Kernel Isolation from an Academic Idea to an Efficient Patch for Every Computer DANIELSECURITY GRUSS, DAVE HANSEN, and BRENDAN GREGG
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
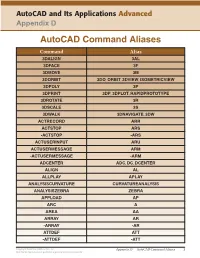
Autocad Command Aliases
AutoCAD and Its Applications Advanced Appendix D AutoCAD Command Aliases Command Alias 3DALIGN 3AL 3DFACE 3F 3DMOVE 3M 3DORBIT 3DO, ORBIT, 3DVIEW, ISOMETRICVIEW 3DPOLY 3P 3DPRINT 3DP, 3DPLOT, RAPIDPROTOTYPE 3DROTATE 3R 3DSCALE 3S 3DWALK 3DNAVIGATE, 3DW ACTRECORD ARR ACTSTOP ARS -ACTSTOP -ARS ACTUSERINPUT ARU ACTUSERMESSAGE ARM -ACTUSERMESSAGE -ARM ADCENTER ADC, DC, DCENTER ALIGN AL ALLPLAY APLAY ANALYSISCURVATURE CURVATUREANALYSIS ANALYSISZEBRA ZEBRA APPLOAD AP ARC A AREA AA ARRAY AR -ARRAY -AR ATTDEF ATT -ATTDEF -ATT Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 1 May not be reproduced or posted to a publicly accessible website. Command Alias ATTEDIT ATE -ATTEDIT -ATE, ATTE ATTIPEDIT ATI BACTION AC BCLOSE BC BCPARAMETER CPARAM BEDIT BE BLOCK B -BLOCK -B BOUNDARY BO -BOUNDARY -BO BPARAMETER PARAM BREAK BR BSAVE BS BVSTATE BVS CAMERA CAM CHAMFER CHA CHANGE -CH CHECKSTANDARDS CHK CIRCLE C COLOR COL, COLOUR COMMANDLINE CLI CONSTRAINTBAR CBAR CONSTRAINTSETTINGS CSETTINGS COPY CO, CP CTABLESTYLE CT CVADD INSERTCONTROLPOINT CVHIDE POINTOFF CVREBUILD REBUILD CVREMOVE REMOVECONTROLPOINT CVSHOW POINTON Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 2 May not be reproduced or posted to a publicly accessible website. Command Alias CYLINDER CYL DATAEXTRACTION DX DATALINK DL DATALINKUPDATE DLU DBCONNECT DBC, DATABASE, DATASOURCE DDGRIPS GR DELCONSTRAINT DELCON DIMALIGNED DAL, DIMALI DIMANGULAR DAN, DIMANG DIMARC DAR DIMBASELINE DBA, DIMBASE DIMCENTER DCE DIMCONSTRAINT DCON DIMCONTINUE DCO, DIMCONT DIMDIAMETER DDI, DIMDIA DIMDISASSOCIATE DDA DIMEDIT DED, DIMED DIMJOGGED DJO, JOG DIMJOGLINE DJL DIMLINEAR DIMLIN, DLI DIMORDINATE DOR, DIMORD DIMOVERRIDE DOV, DIMOVER DIMRADIUS DIMRAD, DRA DIMREASSOCIATE DRE DIMSTYLE D, DIMSTY, DST DIMTEDIT DIMTED DIST DI, LENGTH DIVIDE DIV DONUT DO DRAWINGRECOVERY DRM DRAWORDER DR Copyright Goodheart-Willcox Co., Inc. -

