Generating Relative Pick Value in the NBA Draft and Predicting Success from College Basketball
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

College Hoops Scoops Stony Brook, Hofstra, LIU Set to Go
Newsday.com 11/12/11 10:17 AM http://www.newsday.com/sports/college/college-hoops-scoops-1.1620561/stony-brook-hofstra-liu-set-to-go-1.3314160 College hoops scoops Stony Brook, Hofstra, LIU set to go Friday November 11, 2011 2:47 PM By Marcus Henry We’re not even technically through the first week of college basketball an already there are a couple of matchups the that should be paid attention to. Local Matchups Friday LIU at Hofstra, 7:00: After LIU’s fabulous run to the NCAA Tournament last, the Blackbirds have become one of the hottest programs in the NY Metro area. With six of its top eight players back, led by junior forward Julian Boyd the Blackbirds could he a handful for Hofstra. As for the Pride, Mo Cassara’s group could be one of the most underrated in the area. Sure, Charles Jenkins and Greg Washington are gone, but Mike Moore, David Imes, Stevie Mejia, Nathaniel Lester and Shemiye McLendon are all experienced players. It should be a good one in Hempstead. Stony Brook at Indiana, 7:00: Stony Brook and its followers have waited an entire off season for this matchup. With so much talent back and several newcomers expected to create an immediate impact, no one would be shocked to see the Seawolves win this game. Senior guard Bryan Dougher, redshirt junior forward Tommy Brenton and senior Dallis Joyner have been the key elements to Stony Brook’s rise. The Seawolves have had winning seasons two of the last three years and have finished .500 or better in the America East the last three years. -

The Cowl 2021
Providence College Vol. LXXXIIII No. 5 October 3, 2019 thecowl.com London Calling: Fiestaval: A Celebration of Beauty and Background by Brian Garvey '20 particularly to JP Collins ’21, who said, “I really News Staff got into the rhythm of their music. It was really "Civ in London" ON-CAMPUS cool to hear live. I had heard mentions of them before, but I really think they could get big.” an Alternative On Friday, September 27, the Board of Programmers (BOP) and the Board of Fiestaval/Page 2 Multicultural Student Affairs (BMSA) hosted Abroad Experience Fiestaval on the Slavin Lawn. Born from the idea of mixing a fiesta with by Max Waite '21 a carnival, Fiestaval is a celebration of the News Staff uniqueness and beauty of different world STUDY ABROAD cultures. The party started with the beautiful Footprints Gospel Choir, celebrating the rich religious and Starting next school year, sophomore musical tradition at Providence College. Dylan students at Providence College will be given Holmes ’20 was blown away by PC’s Footprints, the opportunity to study abroad in London, saying, “Their voices were unbelievable to England, as part of the Development of Western listen to. I didn’t really know anything about Civilization Program. Footprints, but now I really want to see them The Providence College Center for Global perform again.” Education has been working on this program for Following Footprints, the supremely talented about a year, and it will provide a select group Irish Step team took the stage, paying homage of 30-40 non-honors sophomore students an to the strong Irish heritage of many PC students. -

2019-20 Donruss Optic Basketball Checklist NBA HOBBY
