Small Area Estimation Approach
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
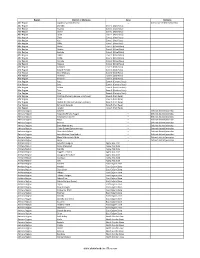
Districts of Ethiopia
Region District or Woredas Zone Remarks Afar Region Argobba Special Woreda -- Independent district/woredas Afar Region Afambo Zone 1 (Awsi Rasu) Afar Region Asayita Zone 1 (Awsi Rasu) Afar Region Chifra Zone 1 (Awsi Rasu) Afar Region Dubti Zone 1 (Awsi Rasu) Afar Region Elidar Zone 1 (Awsi Rasu) Afar Region Kori Zone 1 (Awsi Rasu) Afar Region Mille Zone 1 (Awsi Rasu) Afar Region Abala Zone 2 (Kilbet Rasu) Afar Region Afdera Zone 2 (Kilbet Rasu) Afar Region Berhale Zone 2 (Kilbet Rasu) Afar Region Dallol Zone 2 (Kilbet Rasu) Afar Region Erebti Zone 2 (Kilbet Rasu) Afar Region Koneba Zone 2 (Kilbet Rasu) Afar Region Megale Zone 2 (Kilbet Rasu) Afar Region Amibara Zone 3 (Gabi Rasu) Afar Region Awash Fentale Zone 3 (Gabi Rasu) Afar Region Bure Mudaytu Zone 3 (Gabi Rasu) Afar Region Dulecha Zone 3 (Gabi Rasu) Afar Region Gewane Zone 3 (Gabi Rasu) Afar Region Aura Zone 4 (Fantena Rasu) Afar Region Ewa Zone 4 (Fantena Rasu) Afar Region Gulina Zone 4 (Fantena Rasu) Afar Region Teru Zone 4 (Fantena Rasu) Afar Region Yalo Zone 4 (Fantena Rasu) Afar Region Dalifage (formerly known as Artuma) Zone 5 (Hari Rasu) Afar Region Dewe Zone 5 (Hari Rasu) Afar Region Hadele Ele (formerly known as Fursi) Zone 5 (Hari Rasu) Afar Region Simurobi Gele'alo Zone 5 (Hari Rasu) Afar Region Telalak Zone 5 (Hari Rasu) Amhara Region Achefer -- Defunct district/woredas Amhara Region Angolalla Terana Asagirt -- Defunct district/woredas Amhara Region Artuma Fursina Jile -- Defunct district/woredas Amhara Region Banja -- Defunct district/woredas Amhara Region Belessa -- -

Social and Environmental Risk Factors for Trachoma: a Mixed Methods Approach in the Kembata Zone of Southern Ethiopia
Social and Environmental Risk Factors for Trachoma: A Mixed Methods Approach in the Kembata Zone of Southern Ethiopia by Candace Vinke B.Sc., University of Calgary, 2005 A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of MASTER OF ARTS in the Department of Geography Candace Vinke, 2010 University of Victoria All rights reserved. This thesis may not be reproduced in whole or in part, by photocopy or other means, without the permission of the author. ii Supervisory Committee Social and Environmental Risk Factors for Trachoma: A Mixed Methods Approach in the Kembata Zone of Southern Ethiopia by Candace Vinke Bachelor of Science, University of Calgary, 2005 Supervisory Committee Dr. Stephen Lonergan, Supervisor (Department of Geography) Dr. Denise Cloutier-Fisher, Departmental Member (Department of Geography) Dr. Eric Roth, Outside Member (Department of Anthropology) iii Dr. Stephen Lonergan, Supervisor (Department of Geography) Dr. Denise Cloutier-Fisher, Departmental Member (Department of Geography) Dr. Eric Roth, Outside Member (Department of Anthropology) Abstract Trachoma is a major public health concern throughout Ethiopia and other parts of the developing world. Control efforts have largely focused on the antibiotic treatment (A) and surgery (S) components of the World Health Organizations (WHO) SAFE strategy. Although S and A efforts have had a positive impact, this approach may not be sustainable. Consequently, this study focuses on the latter two primary prevention components; facial cleanliness (F) and environmental improvement (E). A geographical approach is employed to gain a better understanding of how culture, economics, environment and behaviour are interacting to determine disease risk in the Kembata Zone of Southern Ethiopia. -