Mac Keyboard Shortcuts Cut, Copy, Paste, and Other Common Shortcuts
Mac keyboard shortcuts By pressing a combination of keys, you can do things that normally need a mouse, trackpad, or other input device. To use a keyboard shortcut, hold down one or more modifier keys while pressing the last key of the shortcut. For example, to use the shortcut Command-C (copy), hold down Command, press C, then release both keys. Mac menus and keyboards often use symbols for certain keys, including the modifier keys: Command ⌘ Option ⌥ Caps Lock ⇪ Shift ⇧ Control ⌃ Fn If you're using a keyboard made for Windows PCs, use the Alt key instead of Option, and the Windows logo key instead of Command. Some Mac keyboards and shortcuts use special keys in the top row, which include icons for volume, display brightness, and other functions. Press the icon key to perform that function, or combine it with the Fn key to use it as an F1, F2, F3, or other standard function key. To learn more shortcuts, check the menus of the app you're using. Every app can have its own shortcuts, and shortcuts that work in one app may not work in another. Cut, copy, paste, and other common shortcuts Shortcut Description Command-X Cut: Remove the selected item and copy it to the Clipboard. Command-C Copy the selected item to the Clipboard. This also works for files in the Finder. Command-V Paste the contents of the Clipboard into the current document or app. This also works for files in the Finder. Command-Z Undo the previous command. You can then press Command-Shift-Z to Redo, reversing the undo command. -

Alias Manager 4
CHAPTER 4 Alias Manager 4 This chapter describes how your application can use the Alias Manager to establish and resolve alias records, which are data structures that describe file system objects (that is, files, directories, and volumes). You create an alias record to take a “fingerprint” of a file system object, usually a file, that you might need to locate again later. You can store the alias record, instead of a file system specification, and then let the Alias Manager find the file again when it’s needed. The Alias Manager contains algorithms for locating files that have been moved, renamed, copied, or restored from backup. Note The Alias Manager lets you manage alias records. It does not directly manipulate Finder aliases, which the user creates and manages through the Finder. The chapter “Finder Interface” in Inside Macintosh: Macintosh Toolbox Essentials describes Finder aliases and ways to accommodate them in your application. ◆ The Alias Manager is available only in system software version 7.0 or later. Use the Gestalt function, described in the chapter “Gestalt Manager” of Inside Macintosh: Operating System Utilities, to determine whether the Alias Manager is present. Read this chapter if you want your application to create and resolve alias records. You might store an alias record, for example, to identify a customized dictionary from within a word-processing document. When the user runs a spelling checker on the document, your application can ask the Alias Manager to resolve the record to find the correct dictionary. 4 To use this chapter, you should be familiar with the File Manager’s conventions for Alias Manager identifying files, directories, and volumes, as described in the chapter “Introduction to File Management” in this book. -

Vmware Fusion 12 Vmware Fusion Pro 12 Using Vmware Fusion
Using VMware Fusion 8 SEP 2020 VMware Fusion 12 VMware Fusion Pro 12 Using VMware Fusion You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ VMware, Inc. 3401 Hillview Ave. Palo Alto, CA 94304 www.vmware.com © Copyright 2020 VMware, Inc. All rights reserved. Copyright and trademark information. VMware, Inc. 2 Contents Using VMware Fusion 9 1 Getting Started with Fusion 10 About VMware Fusion 10 About VMware Fusion Pro 11 System Requirements for Fusion 11 Install Fusion 12 Start Fusion 13 How-To Videos 13 Take Advantage of Fusion Online Resources 13 2 Understanding Fusion 15 Virtual Machines and What Fusion Can Do 15 What Is a Virtual Machine? 15 Fusion Capabilities 16 Supported Guest Operating Systems 16 Virtual Hardware Specifications 16 Navigating and Taking Action by Using the Fusion Interface 21 VMware Fusion Toolbar 21 Use the Fusion Toolbar to Access the Virtual-Machine Path 21 Default File Location of a Virtual Machine 22 Change the File Location of a Virtual Machine 22 Perform Actions on Your Virtual Machines from the Virtual Machine Library Window 23 Using the Home Pane to Create a Virtual Machine or Obtain One from Another Source 24 Using the Fusion Applications Menus 25 Using Different Views in the Fusion Interface 29 Resize the Virtual Machine Display to Fit 35 Using Multiple Displays 35 3 Configuring Fusion 37 Setting Fusion Preferences 37 Set General Preferences 37 Select a Keyboard and Mouse Profile 38 Set Key Mappings on the Keyboard and Mouse Preferences Pane 39 Set Mouse Shortcuts on the Keyboard and Mouse Preference Pane 40 Enable or Disable Mac Host Shortcuts on the Keyboard and Mouse Preference Pane 40 Enable Fusion Shortcuts on the Keyboard and Mouse Preference Pane 41 Set Fusion Display Resolution Preferences 41 VMware, Inc. -

Mac OS for Quicktime Programmers
Mac OS For QuickTime Programmers Apple Computer, Inc. Technical Publications April, 1998 Apple Computer, Inc. Apple, the Apple logo, Mac, LIMITED WARRANTY ON MEDIA © 1998 Apple Computer, Inc. Macintosh, QuickDraw, and AND REPLACEMENT All rights reserved. QuickTime are trademarks of Apple ALL IMPLIED WARRANTIES ON THIS No part of this publication or the Computer, Inc., registered in the MANUAL, INCLUDING IMPLIED software described in it may be United States and other countries. WARRANTIES OF reproduced, stored in a retrieval The QuickTime logo is a trademark MERCHANTABILITY AND FITNESS system, or transmitted, in any form of Apple Computer, Inc. FOR A PARTICULAR PURPOSE, ARE or by any means, mechanical, Adobe, Acrobat, Photoshop, and LIMITED IN DURATION TO NINETY electronic, photocopying, recording, PostScript are trademarks of Adobe (90) DAYS FROM THE DATE OF or otherwise, without prior written Systems Incorporated or its DISTRIBUTION OF THIS PRODUCT. permission of Apple Computer, Inc., subsidiaries and may be registered in Even though Apple has reviewed this except in the normal use of the certain jurisdictions. manual, APPLE MAKES NO software or to make a backup copy Helvetica and Palatino are registered WARRANTY OR REPRESENTATION, of the software or documentation. trademarks of Linotype-Hell AG EITHER EXPRESS OR IMPLIED, WITH The same proprietary and copyright and/or its subsidiaries. RESPECT TO THIS MANUAL, ITS notices must be affixed to any ITC Zapf Dingbats is a registered QUALITY, ACCURACY, permitted copies as were affixed to trademark of International Typeface MERCHANTABILITY, OR FITNESS the original. This exception does not Corporation. FOR A PARTICULAR PURPOSE. AS A allow copies to be made for others, RESULT, THIS MANUAL IS Simultaneously published in the whether or not sold, but all of the DISTRIBUTED “AS IS,” AND YOU United States and Canada. -

Carbon Copy Cloner Documentation: English
Carbon Copy Cloner Documentation: English Getting started with CCC System Requirements, Installing, Updating, and Uninstalling CCC CCC License, Registration, and Trial FAQs Trouble Applying Your Registration Information? Establishing an initial backup Preparing your backup disk for a backup of Mac OS X Restoring data from your backup What's new in CCC Features of CCC specific to Lion and greater Release History Carbon Copy Cloner's Transition to a Commercial Product: Frequently Asked Questions Credits Example backup scenarios I want to clone my entire hard drive to a new hard drive or a new machine I want to backup my important data to another Macintosh on my network I want to backup multiple machines or hard drives to the same hard drive I want my backup task to run automatically on a scheduled basis Backing up to/from network volumes and other non-HFS volumes I want to back up my whole Mac to a Time Capsule or other network volume I want to defragment my hard drive Backup and archiving settings Excluding files and folders from a backup task Protecting data that is already on your destination volume Managing previous versions of your files Automated maintenance of CCC archives Advanced Settings Some files and folders are automatically excluded from a backup task The Block-Level Copy Scheduling Backup Tasks Scheduling a task and basic settings Performing actions Before and After the backup task Deferring and skipping scheduled tasks Frequently asked questions about scheduled tasks Email and Growl notifications Backing Up to Disk Images -

