AN INTEGRATED STOCK MARKET FORECASTING MODEL USING NEURAL NETWORKS a Thesis Presented to the Faculty of the Fritz J. and Dolores
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Free Stock Screener Page 1
Free Stock Screener www.dojispace.com Page 1 Disclaimer The information provided is not to be considered as a recommendation to buy certain stocks and is provided solely as an information resource to help traders make their own decisions. Past performance is no guarantee of future success. It is important to note that no system or methodology has ever been developed that can guarantee profits or ensure freedom from losses. No representation or implication is being made that using The Shocking Indicator will provide information that guarantees profits or ensures freedom from losses. Copyright © 2005-2012. All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical, without written prior permission from the author. Free Stock Screener www.dojispace.com Page 2 Bullish Engulfing Pattern is one of the strongest patterns that generates a buying signal in candlestick charting and is one of my favorites. The following figure shows how the Bullish Engulfing Pattern looks like. The following conditions must be met for a pattern to be a bullish engulfing. 1. The stock is in a downtrend (short term or long term) 2. The first candle is a red candle (down day) and the second candle must be white (up day) 3. The body of the second candle must completely engulfs the first candle. The following conditions strengthen the buy signal 1. The trading volume is higher than usual on the engulfing day 2. The engulfing candle engulfs multiple previous down days. 3. The stock gap up or trading higher the next day after the bullish engulfing pattern is formed. -

Elliott Wave Principle
THE BASICS OF THE ELLIOTT WAVE PRINCIPLE by Robert R. Prechter, Jr. Published by NEW CLASSICS LIBRARY a division of Post Office Box 1618, Gainesville, GA 30503 USA 800-336-1618 or 770-536-0309 or fax 770-536-2514 THE BASICS OF THE ELLIOTT WAVE PRINCIPLE Copyright © 1995-2004 by Robert R. Prechter, Jr. Printed in the United States of America First Edition: August 1995 Second Edition: February 1996 Third Edition: April 2000 Fourth Edition: June 2004 August 2007 For information, address the publishers: New Classics Library a division of Elliott Wave International Post Office Box 1618 Gainesville, Georgia 30503 USA All rights reserved. The material in this volume may not be reprinted or reproduced in any manner whatsoever. Violators will be prosecuted to the fullest extent of the law. Cover design: Marc Benejan Production: Pamela Greenwood ISBN: 0-932750-63-X CONTENTS 7 The Basics 7 The Five Wave Pattern 8 Wave Mode 10 The Essential Design 11 Variations on the Basic Theme 12 Wave Degree 14 Motive Waves 14 Impulse 16 Extension 17 Truncation 18 Diagonal Triangles (Wedges) 19 Corrective Waves 19 Zigzags (5-3-5) 21 Flats (3-3-5) 22 Horizontal Triangles (Triangles) 24 Combinations (Double and Triple Threes) 26 Guidelines of Wave Formation 26 Alternation 26 Depth of Corrective Waves 27 Channeling Technique 28 Volume 29 Learning the Basics 32 The Fibonacci Sequence and its Application 35 Ratio Analysis 35 Retracements 36 Motive Wave Multiples 37 Corrective Wave Multiples 40 Perspective 41 Glossary FOREWORD By understanding the Wave Principle, you can antici- pate large and small shifts in the psychology driving any investment market and help yourself minimize the emo- tions that drive your own investment decisions. -

Tradescript.Pdf
Service Disclaimer This manual was written for use with the TradeScript™ language. This manual and the product described in it are copyrighted, with all rights reserved. This manual and the TradeScript™ outputs (charts, images, data, market quotes, and other features belonging to the product) may not be copied, except as otherwise provided in your license or as expressly permitted in writing by Modulus Financial Engineering, Inc. Export of this technology may be controlled by the United States Government. Diversion contrary to U.S. law prohibited. Copyright © 2006 by Modulus Financial Engineering, Inc. All rights reserved. Modulus Financial Engineering and TradeScript™ are registered trademarks of Modulus Financial Engineering, Inc. in the United States and other countries. All other trademarks and service marks are the property of their respective owners. Use of the TradeScript™ product and other services accompanying your license and its documentation are governed by the terms set forth in your license. Such use is at your sole risk. The service and its documentation (including this manual) are provided "AS IS" and without warranty of any kind and Modulus Financial Engineering, Inc. AND ITS LICENSORS (HEREINAFTER COLLECTIVELY REFERRED TO AS “MFE”) EXPRESSLY DISCLAIM ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE AND AGAINST INFRINGEMENT. MFE DOES NOT WARRANT THAT THE FUNCTIONS CONTAINED IN THE SERVICE WILL MEET YOUR REQUIREMENTS, OR THAT THE OPERATION OF THE SERVICE WILL BE UNINTERRUPTED OR ERROR-FREE, OR THAT DEFECTS IN THE SERVICE OR ERRORS IN THE DATA WILL BE CORRECTED. FURTHERMORE, MFE DOES NOT WARRANT OR MAKE ANY REPRESENTATIONS REGARDING THE USE OR THE RESULTS OF THE USE OF THE SERVICE OR ITS DOCUMENTATION IN TERMS OF THEIR CORRECTNESS, ACCURACY, RELIABILITY, OR OTHERWISE. -