2019-20 Donruss Optic Basketball Checklist - Hobby - NBA Autograph FOTL Content - All teams with FOTL Auto Content Player Set Card # Team Print Run Matisse Thybulle Auto - Rated Rookies Signatures Purple Stars 192 76ers 49 Matisse Thybulle Auto - Rated Rookies Signatures Purple Velocity 192 76ers 10 Ty Jerome Auto - Rated Rookies Signatures Purple Stars 167 76ers 49 Ty Jerome Auto - Rated Rookies Signatures Purple Velocity 167 76ers 10 CJ McCollum Auto - Dominators Signatures Purple Stars 34 Blazers 29 Damian Lillard Auto - Dominators Signatures Purple Stars 4 Blazers 29 Nassir Little Auto - Rated Rookies Signatures Purple Stars 154 Blazers 49 Nassir Little Auto - Rated Rookies Signatures Purple Velocity 154 Blazers 10 Nassir Little Auto - Rookie Dominators Signatures Purple Stars 2 Blazers 29 Bob Dandridge Auto - Retro Series Signatures Purple Stars 5 Bucks 29 Ersan Ilyasova Auto - Dominators Signatures Purple Stars 22 Bucks 29 Khris Middleton Auto - Dominators Signatures Purple Stars 35 Bucks 29 Wesley Matthews Auto - Dominators Signatures Purple Stars 9 Bucks 29 Coby White Auto - Rated Rookies Signatures Purple Stars 180 Bulls 49 Coby White Auto - Rated Rookies Signatures Purple Velocity 180 Bulls 10 Coby White Auto - Rookie Dominators Signatures Purple Stars 21 Bulls 29 Daniel Gafford Auto - Rated Rookies Signatures Purple Stars 153 Bulls 49 Daniel Gafford Auto - Rated Rookies Signatures Purple Velocity 153 Bulls 10 Lauri Markkanen Auto - Dominators Signatures Purple Stars 20 Bulls 29 Otto Porter Jr. Auto - Dominators Signatures Purple Stars 10 Bulls 29 Thaddeus Young Auto - Dominators Signatures Purple Stars 15 Bulls 29 Toni Kukoc Auto - Retro Series Signatures Purple Stars 25 Bulls 29 Cedi Osman Auto - Dominators Signatures Purple Stars 29 Cavaliers 29 Dylan Windler Auto - Rated Rookies Signatures Purple Stars 197 Cavaliers 49 Dylan Windler Auto - Rated Rookies Signatures Purple Velocity 197 Cavaliers 10 Dylan Windler Auto - Rookie Dominators Signatures Purple Stars 12 Cavaliers 29 Kevin Porter Jr. -
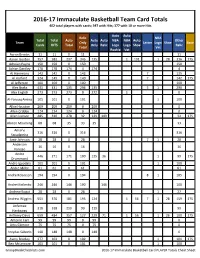
2016-17 Immaculate Basketball Player Checklist;
2016-17 Immaculate Basketball Team Card Totals 402 total players with cards; 397 with Hits; 377 with 10 or more Hits Auto Auto Relic NBA Total Total Auto Auto Auto NBA NBA Auto Other Team Only Letter Logo Shoe Base Cards HITS Total Only Relic Logo Logo Shoe Relic Total Vet Rookie Vet Aaron Brooks 11 11 0 11 11 Aaron Gordon 757 582 237 345 135 1 101 1 28 316 175 Adreian Payne 150 150 0 150 150 Adrian Dantley 178 178 174 4 174 4 AJ Hammons 142 142 0 142 7 135 Al Horford 324 149 0 149 7 142 175 Al Jefferson 100 100 0 100 100 Alec Burks 431 431 135 296 135 5 1 290 Alex English 273 273 273 0 272 1 0 Al-Farouq Aminu 101 101 0 101 1 100 Allan Houston 209 209 209 0 209 0 Allen Crabbe 124 124 124 0 124 0 Allen Iverson 485 310 278 32 129 149 32 175 Alonzo Mourning 68 68 35 33 35 33 Amar'e 316 316 0 316 316 Stoudemire Amir Johnson 28 28 0 28 7 1 20 Anderson 16 16 0 16 16 Varejao Andre 446 271 171 100 135 36 1 99 175 Drummond Andre Iguodala 101 101 0 101 1 100 Andre Miller 61 61 0 61 61 Andre Roberson 194 194 0 194 8 1 185 Andrei Kirilenko 246 246 146 100 146 100 Andrew Bogut 28 28 0 28 1 27 Andrew Wiggins 551 376 181 195 124 1 56 7 1 28 159 175 Anfernee 318 318 219 99 219 99 Hardaway Anthony Davis 659 484 357 127 229 71 1 56 1 26 100 175 Antoine Carr 99 99 99 0 99 0 Artis Gilmore 75 75 75 0 75 0 Arvydas Sabonis 148 148 148 0 148 0 Avery Bradley 277 102 0 102 1 101 175 Ben McLemore 101 101 0 101 1 100 GroupBreakChecklists.com 2016-17 Immaculate Basketball Card PLAYER Totals Cheat Sheet Auto Auto Relic NBA Total Total Auto Auto Auto NBA NBA Auto Other -

