Chapter 3: Preparing for Installation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enterprise Search Technology Using Solr and Cloud Padmavathy Ravikumar Governors State University
Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Enterprise Search Technology Using Solr and Cloud Padmavathy Ravikumar Governors State University Follow this and additional works at: http://opus.govst.edu/capstones Part of the Databases and Information Systems Commons Recommended Citation Ravikumar, Padmavathy, "Enterprise Search Technology Using Solr and Cloud" (2015). All Capstone Projects. 91. http://opus.govst.edu/capstones/91 For more information about the academic degree, extended learning, and certificate programs of Governors State University, go to http://www.govst.edu/Academics/Degree_Programs_and_Certifications/ Visit the Governors State Computer Science Department This Project Summary is brought to you for free and open access by the Student Capstone Projects at OPUS Open Portal to University Scholarship. It has been accepted for inclusion in All Capstone Projects by an authorized administrator of OPUS Open Portal to University Scholarship. For more information, please contact [email protected]. ENTERPRISE SEARCH TECHNOLOGY USING SOLR AND CLOUD By Padmavathy Ravikumar Masters Project Submitted in partial fulfillment of the requirements For the Degree of Master of Science, With a Major in Computer Science Governors State University University Park, IL 60484 Fall 2014 ENTERPRISE SEARCH TECHNOLOGY USING SOLR AND CLOUD 2 Abstract Solr is the popular, blazing fast open source enterprise search platform from the Apache Lucene project. Its major features include powerful full-text search, hit highlighting, faceted search, near real-time indexing, dynamic clustering, database in9tegration, rich document (e.g., Word, PDF) handling, and geospatial search. Solr is highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. -

Next Generation Web Scanning Presentation
Next generation web scanning New Zealand: A case study First presented at KIWICON III 2009 By Andrew Horton aka urbanadventurer NZ Web Recon Goal: To scan all of New Zealand's web-space to see what's there. Requirements: – Targets – Scanning – Analysis Sounds easy, right? urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets What does 'NZ web-space' mean? It could mean: •Geographically within NZ regardless of the TLD •The .nz TLD hosted anywhere •All of the above For this scan it means, IPs geographically within NZ urbanadventurer (Andrew Horton) www.morningstarsecurity.com Finding Targets We need creative methods to find targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com DNS Zone Transfer urbanadventurer (Andrew Horton) www.morningstarsecurity.com Find IP addresses on IRC and by resolving lots of NZ websites 58.*.*.* 60.*.*.* 65.*.*.* 91.*.*.* 110.*.*.* 111.*.*.* 113.*.*.* 114.*.*.* 115.*.*.* 116.*.*.* 117.*.*.* 118.*.*.* 119.*.*.* 120.*.*.* 121.*.*.* 122.*.*.* 123.*.*.* 124.*.*.* 125.*.*.* 130.*.*.* 131.*.*.* 132.*.*.* 138.*.*.* 139.*.*.* 143.*.*.* 144.*.*.* 146.*.*.* 150.*.*.* 153.*.*.* 156.*.*.* 161.*.*.* 162.*.*.* 163.*.*.* 165.*.*.* 166.*.*.* 167.*.*.* 192.*.*.* 198.*.*.* 202.*.*.* 203.*.*.* 210.*.*.* 218.*.*.* 219.*.*.* 222.*.*.* 729,580,500 IPs. More than we want to try. urbanadventurer (Andrew Horton) www.morningstarsecurity.com IP address blocks in the IANA IPv4 Address Space Registry Prefix Designation Date Whois Status [1] ----- -

Dspace 1.8 Documentation
DSpace 1.8 Documentation DSpace 1.8 Documentation Author: The DSpace Developer Team Date: 03 November 2011 URL: https://wiki.duraspace.org/display/DSDOC18 Page 1 of 621 DSpace 1.8 Documentation Table of Contents 1 Preface _____________________________________________________________________________ 13 1.1 Release Notes ____________________________________________________________________ 13 2 Introduction __________________________________________________________________________ 15 3 Functional Overview ___________________________________________________________________ 17 3.1 Data Model ______________________________________________________________________ 17 3.2 Plugin Manager ___________________________________________________________________ 19 3.3 Metadata ________________________________________________________________________ 19 3.4 Packager Plugins _________________________________________________________________ 20 3.5 Crosswalk Plugins _________________________________________________________________ 21 3.6 E-People and Groups ______________________________________________________________ 21 3.6.1 E-Person __________________________________________________________________ 21 3.6.2 Groups ____________________________________________________________________ 22 3.7 Authentication ____________________________________________________________________ 22 3.8 Authorization _____________________________________________________________________ 22 3.9 Ingest Process and Workflow ________________________________________________________ 24 -

