Tackling Parallelization Challenges of Kernel Network Stack for Container Overlay Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Improving Route Scalability: Nexthops As Separate Objects
Improving Route Scalability: Nexthops as Separate Objects September 2019 David Ahern | Cumulus Networks !1 Agenda Executive Summary ▪ If you remember nothing else about this talk … Driving use case Review legacy route API Dive into Nexthop API Benefits of the new API Cumulus Networks !2 Performance with the Legacy Route API route route route prefix/lenroute prefix/lendev prefix/lendev gatewayprefix/len gatewaydev gatewaydev gateway Cumulus Networks !3 Splitting Next Hops from Routes Routes with separate Nexthop objects Legacy Route API route route prefix/len nexthop route nexthop id dev route gateway prefix/lenroute prefix/lendev prefix/lendev gatewayprefix/len gatewaydev gatewaydev gateway route prefix/len nexthop nexthop nexthop id group nexthopdev nexthop[N] gatewaydev gateway Cumulus Networks !4 Dramatically Improves Route Scalability … Cumulus Networks !5 … with the Potential for Constant Insert Times Cumulus Networks !6 Networking Operating System Using Linux APIs Routing daemon or utility manages switchd ip FRR entries in kernel FIBs via rtnetlink APIs SDK userspace ▪ Enables other control plane software to use Linux networking APIs rtnetlink Data path connections, stats, troubleshooting, … FIB notifications FIB Management of hardware offload is separate kernel upper devices tunnels ▪ Keeps hardware in sync with kernel ... eth0 swp1 swp2 swpN Userspace driver with SDK leveraging driver driver driver kernel notifications NIC switch ASIC H / W Cumulus Networks !7 NOS with switchdev Driver In-kernel switchdev driver ip FRR Leverages -

Mesalock Linux: Towards a Memory-Safe Linux Distribution
MesaLock Linux Towards a memory-safe Linux distribution Mingshen Sun MesaLock Linux Maintainer | Baidu X-Lab, USA Shanghai Jiao Tong University, 2018 whoami • Senior Security Research in Baidu X-Lab, Baidu USA • PhD, The Chinese University of Hong Kong • System security, mobile security, IoT security, and car hacking • MesaLock Linux, TaintART, Pass for iOS, etc. • mssun @ GitHub | https://mssun.me !2 MesaLock Linux • Why • What • How !3 Why • Memory corruption occurs in a computer program when the contents of a memory location are unintentionally modified; this is termed violating memory safety. • Memory safety is the state of being protected from various software bugs and security vulnerabilities when dealing with memory access, such as buffer overflows and dangling pointers. !4 Stack Buffer Overflow • https://youtu.be/T03idxny9jE !5 Types of memory errors • Access errors • Buffer overflow • Race condition • Use after free • Uninitialized variables • Memory leak • Double free !6 Memory-safety in user space • CVE-2017-13089 wget: Stack-based buffer overflow in HTTP protocol handling • A stack-based buffer overflow when processing chunked, encoded HTTP responses was found in wget. By tricking an unsuspecting user into connecting to a malicious HTTP server, an attacker could exploit this flaw to potentially execute arbitrary code. • https://bugzilla.redhat.com/show_bug.cgi?id=1505444 • POC: https://github.com/r1b/CVE-2017-13089 !7 What • Linux distribution • Memory-safe user space !8 Linux Distribution • A Linux distribution (often abbreviated as distro) is an operating system made from a software collection, which is based upon the Linux kernel and, often, a package management system. !9 Linux Distros • Server: CentOS, Federa, RedHat, Debian • Desktop: Ubuntu • Mobile: Android • Embedded: OpenWRT, Yocto • Hard-core: Arch Linux, Gentoo • Misc: ChromeOS, Alpine Linux !10 Security and Safety? • Gentoo Hardened: enables several risk-mitigating options in the toolchain, supports PaX, grSecurity, SELinux, TPE and more. -