Soil Micronutrients Status Assessment, Mapping and Spatial Distribution of Damboya, Kedida Gamela and Kecha Bira Districts, Kambata Tambaro Zone, Southern Ethiopia
Vol. 11(44), pp. 4504-4516, 3 November, 2016 DOI: 10.5897/AJAR2016.11494 Article Number: C2000C461481 African Journal of Agricultural ISSN 1991-637X Copyright ©2016 Research Author(s) retain the copyright of this article http://www.academicjournals.org/AJAR Full Length Research Paper Soil micronutrients status assessment, mapping and spatial distribution of Damboya, Kedida Gamela and Kecha Bira Districts, Kambata Tambaro zone, Southern Ethiopia Alemu Lelago Bulta1*, Tekalign Mamo Assefa2, Wassie Haile Woldeyohannes1 and Hailu Shiferaw Desta3 1School of Plant and Horticulture Science, Hawassa University, Ethiopia. 2Ethiopia Agricultural Transformation Agency (ATA), Ethiopia. 3International Food Policy Research Institute (IFPRI), Addis Ababa, Ethiopia. Received 29 July, 2016; Accepted 25 August, 2016 Micronutrients are important for crop growth, production and their deficiency and toxicity affect crop yield. However, the up dated information about their status and spatial distribution in Ethiopian soils is scarce. Therefore, fertilizer recommendation for crops in the country has until recently focused on nitrogen and phosphorus macronutrients only. But many studies have revealed the deficiency of some micronutrients in soils of different parts of Ethiopia. To narrow this gap, this study was conducted in Kedida Gamela, Kecha Bira and Damboya districts of Kambata Tambaro (KT) Zone, Southern Ethiopia, through assessing and mapping the status and spatial distribution of micronutrients. The micronutrients were extracted by using Mehlich-III multi-nutrient extraction method and their concentrations were measured by using Inductively Coupled Plasma Optical Emission Spectrometer (ICP-OES). The fertility maps and predication were prepared by co-Kriging method using Arc map 10.0 tools and the status of Melich-III extractable iron (Fe), Zinc (Zn), boron (B), copper (Cu) and molybdenum (Mo) were indicated on the map. -

Annual Report 2018
1. ORGANIZATIONAL BACKGROUND 1.1. Establishment / Organizational Aspiration: Love In Action Ethiopia/LIA-E/ is an indigenous, not-for-profit, non-governmental charitable organization established and registered in 2001 with the ministry of Justice and re-registered on October 30, 2009 with Charities and Societies Agency of Federal Democratic Republic of Ethiopia as an Ethiopian Residents Charity. Love In Action Ethiopia was established with a view to serving the poorest, underserved, most vulnerable, most at risk, and marginalized segments of the population; including children, youth and women. Over the years, LIAE has grown to serve its target beneficiaries through participatory development programs focusing on creating access to quality educations for children and adults; HIV/AIDS prevention, care and support; and capacity development. All through its periods of struggles, LIAE has grown beyond simply raising awareness and developing skills into rendering more sustainable and meaningful solutions for the multifaceted socio-economic problems of the community and in turn start to save life of the generation. 1.2. VISION: Love In Action Ethiopia aspires to see improved life in the rural (remote) and urban areas by the effort of the people themselves, and with the minimum external intervention. 1.3. MISSION: LIA Ethiopia is committed to bring sustainable change and transformation among the society through concerned effort of the community and genuine participation of all stakeholders. LIA Ethiopia, at its heart of activities promotes peoples’ awareness so as to enable them participate meaningfully and practically in the development processes of their locality, region and nation. 1.4. PROGRAM FOCUS: a. Education And Skills Development Program (ESDP): The key aspects which ESDP are focusing are: Creating Access to Education Improving Quality of Education Services Page 1 Increasing Educational Efficiency Ensuring Equity b. -

