A Generalized Gene Set Data Mining Approach
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Analyses of Allele-Specific Gene Expression in Highly Divergent
ARTICLES Analyses of allele-specific gene expression in highly divergent mouse crosses identifies pervasive allelic imbalance James J Crowley1,10, Vasyl Zhabotynsky1,10, Wei Sun1,2,10, Shunping Huang3, Isa Kemal Pakatci3, Yunjung Kim1, Jeremy R Wang3, Andrew P Morgan1,4,5, John D Calaway1,4,5, David L Aylor1,9, Zaining Yun1, Timothy A Bell1,4,5, Ryan J Buus1,4,5, Mark E Calaway1,4,5, John P Didion1,4,5, Terry J Gooch1,4,5, Stephanie D Hansen1,4,5, Nashiya N Robinson1,4,5, Ginger D Shaw1,4,5, Jason S Spence1, Corey R Quackenbush1, Cordelia J Barrick1, Randal J Nonneman1, Kyungsu Kim2, James Xenakis2, Yuying Xie1, William Valdar1,4, Alan B Lenarcic1, Wei Wang3,9, Catherine E Welsh3, Chen-Ping Fu3, Zhaojun Zhang3, James Holt3, Zhishan Guo3, David W Threadgill6, Lisa M Tarantino7, Darla R Miller1,4,5, Fei Zou2,11, Leonard McMillan3,11, Patrick F Sullivan1,5,7,8,11 & Fernando Pardo-Manuel de Villena1,4,5,11 Complex human traits are influenced by variation in regulatory DNA through mechanisms that are not fully understood. Because regulatory elements are conserved between humans and mice, a thorough annotation of cis regulatory variants in mice could aid in further characterizing these mechanisms. Here we provide a detailed portrait of mouse gene expression across multiple tissues in a three-way diallel. Greater than 80% of mouse genes have cis regulatory variation. Effects from these variants influence complex traits and usually extend to the human ortholog. Further, we estimate that at least one in every thousand SNPs creates a cis regulatory effect. -

Whole-Genome Sequencing for Tracing the Genetic Diversity of Brucella Abortus and Brucella Melitensis Isolated from Livestock in Egypt
pathogens Article Whole-Genome Sequencing for Tracing the Genetic Diversity of Brucella abortus and Brucella melitensis Isolated from Livestock in Egypt Aman Ullah Khan 1,2,3 , Falk Melzer 1, Ashraf E. Sayour 4, Waleed S. Shell 5, Jörg Linde 1, Mostafa Abdel-Glil 1,6 , Sherif A. G. E. El-Soally 7, Mandy C. Elschner 1, Hossam E. M. Sayour 8 , Eman Shawkat Ramadan 9, Shereen Aziz Mohamed 10, Ashraf Hendam 11 , Rania I. Ismail 4, Lubna F. Farahat 10, Uwe Roesler 2, Heinrich Neubauer 1 and Hosny El-Adawy 1,12,* 1 Institute of Bacterial Infections and Zoonoses, Friedrich-Loeffler-Institut, 07743 Jena, Germany; AmanUllah.Khan@fli.de (A.U.K.); falk.melzer@fli.de (F.M.); Joerg.Linde@fli.de (J.L.); Mostafa.AbdelGlil@fli.de (M.A.-G.); mandy.elschner@fli.de (M.C.E.); Heinrich.neubauer@fli.de (H.N.) 2 Institute for Animal Hygiene and Environmental Health, Free University of Berlin, 14163 Berlin, Germany; [email protected] 3 Department of Pathobiology, University of Veterinary and Animal Sciences (Jhang Campus), Lahore 54000, Pakistan 4 Department of Brucellosis, Animal Health Research Institute, Agricultural Research Center, Dokki, Giza 12618, Egypt; [email protected] (A.E.S.); [email protected] (R.I.I.) 5 Central Laboratory for Evaluation of Veterinary Biologics, Agricultural Research Center, Abbassia, Citation: Khan, A.U.; Melzer, F.; Cairo 11517, Egypt; [email protected] 6 Sayour, A.E.; Shell, W.S.; Linde, J.; Department of Pathology, Faculty of Veterinary Medicine, Zagazig University, Elzera’a Square, Abdel-Glil, M.; El-Soally, S.A.G.E.; Zagazig 44519, Egypt 7 Veterinary Service Department, Armed Forces Logistics Authority, Egyptian Armed Forces, Nasr City, Elschner, M.C.; Sayour, H.E.M.; Cairo 11765, Egypt; [email protected] Ramadan, E.S.; et al. -

