Rbfopt: an Open-Source Library for Black-Box Optimization with Costly Function Evaluations
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

A Hybrid Global Optimization Method: the One-Dimensional Case Peiliang Xu
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Journal of Computational and Applied Mathematics 147 (2002) 301–314 www.elsevier.com/locate/cam A hybrid global optimization method: the one-dimensional case Peiliang Xu Disaster Prevention Research Institute, Kyoto University, Uji, Kyoto 611-0011, Japan Received 20 February 2001; received in revised form 4 February 2002 Abstract We propose a hybrid global optimization method for nonlinear inverse problems. The method consists of two components: local optimizers and feasible point ÿnders. Local optimizers have been well developed in the literature and can reliably attain the local optimal solution. The feasible point ÿnder proposed here is equivalent to ÿnding the zero points of a one-dimensional function. It warrants that local optimizers either obtain a better solution in the next iteration or produce a global optimal solution. The algorithm by assembling these two components has been proved to converge globally and is able to ÿnd all the global optimal solutions. The method has been demonstrated to perform excellently with an example having more than 1 750 000 local minima over [ −106; 107].c 2002 Elsevier Science B.V. All rights reserved. Keywords: Interval analysis; Hybrid global optimization 1. Introduction Many problems in science and engineering can ultimately be formulated as an optimization (max- imization or minimization) model. In the Earth Sciences, we have tried to collect data in a best way and then to extract the information on, for example, the Earth’s velocity structures and=or its stress=strain state, from the collected data as much as possible. -

Geometric GSI’19 Science of Information Toulouse, 27Th - 29Th August 2019
ALEAE GEOMETRIA Geometric GSI’19 Science of Information Toulouse, 27th - 29th August 2019 // Program // GSI’19 Geometric Science of Information On behalf of both the organizing and the scientific committees, it is // Welcome message our great pleasure to welcome all delegates, representatives and participants from around the world to the fourth International SEE from GSI’19 chairmen conference on “Geometric Science of Information” (GSI’19), hosted at ENAC in Toulouse, 27th to 29th August 2019. GSI’19 benefits from scientific sponsor and financial sponsors. The 3-day conference is also organized in the frame of the relations set up between SEE and scientific institutions or academic laboratories: ENAC, Institut Mathématique de Bordeaux, Ecole Polytechnique, Ecole des Mines ParisTech, INRIA, CentraleSupélec, Institut Mathématique de Bordeaux, Sony Computer Science Laboratories. We would like to express all our thanks to the local organizers (ENAC, IMT and CIMI Labex) for hosting this event at the interface between Geometry, Probability and Information Geometry. The GSI conference cycle has been initiated by the Brillouin Seminar Team as soon as 2009. The GSI’19 event has been motivated in the continuity of first initiatives launched in 2013 at Mines PatisTech, consolidated in 2015 at Ecole Polytechnique and opened to new communities in 2017 at Mines ParisTech. We mention that in 2011, we // Frank Nielsen, co-chair Ecole Polytechnique, Palaiseau, France organized an indo-french workshop on “Matrix Information Geometry” Sony Computer Science Laboratories, that yielded an edited book in 2013, and in 2017, collaborate to CIRM Tokyo, Japan seminar in Luminy TGSI’17 “Topoplogical & Geometrical Structures of Information”. -
![Arxiv:1804.07332V1 [Math.OC] 19 Apr 2018](https://docslib.b-cdn.net/cover/7357/arxiv-1804-07332v1-math-oc-19-apr-2018-1077357.webp)
Arxiv:1804.07332V1 [Math.OC] 19 Apr 2018
Juniper: An Open-Source Nonlinear Branch-and-Bound Solver in Julia Ole Kr¨oger,Carleton Coffrin, Hassan Hijazi, Harsha Nagarajan Los Alamos National Laboratory, Los Alamos, New Mexico, USA Abstract. Nonconvex mixed-integer nonlinear programs (MINLPs) rep- resent a challenging class of optimization problems that often arise in engineering and scientific applications. Because of nonconvexities, these programs are typically solved with global optimization algorithms, which have limited scalability. However, nonlinear branch-and-bound has re- cently been shown to be an effective heuristic for quickly finding high- quality solutions to large-scale nonconvex MINLPs, such as those arising in infrastructure network optimization. This work proposes Juniper, a Julia-based open-source solver for nonlinear branch-and-bound. Leverag- ing the high-level Julia programming language makes it easy to modify Juniper's algorithm and explore extensions, such as branching heuris- tics, feasibility pumps, and parallelization. Detailed numerical experi- ments demonstrate that the initial release of Juniper is comparable with other nonlinear branch-and-bound solvers, such as Bonmin, Minotaur, and Knitro, illustrating that Juniper provides a strong foundation for further exploration in utilizing nonlinear branch-and-bound algorithms as heuristics for nonconvex MINLPs. 1 Introduction Many of the optimization problems arising in engineering and scientific disci- plines combine both nonlinear equations and discrete decision variables. Notable examples include the blending/pooling problem [1,2] and the design and opera- tion of power networks [3,4,5] and natural gas networks [6]. All of these problems fall into the class of mixed-integer nonlinear programs (MINLPs), namely, minimize: f(x; y) s.t. -