Addis Ababa University School of Graduate Studies Department of Earth Sciences
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES DEPARTMENT OF EARTH SCIENCES APPLICATION OF GIS AND REMOTE SENSING FOR FLOOD HAZARD AND RISK ANALYSIS: THE CASE OF BOYO CATCHMENT. Destaye Gobena June, 2009 ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES DEPARTMENT OF EARTH SCIENCES APPLICATION OF GIS AND REMOTE SENSING FOR FLOOD HAZARD AND RISK ANALYSIS: THE CASE OF BOYO CATCHMENT. Destaye Gobena A Thesis Submitted to the School of Graduate Studies of Addis Ababa University in the Partial Fulfillment of the Requirements for the Degree of Masters of Science in GIS and Remote Sensing ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES DEPARTMENT OF EARTH SCIENCES APPLICATION OF GIS AND REMOTE SENSING FOR FLOOD HAZARD AND RISK ANALYSIS: THE CASE OF BOYO CATCHMENT. Destaye Gobena APPROVED BY EXAMINING BOARD: SIGNATURE Balemwal Atnafu (Ph.D.) ______________________________ Chairman, Department Graduate Committee K.V. Suryabhagavan (Ph.D.) ______________________________ Advisor Mekuriya Argaw (Ph.D.) ______________________________ Examiner Balemwal Atnafu (Ph.D.) ______________________________ Examiner ii Acknowledgement The achievement of this paper has come through the overwhelming help of many people. I wish to express my sincere gratitude to all those who offered their kind corporation and guidance throughout my project period. First and for most, I would like to thank Jesus for his provisions, protections and support in my entire life. I would like to convey my sincere gratitude to my advisor Dr. K.V. Suryabhagavan for his guidance and constant encouragement. My deeper gratitude goes to my advisor, Prof. M. Balkrishnan who patiently corrected the manuscript and provided me valuable comments. I remain indebted to the Addis Ababa university community in general and the Department of Earth Sciences staff in particular for their cooperation during my stay in this campus. -

Ediget Ayele Final Thesis
ADDIS ABABA UNIVERISTY COLLEGE OF HUMANITIES LANGUAGE STUDIES JOURNALISM AND COMMUNICATION DEPARTMENT OF LINGUISTICS CORONATION AND TRADITIONAL ADMINISTRATIVE SYSTEM OF THE DONGA PEOPLE BY EDGET AYELE WORKU ADDIS ABABA, ETHIOPIA JUNE, 2015 0 CORONATION AND TRADITIONAL ADMINISTRATIVE SYSTEM OF THE DONGA PEOPLE BY EDGET AYELE A THESIS SUBMITTED TO COLLEGE OF HUMANITIES, LANGUAGE STUDIES, JOURNALISM AND COMMUNICATION DEPARTMENT OF DOCUMENTARY LINGUISTICS AND CULTURE IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR DEGREE OF MASTER OF ARTS (DOCUMENTARY LINGUISTICS AND CULTURE) ADDIS ABABA UNIVERSITY ADDIS ABABA, ETHIOPIA JUNE, 2015 1 Addis Ababa University College of Humanities, Language Studies, Journalism and Communication Department of Linguistics Signed by Examining Committee: ADVISOR SIGNATURE DATE EXAMINER SIGNATURE DATE EXAMINER SIGNATURE DATE Addis Ababa, Ethiopia June, 2015 0 DECLARATION I, the undersigned graduate student, declare that this thesis is my original work and that all sources of materials used in this thesis have been duly acknowledged. Name: Edget Ayele Worku Signature: Date: This thesis has been submitted for examination with my approval as a University Advisor. Name: Ahmed Hassen (PhD) Signature: Date: Place: College of Humanities, Language Studies, Journalism and Communication Department of Linguistics. Date of Submission, Addis Ababa, University Addis Ababa, Ethiopia 0 ABSTRACT This thesis describes the coronation rituals and traditional administrative systems of Donga People, who lives in southern part of Ethiopia. It further investigates the roles of traditional institutions; the community’s perceptions towards their traditional administrative system and other related socio-cultural events. To achieve this goal primary and secondary data were used. The data were collected through observation, informal and formal interviews, focus group discussions and reviewing available primary and secondary sources. -

