Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Pages 1–13, Baltimore, Maryland, USA, June 27, 2014
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
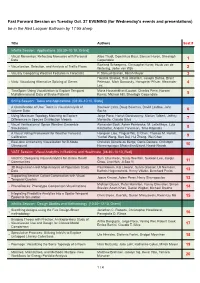
Tuesday's Evening Fast Forward Session
Fast Forward Session on Tuesday Oct. 27 EVENING (for Wednesday's events and presentations) be in the Red Lacquer Ballroom by 17:55 sharp Title Authors Seat # InfoVis Session: Applications [08:30–10:10, Grand] Visual Mementos: Reflecting Memories with Personal Alice Thudt, Dominikus Baur, Samuel Huron, Sheelagh - Data Carpendale 1 Roeland Scheepens, Christophe Hurter, Huub van de - Visualization, Selection, and Analysis of Traffic Flows Wetering, Jarke van Wijk 2 - Visually Comparing Weather Features in Forecasts P. Samuel Quinan, Miriah Meyer 3 Hendrik Strobelt, Bilal Alsallakh, Joseph Botros, Brant - Vials: Visualizing Alternative Splicing of Genes Peterson, Mark Borowsky, Hanspeter Pfister, Alexander 4 Lex TimeSpan: Using Visualization to Explore Temporal Mona Hosseinkhani Loorak, Charles Perin, Noreen - Multidimensional Data of Stroke Patients Kamal, Michael Hill, Sheelagh Carpendale 5 SciVis Session: Tasks and Applications [08:30–10:10, State] A Classification of User Tasks in Visual Analysis of Bireswar Laha, Doug Bowman, David Laidlaw, John - Volume Data Socha 6 Using Maximum Topology Matching to Explore Jorge Poco, Harish Doraiswamy, Marian Talbert, Jeffrey - Differences in Species Distribution Models Morisette, Claudio Silva 7 Visual Verification of Space Weather Ensemble Alexander Bock, Asher Pembroke, M. Leila Mays, Lutz - Simulations Rastaetter, Anders Ynnerman, Timo Ropinski 8 A Visual Voting Framework for Weather Forecast Hongsen Liao, Yingcai Wu, Li Chen, Thomas M. Hamill, - Calibration Yunhai Wang, Kan Dai, Hui Zhang, Wei -

Comparing Bar Chart Authoring with Microsoft Excel and Tangible Tiles Tiffany Wun, Jennifer Payne, Samuel Huron, Sheelagh Carpendale
Comparing Bar Chart Authoring with Microsoft Excel and Tangible Tiles Tiffany Wun, Jennifer Payne, Samuel Huron, Sheelagh Carpendale To cite this version: Tiffany Wun, Jennifer Payne, Samuel Huron, Sheelagh Carpendale. Comparing Bar Chart Authoring with Microsoft Excel and Tangible Tiles. Computer Graphics Forum, Wiley, 2016, Computer Graphics Forum, 35 (3), pp.111 - 120. 10.1111/cgf.12887. hal-01400906 HAL Id: hal-01400906 https://hal-imt.archives-ouvertes.fr/hal-01400906 Submitted on 10 Oct 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Eurographics Conference on Visualization (EuroVis) 2016 Volume 35 (2016), Number 3 K.-L. Ma, G. Santucci, and J. van Wijk (Guest Editors) Comparing Bar Chart Authoring with Microsoft Excel and Tangible Tiles Tiffany Wun1, Jennifer Payne1, Samuel Huron1;2, and Sheelagh Carpendale1 1University of Calgary, Canada 2I3-SES, CNRS, Télécom ParisTech, Université Paris-Saclay, 75013, Paris, France Abstract Providing tools that make visualization authoring accessible to visualization non-experts is a major research challenge. Cur- rently the most common approach to generating a visualization is to use software that quickly and automatically produces visualizations based on templates. However, it has recently been suggested that constructing a visualization with tangible tiles may be a more accessible method, especially for people without visualization expertise. -