Global Optimization, the Gaussian Ensemble, and Universal Ensemble Equivalence
Probability, Geometry and Integrable Systems MSRI Publications Volume 55, 2007 Global optimization, the Gaussian ensemble, and universal ensemble equivalence MARIUS COSTENIUC, RICHARD S. ELLIS, HUGO TOUCHETTE, AND BRUCE TURKINGTON With great affection this paper is dedicated to Henry McKean on the occasion of his 75th birthday. ABSTRACT. Given a constrained minimization problem, under what condi- tions does there exist a related, unconstrained problem having the same mini- mum points? This basic question in global optimization motivates this paper, which answers it from the viewpoint of statistical mechanics. In this context, it reduces to the fundamental question of the equivalence and nonequivalence of ensembles, which is analyzed using the theory of large deviations and the theory of convex functions. In a 2000 paper appearing in the Journal of Statistical Physics, we gave nec- essary and sufficient conditions for ensemble equivalence and nonequivalence in terms of support and concavity properties of the microcanonical entropy. In later research we significantly extended those results by introducing a class of Gaussian ensembles, which are obtained from the canonical ensemble by adding an exponential factor involving a quadratic function of the Hamiltonian. The present paper is an overview of our work on this topic. Our most important discovery is that even when the microcanonical and canonical ensembles are not equivalent, one can often find a Gaussian ensemble that satisfies a strong form of equivalence with the microcanonical ensemble known as universal equivalence. When translated back into optimization theory, this implies that an unconstrained minimization problem involving a Lagrange multiplier and a quadratic penalty function has the same minimum points as the original con- strained problem. -
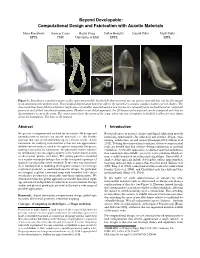
Beyond Developable: Omputational Design and Fabrication with Auxetic Materials
Beyond Developable: Computational Design and Fabrication with Auxetic Materials Mina Konakovic´ Keenan Crane Bailin Deng Sofien Bouaziz Daniel Piker Mark Pauly EPFL CMU University of Hull EPFL EPFL Figure 1: Introducing a regular pattern of slits turns inextensible, but flexible sheet material into an auxetic material that can locally expand in an approximately uniform way. This modified deformation behavior allows the material to assume complex double-curved shapes. The shoe model has been fabricated from a single piece of metallic material using a new interactive rationalization method based on conformal geometry and global, non-linear optimization. Thanks to our global approach, the 2D layout of the material can be computed such that no discontinuities occur at the seam. The center zoom shows the region of the seam, where one row of triangles is doubled to allow for easy gluing along the boundaries. The base is 3D printed. Abstract 1 Introduction We present a computational method for interactive 3D design and Recent advances in material science and digital fabrication provide rationalization of surfaces via auxetic materials, i.e., flat flexible promising opportunities for industrial and product design, engi- material that can stretch uniformly up to a certain extent. A key neering, architecture, art and science [Caneparo 2014; Gibson et al. motivation for studying such material is that one can approximate 2015]. To bring these innovations to fruition, effective computational doubly-curved surfaces (such as the sphere) using only flat pieces, tools are needed that link creative design exploration to material making it attractive for fabrication. We physically realize surfaces realization. A versatile approach is to abstract material and fabrica- by introducing cuts into approximately inextensible material such tion constraints into suitable geometric representations which are as sheet metal, plastic, or leather. -