University of California, San Diego
UNIVERSITY OF CALIFORNIA, SAN DIEGO The post-terminal differentiation fate of RNAs revealed by next-generation sequencing A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biomedical Sciences by Gloria Kuo Lefkowitz Committee in Charge: Professor Benjamin D. Yu, Chair Professor Richard Gallo Professor Bruce A. Hamilton Professor Miles F. Wilkinson Professor Eugene Yeo 2012 Copyright Gloria Kuo Lefkowitz, 2012 All rights reserved. The Dissertation of Gloria Kuo Lefkowitz is approved, and it is acceptable in quality and form for publication on microfilm and electronically: __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ Chair University of California, San Diego 2012 iii DEDICATION Ma and Ba, for your early indulgence and support. Matt and James, for choosing more practical callings. Roy, my love, for patiently sharing the ups and downs of this journey. iv EPIGRAPH It is foolish to tear one's hair in grief, as though sorrow would be made less by baldness. ~Cicero v TABLE OF CONTENTS Signature Page .............................................................................................................. iii Dedication .................................................................................................................... -

Uncovering the Signaling Landscape Controlling Breast Cancer Cell Migration Identifies Novel Metastasis Driver Genes
ARTICLE https://doi.org/10.1038/s41467-019-11020-3 OPEN Uncovering the signaling landscape controlling breast cancer cell migration identifies novel metastasis driver genes Esmee Koedoot1,4, Michiel Fokkelman 1,4, Vasiliki-Maria Rogkoti1,4, Marcel Smid2, Iris van de Sandt1, Hans de Bont1, Chantal Pont1, Janna E. Klip1, Steven Wink 1, Mieke A. Timmermans2, Erik A.C. Wiemer2, Peter Stoilov3, John A. Foekens2, Sylvia E. Le Dévédec 1, John W.M. Martens 2 & Bob van de Water1 1234567890():,; Ttriple-negative breast cancer (TNBC) is an aggressive and highly metastatic breast cancer subtype. Enhanced TNBC cell motility is a prerequisite of TNBC cell dissemination. Here, we apply an imaging-based RNAi phenotypic cell migration screen using two highly motile TNBC cell lines (Hs578T and MDA-MB-231) to provide a repository of signaling determinants that functionally drive TNBC cell motility. We have screened ~4,200 target genes individually and discovered 133 and 113 migratory modulators of Hs578T and MDA-MB-231, respectively, which are linked to signaling networks predictive for breast cancer progression. The splicing factors PRPF4B and BUD31 and the transcription factor BPTF are essential for cancer cell migration, amplified in human primary breast tumors and associated with metastasis-free survival. Depletion of PRPF4B, BUD31 and BPTF causes primarily down regulation of genes involved in focal adhesion and ECM-interaction pathways. PRPF4B is essential for TNBC metastasis formation in vivo, making PRPF4B a candidate for further drug development. 1 Division of Drug Discovery and Safety, LACDR, Leiden University, Einsteinweg 55, Leiden 2333 CC, Netherlands. 2 Department of Medical Oncology and Cancer Genomics Netherlands, Erasmus MC Cancer Institute, Erasmus University Medical Center, Rotterdam 3008 AE, Netherlands. -

Nuclear and Mitochondrial Genome Defects in Autisms
UC Irvine UC Irvine Previously Published Works Title Nuclear and mitochondrial genome defects in autisms. Permalink https://escholarship.org/uc/item/8vq3278q Journal Annals of the New York Academy of Sciences, 1151(1) ISSN 0077-8923 Authors Smith, Moyra Spence, M Anne Flodman, Pamela Publication Date 2009 DOI 10.1111/j.1749-6632.2008.03571.x License https://creativecommons.org/licenses/by/4.0/ 4.0 Peer reviewed eScholarship.org Powered by the California Digital Library University of California THE YEAR IN HUMAN AND MEDICAL GENETICS 2009 Nuclear and Mitochondrial Genome Defects in Autisms Moyra Smith, M. Anne Spence, and Pamela Flodman Department of Pediatrics, University of California, Irvine, California In this review we will evaluate evidence that altered gene dosage and structure im- pacts neurodevelopment and neural connectivity through deleterious effects on synap- tic structure and function, and evidence that the latter are key contributors to the risk for autism. We will review information on alterations of structure of mitochondrial DNA and abnormal mitochondrial function in autism and indications that interactions of the nuclear and mitochondrial genomes may play a role in autism pathogenesis. In a final section we will present data derived using Affymetrixtm SNP 6.0 microar- ray analysis of DNA of a number of subjects and parents recruited to our autism spectrum disorders project. We include data on two sets of monozygotic twins. Col- lectively these data provide additional evidence of nuclear and mitochondrial genome imbalance in autism and evidence of specific candidate genes in autism. We present data on dosage changes in genes that map on the X chromosomes and the Y chro- mosome. -