Lecture 14: Evaluation the Perceptual Scalability of Visualization
Readings Covered Further Readings Evaluation, Carpendale Evaluating Information Visualizations. Sheelagh Carpendale. Chapter in Task-Centered User Interface Design, Clayton Lewis and John Rieman, thorough survey/discussion, won’t summarize here Information Visualization: Human-Centered Issues and Perspectives, Chapters 0-5. Springer LNCS 4950, 2008, p 19-45. The challenge of information visualization evaluation. Catherine Plaisant. Lecture 14: Evaluation The Perceptual Scalability of Visualization. Beth Yost and Chris North. Proc. Advanced Visual Interfaces (AVI) 2004 Proc. InfoVis 06, published as IEEE TVCG 12(5), Sep 2006, p 837-844. Information Visualization Effectiveness of Animation in Trend Visualization. George G. Robertson, CPSC 533C, Fall 2011 Turning Pictures into Numbers: Extracting and Generating Information Roland Fernandez, Danyel Fisher, Bongshin Lee, and John T. Stasko. from Complex Visualizations. J. Gregory Trafton, Susan S. IEEE TVCG (Proc. InfoVis 2008). 14(6): 1325-1332 (2008) Kirschenbaum, Ted L. Tsui, Robert T. Miyamoto, James A. Ballas, and Artery Visualizations for Heart Disease Diagnosis. Michelle A. Borkin, Tamara Munzner Paula D. Raymond. Intl Journ. Human Computer Studies 53(5), Krzysztof Z. Gajos, Amanda Peters, Dimitrios Mitsouras, Simone 827-850. Melchionna, Frank J. Rybicki, Charles L. Feldman, and Hanspeter Pfister. UBC Computer Science IEEE TVCG (Proc. InfoVis 2011), 17(12):2479-2488. Wed, 2 November 2011 1 / 46 2 / 46 3 / 46 4 / 46 Psychophysics Cognitive Psychology Structural Analysis Comparative User -

Scientific Visualization
Report from Dagstuhl Seminar 11231 Scientific Visualization Edited by Min Chen1, Hans Hagen2, Charles D. Hansen3, and Arie Kaufman4 1 University of Oxford, GB, [email protected] 2 TU Kaiserslautern, DE, [email protected] 3 University of Utah, US, [email protected] 4 SUNY – Stony Brook, US, [email protected] Abstract This report documents the program and the outcomes of Dagstuhl Seminar 11231 “Scientific Visualization”. Seminar 05.–10. June, 2011 – www.dagstuhl.de/11231 1998 ACM Subject Classification I.3 Computer Graphics, I.4 Image Processing and Computer Vision, J.2 Physical Sciences and Engineering, J.3 Life and Medical Sciences Keywords and phrases Scientific Visualization, Biomedical Visualization, Integrated Multifield Visualization, Uncertainty Visualization, Scalable Visualization Digital Object Identifier 10.4230/DagRep.1.6.1 1 Executive Summary Min Chen Hans Hagen Charles D. Hansen Arie Kaufman License Creative Commons BY-NC-ND 3.0 Unported license © Min Chen, Hans Hagen, Charles D. Hansen, and Arie Kaufman Scientific Visualization (SV) is the transformation of abstract data, derived from observation or simulation, into readily comprehensible images, and has proven to play an indispensable part of the scientific discovery process in many fields of contemporary science. This seminar focused on the general field where applications influence basic research questions on one hand while basic research drives applications on the other. Reflecting the heterogeneous structure of Scientific Visualization and the currently unsolved problems in the field, this seminar dealt with key research problems and their solutions in the following subfields of scientific visualization: Biomedical Visualization: Biomedical visualization and imaging refers to the mechan- isms and techniques utilized to create and display images of the human body, organs or their components for clinical or research purposes. -

Constructing Visual Representations: Investigating the Use of Tangible Tokens Samuel Huron, Yvonne Jansen, Sheelagh Carpendale
Constructing Visual Representations: Investigating the Use of Tangible Tokens Samuel Huron, Yvonne Jansen, Sheelagh Carpendale To cite this version: Samuel Huron, Yvonne Jansen, Sheelagh Carpendale. Constructing Visual Representations: Investigating the Use of Tangible Tokens. IEEE Transactions on Visualization and Computer Graphics, Institute of Electrical and Electronics Engineers (IEEE), 2014, Transactions on Vi- sualization and Computer Graphics, 20 (12), pp.1. <10.1109/TVCG.2014.2346292>. <hal- 01024053> HAL Id: hal-01024053 https://hal.inria.fr/hal-01024053 Submitted on 1 Aug 2014 HAL is a multi-disciplinary open access L'archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destin´eeau d´ep^otet `ala diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publi´esou non, lished or not. The documents may come from ´emanant des ´etablissements d'enseignement et de teaching and research institutions in France or recherche fran¸caisou ´etrangers,des laboratoires abroad, or from public or private research centers. publics ou priv´es. Constructing Visual Representations: Investigating the Use of Tangible Tokens Samuel Huron, Yvonne Jansen, Sheelagh Carpendale Fig. 1. Constructing a visualization with tokens: right hand positions tokens, left hand points to the corresponding data. Abstract—The accessibility of infovis authoring tools to a wide audience has been identified as a major research challenge. A key task in the authoring process is the development of visual mappings. While the infovis community has long been deeply interested in finding effective visual mappings, comparatively little attention has been placed on how people construct visual mappings. In this paper, we present the results of a study designed to shed light on how people transform data into visual representations. -