Couenne: a User's Manual
couenne: a user’s manual Pietro Belotti⋆ Dept. of Mathematical Sciences, Clemson University Clemson SC 29634. Abstract. This is a short user’s manual for the couenne open-source software for global optimization. It provides downloading and installation instructions, an explanation to all options available in couenne, and suggestions on when to use some of its features. 1 Introduction couenne is an Open Source code for solving Global Optimization problems, i.e., problems of the form (P) min f(x) s.t. gj(x) ≤ 0 ∀j ∈ M l u xi ≤ xi ≤ xi ∀i ∈ N0 Z I xi ∈ ∀i ∈ N0 ⊆ N0, n n where f : R → R and, for all j ∈ M, gj : R → R are multivariate (possibly nonconvex) functions, n = |N0| is the number of variables, and x = (xi)i∈N0 is the n-vector of variables. We assume that f and all gj’s are factorable, i.e., they are expressed as Ph Qk ηhk(x), where all functions ηhk(x) are univariate. couenne is part of the COIN-OR infrastructure for Operations Research software1. It is a reformulation-based spatial branch&bound (sBB) [10,11,12], and it implements: – linearization; – branching; – heuristics to find feasible solutions; – bound reduction. Its main purpose is to provide the Optimization community with an Open- Source tool that can be specialized to handle specific classes of MINLP problems, or improved by adding more efficient linearization, branching, heuristic, and bound reduction techniques. ⋆ Email: [email protected] 1 See http://www.coin-or.org Web resources. The homepage of couenne is on the COIN-OR website: http://www.coin-or.org/Couenne and shows a brief description of couenne and some useful links. -

Stochastic Optimization,” in Handbook of Computational Statistics: Concepts and Methods (2Nd Ed.) (J
Citation: Spall, J. C. (2012), “Stochastic Optimization,” in Handbook of Computational Statistics: Concepts and Methods (2nd ed.) (J. Gentle, W. Härdle, and Y. Mori, eds.), Springer−Verlag, Heidelberg, Chapter 7, pp. 173–201. dx.doi.org/10.1007/978-3-642-21551-3_7 STOCHASTIC OPTIMIZATION James C. Spall The Johns Hopkins University Applied Physics Laboratory 11100 Johns Hopkins Road Laurel, Maryland 20723-6099 U.S.A. [email protected] Stochastic optimization algorithms have been growing rapidly in popularity over the last decade or two, with a number of methods now becoming “industry standard” approaches for solving challenging optimization problems. This chapter provides a synopsis of some of the critical issues associated with stochastic optimization and a gives a summary of several popular algorithms. Much more complete discussions are available in the indicated references. To help constrain the scope of this article, we restrict our attention to methods using only measurements of the criterion (loss function). Hence, we do not cover the many stochastic methods using information such as gradients of the loss function. Section 1 discusses some general issues in stochastic optimization. Section 2 discusses random search methods, which are simple and surprisingly powerful in many applications. Section 3 discusses stochastic approximation, which is a foundational approach in stochastic optimization. Section 4 discusses a popular method that is based on connections to natural evolution—genetic algorithms. Finally, Section 5 offers some concluding remarks. 1 Introduction 1.1 General Background Stochastic optimization plays a significant role in the analysis, design, and operation of modern systems. Methods for stochastic optimization provide a means of coping with inherent system noise and coping with models or systems that are highly nonlinear, high dimensional, or otherwise inappropriate for classical deterministic methods of optimization. -

