5.3 Compare Players
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

7 Sept. 2, 2021
Sept. 2, 2021 Brazilian former football star Pele said on Twitter that he was undergoing routine exams in hospital and that he was “in very good health”, denying a 7 report of a more serious health issue, Reuters reported. Djokovic takes first unsteady step toward calendar slam Sports Desk 5-1, courtesy of doubles by Abbasi and Olad-Qobad, and a Tavakkoli strike. ead coach Mohammad Nazemasharieh released Iran is pitted against the defending champion Argentina, Iran’s 16-man squad for the FIFA Futsal World Serbia, and USA in Group F of the World Cup, which was HCup in Lithuania, starting September 12. postponed by a year due to the coronavirus pandemic. Alireza Samimi, Sepehr Mohammadi, Baqer Moham- The 12-time Asian champion will kick off its campaign madi, Hamid Ahmadi, Mohammadreza Sang-Sefidi, against Serbia on September 14 at the Avia Solutions Hossein Tayyebi, Farhad Tavakkoli, Alireza Rafieipour, Group Arena in the capital city of Vilnius. Mohammad Shajari, Moslem Olad-Qobad, Ali-Asghar Nazemasharieh’s men will then take on USA on Septem- Hassanzadeh, Mohammad-Taha Nematian, Mehdi Javid, ber 17, before squaring off against Argentina in the final Seyyed Ahmad Abbasi, Ahmad Esmaeilpour, and Farhad group fixture three days later. Fakhim will represent the country at the event, ISNA re- Top two of the six groups plus four of the best third- ported. placed teams will progress to the round of 16. The Asian powerhouse on Tuesday claimed a second Iran made history in 2016 by becoming the first Asian consecutive friendly victory over Belarus – after an 8-2 side to reach the last-four of the World Cup, beating Portu- win on the preceding night – beating the European host gal in the shootout for the third spot in Colombia. -

Iranian Skiers Bag Four More Medals at Murat Dedeman FIS
6 December 19, 2019 6th Wrestling World Club Iranian Skiers Bag Four More Championships Kicks Off in Iran Medals at Murat Dedeman FIS Cup TEHRAN (Tasnim) – Iranian skiers have claimed four more medals at the Murat Dedeman FIS Cup underway in Palandoken in Erzurum, Turkey. Atefeh Ahmadi seized a gold medal in the women’s slalom with a time of 1:37.35. Her countrywoman Fo- rough Abbasi claimed a bronze and silver medal went to Turkey’s Sila Kara. In the men’s slalom, Luka Tiriel Abramovic from Turkey won the BOJNOURD, Iran (Dispatches) Sarzamin, as the representatives gold with 1:26.35, and Iranian ski- - The 6th Freestyle and Greco- of Iranian wrestling, several club ers Morteza Jafari and Porya Saveh Roman Wrestling World Club teams from China, Kyrgyzstan, Shemshaki climed silver and bronze Championships 2019, started on Georgia, Azerbaijan, Armenia, medals, respectively. Wednesday in Northeast Iran city and India will compete in the Iranian skiers had won two silver of Bojnourd. Freestyle and Greco-Roman and two bronze medals in the compe- These competitions, which are wrestling events. tition’s first day. being held in the gym of Boj- The 6th Freestyle and Greco- nourd University, will be fol- Roman Wrestling World Club lowed by a wrestling tournament Championships 2019, which Clippers Overpower Suns 120-99 involving 2 Iranian and 3 foreign began on Dec.17 with the entry teams. of the teams participating in the LOS ANGELES (AP) -- The Los Angeles Clippers are one player short of In addition to Iran’s big market Greco-Roman Wrestling Cham- finally fielding their entire team. -