Sheelagh Carpendale
CURRICULUM VITAE Sheelagh Carpendale Full Professor NSERC/SMART Industrial Research Chair: Interactive Technologies Director: Innovations in Visualization (InnoVis) Co-Director: Interactive Experiences Lab (ixLab) Office: TASC1 9233 Lab: ixLab TASC1 9200 School of Computing Science Simon Fraser University 8888 University Drive Burnaby, British Columbia Canada V5A 1S6 Phone: +1 778 782 5415 Email: [email protected] Web: https:// www.cs.sfu.ca/~sheelagh/ TABLE OF CONTENTS 2 Executive Summary 5 Education 6 Awards 11 Research Overview 13 Employment and Appointments 16 Teaching and Supervision 25 Technology Transfer 27 Grants 31 Service 36 Presentations 44 Publications Sheelagh Carpendale Executive Summary Brief Biography (in 3rd person) Sheelagh Carpendale is a Professor at Simon Fraser University (SFU). She directs the InnoVis (Innovations in Visualization) research group and the newly formed ixLab (Interactive Experiences Lab). Her NSERC/SMART Industrial Research Chair in Interactive Technologies is still current. She has been awarded the IEEE VGTC Visualization Career Award (https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8570932 ) and is inducted into both the IEEE Visualization Academy (highest and most prestigious honor in the field of visualization) and the ACM CHI Academy, which is an honorary group of individuals who are the principal leaders of the field having led the research and/or innovation in human-computer interaction (https://sigchi.org/awards/sigchi-award-recipients/2018-sigchi-awards/) Formerly, she was at University -

Data Visualization by Nils Gehlenborg
Data Visualization Nils Gehlenborg ([email protected]) Center for Biomedical Informatics / Harvard Medical School Cancer Program / Broad Institute of MIT and Harvard ISMB/ECCB 2011 http://www.biovis.net Flyers at ISCB booth! Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg A good sketch is better than a long speech. Napoleon Bonaparte Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg Minard 1869 Napoleon’s March on Moscow Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 4 I believe when I see it. Unknown Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg Anscombe 1973, The American Statistician Anscombe’s Quartet mean(X) = 9, var(X) = 11, mean(Y) = 7.5, var(Y) = 4.12, cor(X,Y) = 0.816, linear regression line Y = 3 + 0.5*X Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 6 Anscombe 1973, The American Statistician Anscombe’s Quartet Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 7 Exploration: Hypothesis Generation trends gaps outliers clusters - A large data set is given and the goal is to learn something about it. - Visualization is employed to perform pattern detection using the human visual system. - The goal is to generate hypotheses that can be tested with statistical methods or follow-up experiments. Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 8 Visualization Use Cases Presentation Confirmation Exploration Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 9 Definition The use of computer-supported, interactive, visual representations of data to amplify cognition. Stu Card, Jock Mackinlay & Ben Shneiderman Computer-based visualization systems provide visual representations of datasets intended to help people carry out some task more effectively.effectively. -

