Algorithms in the Real World
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Leveraging Activation Sparsity for Training Deep Neural Networks
Compressing DMA Engine: Leveraging Activation Sparsity for Training Deep Neural Networks Minsoo Rhu Mike O’Connor Niladrish Chatterjee Jeff Pool Stephen W. Keckler NVIDIA Santa Clara, CA 95050 fmrhu, moconnor, nchatterjee, jpool, [email protected] Abstract—Popular deep learning frameworks require users to the time needed to copy data back and forth through PCIe is fine-tune their memory usage so that the training data of a deep smaller than the time the GPU spends computing the DNN neural network (DNN) fits within the GPU physical memory. forward and backward propagation operations, vDNN does Prior work tries to address this restriction by virtualizing the memory usage of DNNs, enabling both CPU and GPU memory not affect performance. For networks whose memory copying to be utilized for memory allocations. Despite its merits, vir- operation is bottlenecked by the data transfer bandwidth of tualizing memory can incur significant performance overheads PCIe however, vDNN can incur significant overheads with an when the time needed to copy data back and forth from CPU average 31% performance loss (worst case 52%, Section III). memory is higher than the latency to perform the computations The trend in deep learning is to employ larger and deeper required for DNN forward and backward propagation. We introduce a high-performance virtualization strategy based on networks that leads to large memory footprints that oversub- a “compressing DMA engine” (cDMA) that drastically reduces scribe GPU memory [13, 14, 15]. Therefore, ensuring the the size of the data structures that are targeted for CPU-side performance scalability of the virtualization features offered allocations. -
Compress/Decompress Encrypt/Decrypt
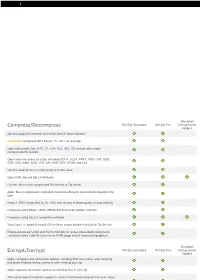
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

Word-Based Text Compression
WORD-BASED TEXT COMPRESSION Jan Platoš, Jiří Dvorský Department of Computer Science VŠB – Technical University of Ostrava, Czech Republic {jan.platos.fei, jiri.dvorsky}@vsb.cz ABSTRACT Today there are many universal compression algorithms, but in most cases is for specific data better using specific algorithm - JPEG for images, MPEG for movies, etc. For textual documents there are special methods based on PPM algorithm or methods with non-character access, e.g. word-based compression. In the past, several papers describing variants of word- based compression using Huffman encoding or LZW method were published. The subject of this paper is the description of a word-based compression variant based on the LZ77 algorithm. The LZ77 algorithm and its modifications are described in this paper. Moreover, various ways of sliding window implementation and various possibilities of output encoding are described, as well. This paper also includes the implementation of an experimental application, testing of its efficiency and finding the best combination of all parts of the LZ77 coder. This is done to achieve the best compression ratio. In conclusion there is comparison of this implemented application with other word-based compression programs and with other commonly used compression programs. Key Words: LZ77, word-based compression, text compression 1. Introduction Data compression is used more and more the text compression. In the past, word- in these days, because larger amount of based compression methods based on data require to be transferred or backed-up Huffman encoding, LZW or BWT were and capacity of media or speed of network tested. This paper describes word-based lines increase slowly. -

The Basic Principles of Data Compression
The Basic Principles of Data Compression Author: Conrad Chung, 2BrightSparks Introduction Internet users who download or upload files from/to the web, or use email to send or receive attachments will most likely have encountered files in compressed format. In this topic we will cover how compression works, the advantages and disadvantages of compression, as well as types of compression. What is Compression? Compression is the process of encoding data more efficiently to achieve a reduction in file size. One type of compression available is referred to as lossless compression. This means the compressed file will be restored exactly to its original state with no loss of data during the decompression process. This is essential to data compression as the file would be corrupted and unusable should data be lost. Another compression category which will not be covered in this article is “lossy” compression often used in multimedia files for music and images and where data is discarded. Lossless compression algorithms use statistic modeling techniques to reduce repetitive information in a file. Some of the methods may include removal of spacing characters, representing a string of repeated characters with a single character or replacing recurring characters with smaller bit sequences. Advantages/Disadvantages of Compression Compression of files offer many advantages. When compressed, the quantity of bits used to store the information is reduced. Files that are smaller in size will result in shorter transmission times when they are transferred on the Internet. Compressed files also take up less storage space. File compression can zip up several small files into a single file for more convenient email transmission. -