Adecuándose a La Norma ISO/IEC 1799 Mediante Software Libre
Adecu´andose a la norma ISO/IEC 1799 mediante software libre * Jose Fernando Carvajal Vi´on Grupo de Inter´esen Seguridad de ATI (ATI-GISI) <[email protected]> Javier Fern´andez-Sanguino Pe˜na Grupo de Inter´esen Seguridad de ATI (ATI-GISI) <[email protected]> 28 de octubre de 2002 Resumen Este art´ıculo muestra la forma de adecuar a la norma ISO/IEC 17999 un sistema de informaci´onimplementado en un servidor cuyo software de sistema operativo se basa en alguna alternativa de software Libre y c´odigo abierto. La utilizaci´onde una distribuci´onDebian GNU/Linux sirve como base a la que a˜nadir las utilidades y paquetes necesarios para conseguir el objetivo. ´Indice 1. Introducci´on 1 2. Objetivo y Asunciones 2 3. Cumplimiento de la Norma ISO/IEC 17799 en GNU/Linux 4 4. Conclusiones 4 5. Referencias 5 6. Referencias de herramientas 7 7. Referencias Generales 11 *Copyright (c) 2002 Jose Fernando Carvajal y Javier Fern´andez-Sanguino. Se otorga permiso para copiar, distribuir y/o modificar este documento bajo los t´erminos de la Licencia de Documen- taci´onLibre GNU, Versi´on1.1 o cualquier otra versi´onposterior publicada por la Free Software Foundation. Puede consultar una copia de la licencia en: http://www.gnu.org/copyleft/fdl.html 1 1. Introducci´on De forma general para mantener la seguridad de los activos de informaci´on se deben preservar las caracter´ısticas siguientes [1]. 1. Confidencialidad: s´oloel personal o equipos autorizados pueden acceder a la informaci´on. 2. Integridad: la informaci´on y sus m´etodos de proceso son exactos y completos. -

Linux Networking 101
The Gorilla ® Guide to… Linux Networking 101 Inside this Guide: • Discover how Linux continues its march toward world domination • Learn basic Linux administration tips • See how easy it can be to build your entire network on a Linux foundation • Find out how Cumulus Linux is your ticket to networking freedom David M. Davis ActualTech Media Helping You Navigate The Technology Jungle! In Partnership With www.actualtechmedia.com The Gorilla Guide To… Linux Networking 101 Author David M. Davis, ActualTech Media Editors Hilary Kirchner, Dream Write Creative, LLC Christina Guthrie, Guthrie Writing & Editorial, LLC Madison Emery, Cumulus Networks Layout and Design Scott D. Lowe, ActualTech Media Copyright © 2017 by ActualTech Media. All rights reserved. No portion of this book may be reproduced or used in any manner without the express written permission of the publisher except for the use of brief quotations. The information provided within this eBook is for general informational purposes only. While we try to keep the information up- to-date and correct, there are no representations or warranties, express or implied, about the completeness, accuracy, reliability, suitability or availability with respect to the information, products, services, or related graphics contained in this book for any purpose. Any use of this information is at your own risk. ActualTech Media Okatie Village Ste 103-157 Bluffton, SC 29909 www.actualtechmedia.com Entering the Jungle Introduction: Six Reasons You Need to Learn Linux ....................................................... 7 1. Linux is the future ........................................................................ 9 2. Linux is on everything .................................................................. 9 3. Linux is adaptable ....................................................................... 10 4. Linux has a strong community and ecosystem ........................... 10 5. -