Vislink: Revealing Relationships Amongst Visualizations
University of Calgary PRISM: University of Calgary's Digital Repository Science Science Research & Publications 2007-05-17 VisLink: Revealing Relationships Amongst Visualizations Collins, Christopher; Carpendale, Sheelagh http://hdl.handle.net/1880/45783 unknown Downloaded from PRISM: https://prism.ucalgary.ca VisLink: Revealing Relationships Amongst Visualizations Christopher Collins1, Sheelagh Carpendale2 1Department of Computer Science, University of Toronto 2Department of Computer Science, University of Calgary Abstract We present VisLink, a method by which visualizations and the relationships be- tween them can be interactively explored. VisLink readily generalizes to support mul- tiple visualizations, empowers inter-representational queries, and enables the reuse of the spatial variables, thus supporting efficient information encoding and providing for powerful visualization bridging. Our approach uses multiple 2D layouts, drawing each one in its own plane. These planes can then be placed and re-positioned at will, side by side, in parallel, or in chosen placements that provide favoured views. Relationships, connections and patterns between visualizations can be revealed. 1 Introduction As information visualizations continue to play a more frequent role in information analysis, the complexity of the queries for which we would like, or even expect, visual explanations also continues to grow. For example, while creating visualizations of multi-variate data re- mains a familiar challenge, the visual portrayal of two set of relationships, one primary and one secondary, within a given visualization is relatively new (e. g. [6, 14, 8]). With VisLink, we extend this latter direction, making it possible reveal relationships between one or more primary visualizations. This enables new types of questions. For example, consider a lin- guistic question such as whether the formal hierarchical structure as expressed through the IS-A relationships in WordNet [13] is reflected by actual semantic similarity from usage statistics. -

Pop-Out, Illusions, Interaction
Pop-Out, Illusions, Interaction DS 4200 FALL 2020 Prof. Cody Dunne NORTHEASTERN UNIVERSITY Slides and inspiration from Michelle Borkin, Krzysztof Gajos, Hanspeter Pfister, Miriah Meyer, Jonathan Schwabish, and David Sprague 1 CHECK-IN 2 PREVIOUSLY, ON DS 4200… 4 Color Vocabulary and Perceptual Ordering Darkness (Lightness) Saturation Hue ? ? Based on Slides by Miriah Meyer, Tamara Munzner 5 Color Deficiencies (Color Blindness) Based on Slides by Hanspeter Pfister, Maureen Stone 6 Check your images/colormaps for issues! http://www.vischeck.com/vischeck/vischeckImage.php https://www.color-blindness.com/coblis-color-blindness-simulator/ 7 Color Brewer http://colorbrewer2.org 8 Color Advice Summary Use a limited hue palette • Control color “pop out” with low-saturation colors • Avoid clutter from too many competing colors Use neutral backgrounds • Control impact of color • Minimize simultaneous contrast Use Color Brewer etc. for picking scales Don’t forget aesthetics! Based on Slides by Hanspeter Pfister, Maureen Stone 9 NOW, ON DS 4200… 10 POP-OUT EFFECTS 15 POP-OUT EFFECTS COLOR Healey, 2012 16 POP-OUT EFFECTS SHAPE Healey, 2012 17 POP-OUT EFFECTS “CONJUNCTION” (HARDER TO FIND RED CIRCLE!) Healey, 2012 18 POP-OUT EFFECTS MOTION Healey, 2012 19 POP-OUT EFFECTS Healey, 2012 20 POP-OUT EFFECTS Healey, 2012 21 Use these “popout” effects to help design effective visualizations! (E.g., draw viewer’s attention to main points, effective redundant encodings, etc.) Ware, VTFD 22 Discriminability and Separability The question of discriminability is: if you encode data using a particular visual channel, are the differences between items perceptible to the human as intended? Munzner, VAD 23 Textures easy hard Ware, VTFD 25 Textures: Interference Ware, VTFD 26 ILLUSIONS AND TRICKS 28 Visual Attention & Change Blindness 30 Visual Attention & Change Blindness Task: Identify the lumps/nodules in the patient’s lungs to look for cancer or abnormal growth. -

