Hadoop Ecosystem Why an Ecosystem
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem
Noname manuscript No. (will be inserted by the editor) A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem César Soto-Valero · Nicolas Harrand · Martin Monperrus · Benoit Baudry Received: date / Accepted: date Abstract Build automation tools and package managers have a profound influence on software development. They facilitate the reuse of third-party libraries, support a clear separation between the application’s code and its ex- ternal dependencies, and automate several software development tasks. How- ever, the wide adoption of these tools introduces new challenges related to dependency management. In this paper, we propose an original study of one such challenge: the emergence of bloated dependencies. Bloated dependencies are libraries that the build tool packages with the application’s compiled code but that are actually not necessary to build and run the application. This phenomenon artificially grows the size of the built binary and increases maintenance effort. We propose a tool, called DepClean, to analyze the presence of bloated dependencies in Maven artifacts. We ana- lyze 9; 639 Java artifacts hosted on Maven Central, which include a total of 723; 444 dependency relationships. Our key result is that 75:1% of the analyzed dependency relationships are bloated. In other words, it is feasible to reduce the number of dependencies of Maven artifacts up to 1=4 of its current count. We also perform a qualitative study with 30 notable open-source projects. Our results indicate that developers pay attention to their dependencies and are willing to remove bloated dependencies: 18/21 answered pull requests were accepted and merged by developers, removing 131 dependencies in total. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

The Programmer's Guide to Apache Thrift MEAP
MEAP Edition Manning Early Access Program The Programmer’s Guide to Apache Thrift Version 5 Copyright 2013 Manning Publications For more information on this and other Manning titles go to www.manning.com ©Manning Publications Co. We welcome reader comments about anything in the manuscript - other than typos and other simple mistakes. These will be cleaned up during production of the book by copyeditors and proofreaders. http://www.manning-sandbox.com/forum.jspa?forumID=873 Licensed to Daniel Gavrila <[email protected]> Welcome Hello and welcome to the third MEAP update for The Programmer’s Guide to Apache Thrift. This update adds Chapter 7, Designing and Serializing User Defined Types. This latest chapter is the first of the application layer chapters in Part 2. Chapters 3, 4 and 5 cover transports, error handling and protocols respectively. These chapters describe the foundational elements of Apache Thrift. Chapter 6 describes Apache Thrift IDL in depth, introducing the tools which enable us to describe data types and services in IDL. Chapters 7 through 9 bring these concepts into action, covering the three key applications areas of Apache Thrift in turn: User Defined Types (UDTs), Services and Servers. Chapter 7 introduces Apache Thrift IDL UDTs and provides insight into the critical role played by interface evolution in quality type design. Using IDL to effectively describe cross language types greatly simplifies the transmission of common data structures over messaging systems and other generic communications interfaces. Chapter 7 demonstrates the process of serializing types for use with external interfaces, disk I/O and in combination with Apache Thrift transport layer compression. -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Kyuubi Release 1.3.0 Kent
Kyuubi Release 1.3.0 Kent Yao Sep 30, 2021 USAGE GUIDE 1 Multi-tenancy 3 2 Ease of Use 5 3 Run Anywhere 7 4 High Performance 9 5 Authentication & Authorization 11 6 High Availability 13 6.1 Quick Start................................................ 13 6.2 Deploying Kyuubi............................................ 47 6.3 Kyuubi Security Overview........................................ 76 6.4 Client Documentation.......................................... 80 6.5 Integrations................................................ 82 6.6 Monitoring................................................ 87 6.7 SQL References............................................. 94 6.8 Tools................................................... 98 6.9 Overview................................................. 101 6.10 Develop Tools.............................................. 113 6.11 Community................................................ 120 6.12 Appendixes................................................ 128 i ii Kyuubi, Release 1.3.0 Kyuubi™ is a unified multi-tenant JDBC interface for large-scale data processing and analytics, built on top of Apache Spark™. In general, the complete ecosystem of Kyuubi falls into the hierarchies shown in the above figure, with each layer loosely coupled to the other. For example, you can use Kyuubi, Spark and Apache Iceberg to build and manage Data Lake with pure SQL for both data processing e.g. ETL, and analytics e.g. BI. All workloads can be done on one platform, using one copy of data, with one SQL interface. Kyuubi provides the following features: USAGE GUIDE 1 Kyuubi, Release 1.3.0 2 USAGE GUIDE CHAPTER ONE MULTI-TENANCY Kyuubi supports the end-to-end multi-tenancy, and this is why we want to create this project despite that the Spark Thrift JDBC/ODBC server already exists. 1. Supports multi-client concurrency and authentication 2. Supports one Spark application per account(SPA). 3. Supports QUEUE/NAMESPACE Access Control Lists (ACL) 4. -