CERENKOV: Computational Elucidation of the Regulatory Noncoding Variome
CERENKOV: Computational Elucidation of the Regulatory Noncoding Variome Yao Yao∗ Zheng Liu∗ Satpreet Singh Oregon State University Oregon State University Oregon State University EECS EECS EECS [email protected] [email protected] [email protected] Qi Wei Stephen A. Ramsey Oregon State University Oregon State University EECS Department of Biomedical Sciences [email protected] Corvallis, Oregon 97330 [email protected] ABSTRACT (hAVGRANKi = 3.877). The source code for CERENKOV We describe a novel computational approach, CERENKOV is available on GitHub and the SNP feature data files are (Computational Elucidation of the REgulatory NonKOd- available for download via the CERENKOV website. ing Variome), for discriminating regulatory single nucleotide polymorphisms (rSNPs) from non-regulatory SNPs within CCS CONCEPTS noncoding genetic loci. CERENKOV is specifically designed • Computing methodologies → Machine learning; • for recognizing rSNPs in the context of a post-analysis of a Applied computing → Computational biology; Bioin- genome-wide association study (GWAS); it includes a novel formatics; accuracy scoring metric (which we call average rank, or AV- GRANK) and a novel cross-validation strategy (locus-based KEYWORDS sampling) that both correctly account for the \sparse positive SNP, GWAS, noncoding, rSNP, SNV, machine learning bag" nature of the GWAS post-analysis rSNP recognition problem. We trained and validated CERENKOV using a reference set of 15,331 SNPs (the OSU17 SNP set) whose composition is based -
Table S1. 49 Histone Variants Were Identified with High Sequence Coverage Through LC-MS/MS Analysis Electronic Supplementary
Electronic Supplementary Material (ESI) for Analytical Methods. This journal is © The Royal Society of Chemistry 2020 Table S1. 49 histone variants were identified with high sequence coverage through LC-MS/MS analysis Sequence Uniprot IDs Protein Name Protein Description Coverage Ratio E2+/E2- RSD P07305 H10_HUMAN 67.5% Histone H1.0 OS=Homo sapiens GN=H1F0 PE=1 SV=3 4.85 23.3% Histone H1.1 OS=Homo sapiens GN=HIST1H1A PE=1 Q02539 H11_HUMAN 74.4% SV=3 0.35 92.6% Histone H1.2 OS=Homo sapiens GN=HIST1H1C PE=1 P16403 H12_HUMAN 67.1% SV=2 0.73 80.6% Histone H1.3 OS=Homo sapiens GN=HIST1H1D PE=1 P16402 H13_HUMAN 63.8% SV=2 0.75 77.7% Histone H1.4 OS=Homo sapiens GN=HIST1H1E PE=1 P10412 H14_HUMAN 69.0% SV=2 0.70 80.3% Histone H1.5 OS=Homo sapiens GN=HIST1H1B PE=1 P16401 H15_HUMAN 79.6% SV=3 0.29 98.3% Testis-specific H1 histone OS=Homo sapiens GN=H1FNT Q75WM6 H1FNT_HUMAN 7.8% \ \ PE=2 SV=3 Histone H1oo OS=Homo sapiens GN=H1FOO PE=2 Q8IZA3 H1FOO_HUMAN 5.2% \ \ SV=1 Histone H1t OS=Homo sapiens GN=HIST1H1T PE=2 P22492 H1T_HUMAN 31.4% SV=4 1.42 65.0% Q92522 H1X_HUMAN 82.6% Histone H1x OS=Homo sapiens GN=H1FX PE=1 SV=1 1.15 33.2% Histone H2A type 1 OS=Homo sapiens GN=HIST1H2AG P0C0S8 H2A1_HUMAN 99.2% PE=1 SV=2 0.57 26.8% Q96QV6 H2A1A_HUMAN 58.0% Histone H2A type 1-A OS=Homo sapiens 0.90 11.2% GN=HIST1H2AA PE=1 SV=3 Histone H2A type 1-B/E OS=Homo sapiens P04908 H2A1B_HUMAN 99.2% GN=HIST1H2AB PE=1 SV=2 0.92 30.2% Histone H2A type 1-C OS=Homo sapiens Q93077 H2A1C_HUMAN 100.0% GN=HIST1H2AC PE=1 SV=3 0.76 27.6% Histone H2A type 1-D OS=Homo sapiens P20671 -