Global Optimization Methods for Chemical Process Design: Deterministic and Stochastic Approaches
Korean J. Chem. Eng., 19(2), 227-232 (2002) SHORT COMMUNICATION Global Optimization Methods for Chemical Process Design: Deterministic and Stochastic Approaches Soo Hyoung Choi† and Vasilios Manousiouthakis* School of Chemical Engineering and Technology, Chonbuk National University, Jeonju 561-756, S. Korea *Chemical Engineering Department, University of California Los Angeles, Los Angeles, CA 90095, USA (Received 24 September 2001 • accepted 22 November 2001) Abstract−Process optimization often leads to nonconvex nonlinear programming problems, which may have multiple local optima. There are two major approaches to the identification of the global optimum: deterministic approach and stochastic approach. Algorithms based on the deterministic approach guarantee the global optimality of the obtained solution, but are usually applicable to small problems only. Algorithms based on the stochastic approach, which do not guarantee the global optimality, are applicable to large problems, but inefficient when nonlinear equality con- straints are involved. This paper reviews representative deterministic and stochastic global optimization algorithms in order to evaluate their applicability to process design problems, which are generally large, and have many nonlinear equality constraints. Finally, modified stochastic methods are investigated, which use a deterministic local algorithm and a stochastic global algorithm together to be suitable for such problems. Key words: Global Optimization, Deterministic, Stochastic Approach, Nonconvex, Nonlinear -

CME 338 Large-Scale Numerical Optimization Notes 2
Stanford University, ICME CME 338 Large-Scale Numerical Optimization Instructor: Michael Saunders Spring 2019 Notes 2: Overview of Optimization Software 1 Optimization problems We study optimization problems involving linear and nonlinear constraints: NP minimize φ(x) n x2R 0 x 1 subject to ` ≤ @ Ax A ≤ u; c(x) where φ(x) is a linear or nonlinear objective function, A is a sparse matrix, c(x) is a vector of nonlinear constraint functions ci(x), and ` and u are vectors of lower and upper bounds. We assume the functions φ(x) and ci(x) are smooth: they are continuous and have continuous first derivatives (gradients). Sometimes gradients are not available (or too expensive) and we use finite difference approximations. Sometimes we need second derivatives. We study algorithms that find a local optimum for problem NP. Some examples follow. If there are many local optima, the starting point is important. x LP Linear Programming min cTx subject to ` ≤ ≤ u Ax MINOS, SNOPT, SQOPT LSSOL, QPOPT, NPSOL (dense) CPLEX, Gurobi, LOQO, HOPDM, MOSEK, XPRESS CLP, lp solve, SoPlex (open source solvers [7, 34, 57]) x QP Quadratic Programming min cTx + 1 xTHx subject to ` ≤ ≤ u 2 Ax MINOS, SQOPT, SNOPT, QPBLUR LSSOL (H = BTB, least squares), QPOPT (H indefinite) CLP, CPLEX, Gurobi, LANCELOT, LOQO, MOSEK BC Bound Constraints min φ(x) subject to ` ≤ x ≤ u MINOS, SNOPT LANCELOT, L-BFGS-B x LC Linear Constraints min φ(x) subject to ` ≤ ≤ u Ax MINOS, SNOPT, NPSOL 0 x 1 NC Nonlinear Constraints min φ(x) subject to ` ≤ @ Ax A ≤ u MINOS, SNOPT, NPSOL c(x) CONOPT, LANCELOT Filter, KNITRO, LOQO (second derivatives) IPOPT (open source solver [30]) Algorithms for finding local optima are used to construct algorithms for more complex optimization problems: stochastic, nonsmooth, global, mixed integer. -

