to Collector deallocate memory !6 Agenda 1. Background: Runtime Parser • Object representation and Builtins JIT Compiler 2. JIT Compiler Internals • Problem: missing type information • Solution: "speculative" JIT Interpreter 3. -

CSE 220: Systems Programming
Memory Allocation CSE 220: Systems Programming Ethan Blanton Department of Computer Science and Engineering University at Buffalo Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Allocating Memory We have seen how to use pointers to address: An existing variable An array element from a string or array constant This lecture will discuss requesting memory from the system. © 2021 Ethan Blanton / CSE 220: Systems Programming 2 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Memory Lifetime All variables we have seen so far have well-defined lifetime: They persist for the entire life of the program They persist for the duration of a single function call Sometimes we need programmer-controlled lifetime. © 2021 Ethan Blanton / CSE 220: Systems Programming 3 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Here, global is statically allocated: It is allocated by the compiler It is created when the program starts It disappears when the program exits © 2021 Ethan Blanton / CSE 220: Systems Programming 4 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Whereas x is automatically allocated: It is allocated by the compiler It is created when foo() is called ¶ It disappears when foo() returns © 2021 Ethan Blanton / CSE 220: Systems Programming 5 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary The Heap The heap represents memory that is: allocated and released at run time managed explicitly by the programmer only obtainable by address Heap memory is just a range of bytes to C. -

1 More Register Allocation Interference Graph Allocators
More Register Allocation Last time – Register allocation – Global allocation via graph coloring Today – More register allocation – Clarifications from last time – Finish improvements on basic graph coloring concept – Procedure calls – Interprocedural CS553 Lecture Register Allocation II 2 Interference Graph Allocators Chaitin Briggs CS553 Lecture Register Allocation II 3 1 Coalescing Move instructions – Code generation can produce unnecessary move instructions mov t1, t2 – If we can assign t1 and t2 to the same register, we can eliminate the move Idea – If t1 and t2 are not connected in the interference graph, coalesce them into a single variable Problem – Coalescing can increase the number of edges and make a graph uncolorable – Limit coalescing coalesce to avoid uncolorable t1 t2 t12 graphs CS553 Lecture Register Allocation II 4 Coalescing Logistics Rule – If the virtual registers s1 and s2 do not interfere and there is a copy statement s1 = s2 then s1 and s2 can be coalesced – Steps – SSA – Find webs – Virtual registers – Interference graph – Coalesce CS553 Lecture Register Allocation II 5 2 Example (Apply Chaitin algorithm) Attempt to 3-color this graph ( , , ) Stack: Weighted order: a1 b d e c a1 b a e c 2 a2 b a1 c e d a2 d The example indicates that nodes are visited in increasing weight order. Chaitin and Briggs visit nodes in an arbitrary order. CS553 Lecture Register Allocation II 6 Example (Apply Briggs Algorithm) Attempt to 2-color this graph ( , ) Stack: Weighted order: a1 b d e c a1 b* a e c 2 a2* b a1* c e* d a2 d * blocked node CS553 Lecture Register Allocation II 7 3 Spilling (Original CFG and Interference Graph) a1 := .. -
Memory Allocation Pushq %Rbp Java Vs
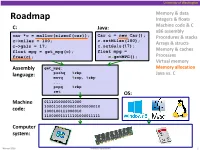
University of Washington Memory & data Roadmap Integers & floats C: Java: Machine code & C x86 assembly car *c = malloc(sizeof(car)); Car c = new Car(); Procedures & stacks c.setMiles(100); c->miles = 100; Arrays & structs c->gals = 17; c.setGals(17); float mpg = get_mpg(c); float mpg = Memory & caches free(c); c.getMPG(); Processes Virtual memory Assembly get_mpg: Memory allocation pushq %rbp Java vs. C language: movq %rsp, %rbp ... popq %rbp ret OS: Machine 0111010000011000 100011010000010000000010 code: 1000100111000010 110000011111101000011111 Computer system: Winter 2016 Memory Allocation 1 University of Washington Memory Allocation Topics Dynamic memory allocation . Size/number/lifetime of data structures may only be known at run time . Need to allocate space on the heap . Need to de-allocate (free) unused memory so it can be re-allocated Explicit Allocation Implementation . Implicit free lists . Explicit free lists – subject of next programming assignment . Segregated free lists Implicit Deallocation: Garbage collection Common memory-related bugs in C programs Winter 2016 Memory Allocation 2 University of Washington Dynamic Memory Allocation Programmers use dynamic memory allocators (such as malloc) to acquire virtual memory at run time . For data structures whose size (or lifetime) is known only at runtime Dynamic memory allocators manage an area of a process’ virtual memory known as the heap User stack Top of heap (brk ptr) Heap (via malloc) Uninitialized data (.bss) Initialized data (.data) Program text (.text) 0 Winter 2016 Memory Allocation 3 University of Washington Dynamic Memory Allocation Allocator organizes the heap as a collection of variable-sized blocks, which are either allocated or free . Allocator requests pages in heap region; virtual memory hardware and OS kernel allocate these pages to the process . -

Unleashing the Power of Allocator-Aware Software
P2126R0 2020-03-02 Pablo Halpern (on behalf of Bloomberg): [email protected] John Lakos: [email protected] Unleashing the Power of Allocator-Aware Software Infrastructure NOTE: This white paper (i.e., this is not a proposal) is intended to motivate continued investment in developing and maturing better memory allocators in the C++ Standard as well as to counter misinformation about allocators, their costs and benefits, and whether they should have a continuing role in the C++ library and language. Abstract Local (arena) memory allocators have been demonstrated to be effective at improving runtime performance both empirically in repeated controlled experiments and anecdotally in a variety of real-world applications. The initial development and subsequent maintenance effort of implementing bespoke data structures using custom memory allocation, however, are typically substantial and often untenable, especially in the limited timeframes that urgent business needs impose. To address such recurring performance needs effectively across the enterprise, Bloomberg has adopted a consistent, ubiquitous allocator-aware software infrastructure (AASI) based on the PMR-style1 plug-in memory allocator protocol pioneered at Bloomberg and adopted into the C++17 Standard Library. In this paper, we highlight the essential mechanics and subtle nuances of programing on top of Bloomberg’s AASI platform. In addition to delineating how to obtain performance gains safely at minimal development cost, we explore many of the inherent collateral benefits — such as object placement, metrics gathering, testing, debugging, and so on — that an AASI naturally affords. After reading this paper and surveying the available concrete allocators (provided in Appendix A), a competent C++ developer should be adequately equipped to extract substantial performance and other collateral benefits immediately using our AASI. -

Feasibility of Optimizations Requiring Bounded Treewidth in a Data Flow Centric Intermediate Representation
Feasibility of Optimizations Requiring Bounded Treewidth in a Data Flow Centric Intermediate Representation Sigve Sjømæling Nordgaard and Jan Christian Meyer Department of Computer Science, NTNU Trondheim, Norway Abstract Data flow analyses are instrumental to effective compiler optimizations, and are typically implemented by extracting implicit data flow information from traversals of a control flow graph intermediate representation. The Regionalized Value State Dependence Graph is an alternative intermediate representation, which represents a program in terms of its data flow dependencies, leaving control flow implicit. Several analyses that enable compiler optimizations reduce to NP-Complete graph problems in general, but admit linear time solutions if the graph’s treewidth is limited. In this paper, we investigate the treewidth of application benchmarks and synthetic programs, in order to identify program features which cause the treewidth of its data flow graph to increase, and assess how they may appear in practical software. We find that increasing numbers of live variables cause unbounded growth in data flow graph treewidth, but this can ordinarily be remedied by modular program design, and monolithic programs that exceed a given bound can be efficiently detected using an approximate treewidth heuristic. 1 Introduction Effective program optimizations depend on an intermediate representation that permits a compiler to analyze the data and control flow semantics of the source program, so as to enable transformations without altering the result. The information from analyses such as live variables, available expressions, and reaching definitions pertains to data flow. The classical method to obtain it is to iteratively traverse a control flow graph, where program execution paths are explicitly encoded and data movement is implicit. -