UNIVERSITY of CALIFORNIA, SAN DIEGO Functional Analysis of Sall4
UNIVERSITY OF CALIFORNIA, SAN DIEGO Functional analysis of Sall4 in modulating embryonic stem cell fate A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Molecular Pathology by Pei Jen A. Lee Committee in charge: Professor Steven Briggs, Chair Professor Geoff Rosenfeld, Co-Chair Professor Alexander Hoffmann Professor Randall Johnson Professor Mark Mercola 2009 Copyright Pei Jen A. Lee, 2009 All rights reserved. The dissertation of Pei Jen A. Lee is approved, and it is acceptable in quality and form for publication on microfilm and electronically: ______________________________________________________________ ______________________________________________________________ ______________________________________________________________ ______________________________________________________________ Co-Chair ______________________________________________________________ Chair University of California, San Diego 2009 iii Dedicated to my parents, my brother ,and my husband for their love and support iv Table of Contents Signature Page……………………………………………………………………….…iii Dedication…...…………………………………………………………………………..iv Table of Contents……………………………………………………………………….v List of Figures…………………………………………………………………………...vi List of Tables………………………………………………….………………………...ix Curriculum vitae…………………………………………………………………………x Acknowledgement………………………………………………….……….……..…...xi Abstract………………………………………………………………..…………….....xiii Chapter 1 Introduction ..…………………………………………………………………………….1 Chapter 2 Materials and Methods……………………………………………………………..…12 -
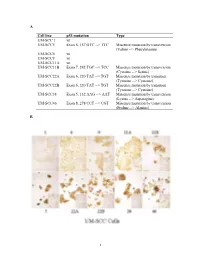
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Comprehensive Study of Nuclear Receptor DNA Binding Provides a Revised Framework for Understanding Receptor Specificity
ARTICLE https://doi.org/10.1038/s41467-019-10264-3 OPEN Comprehensive study of nuclear receptor DNA binding provides a revised framework for understanding receptor specificity Ashley Penvose 1,2,4, Jessica L. Keenan 2,3,4, David Bray2,3, Vijendra Ramlall 1,2 & Trevor Siggers 1,2,3 The type II nuclear receptors (NRs) function as heterodimeric transcription factors with the retinoid X receptor (RXR) to regulate diverse biological processes in response to endogenous 1234567890():,; ligands and therapeutic drugs. DNA-binding specificity has been proposed as a primary mechanism for NR gene regulatory specificity. Here we use protein-binding microarrays (PBMs) to comprehensively analyze the DNA binding of 12 NR:RXRα dimers. We find more promiscuous NR-DNA binding than has been reported, challenging the view that NR binding specificity is defined by half-site spacing. We show that NRs bind DNA using two distinct modes, explaining widespread NR binding to half-sites in vivo. Finally, we show that the current models of NR specificity better reflect binding-site activity rather than binding-site affinity. Our rich dataset and revised NR binding models provide a framework for under- standing NR regulatory specificity and will facilitate more accurate analyses of genomic datasets. 1 Department of Biology, Boston University, Boston, MA 02215, USA. 2 Biological Design Center, Boston University, Boston, MA 02215, USA. 3 Bioinformatics Program, Boston University, Boston, MA 02215, USA. 4These authors contributed equally: Ashley Penvose, Jessica L. Keenan. Correspondence -

HIST1H2BN (H2BC15) (NM 003520) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC224109L3 HIST1H2BN (H2BC15) (NM_003520) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: HIST1H2BN (H2BC15) (NM_003520) Human Tagged ORF Clone Tag: Myc-DDK Symbol: H2BC15 Synonyms: H2B/d; H2BFD; HIST1H2BN Vector: pLenti-C-Myc-DDK-P2A-Puro (PS100092) E. coli Selection: Chloramphenicol (34 ug/mL) Cell Selection: Puromycin ORF Nucleotide The ORF insert of this clone is exactly the same as(RC224109). Sequence: Restriction Sites: SgfI-MluI Cloning Scheme: ACCN: NM_003520 ORF Size: 378 bp This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 HIST1H2BN (H2BC15) (NM_003520) Human Tagged ORF Clone – RC224109L3 OTI Disclaimer: The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. polymorphisms), each with its own valid existence. This clone is substantially in agreement with the reference, but a complete review of all prevailing variants is recommended prior to use. More info OTI Annotation: This clone was engineered to express the complete ORF with an expression tag. Expression varies depending on the nature of the gene. RefSeq: NM_003520.3 RefSeq Size: 449 bp RefSeq ORF: 381 bp Locus ID: 8341 UniProt ID: Q99877, A0A024RCJ9 Protein Pathways: Systemic lupus erythematosus MW: 13.9 kDa Gene Summary: Histones are basic nuclear proteins that are responsible for the nucleosome structure of the chromosomal fiber in eukaryotes. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated.