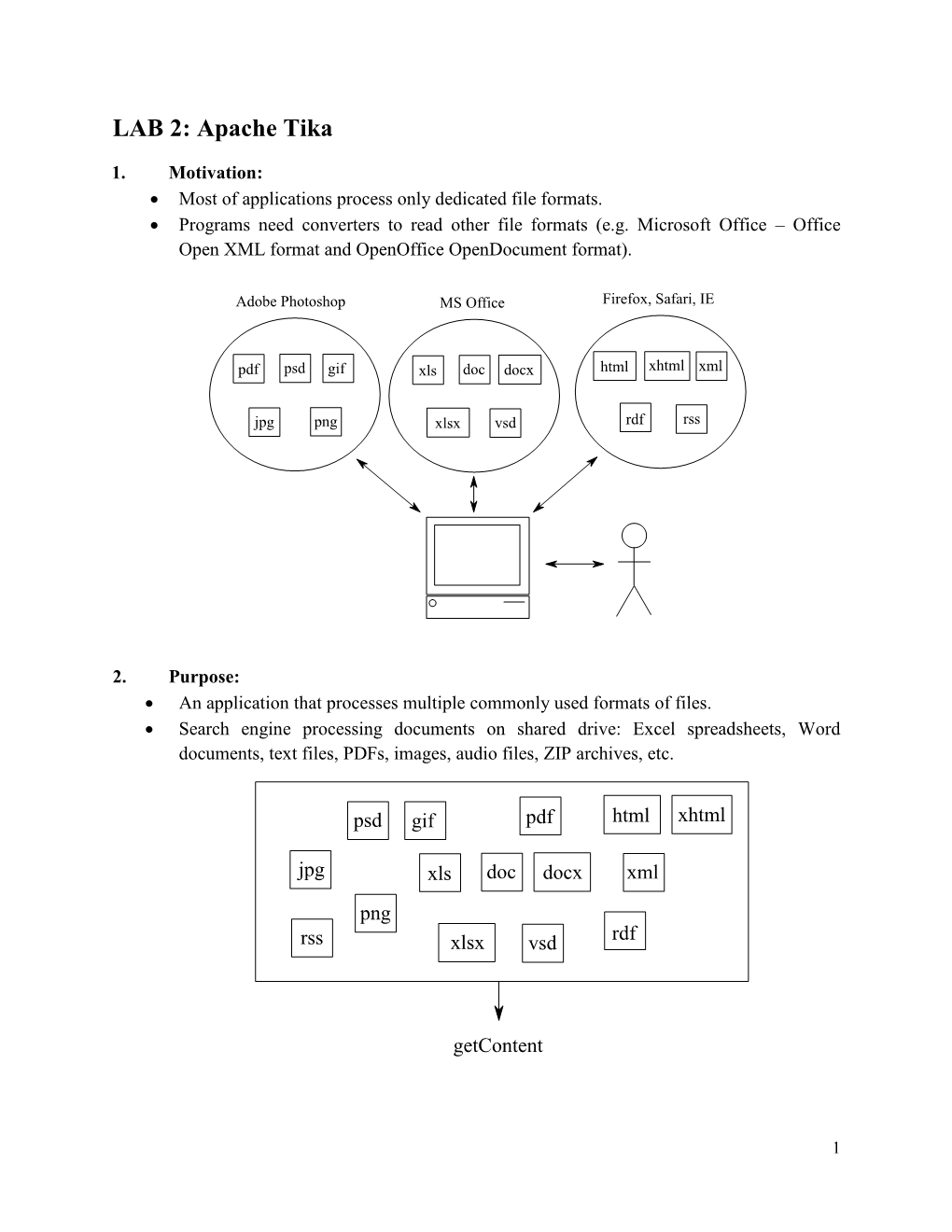
LAB 2: Apache Tika
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Third Party Library Attributions
Third Party Library Attributions Table of Contents 1. Summary 2. PureWeb® Software Third Party Library Attributions 3. PureWeb iOS Client Libraries 3.1. Cocoa Lumberjack Framework 3.2. Sodium Crypto Library 4. ResolutionMD Server Libraries 4.1. Apache Commons 4.2. Apache PDFBox 4.3. Apache HttpComponents 4.4. Arial Unicode Font 4.5. Auto 4.6. Boost 4.7. Bootstrap 4.8. Cairo 4.9. CanJS 4.10. Curl 4.11. dcm4che2 4.12. dcm4che3 4.13. dcm4che5 4.14. DCMTK 4.15. Drools Expert 4.16. Eclipse Implementation of JAXB 4.17. Eclipse Metro 4.18. Eclipse ORB 4.19. Eclipse Project for JAX-WS 4.20. FFmpeg 4.21. FreeMarker 4.22. Freetype 4.23. FTGL 4.24. Glew 4.25. google-api-java-client 4.26. google-api-java-client-services 4.27. google-code-prettify 4.28. google-http-java-client 4.29. google-oauth-java-client 4.30. grcp-java 4.31. guava 4.32. html5shiv 4.33. HAPI 4.34. ICU 4.35. ITK 4.36. Java implementation of JSON Web Token (JWT) 4.37. Jersey 4.38. Joda-Time 4.39. jQuery 4.40. jQuery File Upload Plugin 4.41. jQuery Hashchange 4.42. jQuery UI 4.43. JSON Web Token support for the JVM 4.44. jsoup Java HTML Parser 4.45. Lo-Dash 4.46. libpng 4.47. llvm 4.48. logback 4.49. Mesa 3D Graphics Library 4.50. minizip 4.51. PixelMed 4.52. opencensus-java 4.53. requirejs 4.54. SLF4J 4.55. wysihtml5 4.56. zlib 5. -