P20 Layout 1
Tanaka shines Russia draw as NY Yankees with South 16thump Toronto 19Korea 1-1 THURSDAY, JUNE 19, 2014 5 problems jeopardizing Brazil World Cup hopes Page 18 Spain crash out of World Cup Chile prove too hot to handle; Spain’s reign ends RIO DE JANEIRO: Holders Spain were sensationally sent Ange Postecoglou paid tribute to his team after the loss. “I just crashing out of the World Cup with a 2-0 defeat to Chile wanted the players to get the reward for the way they went yesterday, the earliest exit by the reigning champions for about things today,” said Postecoglou. “I have put a lot of 5 reasons it went 64 years. On a day when King Juan Carlos tearfully pressure on the players and the staff that we are going to sealed his abdication after a four-decade reign, Spain’s be a certain type of team and take it to world class oppo- players were booted off their throne in 90 minutes after sition, but it is one thing saying it and another thing wrong for Spain six years as the dominant force of world football. Chile’s doing it. “They did that today but didn’t get their reward. Eduardo Vargas and Charles Aranguiz administered the It’s heartbreaking and massively disappointing.” RIO DE JANEIRO: Spain became the country rather than his native Brazil, it killer blows as a trophy-laden Spanish era was brought Elsewhere yesterday, in Group A, Cameroon and Croatia, fifth holders to be eliminated from the was inevitable that the Atletico Madrid to a shattering end at the Maracana Stadium. -

Pogba Scores Twice As United Beat Fenerbahce
SPORTS SATURDAY, OCTOBER 22, 2016 Matches on TV (Local Timings) ENGLISH PREMIER LEAGUE Bournemouth v Tottenham 14:30 beIN SPORTS 2 HD Leicester v Crystal Palace 17:00 beIN SPORTS 1 HD Arsenal v Middlesbrough 17:00 beIN SPORTS 2 HD Burnley v Everton 17:00 beIN SPORTS 4 HD Hull City v Stoke City 17:00 beIN SPORTS 9 HD Swansea City v Watford 17:00 beIN SPORTS 12 HD EN West Ham v Sunderland 17:00 beIN SPORTS 8 HD Liverpool v West Bromwich 19:30 beIN SPORTS 2 HD SPANISH LEAGUE Espanyol v SD Eibar 14:00 beIN SPORTS 3 HD Valencia v FC Barcelona 17:15 beIN SPORTS 3 HD Real Sociedad v Deportivo 19:30 beIN SPORTS 3 HD Granada v Sporting Gijon 21:45 beIN SPORTS 3 HD MANCHESTER: Fenerbahce’s Souza, left, Manchester United’s Memphis Depay, centre, and Fenerbahce’s Robin van ITALIAN CALCIO LEAGUE Persie, right, compete for the ball during the Europa League Group A soccer match between Manchester United and Fenerbahce at Old Trafford stadium in Manchester, England, Thursday. —AP UC Sampdoria v Genoa CFC 19:00 beIN SPORTS 4 HD AC Milan v Juventus 21:45 beIN SPORTS 4 HD Pogba scores twice as GERMAN BUNDESLIGA Bayer 04 v Hoffenheim 16:30 United beat Fenerbahce beIN SPORTS Hertha Berlin v FC Koln 16:30 LONDON: Paul Pogba repaid some of his a morale-boosting performance ahead of pounds ($109.04 million) in the close sea- beIN SPORTS world record transfer fee with two goals as manager Jose Mourinho’s return to former son. -

Lijst Vragen En Antwoorden