Trend Following Algorithms in Automated Derivatives Market Trading ⇑ Simon Fong , Yain-Whar Si, Jackie Tai
Expert Systems with Applications 39 (2012) 11378–11390 Contents lists available at SciVerse ScienceDirect Expert Systems with Applications journal homepage: www.elsevier.com/locate/eswa Trend following algorithms in automated derivatives market trading ⇑ Simon Fong , Yain-Whar Si, Jackie Tai Department of Computer and Information Science, University of Macau, Macau article info abstract Keywords: Trend following (TF) is trading philosophy by which buying/selling decisions are made solely according to Trend following the observed market trend. For many years, many manifestations of TF such as a software program called Automated trading system Turtle Trader, for example, emerged in the industry. Surprisingly little has been studied in academic Futures contracts research about its algorithms and applications. Unlike financial forecasting, TF does not predict any mar- Mechanical trading ket movement; instead it identifies a trend at early time of the day, and trades automatically afterwards by a pre-defined strategy regardless of the moving market directions during run time. Trend following trading has been popular among speculators. However it remains as a trading method where human judgment is applied in setting the rules (aka the strategy) manually. Subsequently the TF strategy is exe- cuted in pure objective operational manner. Finding the correct strategy at the beginning is crucial in TF. This usually involves human intervention in first identifying a trend, and configuring when to place an order and close it out, when certain conditions are met. In this paper, we evaluated and compared a col- lection of TF algorithms that can be programmed in a computer system for automated trading. In partic- ular, a new version of TF called trend recalling model is presented. -

New Elliott Wave Principle
History The Elliott Wave Theory is named after Ralph Nelson Elliott. In the 1930s, Ralph Nelson Elliott found that the markets exhibited certain repeated patterns. His primary research was with stock market data for the Dow Jones Industrial Average. This research identified patterns or waves that recur in the markets. Very simply, in the direction of the trend, expect five waves. Any corrections against the trend are in three waves. Three wave corrections are lettered as "a, b, c." These patterns can be seen in long-term as well as in short-term charts. In Elliott's model, market prices alternate between an impulsive, or motive phase, and a corrective phase on all time scales of trend, as the illustration shows. Impulses are always subdivided into a set of 5 lower-degree waves, alternating again between motive and corrective character, so that waves 1, 3, and 5 are impulses, and waves 2 and 4 are smaller retraces of waves 1 and 3. Corrective waves subdivide into 3 smaller-degree waves. In a bear market the dominant trend is downward, so the pattern is reversed—five waves down and three up. Motive waves always move with the trend, while corrective waves move against it and hence called corrective waves. Ideally, smaller patterns can be identified within bigger patterns. In this sense, Elliott Waves are like a piece of broccoli, where the smaller piece, if broken off from the bigger piece, does, in fact, look like the big piece. This information (about smaller patterns fitting into bigger patterns), coupled with the Fibonacci relationships between the waves, offers the trader a level of anticipation and/or prediction when searching for and identifying trading opportunities with solid reward/risk ratios. -