Building Multiplayer Games with Web Sockets #GHC19 About Us
Leveling Up: Building Multiplayer Games with Web Sockets #GHC19 About Us: #GHC19 Agenda 0. Introduction 1. Simple Chat Application 2. Multiplayer Game 3. Further Applications #GHC19 www.kahoot.com #GHC19 #GHC19 #GHC19 #GHC19 Diagram source: BMC Blog #GHC19 Diagram source: BMC Blog TCP and UDP are the transport level protocols TCP UDP Reliable Unreliable Connection-oriented Connectionless Segment sequencing No sequencing Acknowledge No acknowledgement segments #GHC19 Source: Pluralsight #GHC19 Diagram source: BMC Blog #GHC19 Diagram source: BMC Blog HTTP is used to share information on the application layer #GHC19 Graphic Source: Webnots Alternatives to WebSockets ● Browser Plug-Ins ● Polling ● Long Polling ● Server-Sent Events (SSE) #GHC19 The WebSocket protocol is used for real-time communication RFC-6455 #GHC19 Source: IETF RFC-6455 Some benefits of WebSockets Event driven Reduces network overhead - no need to send full HTTP requests HTTP compatible Co-exists on same port as your web server TLS/SSL compatible Same security as HTTPS #GHC19 WebSocket connection overview #GHC19 Diagram source: PubNub Staff Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Opening Handshake Client Handshake Server Handshake #GHC19 Source: IETF RFC-6455 Data Transfer Base Framing Protocol -

Final Report CS 5604: Information Storage and Retrieval
Final Report CS 5604: Information Storage and Retrieval Solr Team Abhinav Kumar, Anand Bangad, Jeff Robertson, Mohit Garg, Shreyas Ramesh, Siyu Mi, Xinyue Wang, Yu Wang January 16, 2018 Instructed by Professor Edward A. Fox Virginia Polytechnic Institute and State University Blacksburg, VA 24061 1 Abstract The Digital Library Research Laboratory (DLRL) has collected over 1.5 billion tweets and millions of webpages for the Integrated Digital Event Archiving and Library (IDEAL) and Global Event Trend Archive Research (GETAR) projects [6]. We are using a 21 node Cloudera Hadoop cluster to store and retrieve this information. One goal of this project is to expand the data collection to include more web archives and geospatial data beyond what previously had been collected. Another important part in this project is optimizing the current system to analyze and allow access to the new data. To accomplish these goals, this project is separated into 6 parts with corresponding teams: Classification (CLA), Collection Management Tweets (CMT), Collection Management Webpages (CMW), Clustering and Topic Analysis (CTA), Front-end (FE), and SOLR. This report describes the work completed by the SOLR team which improves the current searching and storage system. We include the general architecture and an overview of the current system. We present the part that Solr plays within the whole system with more detail. We talk about our goals, procedures, and conclusions on the improvements we made to the current Solr system. This report also describes how we coordinate with other teams to accomplish the project at a higher level. Additionally, we provide manuals for future readers who might need to replicate our experiments. -

Hot Technologies” Within the O*NET® System
Identification of “Hot Technologies” within the O*NET® System Phil Lewis National Center for O*NET Development Jennifer Norton North Carolina State University Prepared for U.S. Department of Labor Employment and Training Administration Office of Workforce Investment Division of National Programs, Tools, & Technical Assistance Washington, DC April 4, 2016 www.onetcenter.org National Center for O*NET Development, Post Office Box 27625, Raleigh, NC 27611 Table of Contents Background ......................................................................................................................... 2 Hot Technologies Identification Procedure ...................................................................... 3 Mine data to collect the top technology related terms ................................................ 3 Convert the data-mined technology terms into O*NET technologies ......................... 3 Organize the hot technologies within the O*NET Tools & Technology Taxonomy ..... 4 Link the hot technologies to O*NET-SOC occupations .............................................. 4 Determine the display of occupations linked to a hot technology ............................... 4 Summary ............................................................................................................................. 5 Figure 1: O*NET Hot Technology Icon .............................................................................. 6 Appendix A: Hot Technologies Identified During the Initial Implementation ................ 7 National Center -
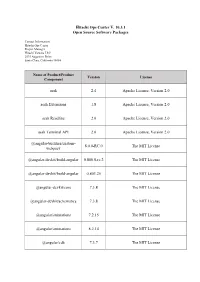
Open Source Software Packages
Hitachi Ops Center V. 10.3.1 Open Source Software Packages Contact Information: Hitachi Ops Center Project Manager Hitachi Vantara LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component aesh 2.4 Apache License, Version 2.0 aesh Extensions 1.8 Apache License, Version 2.0 aesh Readline 2.0 Apache License, Version 2.0 aesh Terminal API 2.0 Apache License, Version 2.0 @angular-builders/custom- 8.0.0-RC.0 The MIT License webpack @angular-devkit/build-angular 0.800.0-rc.2 The MIT License @angular-devkit/build-angular 0.803.25 The MIT License @angular-devkit/core 7.3.8 The MIT License @angular-devkit/schematics 7.3.8 The MIT License @angular/animations 7.2.15 The MIT License @angular/animations 8.2.14 The MIT License @angular/cdk 7.3.7 The MIT License Name of Product/Product Version License Component @angular/cli 8.0.0 The MIT License @angular/cli 8.3.25 The MIT License @angular/common 7.2.15 The MIT License @angular/common 8.2.14 The MIT License @angular/compiler 7.2.15 The MIT License @angular/compiler 8.2.14 The MIT License @angular/compiler-cli 8.2.14 The MIT License @angular/core 7.2.15 The MIT License @angular/forms 7.2.13 The MIT License @angular/forms 7.2.15 The MIT License @angular/forms 8.2.14 The MIT License @angular/forms 8.2.7 The MIT License @angular/language-service 8.2.14 The MIT License @angular/platform-browser 7.2.15 The MIT License @angular/platform-browser 8.2.14 The MIT License Name of Product/Product Version License Component @angular/platform-browser- 7.2.15 The MIT License -