Ethiopia: Administrative Map (August 2017)
Ethiopia: Administrative map (August 2017) ERITREA National capital P Erob Tahtay Adiyabo Regional capital Gulomekeda Laelay Adiyabo Mereb Leke Ahferom Red Sea Humera Adigrat ! ! Dalul ! Adwa Ganta Afeshum Aksum Saesie Tsaedaemba Shire Indasilase ! Zonal Capital ! North West TigrayTahtay KoraroTahtay Maychew Eastern Tigray Kafta Humera Laelay Maychew Werei Leke TIGRAY Asgede Tsimbila Central Tigray Hawzen Medebay Zana Koneba Naeder Adet Berahile Region boundary Atsbi Wenberta Western Tigray Kelete Awelallo Welkait Kola Temben Tselemti Degua Temben Mekele Zone boundary Tanqua Abergele P Zone 2 (Kilbet Rasu) Tsegede Tselemt Mekele Town Special Enderta Afdera Addi Arekay South East Ab Ala Tsegede Mirab Armacho Beyeda Woreda boundary Debark Erebti SUDAN Hintalo Wejirat Saharti Samre Tach Armacho Abergele Sanja ! Dabat Janamora Megale Bidu Alaje Sahla Addis Ababa Ziquala Maychew ! Wegera Metema Lay Armacho Wag Himra Endamehoni Raya Azebo North Gondar Gonder ! Sekota Teru Afar Chilga Southern Tigray Gonder City Adm. Yalo East Belesa Ofla West Belesa Kurri Dehana Dembia Gonder Zuria Alamata Gaz Gibla Zone 4 (Fantana Rasu ) Elidar Amhara Gelegu Quara ! Takusa Ebenat Gulina Bugna Awra Libo Kemkem Kobo Gidan Lasta Benishangul Gumuz North Wello AFAR Alfa Zone 1(Awsi Rasu) Debre Tabor Ewa ! Fogera Farta Lay Gayint Semera Meket Guba Lafto DPubti DJIBOUTI Jawi South Gondar Dire Dawa Semen Achefer East Esite Chifra Bahir Dar Wadla Delanta Habru Asayita P Tach Gayint ! Bahir Dar City Adm. Aysaita Guba AMHARA Dera Ambasel Debub Achefer Bahirdar Zuria Dawunt Worebabu Gambela Dangura West Esite Gulf of Aden Mecha Adaa'r Mile Pawe Special Simada Thehulederie Kutaber Dangila Yilmana Densa Afambo Mekdela Tenta Awi Dessie Bati Hulet Ej Enese ! Hareri Sayint Dessie City Adm. -

Periodic Monitoring Report Working 2016 Humanitarian Requirements Document – Ethiopia Group
DRMTechnical Periodic Monitoring Report Working 2016 Humanitarian Requirements Document – Ethiopia Group Covering 1 Jan to 31 Dec 2016 Prepared by Clusters and NDRMC Introduction The El Niño global climactic event significantly affected the 2015 meher/summer rains on the heels of failed belg/ spring rains in 2015, driving food insecurity, malnutrition and serious water shortages in many parts of the country. The Government and humanitarian partners issued a joint 2016 Humanitarian Requirements Document (HRD) in December 2015 requesting US$1.4 billion to assist 10.2 million people with food, health and nutrition, water, agriculture, shelter and non-food items, protection and emergency education responses. Following the delay and erratic performance of the belg/spring rains in 2016, a Prioritization Statement was issued in May 2016 with updated humanitarian requirements in nutrition (MAM), agriculture, shelter and non-food items and education.The Mid-Year Review of the HRD identified 9.7 million beneficiaries and updated the funding requirements to $1.2 billion. The 2016 HRD is 69 per cent funded, with contributions of $1.08 billion from international donors and the Government of Ethiopia (including carry-over resources from 2015). Under the leadership of the Government of Ethiopia delivery of life-saving and life- sustaining humanitarian assistance continues across the sectors. However, effective humanitarian response was challenged by shortage of resources, limited logistical capacities and associated delays, and weak real-time information management. This Periodic Monitoring Report (PMR) provides a summary of the cluster financial inputs against outputs and achievements against cluster objectives using secured funding since the launch of the 2016 HRD. -

Demonstration and Evlauation of Based Oxen Fattening in Kachabira
Gemiyo D, et al. J Agron Agri Sci 2021, 4: 029 DOI: 10.24966/AAS-8292/100029 HSOA Journal of Agronomy & Agricultural Science Research Article Introduction Demonstration and Evlauation of The livestock sector contributes considerably to Ethiopian Ensete venrticosum economy, yet productivity is not equivocally responded to the livestock Enset Corm ( ) popupation of the country. It is eminent that livestock products and by-products in the form of meat, milk, honey, eggs, cheese, and butter Based Oxen Fattening in supply etc. provide valuable protein that contributes to improve the Kachabira and Lemu Districts, nutritional status of the peoples of the country [1]. The livestock population of the country was estimated to be about 60 million cattle, Southern Ethiopia 31.3 million sheep, 32.74 million goats, 1.42 million camels in the sedentary areas of the country and poultry estimated to be about 56.87 million [1]. Deribe Gemiyo1*, Zekarias Bassa1 and Tesfaye Alemu2 Despite huge potential of livestock population and its diversity, the 1Southern Agricultural Research Institute (SARI), Areka, Ethiopia benefits obtained from the sector are low compared to other African 2Oromiya Agricultural Research Institute (OARI), Adami Tulu Agriculutrual countries and the World standard. Asfaw et al., Berhanu and Pavanello Research Centre, Ziway, Ethiopia [2-4] reported that on average beef yield per animal is 108.4 kg, which is by far lower than other African countries, 119 kg for Sudan, 146 kg for Kenya, 127 kg for Eastern Africa, 146 kg for Africa, and 205 kg for the world. The number of off take rate is also lower than Abstract other African countries [1]. -