Global Optimization Based on a Statistical Model and Simplicial Partitioning
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector An InternationalJournal computers & mathematics with applkations PERGAMON Computers and Mathematics with Applications 44 (2002) 957-967 www.elsevier.com/locate/camwa Global Optimization Based on a Statistical Model and Simplicial Partitioning A. ~ILINSKAS Institute of Mathematics and Informatics Vilnius, Lithuania antanaszBklt.mii.lt J. ~ILINSKAS Department of Informatics KUT, Studentu str. 50-214b, Kaunas, Lithuania jzilQdsplab.ktu.lt Abstract-A statistical model for global optimization is constructed generalizingsome properties of the Wiener process to the multidimensional case. An approach to the construction of global optimization algorithms is developed using the proposed statistical model. The convergence of an algorithm based on the constructed statistical model and simplicial partitioning is proved. Several versions of the algorithm are implemented and investigated. @ 2002 Elsevier Science Ltd. All rights reserved. Keywords-Global optimization, Statistical models, Partitioning, Simplices, Convergence 1. INTRODUCTION The first statistical model used for the global optimization was the Wiener process [l]. Several one-dimensional algorithms were developed using Wiener or Wiener related models, e.g., [2-71. Extensive testing has shown that the implemented algorithms favorably compete with algorithms based on other approaches [7,8]. The sampling functions of Wiener process are not differentiable almost everywhere with probability one. Recently, a statistical one-dimensional model of smooth functions was constructed whose computational complexity is similar to the computational com- plexity of Wiener model [9]. The nondifferentiability of sampling functions was considered a serious theoretical disadvantage of using Wiener process as a model for global optimization. -

A Naïve Five-Element String Algorithm
JOURNAL OF SOFTWARE, VOL. 4, NO. 9, NOVEMBER 2009 925 A Naïve Five-Element String Algorithm Yanhong Cui University of Cape Town, Private Bag, Rondebosch 7701, Cape Town, South Africa Email: [email protected] Renkuan Guo and Danni Guo University of Cape Town, Private Bag, Rondebosch 7701, Cape Town, South Africa South African National Biodiversity Institute, Claremont 7735, Cape Town, South Africa Email: [email protected] ; [email protected] Abstract—In this paper, we propose a new global philosophy and its potential scientific value is often optimization algorithm inspired by the human life model in regarded as nonsense, pseudo-science or waste of times. Chinese Traditional Medicine and graph theory, which is Scientists more tend to believe part-theory based genetic named as naïve five-element string algorithm. The new engineering rather than TCM. We are not resisting any algorithm utilizes strings of elements from member set advancements in science and technology, however, we {0,1,2,3,4} to represent the values of candidate solutions (typically represented as vectors in n-dimensional Euclidean also have to accept the cruel realities: only 30% of the space). Except the mathematical operations for evaluating patients or illness could be cured by modern western the objective function, sort procedure, creating initial medicine, and on other hand, no less than 30% of the population randomly, the algorithm only involves if-else patients or illness could be cured by traditional medical logical operation. In contrast to existing global optimization treatments. More and more people accept traditional algorithms, the five-element algorithm engages the simplest medical treatments because of cost-saving and mathematics but reaches the highest searching efficiency. -

Global Dynamic Optimization Adam Benjamin Singer
Global Dynamic Optimization by Adam Benjamin Singer Submitted to the Department of Chemical Engineering in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Chemical Engineering at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY September 2004 c Massachusetts Institute of Technology 2004. All rights reserved. Author.............................................................. Department of Chemical Engineering June 10, 2004 Certified by. Paul I. Barton Associate Professor of Chemical Engineering Thesis Supervisor Accepted by......................................................... Daniel Blankschtein Professor of Chemical Engineering Chairman, Committee for Graduate Students 2 Global Dynamic Optimization by Adam Benjamin Singer Submitted to the Department of Chemical Engineering on June 10, 2004, in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Chemical Engineering Abstract My thesis focuses on global optimization of nonconvex integral objective functions subject to parameter dependent ordinary differential equations. In particular, effi- cient, deterministic algorithms are developed for solving problems with both linear and nonlinear dynamics embedded. The techniques utilized for each problem classifi- cation are unified by an underlying composition principle transferring the nonconvex- ity of the embedded dynamics into the integral objective function. This composition, in conjunction with control parameterization, effectively transforms the problem into a finite dimensional optimization problem where the objective function is given implic- itly via the solution of a dynamic system. A standard branch-and-bound algorithm is employed to converge to the global solution by systematically eliminating portions of the feasible space by solving an upper bounding problem and convex lower bounding problem at each node. The novel contributions of this work lie in the derivation and solution of these convex lower bounding relaxations.