Learning the Musical Instrument Amplifier Model with Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Magpick: an Augmented Guitar Pick for Nuanced Control
Magpick: an Augmented Guitar Pick for Nuanced Control Fabio Morreale Andrea Guidi Andrew McPherson Creative Arts and Industries Centre For Digital Music Centre For Digital Music University of Auckland, Queen Mary University of Queen Mary University of New Zealand London, UK London, UK [email protected] [email protected] [email protected] ABSTRACT This paper introduces the Magpick, an augmented pick for electric guitar that uses electromagnetic induction to sense the motion of the pick with respect to the permanent mag- nets in the guitar pickup. The Magpick provides the gui- tarist with nuanced control of the sound that coexists with traditional plucking-hand technique. The paper presents three ways that the signal from the pick can modulate the guitar sound, followed by a case study of its use in which 11 guitarists tested the Magpick for five days and composed a piece with it. Reflecting on their comments and experi- Figure 1: The Magpick is composed of two parts: a ences, we outline the innovative features of this technology hollow body (black) and a cap (brass). from the point of view of performance practice. In partic- ular, compared to other augmentations, the high tempo- ral resolution, low latency, and large dynamic range of the The challenge is to find ways to sense the movement of Magpick support a highly nuanced control over the sound. the pick with respect to the guitar with high resolution, Our discussion highlights the utility of having the locus of high dynamic range, and low latency, then use the resulting augmentation coincide with the locus of interaction. -

Guitar Resonator GR-Junior II
Guitar Resonator GR-Junior II User Manual Copyright © by Vibesware, all rights reserved. www.vibesware.com Rev. 1.0 Contents 1 Introduction ...............................................................................................1 1.1 How does it work ? ...............................................................................1 1.2 Differences to the EBow and well known Sustainers ............................2 2 Fields of application .................................................................................3 2.1 Feedback playing everywhere / composing / recording ........................3 2.2 On stage ...............................................................................................3 2.3 New ways of playing .............................................................................4 3 Start-Up of the GR-Junior .........................................................................5 4 Playing techniques ...................................................................................5 4.1 Basics ...................................................................................................5 4.2 Harmonics control by positioning the Resonator ...................................6 4.3 Changing harmonics by phase shifting .................................................6 4.4 Some string vibration basics .................................................................6 4.5 Feedback of multiple strings .................................................................9 4.6 Limits of playing, pickup selection, -

Take Your Guitar Further
The VGA-3 V-Guitar Amplifier puts Roland’s most sought-after guitar and amp models in a compact digital amp at a very friendly price. This 50-watt brute uses COSM modeling to deliver a stunning range of electric and acoustic guitar models—plus unique GK effects—from any GK pickup-equipped guitar. There are also 11 programmable COSM amp models, 3-band EQ, and three independent effects processors that can be accessed using any standard electric guitar. TaTaTa k k k e e e Yo Yo Yoururur Guitar Guitar Guitar Further Further Further ● Rated Power Output 50 W ● Patches 10 (Recalled from Panel), 40 (Recalled from MIDI Foot Controller) ● Nominal Input Level (1 kHz) INPUT: -10 dBu, EXT IN: -10 dBu ● Speaker 30 cm (12 inches) x 1 ● Connectors Front: GK In, Input, Recording Out/Phones, Rear: EXT In, EXP Pedal, Foot SW, MIDI In ● Power Supply AC 117/230/240 V ● Power Consumption 55 W ● Dimensions 586 (W) x 260 (D) x 480 (H) mm / 23-1/8 (W) x 10-1/4 (D) x 18-15/16 (H) inches ● Weight 18.5 kg / 40 lbs. 13 oz. ● Accessory Owner's Manual * 0 dBu=0.775 Vrms ■ Roland’s Flagship Modeling Amplifier. The VGA-7 V-Guitar Amplifier is the most powerful and complete modeling amplifier in history. This technological marvel serves up a range of COSM amp sounds, onboard effects, and speaker cabinet simulations—plus models of different electric and acoustic guitars, pickups, and tunings using any steel-string guitar and an optional GK-2A Divided Pickup. -

Electric Guitar Amplifier with Digital Effects
Electric Guitar Amplifier With Digital Effects By Shawn Garrett Senior Project February, 2011 Computer Engineering Department California Polytechnic State University, San Luis Obispo © 2011 Shawn Garrett Garrett 1 Table of Contents Table of Figures .......................................................................................................................... 3 Acknowledgement ...................................................................................................................... 4 Abstract ....................................................................................................................................... 5 I. Introduction ............................................................................................................................ 6 II. Background ........................................................................................................................... 7 III. Requirements ....................................................................................................................... 9 IV. Design Approach Alternatives ............................................................................................ 13 V. Project Design ..................................................................................................................... 14 VI. Physical Construction and Integration ................................................................................ 21 VII. Integrated System Tests and Results ............................................................................... -