Autodesk Alias 2108 Comparison Matrix
http://www.imaginit.com/alias Product design and Class-A surfacing software 2018 Feature Comparison Alias Applications Alias Design Alias Surface AutoStudio VRed Design - - ü Speedform - - ü Sketchbook ü Shipped with 2016 product. - - Maya ü Shipped with 2016 product. - - Automotive Asset Library - - ü Alias Concept Exploration Alias Design Alias Surface AutoStudio Paint and Canvas Tools ü - ü Overlay Annotation ü ü ü Alias Sketching/Manipulation Alias Design Alias Surface AutoStudio Raster brushes ü - ü Annotation pencils - ü - Custom texture brush ü - ü Effect brushes ü - ü Vector/Raster Hybrid (editable shapes) ü - ü Symmetry ü - ü Gradient Fill ü - ü Raster Text ü ü ü Image warping (transforming) ü - ü Color Replace ü - ü Image Cropping ü - ü Sketch over 3D data (underlay) ü - ü Page 1 of 7 For more information visit www.autodesk.com/products/alias-products http://www.imaginit.com/alias Mark-up brushes over 3D - ü - Project sketch on 3D geometry ü - ü Import Image ü ü ü Save images ü ü *screen and window export * Alias Modeling Alias Design Alias Surface AutoStudio G2 Continuity ü ü ü G3 Continuity - ü ü Explicit Control - ü ü Offset ü ü ü Extend ü ü ü Cut ü ü ü Align ü ü ü Symmetrical Align ü ü ü Smoothing ü ü ü Query Edit ü ü ü Attach ü ü ü Insert ü ü ü Vectors ü ü ü Dynamic Planes ü ü ü Transform Curve Operator ü ü ü Surface/Curve Orientation ü ü ü Workflows ü ü *partial * Preference Sets and Workspaces ü ü ü Alias Dynamic Shape Modeling Alias Design Alias Surface AutoStudio DSM: Transformer Rig - ü ü DSM: Conform Rig ü ü ü DSM: -

Apple Remote Desktop Administrator's Guide
Apple Remote Desktop Administrator’s Guide Version 3 K Apple Computer, Inc. © 2006 Apple Computer, Inc. All rights reserved. The owner or authorized user of a valid copy of Apple Remote Desktop software may reproduce this publication for the purpose of learning to use such software. No part of this publication may be reproduced or transmitted for commercial purposes, such as selling copies of this publication or for providing paid for support services. The Apple logo is a trademark of Apple Computer, Inc., registered in the U.S. and other countries. Use of the “keyboard” Apple logo (Option-Shift-K) for commercial purposes without the prior written consent of Apple may constitute trademark infringement and unfair competition in violation of federal and state laws. Apple, the Apple logo, AirPort, AppleScript, AppleTalk, AppleWorks, FireWire, iBook, iMac, iSight, Keychain, Mac, Macintosh, Mac OS, PowerBook, QuickTime, and Xserve are trademarks of Apple Computer, Inc., registered in the U.S. and other countries. Apple Remote Desktop, Bonjour, eMac, Finder, iCal, and Safari are trademarks of Apple Computer, Inc. Adobe and Acrobat are trademarks of Adobe Systems Incorporated. Java and all Java-based trademarks and logos are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and other countries. UNIX is a registered trademark in the United States and other countries, licensed exclusively through X/Open Company, Ltd. 019-0629/02-28-06 3 Contents Preface 9 About This Book 10 Using This Guide 10 Remote Desktop Help 10 Notation -

Using Windows XP and File Management
C&NS Winter ’08 Faculty Computer Training Using and Maintaining your Mac Table of Contents Introduction to the Mac....................................................................................................... 1 Introduction to Apple OS X (Tiger).................................................................................... 2 Accessing Microsoft Windows if you have it installed .................................................. 2 The OS X Interface ............................................................................................................. 2 Tools for accessing items on your computer .................................................................. 3 Menus.............................................................................................................................. 7 Using Windows............................................................................................................... 8 The Dock....................................................................................................................... 10 Using Mac OS X............................................................................................................... 11 Hard Drive Organization............................................................................................... 11 Folder and File Creation, Managing, and Organization ............................................... 12 Opening and Working with Applications ..................................................................... 15 Creating and -