De complete lijst met vragen en antwoorden van de Grote Online Voetbalquiz van vv Gemert RONDE 1: 1. Het rugnummer 1 wordt eigenlijk altijd gedragen door keepers. Een uitzondering hierop vormde deze speler, die in 1978 wereldkampioen werd met het Argentijnse elftal. Wie is deze legendarische middenvelder? B. Osvaldo Ardiles 2. Joost Habraken is al vele jaren een van de sterkhouders van vv Gemert. Bij welke team/teams heeft hij naast vv Gemert allemaal gespeeld? D: PSV en Helmond Sport. 3. Een spelregelvraag. Een speler krijgt een ingooi. Hij gooit terug op de doelman, maar de bal rolt in eigen doel. Wat doet de scheidsrechter? B: Hij kent de andere partij een hoekschop toe. 4. In 1958 vond deze competitiewedstrijd plaats tussen Gemert en Schijndel, toen nog op het sportpark aan de Molenstraat. Wie maakte het eerste doelpunt namens vv Gemert? B: Hans van Wetten 5. Dennis Bergkamp schoot Nederland op het WK in 1998 naar de halve finale met de 2-1 tegen Argentinië. Het was een weergaloos doelpunt, na een diepe pass van Frank de Boer. Hoe nam Bergkamp die lange bal aan? B; Met zijn rechtervoet. 6. Marinus van der Velden, beter bekend als ‘Meester van der Velden’ was vele jaren voorzitter van de club en een legendarisch persoon binnen onze vereniging. Hij was leerkracht en hoofd op een school in Gemert. Welke? C: Komschool 7. Wat is de nationaliteit van de doelpuntmaker van FC Groningen in het filmpje? B: Argentijns 8. Wanneer is de staantribune aan de oostzijde van het hoofdveld van vv Gemert in gebruik genomen? B: Bij de start van het seizoen 1995-1996 9. -

2016 Panini Flawless Soccer Cards Checklist
Card Set Number Player Base 1 Keisuke Honda Base 2 Riccardo Montolivo Base 3 Antoine Griezmann Base 4 Fernando Torres Base 5 Koke Base 6 Ilkay Gundogan Base 7 Marco Reus Base 8 Mats Hummels Base 9 Pierre-Emerick Aubameyang Base 10 Shinji Kagawa Base 11 Andres Iniesta Base 12 Dani Alves Base 13 Lionel Messi Base 14 Luis Suarez Base 15 Neymar Jr. Base 16 Arjen Robben Base 17 Arturo Vidal Base 18 Franck Ribery Base 19 Manuel Neuer Base 20 Thomas Muller Base 21 Fernando Muslera Base 22 Wesley Sneijder Base 23 David Luiz Base 24 Edinson Cavani Base 25 Marco Verratti Base 26 Thiago Silva Base 27 Zlatan Ibrahimovic Base 28 Cristiano Ronaldo Base 29 Gareth Bale Base 30 Keylor Navas Base 31 James Rodriguez Base 32 Raphael Varane Base 33 Karim Benzema Base 34 Axel Witsel Base 35 Ezequiel Garay Base 36 Hulk Base 37 Angel Di Maria Base 38 Gonzalo Higuain Base 39 Javier Mascherano Base 40 Lionel Messi Base 41 Pablo Zabaleta Base 42 Sergio Aguero Base 43 Eden Hazard Base 44 Jan Vertonghen Base 45 Marouane Fellaini Base 46 Romelu Lukaku Base 47 Thibaut Courtois Base 48 Vincent Kompany Base 49 Edin Dzeko Base 50 Dani Alves Base 51 David Luiz Base 52 Kaka Base 53 Neymar Jr. Base 54 Thiago Silva Base 55 Alexis Sanchez Base 56 Arturo Vidal Base 57 Claudio Bravo Base 58 James Rodriguez Base 59 Radamel Falcao Base 60 Ivan Rakitic Base 61 Luka Modric Base 62 Mario Mandzukic Base 63 Gary Cahill Base 64 Joe Hart Base 65 Raheem Sterling Base 66 Wayne Rooney Base 67 Hugo Lloris Base 68 Morgan Schneiderlin Base 69 Olivier Giroud Base 70 Patrice Evra Base 71 Paul -
Barcelona's Financial Crisis to Have MAJOR Impact on January Transfer