Lead Series Guitar Amps
G10, G20, G35FX, G100FX, G120 DSP, G120H DSP, G412A USER’S MANUAL G120H DSP G412A G100FX G120 DSP G10 G20 G35FX LEAD SERIES GUITAR AMPS www.acousticamplification.com IMPORTANT SAFETY INSTRUCTIONS Exposure to high noise levels may cause permanent hearing loss. Individuals vary considerably to noise-induced hearing loss but nearly everyone will lose some hearing if exposed to sufficiently intense noise over time. The U.S. Government’s Occupational Safety and Health Administration (OSHA) has specified the following permissible noise level exposures: DURATION PER DAY (HOURS) 8 6 4 3 2 1 According to OSHA, any exposure in the above permissible limits could result in some hearing loss. Hearing protection SOUND LEVEL (dB) 90 93 95 97 100 103 must be worn when operating this amplification system in order to prevent permanent hearing loss. This symbol is intended to alert the user to the presence of non-insulated “dangerous voltage” within the products enclosure. This symbol is intended to alert the user to the presence of important operating and maintenance (servicing) instructions in the literature accompanying the unit. Apparatus shall not be exposed to dripping or splashing. Objects filled with liquids, such as vases, shall not be placed on the apparatus. • The apparatus shall not be exposed to dripping or splashing. Objects filled with liquids, such as vases, shall not be placed on the apparatus. L’appareil ne doit pas etreˆ exposé aux écoulements ou aux éclaboussures et aucun objet ne contenant de liquide, tel qu’un vase, ne doit etreˆ placé sur l’objet. • The main plug is used as disconnect device. -

Applications to Guitar Feedback Control
Proceedings of the 2010 Conference on New Interfaces for Musical Expression (NIME 2010), Sydney, Australia Mechanisms for Controlling Complex Sound Sources: Applications to Guitar Feedback Control Aengus Martin Sam Ferguson and Kirsty Beilharz Computing and Audio Research Laboratory Faculty of Arts and Social Sciences School of Electrical and Information Engineering Faculty of Design, Architecture and Building The University of Sydney The University of Technology, Sydney [email protected] [email protected] ABSTRACT Guitar/Amplifier Feedback Loop Many musical instruments have interfaces which emphasise the pitch of the sound produced over other perceptual char- acteristics, such as its timbre. This is at odds with the mu- Metal sical developments of the last century. In this paper, we Slide introduce a method for replacing the interface of musical String Dampers instruments (both conventional and unconventional) with a more flexible interface which can present the intrument's available sounds according to variety of different perceptual characteristics, such as their brightness or roughness. We Audio Feature Mechanical Controller apply this method to an instrument of our own design which Auditing Controller Extraction (Pitch Mechanism comprises an electro-mechanically controlled electric guitar Level etc.) and amplifier configured to produce feedback tones. Keywords Audio Features & Control Concatenative Synthesis, Feedback, Guitar User Interface Associated Control Parameter & Parameters Audio Feature 1. INTRODUCTION Database Concatenative sound synthesis (CSS) is a technique for synthesizing sound by assembling a sequence of short seg- ments of digital audio and concatenating them together Figure 1: A block diagram of the system. (see, e.g. [1] and [2]). There are two parts to a CSS sys- tem. -

RADIAL JDI.Pdf
Mk3 JDI and DUPLEX User Guide Radial Engineering 1638 Kebet Way, Port Coquitlam BC V3C 5W9 tel: 604-942-1001 • fax: 604-942-1010 email: [email protected] • web: www.radialeng.com Radial Engineering is a division of C•TEC (JP CableTek Electronics Ltd.) www.radialeng.com RADIAL JDI & DUPLEX USER GUIDE TABLE OF CONTENTS PAGE 1. Introduction .................................................................................1 2. JDI feature set ............................................................................2 3. JDI quick start ...........................................................................3 4. Direct box basics .........................................................................4 5. Features and functions ...............................................................7 6. Other cool uses for your JDI .................................................... 11 7. Frequently asked questions ......................................................12 8. Block diagram and specifications ..............................................15 Warranty ......................................................................Back cover Radial Engineering 1638 Kebet Way, Port Coquitlam BC V3C 5W9 tel: 604-942-1001 • fax: 604-942-1010 email: [email protected] • web: www.radialeng.com Radial Engineering Ltd. is a division of C•TEC (JP CableTek Electronics Ltd.) Features and specifications are subject to change without notice. True to the Music Part 1 - Introduction Congratulations on your purchase of the world’s finest direct box! The Radial -