Assessment of Small Ruminant Production System in Hadero Tunto
ASSESSMENT OF SMALL RUMINANT PRODUCTION SYSTEM IN HADERO TUNTO ZURIYA WOREDA IN KEMBATA TEMBARO ZONE OF SOUTHERN ETHIOPIA AND ON-FARM EVALUATION OF REPLACEMENT VALUE OF COWPEA (Vigna Unguiculata) HAY FOR CONCENTRATE MIX ON PERFORMANCE OF SHEEP FED NAPIER GRASS (Pennisetum Purpureum) AS BASAL DIET M.SC. THESIS MEKEYA BEDRU HAWASSA UNIVERSITY Collage of Agriculture Hawassa, Ethiopia November, 2018 ASSESSMENT OF SMALL RUMINANT PRODUCTION SYSTEM IN HADERO TUNTO ZURIYA WOREDA IN KEMBATA TEMBARO ZONE OF SOUTHERN ETHIOPIA AND ON-FARM EVALUATION OF REPLACEMENT VALUE OF COWPEA (Vigna Unguiculata) HAY FOR CONCENTRATE MIX ON PERFORMANCE OF SHEEP FED NAPIER GRASS (Pennisetum Purpureum) AS BASAL DIET MEKEYA BEDRU KEDIR MAJOR-ADVISOR: AJEBU NURFETA (PROFESSOR, PhD) CO-ADVISOR: ADUGNA TOLERA (PROFESSOR, PhD) CO-ADVISOR: MELKAMU BEZABIH (PhD) A THESIS SUBMITTED TO THE SCHOOL OF ANIMAL AND RANGE SCIENCES, HAWASSA UNIVERSITY COLLEGE OF AGRICULTURE IN PARTIAL FULFILLMENT OF THE REQUIREMENTS OF THE DEGREE OF MASTER OF SCIENCE IN ANIMAL AND RANGE SCIENCES (SPECIALIZATION: ANIMAL NUTRITION) Hawassa, Ethiopia November, 2019 SCHOOL OF GRADUATE STUDIES Hawassa University Advisor's Approval Sheet (Submission sheet -1) This is to certify that the thesis entitled “Assessment of Small Ruminant Production System in Hadero Tunto Zuriya Woreda in Kembata Tembaro Zone of Southern Ethiopia and On Farm Evaluation of Replacement Value of Cowpea (Vigna unguiculata) Hay for Concentrate Mix on Performance of Sheep Fed Napier Grass (Pennisetum purpureum) As Basal Diet” Submitted in Partial Fulfillment of The Requirements for The Degree of Master with Specialization in Animal Nutrition, the Graduate Program of School of Animal and Range Science, and has been carried out by Mekeya Bedru Kedir, under our supervision. -

