Text Annotation with Opennlp and UIMA
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Pharmacy Product System – National (Pps-N) Installation Guide
PHARMACY PRODUCT SYSTEM – NATIONAL (PPS-N) INSTALLATION GUIDE December 2016 Version 1.2 Department of Veterans Affairs Office of Information and Technology (OIT) PPS-N Installation Guide v1.2 i December 2016 Revision History Date Version Revised Description Author Pages November 1.2 All Updated content with installation REDACTED. HPE 2016 instructions for Fixed Medication Copay FMCT Team. Tiers (FMCT) Release 1.2. May 2015 1.1.02 Updated date and version number to 1.1.02. Enterprise Updated the PPS-N EAR file name. Application Maintenance August 1.1.01 Updated version number to 1.1.01, updated Enterprise 2014 the PPS-N EAR file name and the PPSNS Application MUMPS KIDS file name. Maintenance Added instructions to Undeploy the application. And made some formatting changes. November 1.0.01 Updated version number to 1.0.01, updated Enterprise 2013 the PPS-N EAR file name and the PPSNS Application MUMPS KIDS file name. Maintenance January 1.0 Updated document to modify formatting SwRI 2013 based on NRR Review. December 1.0 No applicable updates for this document SwRI 2012 November 1.0 Updated section 10.5.1 to include a SwRI 2012 reference to other applications updating the image folder October 1.0 Version 1.0 updates SwRI 2012 September 1.0 Version 1.0 SwRI 2012 PPS-N Installation Guide v1.2 ii December 2016 TABLE OF CONTENTS 1 PROJECT SCOPE ....................................................................................................................... 1 1.1 Project Identification ..................................................................................................................... -

Apache Ant Best Practices
08_Lee_ch05.qxd 5/3/06 5:12 PM Page 81 C HAPTER 5 Apache Ant Best Practices This chapter looks in more detail at some best practices for using Ant on real projects. First I describe the use of property files to enable configuration of the build process depending on a user’s role and requirements. I then describe how best to integrate Ant with IBM Rational ClearCase. Finally, I look at some general best practices for supporting the build process on large projects. Aims of This Chapter Apache Ant is a powerful build tool with significant built-in capabilities. However, a few capabil- ities and best practices stand out; they are described here. After reading this chapter, you will be able to • Understand what Ant property files are and how they can be used to make build scripts more maintainable. • Understand how to use Ant’s capabilities to better integrate with IBM Rational ClearCase. • Implement Ant build files that support reuse and maintainability on large projects. This chapter assumes that you are familiar with the basic concepts of Apache Ant that were discussed in Chapter 4, “Defining Your Build and Release Scripts.” Property Files From the perspective of Chapter 4, an Ant build.xml file is a single centralized build file that defines a repeatable process for bringing together an application, usually producing some form of 81 08_Lee_ch05.qxd 5/3/06 5:12 PM Page 82 82 Chapter 5 Apache Ant Best Practices executable output. Although a single build.xml file can be enough to drive the build process, in practice it can quickly become large and unwieldy. -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -
Building Applications Using Arcweb Services with Open Source Tools by Amar J
Building Applications Using ArcWeb Services with Open Source Tools By Amar J. Das, Senior Programmer, NSTAR This tutorial for ArcWeb Services V2 provides The version numbers will most likely Creating the Ant Build File instructions on how to build an application be different from those shown in the Ant allows developers to automate the that incorporates ArcWeb Services using open illustration. application build process. Instructions for Ant source software. The tools Axis and Ant are 4. Click Finish and the Eclipse project is are assembled in an XML file. The default used, and Eclipse was chosen as the integrated set up. name of this file is build.xml, but any name can development environment (IDE). This article be chosen for the build file. does not attempt to explain core concepts of Web services or tools such as Apache Ant. Software Version URL Except for ArcWeb Services, all other software used for development is available freely on the Java SDK 1.5.0_03 www.sun.com Internet. The complete version of all listings Eclipse 3.1.0 www.eclipse.org referenced in this article is available from ArcUser Online at www.esri.com/arcuser. Ant 1.6.2 ant.apache.org Java software development kit (SDK) can Axis 1.2.1 ws.apache.org/axis be downloaded from Sun’s Web site. Setup is Java Activation self-explanatory, and installing the Eclipse SDK 1.0.2 java.sun.com/products/javabeans/glasgow/jaf.html Framework will also install Ant. Axis will generate error messages if it does not find activation.jar in Software needed for this exercise the classpath. -