Migration Guide
MIGRATION GUIDE DIGITAL EXPERIENCE MANAGER 7.2 1 MIGRATION GUIDE DIGITAL EXPERIENCE MANAGER 7.2 SUMMARY 1 INTRODUCTION ...................................................................................................................................................... 4 2 HOW TO UPGRADE FROM DIGITAL EXPERIENCE MANAGER 7.1 TO 7.2 ..................................... 5 2.1 Code base review and potential impacts .................................................................. 5 2.2 Deployment scripts/procedure review ....................................................................... 5 2.3 Test environment migration ............................................................................................ 5 3 RENDER FILTER CHANGE .................................................................................................................................... 6 3.1 Render Filters priority is now a Float instead of an Integer ............................. 6 3.1.1 Impact on the migration to Digital Experience 7.2............................................... 6 4 CUSTOM IMPLEMENTATIONS OF USERS AND GROUPS PROVIDERS ........................................... 7 5 CODE THAT NEEDS TO BE UPGRADED ........................................................................................................ 8 5.1 Overridden jmix:list’s hidden.header views need to be upgraded ................ 8 5.2 Apache PDFBox was upgraded to version 2.0.3 with API changes ............... 8 5.3 osgi:list interface needs to be changed .................................................................... -

Open Source Licenses for Inspire R11
Open Source Licenses for Inspire R11 An Overview Version 11.0 GMC Software AG © 2016 GMC Software AG. All rights reserved. http://www.gmc.net/documentation CLASSIFICATION: PUBLIC Open Source Licenses for Inspire An Overview Product version 11.0 Document version 11.0.0.1 Release date: November 2016 GMC Software AG www.gmc.net See also all GMC documentation online Should you have any queries, suggestions or comments concerning these materials, please do not hesitate to contact us at [email protected]. This document contains information classified as Public. Multiple sites of the GMC Software group of companies hold certificates to ISO 9001, ISO 27001 and ISO 14001. Copyright Information contained within this document may contain technical inaccuracies or typographical errors. Changes will be added periodically and modifications will be made thereto without prior notification. GMC Software AG does not enter into any obligations or responsibilities regarding the content of this document and does not assume any legal liability – neither expressed or implied – for its accuracy, completeness and/or usefulness. Copying of the software or manual on to any data storage medium or in any other way, except for explicit company internal use, is strictly forbidden without the prior written authorization of GMC Software AG. Failure to comply with these restrictions is liable to prosecution. Trademarks GMC Software Technology and its logo are trademarks and service marks of GMC Software AG registered in Switzerland, the US and numerous other countries. Adobe and Adobe ® PDF Library™ are trademarks or registered trademarks of Adobe Systems Inc. in the US and other countries. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Analysis of a Data Processing Pipeline for Generating Knowledge Graphs from Unstructured Data
Analysis of a Data Processing Pipeline for Generating Knowledge Graphs from Unstructured Data Paras Kumar Analysis of a Data Processing Pipeline for Generating Knowledge Graphs from Unstructured Data Master’s Thesis in Computer Science EIT Digital - Cloud Computing & Services Distributed Systems Group Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology Paras Kumar 21st August 2020 Author Paras Kumar Title Analysis of a Data Processing Pipeline for Generating Knowledge Graphs from Unstructured Data MSc presentation 28th August 2020 Graduation Committee Prof. dr. ir. D. H. J. Epema Delft University of Technology Prof. dr. M.M. Specht Delft University of Technology Dr. Gregor Lammel¨ Market Logic Software AG Abstract With the rapid growth of unstructured data across different mediums, it exposes new challenges for its analysis. To overcome this, data processing pipelines are designed with the help of different tools and technologies for the analysis of data at different stages. One of the applications which we find useful for our company is the creation of knowledge graphs for better representation and understanding of relations in the data. Knowledge graph is a structure of representing information where nodes represent the entities and edges define the relationships among them. The construction of a knowledge graph is a process of extracting meaningful in- formation of entities and relations from unstructured textual data and storing it in a graph database. In this project, we are using Neo4j as a graph database for the efficient storage of data in the form of nodes and relations. To achieve this goal, our first research question proposes the architecture and implementation of a data processing pipeline for the construction of knowledge graphs using unstructured textual data. -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Licensing Information User Manual
Oracle Primavera Cloud Licensing Information User Manual Version 21 August 2021 Contents Introduction ...................................................................................................................................... 5 Licensed Products, Restricted Use Licenses, and Prerequisite Products ........................................ 5 Third Party Notices and/or Licenses ................................................................................................ 6 Bootstrap ................................................................................................................................................ 6 Commons Beanutils ............................................................................................................................... 6 Commons Collections............................................................................................................................. 7 Commons CSV ........................................................................................................................................ 8 Core Plot .................................................................................................................................................. 8 electron ................................................................................................................................................... 9 Error Prone ........................................................................................................................................... -