Annual Report IOM PRESENCE in ETHIOPIA IOM Presence in Ethiopia ETHIOPIA: Administrative Map (As of 14 January 2011)
IOM Ethiopia 2018Annual Report IOM PRESENCE IN ETHIOPIA IOM Presence in Ethiopia ETHIOPIA: Administrative Map (as of 14 January 2011) R ShireERITREA E Legend Tahtay Erob Laelay Adiyabo Mereb Ahferom Gulomekeda \\( Adiyabo Leke D National Capital Ganta Medebay Dalul North Adwa Afeshum Saesie Tahtay Zana Laelay Tsaedaemba Kafta Western Maychew PP Koraro Central Humera Asgede Tahtay Eastern Regional Capital Naeder Werei Hawzen Western Tsimbila Maychew Adet Leke Koneba Berahle Welkait Kelete Atsbi S Tigray Awelallo Wenberta International Boundary Tselemti Kola Degua Tsegede Mekele E Temben Temben P Addi Tselemt Tanqua Afdera Zone 2 Enderta Arekay Abergele Regional Boundary Tsegede Beyeda Ab Ala MRCMirab Saharti A Armacho Debark Samre Hintalo Erebti Abergele Wejirat Tach Megale Bidu Zonal Boundary Armacho Dabat Janamora Alaje Lay Sahla North Armacho Wegera Southern Ziquala Woreda Boundary Metema Gonder Sekota Endamehoni Raya Wag Azebo Chilga Yalo Amhara East Ofla Teru West Belesa Himra Kurri Gonder Dehana Belesa Lake Dembia Zuria Gaz Alamata Zone 4 Quara Gibla Semera Elidar Takusa Libo Ebenat Gulina Kemkem Bugna Lasta Kobo Awra Afar Gidan Lake Tana South (Ayna) 0 50 100 200 km Ewa Alfa Fogera Gonder North ¹ Lay Zone 1 Farta Meket Guba Lafto Dubti Gayint MRC Asayta Semen Wollo P Jawi Achefer Tach Habru Chifra Bahr Dar East Wadla Delanta G U L F O F A D E N P Gayint Aysaita Creation date:14 Jan.2011 Dera Esite Bahirdar Ambasel Map Doc Name:21_ADM_000_ETH_011411_A0 Debub Zuria Dawunt Worebabu Achefer West Sources:CSA,EMA Dangura Pawe Esite Simada Tenta Adaa'r Mile Mecha Yilmana Afambo Guba Special Kutaber Feedback:[email protected] http;//ochaonline.un.org/ethiopia Dangila Densa Mekdela Bati DJIBOUTI SUDAN Metekel West Thehulederie The boundaries and names shown and the designations used on Telalak Fagta Lakoma Gonje ADDIS ABABADessie Gojam Sayint Zuria Kalu this map do not imply official endorsement or acceptance by the Sirba Mandura Hulet Goncha South Zone Sekela Quarit Mehal Asossa Abay Banja Dega Ej Enese Siso Argoba United Nations. -

Ethiopia: SNNP Region Administrative Map (As of 15 Aug 2017)
Ethiopia: SNNP region administrative map (as of 15 Aug 2017) ! ! ! ! ! ! ! ! ! Suten ! ! ! ! ! ! Inge Sodo ! ! !Bui ! ! WelikiteKebena Abeshege ! Kokir Gedbano ! ! Kela ! ! Muhur Na Ak!lil ! Gubire ! ! ! Cheha Agena ! Imdibir! ! Ezha Me!skan ! ! Inseno ! Gonichire ! ! ! Kibet Qewaqoto! Koshe ! ! ! ! ! ! ! Enemorina Eaner Alicho Woriro ! Gumer Mareko ! Selti ! ! Areket Alkeso town ! ! ! ! ! ! Geta Kose Tora ! Fofa ! Werabe ! ! ! Dinkela ! ! Sayilem! ! ! ! ! Yadota Geja Endiguagn Yem SP Woreda ! Dalocha ! Misrak Azenet Berbere ! ! ! ! Misha !LERA Dalocha Masha ! Wilb!areg Gibe ! ! Mierab Azenet Berbere ! ! Lanfero ! Homec!ho ! ! Fonqo town ! Mito ! GAMBELA Gesha (Deka) Kondo GECHA TOWN ! Analemmo ! ! !Deka ! Doesha !Belesa town ! Alem Gebeya Anderacha Getawa Gembora ! ! Limu ! ! Bonosha Sankura ! ! ! Lisana town Jajira Shashogo Gimbichu! ! Hufa ! ! ! Diri Soro ! Gojeb Bita (Big) Gimbo Doya Gena Jacho A!nigach!a ! Alaba SP Woreda ! ! ! Daniboya Wishiwishi Dune Kulito ! Kaka Idget ! Bita Genet ! OROMIA Kelata Mudula Hobichaka ! ! Bonga ! ! ! ! ! Yeki ! Menjiwo ! Chena Tembaro Ke!diada Gambela TEPI TOWN Hadero !TubitoKacha Bira ! ! ! !Adilo Chda Idge T!unito ! Legend WACHA ! ! Terche Misrak Badawacho ! Gena Bosa Chiri BOMIBE 01 ! ! ! ! !Karewo ! Mierab Badawacho ! Ameya P ! Tocha Tocha Edget Boloso Bombe Sheka Tulo ! Regional capital ! Waka ! Semen Bench Alem Gena ! ! ! ! Mehal Sheko Mareka Boloso SoreDamot Pulasa Hawassa Zuria PWondo-Ge! net Gesa ! ! Shanito Hawasa Town ! ! ! ! Shama Chuko Shay Bench ! Bitena Town Mizan Aman ! ! Tula ! Damot