We'd like to notify you about the latest This website uses cookies to ensure you get the best experience on our website. Learn more Got it! updates You can unsubscribe from notifications anytime View in Hindi: LIVE TV Later Allow The Debate India News India Vs Australia Coronavirus Entertainment News PoweredSports by iZooto News World News Opinions Nation Wants To Know Home / Sports News / Football News / Barcelona’s nancial crisis to have MAJOR impact on January transfer window signings Last Updated: 24th November, 2020 13:55 IST Barcelona’s Financial Crisis To Have MAJOR Impact On January Transfer Window Signings Barcelona’s ongoing financial issues and the players' refusal to take pay cuts may hamper the club's transfer business in the upcoming transfer window. Written By Azhar Mohamed Sınırsız Geniş Ekran 2.6 GHz İşlemcisi, 4 GB RAM’i ve Android 9.0 İşletim Sistemiyle Temponuz Hızlanacak Reeder Satın Alın MUST READ View all Barcelona’s ongoing financial issues will have a major impact on the club’s ability to buy players 11 hours ago in the January transfer window. Earlier this year, the Barcelona board had asked their players to Hardik Pandya enjoys dinner date take a wage cut in order to help with their finances. The financial condition at Barcelona was with wife Natasa Stankovic after unstable in the summer, which meant they were unable to sign their targets in the transfer returning from Australia window. 11 hours ago Liverpool midfielder Georginio Wijnaldum and Olympique Lyonnais attacker Memphis Depay Pakistan pacer Mohammad Amir were both seen as targets for new manager Ronald Koeman but the club was unable to land 'leaving Cricket for now' at 28; PCB either of them. -

Matteo Darmian PLUS: 10 THINGS YOU DIDN’T KNOW ABOUT Memphis Depay 2 CONTENTS Vol 19 | Issue 1 | | CONTENTS Vol 19 | Issue 1 3
DISABLED SUPPORTERS ASSOCIATION Disabled Supporters Association THE OFFICIAL MUDSA MAGAZINE VOLUME 19, ISSUE 1, SUMMER 2015 DISABLED SUPPORTERS ASSOCIATION acebook! is now on F Join the group by visiting: facebook.com/groups/rollinreds We’ll be asking you for your matchday stories and photos for the magazine and even your questions for the player interviews! Get involved! EXCLUSIVE INTERVIEW WITH Matteo Darmian PLUS: 10 THINGS YOU DIDN’T KNOW ABOUT Memphis Depay 2 CONTENTS Vol 19 | Issue 1 | | CONTENTS Vol 19 | Issue 1 3 Opening his account... Memphis scored two stylish goals at Old Trafford in August to open his Manchester United account. PHIL DOWNS, MBE SUE ROCCA SECRETARY/DLO TREASURER C/O Ticketing & Membership Services, 113 Darley Avenue, Inside this edition… Manchester United, Sir Matt Busby Way, Manchester, M21 7QR Old Trafford, Manchester, M16 0RA T: 0161 861 9454 4 The Platform with Jamie T: 0845 230 1989 E: [email protected] E: [email protected] 5 Team Talk with Chas JOHN SIMISTER 6 secretary says… with Phil JAMIE LEEMING VI REPRESENTITIVE 8 MUDSA goes to the dogs! EDITOR C/O Ticketing & Membership Services, The official MUDsA magazine Pictures: 1 Althorpe Drive, Southport, PR8 6HS Manchester United, Sir Matt Busby Way, Volume 19, Issue 1, Summer 2015 10 Things You Didn’t Know: Memphis T: 07590 406669 Old Trafford, Manchester, M16 0RA This magazine is issued free of charge to MUDSA 12 Pictures: The £850m Squad E: [email protected] T: 07521 863737 members. You can also view Rollin’ Reds and E: [email protected] -