Guitar Harmonics - Wikipedia, the Free Encyclopedia Guitar Harmonics from Wikipedia, the Free Encyclopedia
3/14/2016 Guitar harmonics - Wikipedia, the free encyclopedia Guitar harmonics From Wikipedia, the free encyclopedia A guitar harmonic is a musical note played by preventing or amplifying vibration of certain overtones of a guitar string. Music using harmonics can contain very high pitch notes difficult or impossible to reach by fretting. Guitar harmonics also produce a different sound quality than fretted notes, and are one of many techniques used to create musical variety. Contents Basic and harmonic oscillations of a 1 Technique string 2 Overtones 3 Nodes 4 Intervals 5 Advanced techniques 5.1 Pinch harmonics 5.2 Tapped harmonics 5.3 String harmonics driven by a magnetic field 6 See also 7 References Technique Harmonics are primarily generated manually, using a variety of techniques such as the pinch harmonic. Another method utilizes sound wave feedback from a guitar amplifier at high volume, which allows for indefinite vibration of certain string harmonics. Magnetic string drivers, such as the EBow, also use string harmonics to create sounds that are generally not playable via traditional picking or fretting techniques. Harmonics are most often played by lightly placing a finger on a string at a nodal point of one of the overtones at the moment when the string is driven. The finger immediately damps all overtones that do not have a node near the location touched. The lowest-pitch overtone dominates the resulting sound. https://en.wikipedia.org/wiki/Guitar_harmonics 1/6 3/14/2016 Guitar harmonics - Wikipedia, the free encyclopedia Overtones When a guitar string is plucked normally, the ear tends to hear the fundamental frequency most prominently, but the overall sound is also 0:00 MENU colored by the presence of various overtones (integer multiples of the Tuning a guitar using overtones fundamental frequency). -

THE LEGENDARY PEAVEY SESSION STEEL GUITAR AMPLIFIER by Mike Brown
Peavey Electronics Corporation THE LEGENDARY PEAVEY SESSION STEEL GUITAR AMPLIFIER By Mike Brown In the late 1960's Nashville steel guitarist/road musician Julian Tharpe traveled through Mississippi to visit with Hartley Peavey in hopes of persuading him to design a guitar amplifier that could handle the vast range of frequencies that his 20 string/11 pedal steel guitar was capable of producing. This was a challenge that Hartley did not take lightly, and he immediately began working on this new amplifier design. After several trips back to Meridian with the failed prototypes, Hartley would go "back to the drawing board" to revise / modify the design once more. After several trips, Julian returned to Hartley with the news that the latest version survived his last road trip. Although the amplifier survived, unfortunately the JBL speaker could not handle the power and grueling wide-range of frequencies. As HP would say, "With the push of a foot Pictured: Julian Tharpe pedal, a player could lay the strings on the fret board like a wet noodle!" And for that reason, the Black Widow speaker was born. This new challenge led to the innovative design of the Peavey Black Widow speaker which featured field replaceable speaker baskets that can be swapped out "on the job" in a matter of minutes. With the BW's ability to faithfully reproduce the wide frequency ranges of a multi-string steel guitar, the Black Widow quickly became the steel guitar 'standard' of the industry. The rest is history. The legendary Black Widow 1501 speaker has been used in every Peavey steel guitar amplifier since its inception in the late 1970's. -

Digital Guitar Amplifier and Effects Unit Shaun Caraway, Matt Evens, and Jan Nevarez Group 5, Senior Design Spring 2014
Digital Guitar Amplifier and Effects Unit Shaun Caraway, Matt Evens, and Jan Nevarez Group 5, Senior Design Spring 2014 Table of Contents 1. Executive Summary ....................................................................................... 1 2. Project Description ......................................................................................... 2 2.1. Project Motivation and Goals ................................................................... 2 2.2. Objectives ................................................................................................ 3 2.3. Project Requirements and Specifications ................................................ 3 3. Research ........................................................................................................ 4 3.1. Digital Signal Processing ......................................................................... 4 3.1.1. Requirements ................................................................................... 4 3.1.1.1. Sampling Rate ............................................................................... 4 3.1.1.2. Audio Word Size ............................................................................ 5 3.1.2. Processor Comparison ..................................................................... 5 3.1.3. Features ............................................................................................ 6 3.1.3.1. Programming Method .................................................................... 6 3.1.3.2. Real-Time OS ............................................................................... -