2018-19 Contenders Draft Basketball Checklist
2018 (18/19) Contenders Draft Basketball Team Checklist As of August 2018; 11 Players w Autos currently not signed with NBA Teams (2-way/Exhibit10); No Raptors Autos as assigned Player Set Card # Team Draft Round Summer League/Notes Joel Embiid Season Ticket Signatures 6 76ers NBA Landry Shamet College Ticket Auto 77 76ers 1st Landry Shamet College Ticket Variation Auto 77 76ers 1st Markelle Fultz Turning Pro Signatures 9 76ers NBA Zhaire Smith College RPS Ticket Auto 65 76ers 1st Zhaire Smith College RPS Ticket Variation Auto 65 76ers 1st Zhaire Smith School Colors Signatures 15 76ers 1st Anfernee Simons College Ticket Auto 125 Blazers 1st Damian Lillard Legacy Signatures Auto 3 Blazers NBA Gary Trent Jr. College Ticket Auto 67 Blazers 2nd Gary Trent Jr. College Ticket Variation Auto 67 Blazers 2nd Gary Trent Jr. School Colors Signatures 17 Blazers 2nd Brandon McCoy College Ticket Auto 78 Bucks Undrafted Signed Brandon McCoy College Ticket Variation Auto 78 Bucks Undrafted Signed Donte DiVincenzo College Ticket Auto 91 Bucks 1st Donte DiVincenzo College Ticket Variation Auto 91 Bucks 1st Marques Johnson Season Ticket Signatures 8 Bucks NBA Chandler Hutchison College Ticket Auto 70 Bulls 1st Chandler Hutchison College Ticket Variation Auto 70 Bulls 1st Chandler Hutchison School Colors Signatures 20 Bulls 1st Lauri Markkanen Collegiate Connections Dual Player Auto 1 Bulls NBA Lauri Markkanen Legacy Signatures Auto 7 Bulls NBA Lauri Markkanen Turning Pro Signatures 7 Bulls NBA Wendell Carter Jr. College RPS Ticket Auto 57 Bulls 1st Wendell Carter Jr. College RPS Ticket Variation Auto 57 Bulls 1st Wendell Carter Jr. -

2014-15 NABC-Division I ALL-DISTRICT TEAMS and Coaches
FOR IMMEDIATE RELEASE Contact: Rick Leddy, NABC 203-239-4253 ([email protected]) National Association of Basketball Coaches Announces 2014-15 Division I All-District Teams and UPS All-District Coaches KANSAS CITY, Mo. (March 27, 2015) -- The National Association of Basketball Coaches (NABC) announced today the NABC Division I All-District teams and UPS All-District coaches for 2014-15. Selected and voted on by member coaches of the NABC, these student-athletes and coaches represent the finest basketball players and coaches across America. 2014-15 NABC DIVISION I ALL-DISTRICT TEAMS District 1 District 3 First Team First Team David Laury Iona John Brown High Point A.J. English Iona Saah Nimley Charleston Southern Emmy Andujar Manhattan Keon Moore Winthrop Jameel Warney Stony Brook Brett Comer Florida Gulf Coast Zaid Hearst Quinnipiac Ty Greene USC Upstate Second Team Second Team Sam Rowley Albany Javonte Green Radford Matt Lopez Rider Jerome Hill Gardner Webb Ousmane Drame Quinnipiac Warren Gillis Coastal Carolina Chavaughn Lewis Marist Dallas Moore North Florida Justin Robinson Monmouth Bernard Thompson Florida Gulf Coast District 2 District 4 First Team First Team Jahlil Okafor Duke Treveon Graham VCU Jerian Grant Notre Dame DeAndre’ Bembry Saint Joseph’s Rakeem Christmas Syracuse Jordan Sibert Dayton Malcolm Brogdon Virginia Kendall Anthony Richmond Justin Anderson Virginia E.C. Matthews Rhode Island