Silk Test 20.5
Silk Test 20.5 Silk4J User Guide Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com © Copyright 1992-2019 Micro Focus or one of its affiliates. MICRO FOCUS, the Micro Focus logo and Silk Test are trademarks or registered trademarks of Micro Focus or one of its affiliates. All other marks are the property of their respective owners. 2019-10-23 ii Contents Welcome to Silk4J 20.5 ....................................................................................10 Licensing Information ......................................................................................11 Silk4J ................................................................................................................ 12 Do I Need Administrator Privileges to Run Silk4J? ........................................................... 12 Best Practices for Using Silk4J ........................................................................................ 12 Automation Under Special Conditions (Missing Peripherals) ............................................13 Silk Test Product Suite ...................................................................................................... 14 What's New in Silk4J ........................................................................................16 Save Time and Costs with Service Virtualization for Mobile Devices ............................... 16 Enhance Security with Java-based Encryption ................................................................. 16 Usability Enhancements -

ANT Tutorial Ashley J.S Mills
ANT Tutorial Ashley J.S Mills <[email protected]> Copyright © 2005 The University Of Birmingham Table of Contents 1.Introduction ................................................................................................................................................. 1 2.AntInstallation............................................................................................................................................. 1 3.AntBasics ................................................................................................................................................... 1 4.ATypicalProject .......................................................................................................................................... 3 5.ABitAboutFileSets ..................................................................................................................................... 7 6.AdvancedTopics .......................................................................................................................................... 9 6.1.FlowOfControl ................................................................................................................................. 9 7.References................................................................................................................................................... 12 1. Introduction Imagine that you are working on a large project. The project is a Java project and consists of many .java files. It consists of classes that are dependent -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Apache Geronimo Uncovered a View Through the Eyes of a Websphere Application Server Expert
Apache Geronimo uncovered A view through the eyes of a WebSphere Application Server expert Skill Level: Intermediate Adam Neat ([email protected]) Author Freelance 16 Aug 2005 Discover the Apache Geronimo application server through the eyes of someone who's used IBM WebSphere® Application Server for many years (along with other commercial J2EE application servers). This tutorial explores the ins and outs of Geronimo, comparing its features and capabilities to those of WebSphere Application Server, and provides insight into how to conceptually architect sharing an application between WebSphere Application Server and Geronimo. Section 1. Before you start This tutorial is for you if you: • Use WebSphere Application Server daily and are interested in understanding more about Geronimo. • Want to gain a comparative groundwork understanding of Geronimo and WebSphere Application Server. • Are considering sharing applications between WebSphere Application Server and Geronimo. • Simply want to learn and understand what other technologies are out there (which I often do). Prerequisites Apache Geronimo uncovered © Copyright IBM Corporation 1994, 2008. All rights reserved. Page 1 of 23 developerWorks® ibm.com/developerWorks To get the most out of this tutorial, you should have a basic familiarity with the IBM WebSphere Application Server product family. You should also posses a general understanding of J2EE terminology and technologies and how they apply to the WebSphere Application Server technology stack. System requirements If you'd like to implement the two technologies included in this tutorial, you'll need the following software and components: • IBM WebSphere Application Server. The version I'm using as a base comparison is IBM WebSphere Application Server, Version 6.0. -

Ontology Management (ONT) Cell
Informatics for Integrating Biology and the Bedside i2b2 Installation Guide Ontology Management (ONT) Cell Document Version: 1.4.2 I2b2 Software Version: 1.4 Table of Contents About this Guide______________________________________________________________ 3 1. Prerequisites _____________________________________________________________ 4 1.1 Required Software __________________________________________________________ 4 1.1.1 Java JDK_________________________________________________________________________4 1.1.2 JBoss 4.2.2GA ____________________________________________________________________4 1.1.3 Apache Ant 1.6.5 __________________________________________________________________5 1.1.4 Apache Axis2 1.1 __________________________________________________________________5 1.1.5 Oracle Express Edition ______________________________________________________________5 1.1.6 Update Environment Variables________________________________________________________6 1.1.7 Data Installation or Upgrade__________________________________________________________6 2. Install __________________________________________________________________ 7 2.1 Installing the Ontology Management (ONT) Cell _________________________________ 7 2.1.1 Download and Extract Source Code____________________________________________________7 2.1.2 Stop Services _____________________________________________________________________7 2.1.2.1 JBoss _______________________________________________________________________7 2.1.3 Deploy edu.harvard.i2b2.common _____________________________________________________7 -
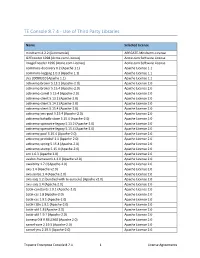
TE Console 8.7.4 - Use of Third Party Libraries
TE Console 8.7.4 - Use of Third Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 (Apache 1.1) Apache License 1.1 commons-logging 1.0.3 (Apache 1.1) Apache License 1.1 jrcs 20080310 (Apache 1.1) Apache License 1.1 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-broker 5.15.4 (Apache-2.0) Apache License 2.0 activemq-camel 5.15.4 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-client 5.15.4 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.15.4 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.15.4 (Apache-2.0) Apache License 2.0 activemq-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.15.4 (Apache-2.0) Apache License 2.0 activemq-stomp 5.15.4 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache 2.0) Apache License 2.0 axis-saaj 1.2 [bundled with te-console] (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache 2.0) Apache License 2.0 batik-constants -