Radial X-AMP Reamp Studio Reamper User Guide
Skip to content Manuals+ User Manuals Simplified. Radial X-AMP Reamp Studio Reamper User Guide Home » Radial » Radial X-AMP Reamp Studio Reamper User Guide Contents [ hide 1 Radial X-AMP Reamp Studio Reamper 2 OVERVIEW 2.1 FEATURE SET: INPUT PANEL 3 SPECIFICATIONS 4 THREE YEAR TRANSFERABLE LIMITED WARRANTY 5 File Downloads 6 References 7 Related Manuals Radial X-AMP Reamp Studio Reamper INTRODUCTION The Radial X-Amp is an active Reamper that has been developed with one goal in mind: To explore new musical sounds and spur on the creative process. Like all Radial products, this ‘creative tool’ is made using the very finest components and care to ensure the very highest quality sound possible. And like any tool, the best way to get the most out of it is by understanding the functions, the intent behind the design and of course some of the safety features and instructions that have been provided. To this end, we recommend reading this manual before operating your X-Amp. We are confident you will find the Radial X-Amp to be fun to use, musical and that it will open new doors to creativity. If you have question after you have read the user guide please visit the X-Amp FAQ page on our web site. If you still can not find what you are looking for, feel free to send us an email at [email protected] and we will do our very best to reply to you in short order. We love to hear from you! Caution: Please read the caution statement on the last page before connecting your Radial X-Amp. -
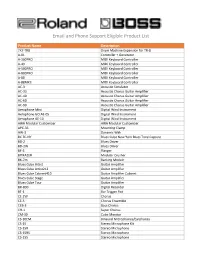
Email and Phone Support Eligible Product List
Email and Phone Support Eligible Product List Product Name Description 7X7-TR8 Drum Machine Expansion for TR-8 A-01 Controller + Generator A-300PRO MIDI Keyboard Controller A-49 MIDI Keyboard Controller A-500PRO MIDI Keyboard Controller A-800PRO MIDI Keyboard Controller A-88 MIDI Keyboard Controller A-88MKII MIDI Keyboard Controller AC-3 Acoustic Simulator AC-33 Acoustic Chorus Guitar Amplifier AC-40 Acoustic Chorus Guitar Amplifier AC-60 Acoustic Chorus Guitar Amplifier AC-90 Acoustic Chorus Guitar Amplifier Aerophone Mini Digital Wind Instrument Aerophone GO AE-05 Digital Wind Instrument Aerophone AE-10 Digital Wind Instrument AIRA Modular Customizer AIRA Modular Customizer APC-33 Mounting Clamp AW-3 Dynamic Wah BC TC-NY Blues Cube New York Blues Tone Capsule BD-2 Blues Driver BD-2W Blues Driver BF-3 Flanger BITRAZER Modular Crusher BK-7m Backing Module Blues Cube Artist Guitar Amplifier Blues Cube Artist212 Guitar Amplifier Blues Cube Cabinet410 Guitar Amplifier Cabinet Blues Cube Stage Guitar Amplifier Blues Cube Tour Guitar Amplifier BR-800 Digital Recorder BT-1 Bar Trigger Pad CE-2W Chorus CE-5 Chorus Ensemble CEB-3 Bass Chorus CH-1 Super Chorus CM-30 Cube Monitor CS-10EM Binaural Microphones/Earphones CS-15 Stereo Microphone Kit CS-15R Stereo Microphone CS-15RS Stereo Microphone CS-15S Stereo Microphone CS-3 Compression Sustainer CUBE JAM iOS App CUBE KIT iOS/Android App CUBE Lite Guitar Amplifier CUBE Lite Monitor Monitor Amplifier CUBE Street Battery Powered Stereo Amplifier CUBE Street EX Battery-Powered Stereo Amplifier CUBE-10GX Guitar Amplifier CUBE-120XL BASS Bass Amplifier CUBE-20XL BASS Bass Amplifier CUBE-60XL BASS Bass Amplifier CV-20KX Custom Finish Package for TD-30KV and TD-20SX CY-12C V-Cymbal Crash CY-18DR V-Cymbal Ride CY-13R V-Cymbal Ride CY-14C-MG V-Cymbal Crash CY-15R-MG V-Cymbal Ride CY-5 Dual-Trigger Cymbal Pad CY-8 Dual-Trigger Cymbal Pad D-05 Linear Synthesizer DB-30 Dr.