Second Team Second Team Terry Rozier Louisville Jordan Price La Salle Montrezl Harrell Louisville Tyler Kalinoski Davidson Quinn Cook Duke Dyshawn Pierre Dayton Marcus Paige North Carolina PatricioOlivier Hanlan Garino BostonGeorge College Washington Olivier Hanlan Boston College Hassan Martin Rhode Island District 5 District 8 First Team First Team Darrun Hilliard Villanova Buddy Hield Oklahoma Kris Dunn Providence Georges Niang Iowa State LaDontae Henton Providence Perry Ellis Kansas D’Angelo Harrison St. -

Individual Statistical Leaders
Tournament Individual Leaders (as of Aug 14, 2012) All games FIELD GOAL PCT (min. 10 made) FG ATT Pct FIELD GOAL ATTEMPTS G Att Att/G -------------------------------------------- --------------------------------------------- Darius Songaila-LTH........... 24 30 .800 Patrick Mills-AUS............. 6 116 19.3 Tyson Chandler-USA............ 14 20 .700 Luis Scola-ARG................ 8 106 13.3 Andre Iguodala-USA............ 14 20 .700 Manu Ginobili-ARG............. 8 103 12.9 Aaron Baynes-AUS.............. 21 32 .656 Kevin Durant-USA.............. 8 101 12.6 Anthony Davis-USA............. 11 17 .647 Pau Gasol-ESP................. 8 100 12.5 Kevin Love-USA................ 34 54 .630 Dan Clark-GBR................. 15 24 .625 FIELD GOALS MADE G Made Made/G Tomofey Mozgov-RUS............ 33 53 .623 --------------------------------------------- LeBron James-USA.............. 44 73 .603 Pau Gasol-ESP................. 8 57 7.1 Serge Ibaka-ESP............... 26 45 .578 Luis Scola-ARG................ 8 56 7.0 Nene Hilario-BRA.............. 12 21 .571 Manu Ginobili-ARG............. 8 51 6.4 Pau Gasol-ESP................. 57 100 .570 Kevin Durant-USA.............. 8 49 6.1 Patrick Mills-AUS............. 6 49 8.2 3-POINT FG PCT (min. 5 made) 3FG ATT Pct 3-POINT FG ATTEMPTS G Att Att/G -------------------------------------------- --------------------------------------------- Shipeng Wang-CHN.............. 13 21 .619 Kevin Durant-USA.............. 8 65 8.1 S. Jasikevicius-LTH........... 7 12 .583 Carlos Delfino-ARG............ 8 54 6.8 Dan Clark-GBR................. 8 14 .571 Patrick Mills-AUS............. 6 48 8.0 Andre Iguodala-USA............ 5 9 .556 Carmelo Anthony-USA........... 8 46 5.8 Amine Rzig-TUN................ 8 15 .533 Manu Ginobili-ARG............. 8 43 5.4 Kevin Durant-USA............. -

Lehigh University Athletics
SCHEDULE/RESULTS (7-6, 1-1 PATRIOT LEAGUE) LEHIGH Nov. 11 at Xavier (Fox College Sports Central) L, 84-81 17 at Yale L, 89-81 (OT) MEN’S BASKETBALL 20 PRINCETON (PLN) W, 76-67 25 at Mississippi State (SEC Network+) W, 87-73 Senior Tim Kempton 27 at Arkansas State L, 97-89 2X Patriot League Player of the Year 30 at La Salle L, 89-81 1,662 career points (Eighth in school history) Dec. 3 ROBERT MORRIS (PLN) W, 64-58 GAME 14: LOYOLA AT LEHIGH 6 at Stony Brook L, 62-57 10 at Mount St. Mary’s W, 90-71 LOYOLA GREYHOUNDS (7-6, 1-1 PATRIOT LEAGUE) at 12 SAINT FRANCIS (PA) (PLN) W, 100-67 22 CABRINI (PLN) W, 93-72 LEHIGH MOUNTAIN HAWKS (7-6, 1-1 PATRIOT LEAGUE) 30 at Army West Point* (PLN) W, 66-59 THURSDAY, JANUARY 5, 2017 • 7:00 PM Jan. STABLER ARENA (5,600) • BETHLEHEM, PA. 2 at Boston University* (PLN) L, 75-61 5 LOYOLA* (SE2/PLN) 7:00 SERVICE ELECTRIC 2 SPORTS 8 AMERICAN* (SE2/PLN) 2:00 11 at Bucknell* (PLN) 7:00 SETTING THE SCENE 14 HOLY CROSS* (SE2/PLN) 2:00 Coming off its first loss in almost a month, the Lehigh men’s basketball team will look to bounce back 18 at Navy* (PLN) 7:00 when it returns to Stabler Arena for its first home Patriot League game on Thursday vs. Loyola. Opening 21 LAFAYETTE* (SE2/PLN) 7:00 tipoff is set for 7 p.m. The Mountain Hawks will look to build upon their 4-0 home record so far this 25 at Colgate* (PLN) 7:00 30 BOSTON UNIVERSITY* (CBS SN) 7:00 season, facing a Loyola squad that enters 1-1 in the league and 7-6 overall. -