NXP Eiq Machine Learning Software Development Environment For
AN12580 NXP eIQ™ Machine Learning Software Development Environment for QorIQ Layerscape Applications Processors Rev. 3 — 12/2020 Application Note Contents 1 Introduction 1 Introduction......................................1 Machine Learning (ML) is a computer science domain that has its roots in 2 NXP eIQ software introduction........1 3 Building eIQ Components............... 2 the 1960s. ML provides algorithms capable of finding patterns and rules in 4 OpenCV getting started guide.........3 data. ML is a category of algorithm that allows software applications to become 5 Arm Compute Library getting started more accurate in predicting outcomes without being explicitly programmed. guide................................................7 The basic premise of ML is to build algorithms that can receive input data and 6 TensorFlow Lite getting started guide use statistical analysis to predict an output while updating output as new data ........................................................ 8 becomes available. 7 Arm NN getting started guide........10 8 ONNX Runtime getting started guide In 2010, the so-called deep learning started. It is a fast-growing subdomain ...................................................... 16 of ML, based on Neural Networks (NN). Inspired by the human brain, 9 PyTorch getting started guide....... 17 deep learning achieved state-of-the-art results in various tasks; for example, A Revision history.............................17 Computer Vision (CV) and Natural Language Processing (NLP). Neural networks are capable of learning complex patterns from millions of examples. A huge adaptation is expected in the embedded world, where NXP is the leader. NXP created eIQ machine learning software for QorIQ Layerscape applications processors, a set of ML tools which allows developing and deploying ML applications on the QorIQ Layerscape family of devices. -
Oak Park Area Visitor Guide
OAK PARK AREA VISITOR GUIDE COMMUNITIES Bellwood Berkeley Broadview Brookfield Elmwood Park Forest Park Franklin Park Hillside Maywood Melrose Park Northlake North Riverside Oak Park River Forest River Grove Riverside Schiller Park Westchester www.visitoakpark.comvisitoakpark.com | 1 OAK PARK AREA VISITORS GUIDE Table of Contents WELCOME TO THE OAK PARK AREA ..................................... 4 COMMUNITIES ....................................................................... 6 5 WAYS TO EXPERIENCE THE OAK PARK AREA ..................... 8 BEST BETS FOR EVERY SEASON ........................................... 13 OAK PARK’S BUSINESS DISTRICTS ........................................ 15 ATTRACTIONS ...................................................................... 16 ACCOMMODATIONS ............................................................ 20 EATING & DRINKING ............................................................ 22 SHOPPING ............................................................................ 34 ARTS & CULTURE .................................................................. 36 EVENT SPACES & FACILITIES ................................................ 39 LOCAL RESOURCES .............................................................. 41 TRANSPORTATION ............................................................... 46 ADVERTISER INDEX .............................................................. 47 SPRING/SUMMER 2018 EDITION Compiled & Edited By: Kevin Kilbride & Valerie Revelle Medina Visit Oak Park -

Dictionary Based Compression for Images
INTERNATIONAL JOURNAL OF COMPUTERS Issue 3, Volume 6, 2012 Dictionary Based Compression for Images Bruno Carpentieri Ziv and Lempel in [1]. Abstract—Lempel-Ziv methods were original introduced to By limiting what could enter the dictionary, LZ2 assures compress one-dimensional data (text, object codes, etc.) but recently that there is at most one instance for each possible pattern in they have been successfully used in image compression. the dictionary. Constantinescu and Storer in [6] introduced a single-pass vector Initially the dictionary is empty. The coding pass consists of quantization algorithm that, with no training or previous knowledge of the digital data was able to achieve better compression results with searching the dictionary for the longest entry that is a prefix of respect to the JPEG standard and had also important computational a string starting at the current coding position. advantages. The index of the match is transmitted to the decoder using We review some of our recent work on LZ-based, single pass, log N bits, where N is the current size of the dictionary. adaptive algorithms for the compression of digital images, taking into 2 account the theoretical optimality of these approach, and we A new pattern is introduced into the dictionary by experimentally analyze the behavior of this algorithm with respect to concatenating the current match with the next character that the local dictionary size and with respect to the compression of bi- has to be encoded. level images. The dictionary of LZ2 continues to grow throughout the coding process. Keywords—Image compression, textual substitution methods. -