FOREX WAVE THEORY.Pdf
FOREX WAVE THEORY This page intentionally left blank FOREX WAVE THEORY A Technical Analysis for Spot and Futures Currency Traders JAMES L. BICKFORD McGraw-Hill New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto Copyright © 2007 by The McGraw-Hill Companies. All rights reserved. Manufactured in the United States of America. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher. 0-07-151046-X The material in this eBook also appears in the print version of this title: 0-07-149302-6. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every occurrence of a trademarked name, we use names in an editorial fashion only, and to the benefit of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales pro- motions, or for use in corporate training programs. For more information, please contact George Hoare, Special Sales, at [email protected] or (212) 904-4069. TERMS OF USE This is a copyrighted work and The McGraw-Hill Companies, Inc. (“McGraw-Hill”) and its licen- sors reserve all rights in and to the work. Use of this work is subject to these terms. -
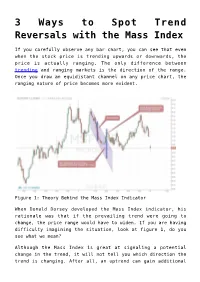
3 Ways to Spot Trend Reversals with the Mass Index
3 Ways to Spot Trend Reversals with the Mass Index If you carefully observe any bar chart, you can see that even when the stock price is trending upwards or downwards, the price is actually ranging. The only difference between trending and ranging markets is the direction of the range. Once you draw an equidistant channel on any price chart, the ranging nature of price becomes more evident. Figure 1: Theory Behind the Mass Index Indicator When Donald Dorsey developed the Mass Index indicator, his rationale was that if the prevailing trend were going to change, the price range would have to widen. If you are having difficulty imagining the situation, look at figure 1, do you see what we mean? Although the Mass Index is great at signaling a potential change in the trend, it will not tell you which direction the trend is changing. After all, an uptrend can gain additional bullish momentum and that will also help make the range much wider. You have to remember that when the Mass Index technical indicator line is going up, the climbing line is only signaling that the volatility of the stock is going up. However, the Mass Index indicator line does not signify any directional bias of the stock. That’s why you need to incorporate other technical analysis tools into your mass index trading strategies in order to identify the change of direction of the prevailing trend. Consider an analogy for a moment, you are driving a car and the mass index calculator, which shows volatility of the stock, is your speedometer. -

The Candlestick Forecaster
The Candlestick Forecaster Samurai Edition User Manual Copyright Ó 2000 Highest Summit Technologies Sdn Bhd. All Rights Reserved. LICENCE AGREEMENT THE CANDLESTICK FORECASTERÒ software constitutes a CD having copyrighted computer software accompanied by a copyrighted user manual in which all copyrights and ownership rights are owned only by Highest Summit Technologies Sdn Bhd (HST). HST grants to you a non-exclusive license to use a copy of The Candlestick Forecaster software on a single computer and the terms of this grant is effective unless violated. You may call and discuss with us by telephone any questions about the installation and use of The Candlestick Forecaster software by calling our office at (603) 245-5877, fax us at (603) 245-6792 or email us at [email protected]. We reserve the right to discontinue technical support at anytime without notice to you. You are not entitled to sub-license, rent, lease, sell, pledge or otherwise transfer or distribute the original copy of The Candlestick Forecaster software. Modification, disassembly, reverse engineering or creating derivative works based on the software or any portion thereof is expressly prohibited. Copying of the manual is also prohibited. Breach of these provisions automatically terminates this agreement and subjects you to further legal implications. The Candlestick Forecaster is warranted for ninety (90) days from the date of purchase to be free of defects in materials and workmanship under normal use. To obtain replacement of any material under this warranty, you must return the inaccurate CD or copy of the manual to us within the warranty period or notify us in writing within the warranty period that you have found an inaccuracy in The Candlestick Forecaster software and then return the materials to us. -

Forex Training Summary and Quiz – Stochastic Oscillator in Forex
EXCHANGE RATES FOREX TRADING MONEY TRANSFERS CURRENCY HEDGING ABOUT US MY ACCOUNT HELP DESK SEARCH U.S. Why OANDA Products Learn News & Analysis Home Learn Forex Technical Analy sis Stochastic Oscillator Forex Training Summary and Quiz LESSON 4: STOCHASTIC OSCILLATOR Sign in or Register with OANDA Forex Training Summary and Quiz Stochastic Oscillator in Forex Stochastic Oscillators w ere developed in the late 1950s by George C. Lane and are used to help predict the future direction of an exchange rate. The Oscillator scale ranges from 0 to 100. When calculating the strength of a trend, the Stochastic Oscillator defines and uptrend as the period of time w hen rates remain equal to or higher than the previous close, w hile a downtrend is the period of time w hen rates remain equal to or low er than the previous close. The Full Stochastic consists of tw o stochastic lines - %K and %D w here: %K tracks the current rate for the currency pair %D is a moving average based on the %K line - the fact that it is an average of %K means that it w ill produce a "smoothed out" version of %K The %K line is commonly referred to as the Fast Stochastic as it moves w ith changes in the spot rate w hile the %D line - w hich is a moving average of the %K line - reacts more slow ly to rate changes. For this reason, it is often referred to as the Slow Stochastic. Crossovers occur w hen the %K line intersects the %D line. -