Powerful Browser Detection and Custom JSP Tags with Geronimo Use Geronimo and Jetty to Create a Browser and OS Detection Scheme
Powerful browser detection and custom JSP tags with Geronimo Use Geronimo and Jetty to create a browser and OS detection scheme Skill Level: Intermediate Daniel Wintschel ([email protected]) Author and developer Freelance 13 Sep 2005 Learn how to take advantage of Apache Geronimo and Jetty to create a powerful browser and open source detection scheme. In addition to the open source (OS) Geronimo application server, this tutorial shows you how to use freely available JavaScript programs to perform browser and OS detection on the client side. Section 1. Before you start This tutorial is for developers who would like to implement some form of a browser detection API into an application. You can take advantage of Geronimo as the Java™ 2 Platform, Enterprise Edition (J2EE) application server (specifically its use of Jetty as a servlet container) as well as some client-side JavaScript. You'll be developing a few separate Java-based components including a servlet filter and two custom JavaServer Pages (JSP) tags. You'll use Apache Ant as a build tool to build the .war file that you'll deploy to Geronimo, so some familiarity with Ant is handy. You should be familiar with the concepts of filters and JSP tag libraries, and feel comfortable reading Java source code. By the end of this tutorial, you should have an idea of how to develop your own basic servlet filters and JSP tag libraries, and be able to implement a robust browser detection API into a J2EE application with the Apache Geronimo application server. About this tutorial Powerful browser detection and custom JSP tags with Geronimo © Copyright IBM Corporation 1994, 2008. -

(F/K/A LCCP) Open Source Disclosure
Below are the licenses for open source software used in the LCCP product and platform. You may download certain source code (as required by applicable licenses below) from verizon.com/opensource. 1. Xerces 3.1.1 2. Libtins 3. G3log v1.1 4. Winpcap v4.1.0.902 5. jersey-container-servlet-core 2.23.1 6. jersey-media-moxy 2.23.1 7. jersey-container-servlet 2.7 8. jersey-media-multipart 2.23.2 9. jersey-media-json-jackson 2.23.2 10. derby 10.12.1.1 11. Log4j 1.2.17 12. quartz 2.2.1 13. jetty-server/jetty-servlet/jetty-webapp 9.2.3.v20140905 14. commons-dbcp 1.4 15. json 20160810 16. gson 2.7 17. mimepull 1.9.3 18. poi 3.15 19. poi-ooxml 3.15 20. ibatis-sqlmap 2.3.0 21. commons-net 3.4 22. commons-lang 3 23. Angular JS/Angular Cookies/Angular Routes/Angular Sanitize 1.5.7 24. Angular ToolTips 1.1.7 25. Google Material Design 26. jQuery v3.0 27. ngDraggable 28. Simple Pagination 29. Animation 3.5.1 30. Freemarker library 2.3.25 31. jetty-runner 9 32. jersey-client 1.8 33. jersey-core 1.8 34. jackson-core-asl-1.7.1 35. jackson-mapper-asl-1.7.1 36. device-api 0.3.2 37. ddmlib 24.5.0 38. ADB 39. AdbWinAPI.dll 40. NVD 3 1.8.1 41. JSCH – 0.1.55 42. Libssh2 – 0.74 43. COMMON DEVELOPMENT AND DISTRIBUTION LICENSE (CDDL) Version 1.1 44.