Practical Practical
PRACTICAL PRACTICAL GPLCOMPLIANCE GPLCOMPLIANCE A GUIDE FOR STARTUPS, SMALL ABUSINESSES GUIDE FOR STARTUPS, AND ENGINEERS SMALL BUSINESSES AND ENGINEERS ARMIJN HEMEL, MSC AND SHANE COUGHLAN ARMIJN HEMEL, MSC AND SHANE COUGHLAN Copyright © 2017 Linux Foundation All rights reserved. This book or any portion thereof may not be reproduced or used in any manner whatsoever without the express written permission of the publisher except for the use of brief quotations in a book review and certain other noncommercial uses permitted by copyright law. Printed in the United States of America First Edition, 2017 ISBN: 978-0-9989078-0-2 1 Letterman Drive Building D Suite D4700 San Francisco CA 94129 Phone/Fax: +1 415 723 9709 https://linuxfoundation.org About the Authors Shane Coughlan Shane Coughlan is an expert in communi- cation, security, and business development. His professional accomplishments include spearheading the licensing team that elevated Open Invention Network into the largest patent non-aggression community in history, establishing the leading professional network of open source legal experts, and aligning stakeholders to launch both the first law journal and the first law book dedicated to open source. He currently leads the OpenChain community as Program Manager. Shane has extensive knowledge of open source governance, internal process development, supply chain management, and community building. His experience includes engagement with the enterprise, embedded, mobile, and automotive industries. Armijn Hemel Armijn Hemel is the owner of Tjaldur Software Governance Solutions. He is an active re- searcher of and internationally recognized expert in open source license compliance and supply chain management. He studied computer science at Utrecht University in The Netherlands, where he pioneered reproducible builds with NixOS. -

Open Source Used in CVR100W 1.0.1.1X
Open Source Used In CVR100W 1.0.1.1x Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-35996155 78-21097-01 Open Source Used In CVR100W 1.0.1.1x 1 This document contains the licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of the source code to which you are entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-35996155 En ce qui a trait au logiciel gratuit ou à exploitation libre figurant dans ce document, si vous avez des questions ou souhaitez recevoir une copie du code source, auquel vous avez droit en vertu des licences gratuites ou d'exploitation libre applicables (telles que licences GNU Lesser/General Public), veuillez communiquer avec nous à l'adresse external- [email protected]. Dans vos demandes, veuillez inclure le numéro de référence 78EE117C99-35996155 Contents 1.1 binutils 2.17 1.1.1 Available under license 1.2 brcm_rstp 0.21 1.2.1 Available under license 1.3 bridge-utils 1.0.6 1.3.1 Available under license 1.4 BusyBox 1.7.2 1.4.1 Available under license 1.5 config 1.0 1.5.1 Available under license 1.6 conntrack-tools 1.0.0 1.6.1 -

BERKELEY PACKET FILTER: Theory, Practice and Perspectives
Alma Mater Studiorum · Universita` di Bologna SCUOLA DI SCIENZE Corso di Laurea in Informatica BERKELEY PACKET FILTER: theory, practice and perspectives Relatore: Presentata da: Chiar.mo Prof. MICHELE DI STEFANO RENZO DAVOLI Sessione II Anno Accademico 2019/2020 All operating systems sucks, but Linux just sucks less. Linus Torvalds Introduction Initially packet filtering mechanism in many Unix versions was imple- mented in the userspace, meaning that each packet was copied from the kernel-space to the user-space before being filtered. This approach resulted to be inefficient compared with the performance shown by the introduction of the BSD classic Berkeley Packet Filter (cBPF). cBPF consists of an as- sembly language for a virtual machine which resides inside the kernel. The assembly language can be used to write filters that are loaded in to the ker- nel from the user-space allowing the filtering to happen in the kernel-space without copying each packet as before. cBPF use is not limited to just the networking domain but it is also applied as a mechanism to filter system calls through seccomp mode. Seccomp allows the programmer to arbitrary select which system calls to permit, representing an useful mechanism to implement sandboxing. In order to increase the number of use cases and to update the architecture accordingly to new advancements in modern processors, the virtual machine has been rewritten and new features have been added. The result is extended Berkeley Packet Filter (eBPF) which consists of a richer assembly, more pro- gram types, maps to store key/value pairs and more components. Currently eBPF (or just BPF) is under continuous development and its capacities are evolving, although the main uses are networking and tracing. -