P1083r2 | Move Resource Adaptor from Library TS to the C++ WP
P1083r2 | Move resource_adaptor from Library TS to the C++ WP Pablo Halpern [email protected] 2018-11-13 | Target audience: LWG 1 Abstract When the polymorphic allocator infrastructure was moved from the Library Fundamentals TS to the C++17 working draft, pmr::resource_adaptor was left behind. The decision not to move pmr::resource_adaptor was deliberately conservative, but the absence of resource_adaptor in the standard is a hole that must be plugged for a smooth transition to the ubiquitous use of polymorphic_allocator, as proposed in P0339 and P0987. This paper proposes that pmr::resource_adaptor be moved from the LFTS and added to the C++20 working draft. 2 History 2.1 Changes from R1 to R2 (in San Diego) • Paper was forwarded from LEWG to LWG on Tuesday, 2018-10-06 • Copied the formal wording from the LFTS directly into this paper • Minor wording changes as per initial LWG review • Rebased to the October 2018 draft of the C++ WP 2.2 Changes from R0 to R1 (pre-San Diego) • Added a note for LWG to consider clarifying the alignment requirements for resource_adaptor<A>::do_allocate(). • Changed rebind type from char to byte. • Rebased to July 2018 draft of the C++ WP. 3 Motivation It is expected that more and more classes, especially those that would not otherwise be templates, will use pmr::polymorphic_allocator<byte> to allocate memory. In order to pass an allocator to one of these classes, the allocator must either already be a polymorphic allocator, or must be adapted from a non-polymorphic allocator. The process of adaptation is facilitated by pmr::resource_adaptor, which is a simple class template, has been in the LFTS for a long time, and has been fully implemented. -

Iterative-Free Program Analysis
Iterative-Free Program Analysis Mizuhito Ogawa†∗ Zhenjiang Hu‡∗ Isao Sasano† [email protected] [email protected] [email protected] †Japan Advanced Institute of Science and Technology, ‡The University of Tokyo, and ∗Japan Science and Technology Corporation, PRESTO Abstract 1 Introduction Program analysis is the heart of modern compilers. Most control Program analysis is the heart of modern compilers. Most control flow analyses are reduced to the problem of finding a fixed point flow analyses are reduced to the problem of finding a fixed point in a in a certain transition system, and such fixed point is commonly certain transition system. Ordinary method to compute a fixed point computed through an iterative procedure that repeats tracing until is an iterative procedure that repeats tracing until convergence. convergence. Our starting observation is that most programs (without spaghetti This paper proposes a new method to analyze programs through re- GOTO) have quite well-structured control flow graphs. This fact cursive graph traversals instead of iterative procedures, based on is formally characterized in terms of tree width of a graph [25]. the fact that most programs (without spaghetti GOTO) have well- Thorup showed that control flow graphs of GOTO-free C programs structured control flow graphs, graphs with bounded tree width. have tree width at most 6 [33], and recent empirical study shows Our main techniques are; an algebraic construction of a control that control flow graphs of most Java programs have tree width at flow graph, called SP Term, which enables control flow analysis most 3 (though in general it can be arbitrary large) [16]. -

The Slab Allocator: an Object-Caching Kernel Memory Allocator
The Slab Allocator: An Object-Caching Kernel Memory Allocator Jeff Bonwick Sun Microsystems Abstract generally superior in both space and time. Finally, Section 6 describes the allocator’s debugging This paper presents a comprehensive design over- features, which can detect a wide variety of prob- view of the SunOS 5.4 kernel memory allocator. lems throughout the system. This allocator is based on a set of object-caching primitives that reduce the cost of allocating complex objects by retaining their state between uses. These 2. Object Caching same primitives prove equally effective for manag- Object caching is a technique for dealing with ing stateless memory (e.g. data pages and temporary objects that are frequently allocated and freed. The buffers) because they are space-efficient and fast. idea is to preserve the invariant portion of an The allocator’s object caches respond dynamically object’s initial state — its constructed state — to global memory pressure, and employ an object- between uses, so it does not have to be destroyed coloring scheme that improves the system’s overall and recreated every time the object is used. For cache utilization and bus balance. The allocator example, an object containing a mutex only needs also has several statistical and debugging features to have mutex_init() applied once — the first that can detect a wide range of problems throughout time the object is allocated. The object can then be the system. freed and reallocated many times without incurring the expense of mutex_destroy() and 1. Introduction mutex_init() each time. An object’s embedded locks, condition variables, reference counts, lists of The allocation and freeing of objects are among the other objects, and read-only data all generally qual- most common operations in the kernel. -