Prizm Content Connect Developer Guide for Windows
Prizm Content Connect Developer Guide for Windows Version 5.0 Published Feb 2012 Accusoft believes the information in this publication is accurate as of its publication date. The information is subject to change without notice. THE INFORMATION IN THIS PUBLICATION IS PROVIDED AS IS. WE MAKES NO REPRESENTATIONS OR WARRANTIES OF ANY KIND WITH RESPECT TO THE INFORMATION IN THIS PUBLICATION, AND SPECIFICALLY DISCLAIMS IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Use, copying, and distribution of any software described in this publication requires an applicable software license. For the most up-to-date listing of product names, see www.accusoft.com. All other trademarks used herein are the property of their respective owners. 2 Attributions, Notices & Copyrights ________________________________________ __ Apache PDFBox (http://pdfbox.apache.org/) Copyright 2002-2010 The Apache Software Foundation Download: http://pdfbox.apache.org/download.html License: http://www.apache.org/licenses/LICENSE-2.0 Apache FontBox (http://pdfbox.apache.org/) Copyright 2008-2010 The Apache Software Foundation Download: http://pdfbox.apache.org/download.html License: http://www.apache.org/licenses/LICENSE-2.0 Apache JempBox (http://pdfbox.apache.org/) Copyright 2008-2010 The Apache Software Foundation Download: http://pdfbox.apache.org/download.html License: http://www.apache.org/licenses/LICENSE-2.0 Apache POI (http://poi.apache.org/) Copyright 2001-2007 The Apache Software Foundation Download: http://www.apache.org/dyn/closer.cgi/poi/ -

Content Based Search Add-On API Implemented for Hadoop Ecosystem
International Journal of Research in Engineering and Science (IJRES) ISSN (Online): 2320-9364, ISSN (Print): 2320-9356 www.ijres.org Volume 4 Issue 5 ǁ May. 2016 ǁ PP. 23-28 Content Based Search Add-on API Implemented for Hadoop Ecosystem Aditya Kamble1 Kshama Jain2 ShaileshHule3 Computer Department. Pimprichinchwad College Of Engineering Akurdi, Pune – India Computer Department. Pimprichinchwad College Of Engineering Akurdi, Pune – India Computer Department. Pimprichinchwad College Of Engineering Akurdi, Pune – India Abstract:- Unstructured data like doc, pdf, accdb is lengthy to search and filter for desired information. We need to go through every file manually for finding information. It is very time consuming and frustrating. It doesn’t need to be done this way if we can use high computing power to achieve much faster content retrieval. We can use features of big data management system like Hadoop to organize unstructured data dynamically and return desired information. Hadoop provides features like Map Reduce, HDFS, HBase to filter data as per user input. Finally we can develop Hadoop Addon for content search and filtering on unstructured data. This addon will be able to provide APIs for different search results and able to download full file, part of files which are actually related to that topic. It will also provide API for context aware search results like most visited documents and much more relevant documents placed first so user work get simplified. This Addon can be used by other industries and government authorities to use Hadoop for their data retrieval as per their requirement. After this addon, we are also planning to add more API features like content retrieval from scanned documents and image based documents. -

Kerio Workspace
Kerio Workspace Step-by-Step Kerio Technologies 2011 Kerio Technologies s.r.o. All rights reserved. This guide provides detailed description on Kerio Workspace, version 1.0.0. All additional modifications and updates reserved. For current versions of the product and related manuals, check http://www.kerio.com/workspace/download/. Information regarding registered trademarks and trademarks are provided in the appendix A. Contents 1 Introduction ................................................................... 4 2 System requirements .......................................................... 5 2.1 Supported operating systems and browsers ................................ 5 3 Installation ..................................................................... 6 3.1 Windows ................................................................. 6 3.2 Mac OS X ................................................................. 6 3.3 Linux ..................................................................... 7 3.4 Admin Account ........................................................... 8 4 Kerio Workspace Administration Interface ..................................... 9 4.1 Users ..................................................................... 9 4.2 Directory Service ........................................................ 11 4.3 Email Settings ........................................................... 13 4.4 Server ports ............................................................. 14 4.5 SSL Certificates ......................................................... -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/