(Software CD/DVD Bundles) APPLE COMPUTER
Apple Computer, Inc. iTunes 7 and QuickTime 7 Bundling Agreement (Software CD/DVD Bundles) APPLE COMPUTER, INC. Software Licensing Department 12545 Riata Vista Circle MS 198-3SWL Austin, TX 78727 E-Mail Address: [email protected] Licensee (Company Name): _____________________________________________ (Must be the copyright owner of products listed in Exhibit A, paragraph 2) Individual to Contact: _____________________________________________ Street Address: _____________________________________________ City: __________________________________ State: ____________________ Zip/Postal Code: ____________________ Country: ________________________ Telephone Number: ____________________________________________ Fax Number: _____________________________________________ E-Mail Address: (Required) ______________________________________________ Licensee’s Site: ______________________________________________ (provide name and address of Licensee's page/URL on the World Wide Web, if applicable Agreement Apple Computer, Inc. ("Apple") and Licensee agree that the terms and conditions of this Agreement shall govern Licensee's use and distribution of the iTunes and QuickTime Software, as defined below. 1. Definitions 1.1 “Bundle” means the bundle(s) identified in Exhibit A distributed by or on behalf of Licensee. 1.2 “Effective Date” means the date on which Apple executed this Agreement as set forth on the signature page. SWL263-091506 Page 1 1.3 “Software” means the iTunes and QuickTime Software identified in Exhibit A, and any updates thereto provided -

Uulity Programs and Scripts
U"lity programs and scripts Thomas Herring [email protected] U"lity Overview • In this lecture we look at a number of u"lity scripts and programs used in the gamit/globk suite of programs. • We examine and will show examples in the areas of – Organizaon/Pre-processing – Scripts used by sh_gamit but useful stand-alone – Evaluang results • Also examine some basic unix, csh, bash programs and method. 11/19/12 Uli"es Lec 08 2 Guide to scripts • There are many scripts in the ~/gg/com directory and you should with "me looks at all these scripts because they oSen contain useful guides as to how to do certain tasks. – Look the programs used in the scripts because these show you the sequences and inputs needed for different tasks – Scrip"ng methods are useful when you want to automate tasks or allow easy re-generaon of results. – Look for templates that show how different tasks can be accomplished. • ~/gg/kf/uls and ~/gg/gamit/uls contain many programs for u"lity tasks and these should be looked at to see what is available. 11/19/12 Uli"es Lec 08 3 GAMIT/GLOBK Utilities" 1.! Organization/Pre-processing" sh_get_times: List start/stop times for all RINEX files" sh_upd_stnfo: Add entries to station.info from RINEX headers" convertc: Transform coodinates (cartesian/geodetic/spherical)" glist: List sites for h-files in gdl; check coordinates, models " corcom: Rotate an apr file to a different plate frame" unify_apr: Set equal velocities/coordinates for glorg equates" sh_dos2unix: Remove the extra CR from each line of a file" doy: Convert to/from DOY, YYMMDD, JD, MJD, GPSW" " " " GAMIT/GLOBK Utilities (cont)" 2. -

Mac Essentials Organizing SAS Software
Host Systems Getting Organized in Mac OS Rick Asler If you work on just one simple project with SAS MAE is emulation software to run Mac on some software, it may not matter very much how you UNIX systems. It is not the best way to run SAS organize your files. But if you work on a complex software. project or on several projects, your productivity and SAS software requires at least version 7.5 of peace of mind depend on organizing your projects Mac OS. System 7.5 shipped on new computers in effectively. 1994-1995 and can be purchased separately for This paper presents a system for organizing the older computers. A new system version is due in files of SAS projects, taking advantage of the 1996. special features of Mac OS. Then it demonstrates A computer system for running SAS software techniques for automating SAS projects. should also have at least an average-size hard disk and at least 16 megabytes of physical RAM. The Finder is the main application that is always Mac essentials running in Mac OS. It displays disks and files as icons and subdirectories as folders. First, these are some Mac terms and features The system folder is the folder containing the you may need to be aware of to operate SAS System file, Finder, and other Mac OS files. software under Mac OS. The Trash Is a Finder container where deleted Mac, Mac OS, Mac operating system, or Macin files go. You can retrieve them Hyou don't wait too tosh operating system is the distinctive graphical long.