Eurovis 2019 Eurographics / IEEE VGTC Conference on Visualization 2019
EuroVis 2019 Eurographics / IEEE VGTC Conference on Visualization 2019 Porto, Portugal June 3 – 7, 2019 Organized by EUROGRAPHICS THE EUROPEAN ASSOCIATION FOR COMPUTER GRAPHICS IEEE Visualization and Graphics Technical Committee General Chairs Alfredo Ferreira – INESC-ID, Instituto Superior Técnico, Universidade de Lisboa Joaquim A. Jorge – INESC-ID, Instituto Superior Técnico, Universidade de Lisboa Full Papers Chairs Michael Gleicher – University of Wisconsin Ivan Viola – KAUST Heike Leitte – TU Kaiserslautern STARs Chairs Robert S. Laramee – Swansea University Steffen Oeltze – Dept. of Neurology, University of Magdeburg Michael Sedlmair – Jacobs University Short Papers Chairs Jimmy Johansson – Linköping University Filip Sadlo – Heidelberg University G. Elisabeta Marai – University of Illinois at Chicago Posters Chairs João Madeiras Pereira – Universidade de Lisboa Renata Raidou – TU Wien DOI: 10.1111/cgf.13725 https://www.eg.org https://diglib.eg.org Eurographics Conference on Visualization (EuroVis) 2019 Volume 38 (2019), Number 3 M. Gleicher, H. Leitte, and I. Viola (Guest Editors) Organizers and Sponsors Eurographics Conference on Visualization (EuroVis) 2019 Volume 38 (2019), Number 3 M. Gleicher, H. Leitte, and I. Viola (Guest Editors) Preface EuroVis 2019, the 21th Eurographics / IEEE VGTC Conference on Visualization, was held in Porto, Portugal, on June 3-7, 2019. The proceedings are published as a special issue of the Eurographics Computer Graphics Forum journal. The conference, which started in 1990 as the Eurographics Workshop on Visualization in Scientific Com- puting and was called VisSym after 1999, has been known as EuroVis since 2005. EuroVis attracts contributions that broadly cover the field of visualization. Topics include visualization techniques for spatial data, such as volumet- ric, tensor, and vector field datasets, and for non-spatial data, such as graphs, text, and high-dimensional datasets. -
Proceedings of the Workshop on Data Exploration for Interactive Surfaces DEXIS 2011
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/265632289 Proceedings of the Workshop on Data Exploration for Interactive Surfaces DEXIS 2011 Article · May 2012 CITATIONS READS 0 56 5 authors, including: Sheelagh Carpendale Tobias Hesselmann The University of Calgary OFFIS 360 PUBLICATIONS 7,311 CITATIONS 16 PUBLICATIONS 200 CITATIONS SEE PROFILE SEE PROFILE Some of the authors of this publication are also working on these related projects: Constructive visualization View project Vuzik: Exploring a Medium for Painting Music View project All content following this page was uploaded by Sheelagh Carpendale on 25 March 2016. The user has requested enhancement of the downloaded file. Proceedings of the Workshop on Data Exploration for Interactive Surfaces hal-00659469, version 1 - 24 Apr 2012 hal-00659469, version 1 - 24 DEXIS 2011 Petra Isenberg, Sheelagh Carpendale, Tobias Hesselmann, Tobias Isenberg, Bongshin Lee (editors) RESEARCH REPORT N° 0421 May 2012 Project-Teams AVIZ ISSN 0249-6399 ISRN INRIA/RR--0421--FR+ENG hal-00659469, version 1 - 24 Apr 2012 Proceedings of the Workshop on Data Exploration for Interactive Surfaces DEXIS 2011 Petra Isenberg*, Sheelagh Carpendale†, Tobias Hesselmann‡, Tobias Isenberg§, Bongshin Lee¶ (editors) Research Report n° 0421 — May 2012 — 47 pages Abstract: By design, interactive tabletops and surfaces provide numerous opportunities for data visu- alization and analysis. In information visualization, scientific visualization, and visual analytics, useful insights primarily emerge from interactive data exploration. Nevertheless, interaction research in these domains has largely focused on mouse-based interactions in the past, with little research on how interac- tive data exploration can benefit from interactive surfaces. -

International Computer Music Conference (ICMC/SMC)
Conference Program 40th International Computer Music Conference joint with the 11th Sound and Music Computing conference Music Technology Meets Philosophy: From digital echos to virtual ethos ICMC | SMC |2014 14-20 September 2014, Athens, Greece ICMC|SMC|2014 14-20 September 2014, Athens, Greece Programme of the ICMC | SMC | 2014 Conference 40th International Computer Music Conference joint with the 11th Sound and Music Computing conference Editor: Kostas Moschos PuBlished By: x The National anD KapoDistrian University of Athens Music Department anD Department of Informatics & Telecommunications Panepistimioupolis, Ilissia, GR-15784, Athens, Greece x The Institute for Research on Music & Acoustics http://www.iema.gr/ ADrianou 105, GR-10558, Athens, Greece IEMA ISBN: 978-960-7313-25-6 UOA ISBN: 978-960-466-133-6 Ξ^ĞƉƚĞŵďĞƌϮϬϭϰʹ All copyrights reserved 2 ICMC|SMC|2014 14-20 September 2014, Athens, Greece Contents Contents ..................................................................................................................................................... 3 Sponsors ..................................................................................................................................................... 4 Preface ....................................................................................................................................................... 5 Summer School .......................................................................................................................................