Fast Efficient Fixed-Size Memory Pool: No Loops and No Overhead
COMPUTATION TOOLS 2012 : The Third International Conference on Computational Logics, Algebras, Programming, Tools, and Benchmarking Fast Efficient Fixed-Size Memory Pool No Loops and No Overhead Ben Kenwright School of Computer Science Newcastle University Newcastle, United Kingdom, [email protected] Abstract--In this paper, we examine a ready-to-use, robust, it can be used in conjunction with an existing system to and computationally fast fixed-size memory pool manager provide a hybrid solution with minimum difficulty. On with no-loops and no-memory overhead that is highly suited the other hand, multiple instances of numerous fixed-sized towards time-critical systems such as games. The algorithm pools can be used to produce a general overall flexible achieves this by exploiting the unused memory slots for general solution to work in place of the current system bookkeeping in combination with a trouble-free indexing memory manager. scheme. We explain how it works in amalgamation with Alternatively, in some time critical systems such as straightforward step-by-step examples. Furthermore, we games; system allocations are reduced to a bare minimum compare just how much faster the memory pool manager is to make the process run as fast as possible. However, for when compared with a system allocator (e.g., malloc) over a a dynamically changing system, it is necessary to allocate range of allocations and sizes. memory for changing resources, e.g., data assets Keywords-memory pools; real-time; memory allocation; (graphical images, sound files, scripts) which are loaded memory manager; memory de-allocation; dynamic memory dynamically at runtime. -

Register Allocation by Puzzle Solving
University of California Los Angeles Register Allocation by Puzzle Solving A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Computer Science by Fernando Magno Quint˜aoPereira 2008 c Copyright by Fernando Magno Quint˜aoPereira 2008 The dissertation of Fernando Magno Quint˜ao Pereira is approved. Vivek Sarkar Todd Millstein Sheila Greibach Bruce Rothschild Jens Palsberg, Committee Chair University of California, Los Angeles 2008 ii to the Brazilian People iii Table of Contents 1 Introduction ................................ 1 2 Background ................................ 5 2.1 Introduction . 5 2.1.1 Irregular Architectures . 8 2.1.2 Pre-coloring . 8 2.1.3 Aliasing . 9 2.1.4 Some Register Allocation Jargon . 10 2.2 Different Register Allocation Approaches . 12 2.2.1 Register Allocation via Graph Coloring . 12 2.2.2 Linear Scan Register Allocation . 18 2.2.3 Register allocation via Integer Linear Programming . 21 2.2.4 Register allocation via Partitioned Quadratic Programming 22 2.2.5 Register allocation via Multi-Flow of Commodities . 24 2.3 SSA based register allocation . 25 2.3.1 The Advantages of SSA-Based Register Allocation . 29 2.4 NP-Completeness Results . 33 3 Puzzle Solving .............................. 37 3.1 Introduction . 37 3.2 Puzzles . 39 3.2.1 From Register File to Puzzle Board . 40 iv 3.2.2 From Program Variables to Puzzle Pieces . 42 3.2.3 Register Allocation and Puzzle Solving are Equivalent . 45 3.3 Solving Type-1 Puzzles . 46 3.3.1 A Visual Language of Puzzle Solving Programs . 46 3.3.2 Our Puzzle Solving Program . -

A Little on V8 and Webassembly
A Little on V8 and WebAssembly An V8 Engine Perspective Ben L. Titzer WebAssembly Runtime TLM Background ● A bit about me ● A bit about V8 and JavaScript ● A bit about virtual machines Some history ● JavaScript ⇒ asm.js (2013) ● asm.js ⇒ wasm prototypes (2014-2015) ● prototypes ⇒ production (2015-2017) This talk mostly ● production ⇒ maturity (2017- ) ● maturity ⇒ future (2019- ) WebAssembly in a nutshell ● Low-level bytecode designed to be fast to verify and compile ○ Explicit non-goal: fast to interpret ● Static types, argument counts, direct/indirect calls, no overloaded operations ● Unit of code is a module ○ Globals, data initialization, functions ○ Imports, exports WebAssembly module example header: 8 magic bytes types: TypeDecl[] ● Binary format imports: ImportDecl[] ● Type declarations funcdecl: FuncDecl[] ● Imports: tables: TableDecl[] ○ Types memories: MemoryDecl[] ○ Functions globals: GlobalVar[] ○ Globals exports: ExportDecl[] ○ Memory ○ Tables code: FunctionBody[] ● Tables, memories data: Data[] ● Global variables ● Exports ● Function bodies (bytecode) WebAssembly bytecode example func: (i32, i32)->i32 get_local[0] ● Typed if[i32] ● Stack machine get_local[0] ● Structured control flow i32.load_mem[8] ● One large flat memory else ● Low-level memory operations get_local[1] ● Low-level arithmetic i32.load_mem[12] end i32.const[42] i32.add end Anatomy of a Wasm engine ● Load and validate wasm bytecode ● Allocate internal data structures ● Execute: compile or interpret wasm bytecode ● JavaScript API integration ● Memory management