Apache Lucene - a Library Retrieving Data for Millions of Users
Apache Lucene - a library retrieving data for millions of users Simon Willnauer Apache Lucene Core Committer & PMC Chair [email protected] / [email protected] Friday, October 14, 2011 About me? • Lucene Core Committer • Project Management Committee Chair (PMC) • Apache Member • BerlinBuzzwords Co-Founder • Addicted to OpenSource 2 Friday, October 14, 2011 Apache Lucene - a library retrieving data for .... Agenda ‣ Apache Lucene a historical introduction ‣ (Small) Features Overview ‣ The Lucene Eco-System ‣ Upcoming features in Lucene 4.0 ‣ Maintaining superior quality in Lucene (backup slides) ‣ Questions 3 Friday, October 14, 2011 Apache Lucene - a brief introduction • A fulltext search library entirely written in Java • An ASF Project since 2001 (happy birthday Lucene) • Founded by Doug Cutting • Grown up - being the de-facto standard in OpenSource search • Starting point for a other well known projects • Apache 2.0 License 4 Friday, October 14, 2011 Where are we now? • Current Version 3.4 (frequent minor releases every 2 - 4 month) • Strong Backwards compatibility guarantees within major releases • Solid Inverted-Index implementation • large committer base from various companies • well established community • Upcoming Major Release is Lucene 4.0 (more about this later) 5 Friday, October 14, 2011 (Small) Features Overview • Fulltext search • Boolean-, Range-, Prefix-, Wildcard-, RegExp-, Fuzzy-, Phase-, & SpanQueries • Faceting, Result Grouping, Sorting, Customizable Scoring • Large set of Language / Text-Processing -

Deploying with Jruby Is the Definitive Text on Getting Jruby Applications up and Running
Early Praise for Deploying JRuby Deploying with JRuby is the definitive text on getting JRuby applications up and running. Joe has pulled together a great collection of deployment knowledge, and the JRuby story is much stronger as a result. ➤ Charles Oliver Nutter JRuby Core team member and coauthor, Using JRuby Deploying with JRuby answers all of the most frequently asked questions regarding real-world use of JRuby that I have seen, including many we were not able to answer in Using JRuby. Whether you’re coming to JRuby from Ruby or Java, Joe fills in all the gaps you’ll need to deploy JRuby with confidence. ➤ Nick Sieger JRuby Core team member and coauthor, Using JRuby This book is an excellent guide to navigating the various JRuby deployment op- tions. Joe is fair in his assessment of these technologies and describes a clear path for getting your Ruby application up and running on the JVM. ➤ Bob McWhirter TorqueBox team lead at Red Hat Essential reading to learn not only how to deploy web applications on JRuby but also why. ➤ David Calavera Creator of Trinidad Deploying with JRuby is a must-read for anyone interested in production JRuby deployments. The book walks through the major deployment strategies by providing easy-to-follow examples that help the reader take full advantage of the JRuby servers while avoiding the common pitfalls of migrating an application to JRuby. ➤ Ben Browning TorqueBox developer at Red Hat Deploying with JRuby is an invaluable resource for anyone planning on using JRuby for web-based development. For those who have never used JRuby, Joe clearly presents its many advantages and few disadvantages in comparison to MRI. -