Chimezie Metu Demar Derozan Taj Gibson Nikola Vucevic
DeMar Chimezie DeRozan Metu Nikola Taj Vucevic Gibson Photo courtesy of Fernando Medina/Orlando Magic 2019-2020 • 179 • USC BASKETBALL USC • In The Pros All-Time The list below includes all former USC players who had careers in the National Basketball League (1937-49), the American Basketball Associa- tion (1966-76) and the National Basketball Association (1950-present). Dewayne Dedmon PLAYER PROFESSIONAL TEAMS SEASONS Dan Anderson Portland .............................................1975-76 Dwight Anderson New York ................................................1983 San Diego ..............................................1984 John Block Los Angeles Lakers ................................1967 San Diego .........................................1968-71 Milwaukee ..............................................1972 Philadelphia ............................................1973 Kansas City-Omaha ..........................1973-74 New Orleans ..........................................1975 Chicago .............................................1975-76 David Bluthenthal Sacramento Kings ..................................2005 Mack Calvin Los Angeles (ABA) .................................1970 Florida (ABA) ....................................1971-72 Carolina (ABA) ..................................1973-74 Denver (ABA) .........................................1975 Virginia (ABA) .........................................1976 Los Angeles Lakers ................................1977 San Antonio ............................................1977 Denver ...............................................1977-78 -

General Assembly of North Carolina Session 2009 Ratified Bill
GENERAL ASSEMBLY OF NORTH CAROLINA SESSION 2009 RATIFIED BILL RESOLUTION 2010-16 SENATE JOINT RESOLUTION 1456 A JOINT RESOLUTION HONORING THE DUKE BLUE DEVILS ON WINNING THE 2010 NATIONAL BASKETBALL CHAMPIONSHIP. Whereas, on April 5, 2010, the Duke University men's basketball team won the 2010 National Collegiate Athletic Association (NCAA) Division I Championship by defeating Butler University by a score of 61-59; and Whereas, this championship gives Duke University its fourth Division I NCAA title for the men's basketball program, adding to the championships won in 1991, 1992, and 2001; and Whereas, the Blue Devils have achieved an outstanding record during their NCAA tournament history, which includes being selected 11 times as a No. 1 seed and appearing in 34 tournaments with 10 championship game appearances, 15 Final Four appearances, 18 Elite Eight appearances, and 25 Sweet 16 appearances; and Whereas, the Blue Devils won the 2010 Atlantic Coast Conference (ACC) tournament championship, increasing the program's record to 18 ACC tournament titles, the most titles of any ACC member; and Whereas, the Blue Devils were the ACC regular season cochampions, achieving a conference record of 13-3; and Whereas, the Blue Devils triumphed on their home court this season by going undefeated; and Whereas, the Blue Devils finished the 2009-2010 season with a record of 35-5 and were ranked No. 1 by the USA Today/ESPN Top 25 men's basketball coaches' poll; and Whereas, much of the Blue Devils' success can be attributed to the leadership of head coach, -