Stochastic Pop & Drop Strategies
Stochastic Pop & Drop Strategies Establish a Trading Bias •Establish a short-term trading bias with a long-term indicator. •Traders look for bullish setups when the bias is bullish and bearish setups when the bias is bearish. •Trading in the direction of this bias is like riding a bike with the wind at your back. The chances of success are higher when the bigger trend is in your favor. •Use the weekly Stochastic Oscillator to define the trading bias. •In particular, the trading bias is deemed bullish when the weekly 14-period Stochastic Oscillator is above 50 and rising, and vice versa for bearish bias •Use a 70-period daily Stochastic Oscillator so all indicators can be displayed on the chart **This timeframe is simply five times the 14-day timeframe. Stochastic Pop Stochastic Pop Buy Signal •70-day Stochastic Oscillator is above 50 •14-day Stochastic Oscillator surges above 80 •Stock rises on high volume and/or breaks consolidation resistance. •Candle pattern confirmation Stochastic Pop •Once the bullish prerequisites are in place, a buy signal triggers when the 14-day Stochastic Oscillator surges above 80 and the stock breaks out on above average volume. •Consolidation breakouts are preferred when using this strategy (ie Box range) •Do not ignore high volume signals that do not produce breakouts •Sometimes the initial high-volume surge is a precursor to a breakout Box Range / Consolidation Trending Market Trending Market Trending Market Trending Market / Box Range Stochastics Stochastic Drop Stochastic Drop Sell Signal •70-day Stochastic Oscillator is below 50 •14-day Stochastic Oscillator plunges below 20 •Stock declines on high volume and/or breaks consolidation support. -

Data Visualization and Analysis
HTML5 Financial Charts Data visualization and analysis Xinfinit’s advanced HTML5 charting tool is also available separately from the managed data container and can be licensed for use with other tools and used in conjunction with any editor. It includes a comprehensive library of over sixty technical indictors, additional ones can easily be developed and added on request. 2 Features Analysis Tools Trading from Chart Trend Channel Drawing Instrument Selection Circle Drawing Chart Duration Rectangle Drawing Chart Intervals Fibonacci Patterns Chart Styles (Line, OHLC etc.) Andrew’s Pitchfork Comparison Regression Line and Channel Percentage (Y-axis) Up and Down arrows Log (Y-axis) Text box Show Volume Save Template Show Data values Load Template Show Last Value Save Show Cross Hair Load Show Cross Hair with Last Show Min / Max Show / Hide History panel Show Previous Close Technical Indicators Show News Flags Zooming Data Streaming Full Screen Print Select Tool Horizontal Divider Trend tool Volume by Price Horizonal Line Drawing Book Volumes 3 Features Technical Indicators Acceleration/Deceleration Oscillator Elliot Wave Oscillator Accumulation Distribution Line Envelopes Aroon Oscilltor Fast Stochastic Oscillator Aroon Up/Down Full Stochastic Oscillator Average Directional Index GMMA Average True Range GMMA Oscillator Awesome Oscillator Highest High Bearish Engulfing Historical Volatility Bollinger Band Width Ichimoku Kinko Hyo Bollinger Bands Keltner Indicator Bullish Engulfing Know Sure Thing Chaikin Money Flow Lowest Low Chaikin Oscillator -

Trading Strategies Using Stochastic
ANALYSIS TOOLS By Ng Ee Hwa, ChartNexus Market Strategist TRADING STRATEGIES USING STOCHASTIC In the aftermath of the global market correction following the big drop in the Chinese stock market indices in Feb 2007, investors have returned to the markets with a vengeance pushing the indices to scale new heights almost daily. However with recent moves by the Chinese authorities to cool the bullishness through measures such as the increase in stamp duties, the Chinese stock markets have again dropped significantly in the first few days of June 2007. This example of wild swings in the market sentiment can cause serious damage to the retail investor’s pocket, especially those uneducated in the forces at play in the stock market. Consequently it is vital that investors and traders are well-equipped in technical analysis tools to time the market effectively. This article will look at one of the tools in Technical Analysis indicators called Stochastic, a momentum indicator that shows clear bullish and bearish signals. Stochastic is a momentum oscillator oscillators that oscillate in a fixed range, an developed by George C.Lane in the late 1950s. overbought and oversold condition can be Lane noticed that in an up trending stock, prices specified. Based on his trading experience, Lane will usually make higher highs and the daily closing defined the overbought and oversold region for price will tend to accumulate near the extreme the Stochastic value to be above 80 and below highs of the “look back” periods. Similarly, a down 20 respectively. He deemed that a Stochastic value trending stock demonstrated the same behavior above 80 or below 20 may signal that a price trend of which the daily closing price tends to reversal may be imminent.