Making the Kernel's Networking Data Path Programmable with BPF and XDP
Making the Kernel’s Networking Data Path Programmable with BPF and XDP. Daniel Borkmann <[email protected]> Covalent IO OSSNA17, September 12, 2017 Daniel Borkmann, Covalent IO BPF and XDP in the Linux kernel September 12, 2017 1 / 17 What is BPF? tcpdump -i eno1 -ddd icmp or icmp6 12 40 0 0 12 21 0 2 2048 48 0 0 23 21 6 7 1 21 0 6 34525 48 0 0 20 21 3 0 58 21 0 3 44 48 0 0 54 21 0 1 58 6 0 0 262144 6 0 0 0 Daniel Borkmann, Covalent IO BPF and XDP in the Linux kernel September 12, 2017 2 / 17 What is BPF? tcpdump -i eno1 -d icmp or icmp6 (000) ldh [12] (001) jeq #0x800 jt 2 jf 4 (002) ldb [23] (003) jeq #0x1 jt 10 jf 11 (004) jeq #0x86dd jt 5 jf 11 (005) ldb [20] (006) jeq #0x3a jt 10 jf 7 (007) jeq #0x2c jt 8 jf 11 (008) ldb [54] (009) jeq #0x3a jt 10 jf 11 (010) ret #262144 (011) ret #0 Daniel Borkmann, Covalent IO BPF and XDP in the Linux kernel September 12, 2017 3 / 17 BPF back then. Original use-case: tcpdump filter for raw packet sockets Filtering as early as possible to avoid wasting resources Generic, fast and safe language for packet parsing Protocols often complex and parsers buggy (→ CVEs) ... Hard requirement to ensure stability when run in kernel space tcpdump → libpcap → BPF insns → kernel → verifier → interpreter Daniel Borkmann, Covalent IO BPF and XDP in the Linux kernel September 12, 2017 4 / 17 BPF nowadays. -

Virtualization Best Practices
SUSE Linux Enterprise Server 12 SP4 Virtualization Best Practices SUSE Linux Enterprise Server 12 SP4 Publication Date: September 24, 2021 Contents 1 Virtualization Scenarios 2 2 Before You Apply Modifications 2 3 Recommendations 3 4 VM Host Server Configuration and Resource Allocation 3 5 VM Guest Images 26 6 VM Guest Configuration 37 7 VM Guest-Specific Configurations and Settings 43 8 Hypervisors Compared to Containers 46 9 Xen: Converting a Paravirtual (PV) Guest to a Fully Virtual (FV/HVM) Guest 50 10 External References 53 1 SLES 12 SP4 1 Virtualization Scenarios Virtualization oers a lot of capabilities to your environment. It can be used in multiple scenarios. For more details refer to Book “Virtualization Guide”, Chapter 1 “Virtualization Technology”, Section 1.2 “Virtualization Capabilities” and Book “Virtualization Guide”, Chapter 1 “Virtualization Technology”, Section 1.3 “Virtualization Benefits”. This best practice guide will provide advice for making the right choice in your environment. It will recommend or discourage the usage of options depending on your workload. Fixing conguration issues and performing tuning tasks will increase the performance of VM Guest's near to bare metal. 2 Before You Apply Modifications 2.1 Back Up First Changing the conguration of the VM Guest or the VM Host Server can lead to data loss or an unstable state. It is really important that you do backups of les, data, images, etc. before making any changes. Without backups you cannot restore the original state after a data loss or a misconguration. Do not perform tests or experiments on production systems. 2.2 Test Your Workloads The eciency of a virtualization environment depends on many factors. -
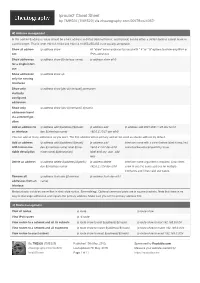
Iproute2 Cheat Sheet by TME520 (TME520) Via Cheatography.Com/20978/Cs/4067
iproute2 Cheat Sheet by TME520 (TME520) via cheatography.com/20978/cs/4067/ Address management In this section ${address} value should be a host address in dotted decimal format, and ${mask} can be either a dotted decimal subnet mask or a prefix length. That is, both 192.0.2.10/24 and 192.0.2.10 /25 5.25 5.255.0 are equally accepta ble. Show all addres‐ ip address show All "s how " commands can be used with "- 4" or "- 6" options to show only IPv4 or ses IPv6 addresses. Show addresses ip address show ${inter face name} ip address show eth0 for a single interf‐ ace Show addresses ip address show up only for running interfa ces Show only ip address show [dev ${inter face}] permanent statically configured address es Show only ip address show [dev ${inter face}] dynamic addresses learnt via autocon fig ur‐ ation Add an address to ip address add ${addre ss} /${ mask} ip address add ip address add 2001:db 8:1 ::/48 dev tun10 an interfa ce dev ${inter face name} 192.0.2.10/27 dev eth0 You can add as many addresses as you want. The first address will be primary and will be used as source address by default. Add an address ip address add ${addre ss} /${ mask} ip address add Interface name with a colon before label is required, with human-r ea‐ dev ${inter face name} label ${inte‐ 192.0.2.1/24 dev eth0 some backwards compati bility issue. dable descrip tion rface name}:$ {de scr ipt ion} label eth0:my _wa n_a dd‐ ress Delete an address ip address delete ${addre ss} /${ pre fix} ip address delete Interface name argument is required. -