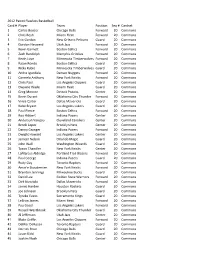
2012 Panini Flawless Basketball Card # Player Team Position Seq
2012 Panini Flawless Basketball Card # Player Team Position Seq # Cardset 1 Carlos Boozer Chicago Bulls Forward 20 Commons 2 Chris Bosh Miami Heat Forward 20 Commons 3 Eric Gordon New Orleans Pelicans Guard 20 Commons 4 Gordon Hayward Utah Jazz Forward 20 Commons 5 Kevin Garnett Boston Celtics Forward 20 Commons 6 Zach Randolph Memphis Grizzlies Forward 20 Commons 7 Kevin Love Minnesota Timberwolves Forward 20 Commons 8 Rajon Rondo Boston Celtics Guard 20 Commons 9 Ricky Rubio Minnesota Timberwolves Guard 20 Commons 10 Andre Iguodala Denver Nuggets Forward 20 Commons 11 Carmelo Anthony New York Knicks Forward 20 Commons 12 Chris Paul Los Angeles Clippers Guard 20 Commons 13 Dwyane Wade Miami Heat Guard 20 Commons 14 Greg Monroe Detroit Pistons Center 20 Commons 15 Kevin Durant Oklahoma City Thunder Forward 20 Commons 16 Vince Carter Dallas Mavericks Guard 20 Commons 17 Kobe Bryant Los Angeles Lakers Guard 20 Commons 18 Paul Pierce Boston Celtics Forward 20 Commons 19 Roy Hibbert Indiana Pacers Center 20 Commons 20 Anderson Varejao Cleveland Cavaliers Center 20 Commons 21 Brook Lopez Brooklyn Nets Center 20 Commons 22 Danny Granger Indiana Pacers Forward 20 Commons 23 Dwight Howard Los Angeles Lakers Center 20 Commons 24 Jameer Nelson Orlando Magic Guard 20 Commons 25 John Wall Washington Wizards Guard 20 Commons 26 Tyson Chandler New York Knicks Center 20 Commons 27 LaMarcus Aldridge Portland Trail Blazers Forward 20 Commons 28 Paul George Indiana Pacers Guard 20 Commons 29 Rudy Gay Toronto Raptors Forward 20 Commons 30 Amar'e Stoudemire -

GAME NOTES for In-Game Notes and Updates, Follow Grizzlies PR on Twitter @Grizzliespr
GAME NOTES For in-game notes and updates, follow Grizzlies PR on Twitter @GrizzliesPR GRIZZLIES 2020-21 SCHEDULE/RESULTS Date Opponent Tip-Off/TV • Result 12/23 SAN ANTONIO L 119-131 MEMPHIS GRIZZLIES 12/26 ATLANTA L 112-122 12/28 @ Brooklyn W (OT) 116-111 END OF 2021 POSTSEASON GAME NOTES 12/30 @ Boston L 107-126 1/1 @ Charlotte W 108-93 38-34 1-4 1/3 LA LAKERS L 94-108 Game Notes/Stats Contact: Ross Wooden [email protected] Reg Season Playoffs 1/5 LA LAKERS L 92-94 1/7 CLEVELAND L 90-94 1/8 BROOKLYN W 115-110 MEMPHIS GRIZZLIES STARTING LINEUP 1/11 @ Cleveland W 101-91 1/13 @ Minnesota W 118-107 SF # 1 6-8 ¼ 230 Previous Game 4 PTS 2 REB 5 AST 2 STL 0 BLK 24:11 1/16 PHILADELPHIA W 106-104 Selected 30th overall in the 2015 NBA Draft after two seasons at UCLA. 1/18 PHOENIX W 108-104 First player to compile 10+ steals in any two-game playoff span since Dwyane 1/30 @ San Antonio W 129-112 KYLE ANDERSON 2/1 @ San Antonio W 133-102 Wade during the 2013 NBA Finals. th 2/2 @ Indiana L 116-134 UCLA / USA 7 Season Career-high 94 3PM this season (previous: 24 3PM in 67 games in 2019-20). 2/4 HOUSTON L 103-115 PPG: 8.4 RPG: 5.0 APG: 3.2 2/6 @ New Orleans L 109-118 2/8 TORONTO L 113-128 PF # 13 6-11 242 Previous Game 21 PTS 6 REB 1 AST 1 STL 0 BLK 26:01 2/10 CHARLOTTE W 130-114 Selected fourth overall in 2018 NBA Draft after freshman year at Michigan State.