Winzip 12 Reviewer's Guide
Introducing WinZip® 12 WinZip® is the most trusted way to work with compressed files. No other compression utility is as easy to use or offers the comprehensive and productivity-enhancing approach that has made WinZip the gold standard for file-compression tools. With the new WinZip 12, you can quickly and securely zip and unzip files to conserve storage space, speed up e-mail transmission, and reduce download times. State-of-the-art file compression, strong AES encryption, compatibility with more compression formats, and new intuitive photo compression, make WinZip 12 the complete compression and archiving solution. Building on the favorite features of a worldwide base of several million users, WinZip 12 adds new features for image compression and management, support for new compression methods, improved compression performance, support for additional archive formats, and more. Users can work smarter, faster, and safer with WinZip 12. Who will benefit from WinZip® 12? The simple answer is anyone who uses a PC. Any PC user can benefit from the compression and encryption features in WinZip to protect data, save space, and reduce the time to transfer files on the Internet. There are, however, some PC users to whom WinZip is an even more valuable and essential tool. Digital photo enthusiasts: As the average file size of their digital photos increases, people are looking for ways to preserve storage space on their PCs. They have lots of photos, so they are always seeking better ways to manage them. Sharing their photos is also important, so they strive to simplify the process and reduce the time of e-mailing large numbers of images. -

A Survey on Different Compression Techniques Algorithm for Data Compression Ihardik Jani, Iijeegar Trivedi IC
International Journal of Advanced Research in ISSN : 2347 - 8446 (Online) Computer Science & Technology (IJARCST 2014) Vol. 2, Issue 3 (July - Sept. 2014) ISSN : 2347 - 9817 (Print) A Survey on Different Compression Techniques Algorithm for Data Compression IHardik Jani, IIJeegar Trivedi IC. U. Shah University, India IIS. P. University, India Abstract Compression is useful because it helps us to reduce the resources usage, such as data storage space or transmission capacity. Data Compression is the technique of representing information in a compacted form. The actual aim of data compression is to be reduced redundancy in stored or communicated data, as well as increasing effectively data density. The data compression has important tool for the areas of file storage and distributed systems. To desirable Storage space on disks is expensively so a file which occupies less disk space is “cheapest” than an uncompressed files. The main purpose of data compression is asymptotically optimum data storage for all resources. The field data compression algorithm can be divided into different ways: lossless data compression and optimum lossy data compression as well as storage areas. Basically there are so many Compression methods available, which have a long list. In this paper, reviews of different basic lossless data and lossy compression algorithms are considered. On the basis of these techniques researcher have tried to purpose a bit reduction algorithm used for compression of data which is based on number theory system and file differential technique. The statistical coding techniques the algorithms such as Shannon-Fano Coding, Huffman coding, Adaptive Huffman coding, Run Length Encoding and Arithmetic coding are considered. -