BESTE SPELERS B Junioren Eredivisie Seizoen 2009/'10 Stand Per 6 Mei 2010
BESTE SPELERS B junioren Eredivisie seizoen 2009/'10 Stand per 6 mei 2010 Naam Club Team Totaal 1 Chris David FC Twente Academie B1 45 2 Ouasim Bouy Ajax B1 39 3 Leegreg Fer Excelsior R. B1 33 4 Anthony van den Hurk PSV B1 30 5 Tigran Gazarjan RVO FC Groningen B1 28 Cas Peters FC Twente Academie B1 28 Diego Theunissen NAC Breda B1 28 8 Jurgen Locadia Willem II/RKC B1 27 9 Jair Balrak Feyenoord B1 25 Lesly de Sa Ajax B1 25 11 Giovanni Cairo NAC Breda B1 24 Elvis Manu Feyenoord B1 24 Moreno Rutten Feyenoord B1 24 Hakim Ziyech RJO Heerenveen Emmen B1 24 15 Pepijn Kooij Excelsior R. B1 23 Yoell van Nieff RVO FC Groningen B1 23 Rick Stuy van den Herik Sparta Rotterdam B1 23 18 Murat Gök Excelsior R. B1 22 19 Virgil Misidjan Willem II/RKC B1 21 Thierry Monteny ADO Den Haag B1 21 21 Memphis Depay PSV B1 20 Robert Klaasen AZ B1 20 23 Michael Chacon Ibarguen RJO Heerenveen Emmen B1 19 Martin la Cruz Sparta Rotterdam B1 19 25 Fabian Sporkslede Ajax B1 18 Jordy Toorenburg ADO Den Haag B1 18 Mitchel de Vlugt ADO Den Haag B1 18 28 Adikalie Kamara Willem II/RKC B1 17 Elvio do Rosario PSV B1 17 Luciano Slagveer RJO Heerenveen Emmen B1 17 31 Lucas Bijker RVO FC Groningen B1 16 Michael Birnie RJO Heerenveen Emmen B1 16 Kevin Luckassen AZ B1 16 Hafid Salhi Willem II/RKC B1 16 35 Micro Born FC Twente Academie B1 15 Thomas Horsten PSV B1 15 Gino van Kessel AZ B1 15 38 Geraldo Alberto Antonio AZ B1 14 Adnan Bajic Sparta Rotterdam B1 14 40 Junior Ebobo NAC Breda B1 13 Mats van Huijgevoort Feyenoord B1 13 Jeffrey Ket AZ B1 13 Jamail Piqué Excelsior R. -

Number #9 in the TDF Top 50
From being a small boy, I have always been a huge fan of both football and professional wrestling and at around the age of 10-years-old, I came across a monthly magazine brought to newsagents from the makers of the world famous Sports Illustrated all about pro wrestling. It was simply named Pro Wrestling Illustrated. It was a publication I regularly read as well as Shoot and Match weekly magazines to feed my football addiction. In 1991, PWI began this new craze that instantly grabbed my attention more than no other magazine had before. They revealed the 'PWI 500'. The 'PWI 500' section in the magazine listed (in rank order) the top 500 professional wrestlers in the world that year. Counting down from 500, this revealed to me many, many talents that I have not discovered as of yet. This was released every year, and still to this day is the best selling edition of the magazine each year. I studied and read and read over and over again that edition in 1991 and I came up with an idea. What if Match or Shoot revealed the top 500 footballers in the world? Thinking back to 1991, I used to love to tune into the 'BBC Radio 1 Top 40' show every Sunday afternoon too... maybe I'm a tad obsessed with countdowns. Anyways, reflecting on the idea, I thought about it each year the 'PWI 500' was released. As years went on, I felt that this would have grown into a hugely successful plan, gaining great recognition with people in the game, possibly gained its own award ceremony on TV with the emergence and exposure SKY Television in the United Kingdom was just beginning to give to the game back then. -