How to Surprise by Being a Linux Performance "Know-It-All"
Christian Ehrhardt Webcast October 2013, Germany How to Surprise by being a Linux Performance "know-it-all" Christian Ehrhardt, IBM R&D Germany, System Performance Analyst © 2013 IBM Corporation Linux on System z Performance Evaluation Agenda . Tools are your swiss army knife – ps – top – sadc/sar – iostat – vmstat – netstat IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at www.ibm.com/legal/copytrade.shtml. 2 October 4, 2013 Webcast October 2013 © 2013 IBM Corporation Linux on System z Performance Evaluation Agenda . Tools are your swiss army knife – ps – top – sadc/sar – iostat – vmstat – netstat 3 October 4, 2013 Webcast October 2013 © 2013 IBM Corporation Linux on System z Performance Evaluation Everything was nice and easy up to now, → be Ready for Take-Off 4 October 4, 2013 Webcast October 2013 © 2013 IBM Corporation Linux on System z Performance Evaluation Agenda . Your swiss army knife for the complex cases – Netstat – network statistics and overview – Pidstat – per process statistics – Socket Statistics – extended socket statistics – Slabtop – kernel memory pool consumption – top / ps – process overview – Lsof – check file flags of open files – Icastats / lszcrypt – check usage of crypto hw support – Blktrace – low level disk I/O analysis – Lsluns / multipath – check multipath setup – -

Intro to Iproute2
Intro to iproute2 John Lewis Western Pennsylvania Linux Users Group May 1, 2012 John Lewis Intro to iproute2 What is iproute2 iproute2 is a collection of utilities for controlling TCP/IP networking in Linux John Lewis Intro to iproute2 Net-tools inadequate for modern networks and is obsolete ifconfig route netstat arp rarp John Lewis Intro to iproute2 New tools in iproute2 ip ip help ip link (network device) ip addr (IP or Ipv6 address on device) ip addrlabel (label configuration on protocol address) ip route (routing table entry) ip rule (rule and routing protocol entry) ip neigh (ARP or NDISC cache entry) John Lewis Intro to iproute2 More new tools in iproute2 ip tunnel (tunnel over IP) ip tuntap ip maddr (multicast address) ip mroute (multicast routing cache entry) ip monitor (show objects) ip xfrm ss investigates sockets John Lewis Intro to iproute2 ip ip [options] object f command | help g tools are addressed as objects help goes at the end to get help on a specific object using help on ip directly gets all of the available commands man page not as current as ip help John Lewis Intro to iproute2 ip link ip link modifies device state add device ip link add link [device to act on] name [name of new device] remove device ip link delete [device to act on] show device ip link show ip link set [device] fup | down | arp fon | offgg John Lewis Intro to iproute2 ip neigh ip neigh fshow | flushg [target address] dev [device name] [state] show shows things flush removes things can be manipulated with other commands ip neigh f add | del | change |