Performance Tuning Apache Drill on Hadoop Clusters with Evolutionary Algorithms
Performance tuning Apache Drill on Hadoop Clusters with Evolutionary Algorithms Proposing the algorithm SIILCK (Society Inspired Incremental Learning through Collective Knowledge) Roger Bløtekjær Thesis submitted for the degree of Master of science in Informatikk: språkteknologi 30 credits Institutt for informatikk Faculty of mathematics and natural sciences UNIVERSITY OF OSLO Spring 2018 Performance tuning Apache Drill on Hadoop Clusters with Evolutionary Algorithms Proposing the algorithm SIILCK (Society Inspired Incremental Learning through Collective Knowledge) Roger Bløtekjær c 2018 Roger Bløtekjær Performance tuning Apache Drill on Hadoop Clusters with Evolutionary Algorithms http://www.duo.uio.no/ Printed: Reprosentralen, University of Oslo 0.1 Abstract 0.1.1 Research question How can we make a self optimizing distributed Apache Drill cluster, for high performance data readings across several file formats and database architec- tures? 0.1.2 Overview Apache Drill enables the user to perform schema-free querying of distributed data, and ANSI SQL programming on top of NoSQL datatypes like JSON or XML - typically in a Hadoop cluster. As it is with the core Hadoop stack, Drill is also highly customizable, with plenty of performance tuning parame- ters to ensure optimal efficiency. Tweaking these parameters however, requires deep domain knowledge and technical insight, and even then the optimal con- figuration may not be evident. Businesses will want to use Apache Drill in a Hadoop cluster, without the hassle of configuring it, for the most cost-effective implementation. This can be done by solving the following problems: • How to apply evolutionary algorithms to automatically tune a distributed Apache Drill configuration, regardless of cluster environment. -

Apache Calcite: a Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources Edmon Begoli Jesús Camacho-Rodríguez Julian Hyde Oak Ridge National Laboratory Hortonworks Inc. Hortonworks Inc. (ORNL) Santa Clara, California, USA Santa Clara, California, USA Oak Ridge, Tennessee, USA [email protected] [email protected] [email protected] Michael J. Mior Daniel Lemire David R. Cheriton School of University of Quebec (TELUQ) Computer Science Montreal, Quebec, Canada University of Waterloo [email protected] Waterloo, Ontario, Canada [email protected] ABSTRACT argued that specialized engines can offer more cost-effective per- Apache Calcite is a foundational software framework that provides formance and that they would bring the end of the “one size fits query processing, optimization, and query language support to all” paradigm. Their vision seems today more relevant than ever. many popular open-source data processing systems such as Apache Indeed, many specialized open-source data systems have since be- Hive, Apache Storm, Apache Flink, Druid, and MapD. Calcite’s ar- come popular such as Storm [50] and Flink [16] (stream processing), chitecture consists of a modular and extensible query optimizer Elasticsearch [15] (text search), Apache Spark [47], Druid [14], etc. with hundreds of built-in optimization rules, a query processor As organizations have invested in data processing systems tai- capable of processing a variety of query languages, an adapter ar- lored towards their specific needs, two overarching problems have chitecture designed for extensibility, and support for heterogeneous arisen: data models and stores (relational, semi-structured, streaming, and • The developers of such specialized systems have encoun- geospatial). This flexible, embeddable, and extensible architecture tered related problems, such as query optimization [4, 25] is what makes Calcite an attractive choice for adoption in big- or the need to support query languages such as SQL and data frameworks. -

Implementing Replication for Predictability Within Apache Thrift Jianwei Tu the Ohio State University [email protected]
Implementing Replication for Predictability within Apache Thrift Jianwei Tu The Ohio State University [email protected] ABSTRACT have a large number of packets. A study indicated that about Interactive applications, such as search, social networking and 0.02% of all flows contributed more than 59.3% of the total retail, hosted in cloud data center generate large quantities of traffic volume [1]. TCP is the dominating transport protocol small workloads that require extremely low median and tail used in data center. However, the performance for short flows latency in order to provide soft real-time performance to users. in TCP is very poor: although in theory they can be finished These small workloads are known as short TCP flows. in 10-20 microseconds with 1G or 10G interconnects, the However, these short TCP flows experience long latencies actual flow completion time (FCT) is as high as tens of due in part to large workloads consuming most available milliseconds [2]. This is due in part to long flows consuming buffer in the switches. Imperfect routing algorithm such as some or all of the available buffers in the switches [3]. ECMP makes the matter even worse. We propose a transport Imperfect routing algorithms such as ECMP makes the matter mechanism using replication for predictability to achieve low even worse. State of the art forwarding in enterprise and data flow completion time (FCT) for short TCP flows. We center environment uses ECMP to statically direct flows implement replication for predictability within Apache Thrift across available paths using flow hashing. It doesn’t account transport layer that replicates each short TCP flow and sends for either current network utilization or flow size, and may out identical packets for both flows, then utilizes the first flow direct many long flows to the same path causing flash that finishes the transfer. -