J2EETM Deployment: the Jonas Case Study
J2EETM Deployment: The JOnAS Case Study François Exertier Bull, 1, rue de Provence BP 208 38432 Echirolles Cedex [email protected] RÉSUMÉ. La spécification J2EE (Java 2 platform Enterprise Edition) définit une architecture de serveur d'application Java. Jusqu'à J2EE 1.3, seuls les aspects de déploiement concernant le développeur d'applications étaient adressés. Avec J2EE 1.4, les interfaces et les étapes de déploiement ont été plus précisément spécifiées dans la spécification "J2EE Deployment". JOnAS (Java Open Application Server) est une plate-forme J2EE développée au sein du consortium ObjectWeb. Les aspects déploiement sont en cours de développement. Cet article décrit les concepts liés au déploiement dans J2EE, ainsi que les problématiques levées lors de leur mise en œuvre pour JOnAS. Il n'a pas pour but de présenter un travail abouti, mais illustre le déploiement par un cas concret et ébauche une liste de besoins non encore satisfaits dans le domaine. ABSTRACT. The J2EE (Java 2 platform Enterprise Edition) specification defines an architecture for Java Application Servers. Until J2EE 1.3, the deployment aspect was addressed from the developer point of view only. Since J2EE 1.4, deployment APIs and steps have been more precisely specified within the "J2EE Deployment Specification". JOnAS (Java Open Application Server) is a J2EE platform implementation by ObjectWeb. The deployment aspects are under development. This article describes the J2EE Deployment concepts, and the issues raised when implementing deployment features within JOnAS. It does not provide a complete solution, but illustrates deployment through a concrete example and initiates a list of non fulfilled requirements. -

CKAN) Developer Documentation Release 1.5.2A
Comprehensive Knowledge Archive Network (CKAN) Developer Documentation Release 1.5.2a Open Knowledge Foundation January 07, 2015 Contents 1 Option 1: Package Installation3 1.1 Prepare your System...........................................3 1.2 Run the Package Installer........................................ 24 2 Option 2: Install from Source 29 2.1 Install the Source............................................. 29 3 Post-Installation Setup 35 3.1 Create an Admin User.......................................... 35 3.2 Load Test Data.............................................. 35 3.3 Deployment............................................... 35 4 Customization 37 4.1 Site Name and Description........................................ 37 4.2 Adding CSS, Javascript and other HTML using Config Options.................... 37 4.3 More Advanced Customization..................................... 38 5 Load Datasets 41 5.1 Import Data with the CKAN API.................................... 41 5.2 Import Data with the Harvester Extension................................ 43 6 Common CKAN Tasks 45 6.1 Understanding Paster........................................... 45 6.2 Common Tasks Using Paster....................................... 46 7 Set and Manage Permissions 51 7.1 Overview................................................. 51 7.2 Default Permissions........................................... 53 7.3 Managing Permissions.......................................... 53 7.4 Openness Modes............................................. 54 8 Prepare to Use Extensions -

JATE 2.0: Java Automatic Term Extraction with Apache Solr
JATE 2.0: Java Automatic Term Extraction with Apache Solr Ziqi Zhang, Jie Gao, Fabio Ciravegna Regent Court, 211 Portobello, Sheffield, UK, S1 4DP ziqi.zhang@sheffield.ac.uk, j.gao@sheffield.ac.uk, f.ciravegna@sheffield.ac.uk Abstract Automatic Term Extraction (ATE) or Recognition (ATR) is a fundamental processing step preceding many complex knowledge engineering tasks. However, few methods have been implemented as public tools and in particular, available as open-source freeware. Further, little effort is made to develop an adaptable and scalable framework that enables customization, development, and comparison of algorithms under a uniform environment. This paper introduces JATE 2.0, a complete remake of the free Java Automatic Term Extraction Toolkit (Zhang et al., 2008) delivering new features including: (1) highly modular, adaptable and scalable ATE thanks to integration with Apache Solr, the open source free-text indexing and search platform; (2) an extended collection of state-of-the-art algorithms. We carry out experiments on two well-known benchmarking datasets and compare the algorithms along the dimensions of effectiveness (precision) and efficiency (speed and memory consumption). To the best of our knowledge, this is by far the only free ATE library offering a flexible architecture and the most comprehensive collection of algorithms. Keywords: term extraction, term recognition, NLP, text mining, Solr, search, indexing 1. Introduction by completely re-designing and re-implementing JATE to Automatic Term Extraction (or Recognition) is an impor- fulfill three goals: adaptability, scalability, and extended tant Natural Language Processing (NLP) task that deals collections of algorithms. The new library, named JATE 3 4 with the extraction of terminologies from domain-specific 2.0 , is built on the Apache Solr free-text indexing and textual corpora.