Enhanced Data Reduction, Segmentation, and Spatial
ENHANCED DATA REDUCTION, SEGMENTATION, AND SPATIAL MULTIPLEXING METHODS FOR HYPERSPECTRAL IMAGING LEANNA N. ERGIN Bachelor of Forensic Chemistry Ohio University June 2006 Submitted in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY IN BIOANALYTICAL CHEMISTRY at the CLEVELAND STATE UNIVERSITY July 19th, 2017 We hereby approve this dissertation for Leanna N. Ergin Candidate for the Doctor of Philosophy in Clinical-Bioanalytical Chemistry degree for the Department of Chemistry and CLEVELAND STATE UNIVERSITY College of Graduate Studies ________________________________________________ Dissertation Committee Chairperson, Dr. John F. Turner II ________________________________ Department/Date ________________________________________________ Dissertation Committee Member, Dr. David W. Ball ________________________________ Department/Date ________________________________________________ Dissertation Committee Member, Dr. Petru S. Fodor ________________________________ Department/Date ________________________________________________ Dissertation Committee Member, Dr. Xue-Long Sun ________________________________ Department/Date ________________________________________________ Dissertation Committee Member, Dr. Yan Xu ________________________________ Department/Date ________________________________________________ Dissertation Committee Member, Dr. Aimin Zhou ________________________________ Department/Date Date of Defense: July 19th, 2017 Dedicated to my husband, Can Ergin. ACKNOWLEDGEMENT I would like to thank my advisor, -
Winzip 15 Matrix 4.Cdr
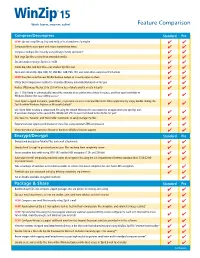
15 Feature Comparison NEW! Compress/Decompress Standard Pro NEW! Zip and unzip files quickly and easily with a brand new zip engine Compress files to save space and reduce transmission times Compress multiple files instantly using WinZip's handy Zip button* Split large Zip files so they fit on removable media Zip and unzip very large Zip files (>4GB) Create Zip, LHA, and Zipx files—our smallest Zip files ever Open and extract Zip, Zipx, RAR, 7Z, LHA BZ2, CAB, IMG, ISO, and most other compressed file formats NEW! Drag files onto the new WinZip Desktop Gadget to instantly zip/unzip them Utilize 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 to 25% with no loss of photo quality or data integrity Use '1-Click Unzip' to automatically extract the contents of an archive into a folder it creates, and then open that folder in Windows Explorer for easy editing access* 'Auto Open' a zipped document, spreadsheet, or presentation in its associated Microsoft Office application by simply double clicking the Zip file within Windows Explorer or Microsoft Outlook* Use 'Open With' to unzip a compressed file using the default Windows file association (or an application you specify), and, if you make changes to the opened file, WinZip will offer to save them back to the Zip file for you* Use 'Save As', 'Rename', and 'New Folder' commands to easily manage Zip files Experience faster zipping performance on most files using optional LZMA compression View international characters in filenames thanks to WinZip's Unicode support Encrypt/Decrypt Standard Pro Encrypt and decrypt confidential files and email attachments Simply check 'Encrypt' to password protect your files and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256-bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

About FOSS for Mac OS X (FREE)
Free and Open Source Software FREE for Mac OS X A selection of some of the best, yet totally free, software that’s available for the Mac, collected together on a single DVD… plus some bonus videos! Audio PrBoom Graphics First Person Shooter based on the Audacity original Doom. We’ve included Blender Simple sound recording and bonus IWADs from Freedoom. Fully integrated 3D graphics editing tool. creation suite allowing modeling, PySol Fan Club Edition animation, rendering, post- iPodDisk Collection of more than 1000 production, realtime interactive 3D Copy music off your iPod in the solitaire card games. There are and game creation and playback finder, just like a regular disk drive. games that use the 52 card with cross-platform compatibility - International Pattern deck, games all in one tidy, package! Games for the 78 card Tarock deck, eight and ten suit Ganjifa games, Seashore Aleph One Hanafuda games, Matrix games, Image editor that aims to serve the Engine for Bungie's free First Mahjongg games, and games for basic image editing needs of most Person Shooter series Marathon. an original hexadecimal-based computer users, but still has Play online, solo play with rich deck. features like gradients, textures and original story, many total Scorched 3D anti-aliasing for both text and conversions and thousands of brush strokes, as well as supporting Simple turn-based artillery game multiple layers and alpha channel maps. Includes Marathon, and also a real-time strategy game Marathon 2 & Marathon Infinity editing. It is based around the in which players can counter each GIMP's technology and uses the Armagetron Advanced others' weapons with other same native file format, but uses Multiplayer game in 3d that creative accessories, shields and Mac OS X native interface.