Big-5 Weekly Post
CIES Football Observatory Issue n°99- 17/02/2015 Big-5 Weekly Post Experience capital: most promising players, by age category and position Experience capital: number of matches played in adult championships weighted by league level and club results. For more information, see CIES Football Observatory Monthly Report 2. Goalkeepers Big-5 Other leagues2 U201 Mouez Hassen, Nice (FRA) 12.1 Georgi Kitanov, Cherno More Varna (BUL) 23.8 U21 Stefanos Kapino, Mainz (GER) 33.1 Yvon Mvogo, Young Boys (SUI) 25.6 U22 Jan Oblak, Atlético Madrid (ESP) 57.2 Oliver Zelenika, Lokomotiva Zagreb (CRO) 26.4 U23 Thibaut Courtois, Chelsea (ENG) 200.6 Mathew Ryan, Club Brugge (BEL) 83.1 Full backs Big-5 Other leagues2 U20 Luke Shaw, Manchester United (ENG) 65.8 Eduard Sobol, Metalurg Donetsk (UKR) 29.4 U21 Benjamin Mendy, Marseille (FRA) 60.8 Jetro Willems, PSV (NED) 94.5 U22 Juan Bernat, Bayern München (GER) 75.3 Jonas Svensson, Rosenborg (NOR) 62.9 U23 David Alaba, Bayern München (GER) 155.2 Laurens De Bock, Club Brugge (BEL) 82.4 Centre backs Big-5 Other leagues2 U20 Niklas Süle, Hoffenheim (GER) 36.4 Milan Škriniar, MŠK Žilina (SVK) 21.8 U21 Marquinhos Aoás, PSG (FRA) 66.8 Karim Rekik, PSV (NED) 52.2 U22 Raphaël Varane, Real Madrid (ESP) 84.8 Emil Bergström, Djurgårdens (SWE) 46.7 U23 Phil Jones, Manchester United (ENG) 143.0 Bruno Martins Indi, Porto (POR) 115.7 Defensive/Central midfielders Big-5 Other leagues2 U20 Carlos Gruezo, Stuttgart (GER) 51.0 Tonny Vilhena, Feyenoord (NED) 76.8 U21 Mateo Kovačić, Internazionale (ITA) 81.5 Kyle Ebecilio, Twente (NED) -
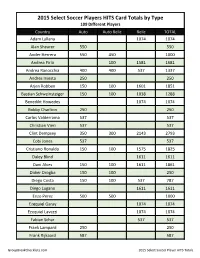
2015 Select Soccer Team HITS Checklist;
2015 Select Soccer Players HITS Card Totals by Type 109 Different Players Country Auto Auto Relic Relic TOTAL Adam Lallana 1074 1074 Alan Shearer 550 550 Ander Herrera 550 450 1000 Andrea Pirlo 100 1581 1681 Andrea Ranocchia 400 400 537 1337 Andres Iniesta 250 250 Arjen Robben 150 100 1601 1851 Bastian Schweinsteiger 150 100 1038 1288 Benedikt Howedes 1074 1074 Bobby Charlton 250 250 Carlos Valderrama 537 537 Christian Vieri 537 537 Clint Dempsey 350 300 2143 2793 Cobi Jones 537 537 Cristiano Ronaldo 150 100 1575 1825 Daley Blind 1611 1611 Dani Alves 150 100 1611 1861 Didier Drogba 150 100 250 Diego Costa 150 100 537 787 Diego Lugano 1611 1611 Enzo Perez 500 500 1000 Ezequiel Garay 1074 1074 Ezequiel Lavezzi 1074 1074 Fabian Schar 537 537 Frank Lampard 250 250 Frank Rijkaard 587 587 GroupBreakChecklists.com 2015 Select Soccer Player HITS Totals Country Auto Auto Relic Relic TOTAL Franz Beckenbauer 250 250 Gerard Pique 150 100 1601 1851 Gervinho 525 475 1611 2611 Gianluigi Buffon 125 125 1521 1771 Guillermo Ochoa 335 125 1611 2071 Harry Kane 513 503 537 1553 Hector Herrera 537 537 Hugo Sanchez 539 539 Iker Casillas 1591 1591 Ivan Rakitic 450 450 1024 1924 Ivan Zamorano 537 537 James Rodriguez 125 125 1611 1861 Jan Vertonghen 200 150 1074 1424 Jasper Cillessen 1575 1575 Javier Mascherano 1074 1074 Joao Moutinho 1611 1611 Joe Hart 175 175 1561 1911 John Terry 587 100 687 Jordan Henderson 1074 1074 Jorge Campos 587 587 Jozy Altidore 275 225 1611 2111 Juan Mata 425 375 800 Jurgen Klinsmann 250 250 Karim Benzema 537 537 Kevin Mirallas 525 475