Umltographdb: Mapping Conceptual Schemas to Graph Databases
Citation for published version Daniel, G., Sunyé, G. & Cabot, J. (2016). UMLtoGraphDB: Mapping Conceptual Schemas to Graph Databases. Lecture Notes in Computer Science, 9974(), 430-444. DOI https://doi.org/10.1007/978-3-319-46397-1_33 Document Version This is the Submitted Manuscript version. The version in the Universitat Oberta de Catalunya institutional repository, O2 may differ from the final published version. https://doi.org/10.1007/978-3-319-61482-3_16 Copyright and Reuse This manuscript version is made available under the terms of the Creative Commons Attribution Non Commercial No Derivatives licence (CC-BY-NC-ND) http://creativecommons.org/licenses/by-nc-nd/3.0/es/, which permits others to download it and share it with others as long as they credit you, but they can’t change it in any way or use them commercially. Enquiries If you believe this document infringes copyright, please contact the Research Team at: [email protected] Universitat Oberta de Catalunya Research archive UMLtoGraphDB: Mapping Conceptual Schemas to Graph Databases Gwendal Daniel1, Gerson Sunyé1, and Jordi Cabot2;3 1 AtlanMod Team Inria, Mines Nantes & Lina {gwendal.daniel,gerson.sunye}@inria.fr 2 ICREA [email protected] 3 Internet Interdisciplinary Institute, UOC Abstract. The need to store and manipulate large volume of (unstructured) data has led to the development of several NoSQL databases for better scalability. Graph databases are a particular kind of NoSQL databases that have proven their efficiency to store and query highly interconnected data, and have become a promising solution for multiple applications. While the mapping of conceptual schemas to relational databases is a well-studied field of research, there are only few solutions that target conceptual modeling for NoSQL databases and even less focusing on graph databases. -
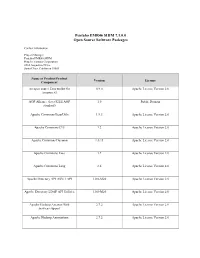
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -

Plugin Tapestry
PlugIn Tapestry Autor @picodotdev https://picodotdev.github.io/blog-bitix/ 2019 1.4.2 5.4 A tod@s l@s programador@s que en su trabajo no pueden usar el framework, librería o lenguaje que quisieran. Y a las que se divierten programando y aprendiendo hasta altas horas de la madrugada. Non gogoa, han zangoa Hecho con un esfuerzo en tiempo considerable con una buena cantidad de software libre y más ilusión en una región llamada Euskadi. PlugIn Tapestry: Desarrollo de aplicaciones y páginas web con Apache Tapestry @picodotdev 2014 - 2019 2 Prefacio Empecé El blog de pico.dev y unos años más tarde Blog Bitix con el objetivo de poder aprender y compartir el conocimiento de muchas cosas que me interesaban desde la programación y el software libre hasta análisis de los productos tecnológicos que caen en mis manos. Las del ámbito de la programación creo que usándolas pueden resolver en muchos casos los problemas típicos de las aplicaciones web y que encuentro en el día a día en mi trabajo como desarrollador. Sin embargo, por distintas circunstancias ya sean propias del cliente, la empresa o las personas es habitual que solo me sirvan meramente como satisfacción de adquirir conocimientos. Hasta el día de hoy una de ellas es el tema del que trata este libro, Apache Tapestry. Para escribir en el blog solo dependo de mí y de ninguna otra circunstancia salvo mi tiempo personal, es com- pletamente mío con lo que puedo hacer lo que quiera con él y no tengo ninguna limitación para escribir y usar cualquier herramienta, aunque en un principio solo sea para hacer un ejemplo muy sencillo, en el momento que llegue la oportunidad quizá me sirva para aplicarlo a un proyecto real. -

Technology Overview
Big Data Technology Overview Term Description See Also Big Data - the 5 Vs Everyone Must Volume, velocity and variety. And some expand the definition further to include veracity 3 Vs Know and value as well. 5 Vs of Big Data From Wikipedia, “Agile software development is a group of software development methods based on iterative and incremental development, where requirements and solutions evolve through collaboration between self-organizing, cross-functional teams. Agile The Agile Manifesto It promotes adaptive planning, evolutionary development and delivery, a time-boxed iterative approach, and encourages rapid and flexible response to change. It is a conceptual framework that promotes foreseen tight iterations throughout the development cycle.” A data serialization system. From Wikepedia, Avro Apache Avro “It is a remote procedure call and serialization framework developed within Apache's Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format.” BigInsights Enterprise Edition provides a spreadsheet-like data analysis tool to help Big Insights IBM Infosphere Biginsights organizations store, manage, and analyze big data. A scalable multi-master database with no single points of failure. Cassandra Apache Cassandra It provides scalability and high availability without compromising performance. Cloudera Inc. is an American-based software company that provides Apache Hadoop- Cloudera Cloudera based software, support and services, and training to business customers. Wikipedia - Data Science Data science The study of the generalizable extraction of knowledge from data IBM - Data Scientist Coursera Big Data Technology Overview Term Description See Also Distributed system developed at Google for interactively querying large datasets. Dremel Dremel It empowers business analysts and makes it easy for business users to access the data Google Research rather than having to rely on data engineers.