The Three Ghosts of Medical AI: Can the Black-Box Present Deliver?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Educating Ourselves and Our Patrons About Retracted Articles
Joanna Thielen 183 When Scholarly Publishing Goes Awry: Educating 18.1. Ourselves and Our Patrons portal about Retracted Articles Joanna Thielen publication, for abstract: Retracted articles, articles that violate professional ethics, are an unsettling, yet integral, part of the scholarly publishing process seldom discussed in the academy. Unfortunately, article retractions continue to rise across all disciplines. Although academic librarians consistently provide instruction on scholarly publishing, little has been writtenaccepted about their role in educating patrons about retracted article. This article provides an overview of the article retraction process. Search strategies for locating retracted articles in several scholarlyand databases are discussed. Suggestions on how to incorporate article retractions into information literacy instruction are provided, including connections to the Association of College and Research Libraries Framework for Information Literacy for Higher Education. edited, copy Introduction n the academy, there is a heightened awareness of the fallibility of scholarly research and publishing. This awareness is exemplified by the “reproducibility crisis”: re- searchersreviewed, have become increasingly cognizant that many published research stud- Iies cannot be successfully duplicated.1 For example, only a reported 10 to 25 percent of cancerpeer biology studies can be reproduced.2 (Being unable to reproduce published resultsis does not necessarily indicate that the authors committed malfeasance or that the article’s results are incorrect. Rather, it only indicates that another researcher was unable to replicate the published work.) The lack of reproducibility of scholarly research has led mss. to calls for more transparency in research and publication practices. While the scholarly publishing process, including peer review, is intended to set rigorous standards and This expectations for publications, it is not infallible. -
![Amending Published Articles: Time to Rethink Retractions and Corrections?[Version 1; Peer Review: 2 Approved with Reservations]](https://docslib.b-cdn.net/cover/9147/amending-published-articles-time-to-rethink-retractions-and-corrections-version-1-peer-review-2-approved-with-reservations-219147.webp)
Amending Published Articles: Time to Rethink Retractions and Corrections?[Version 1; Peer Review: 2 Approved with Reservations]
F1000Research 2017, 6:1960 Last updated: 20 SEP 2021 OPINION ARTICLE Amending published articles: time to rethink retractions and corrections? [version 1; peer review: 2 approved with reservations] Virginia Barbour 1, Theodora Bloom 2, Jennifer Lin 3, Elizabeth Moylan 4 1QUT, Kelvin Grove, Brisbane, Queensland, 4059, Australia 2BMJ, BMA House, Tavistock Square, London, WC1H 9JR, UK 3Crossref, North American Office , 50 Salem Street, Lynnfield, MA 01940, USA 4BMC (part of Springer Nature), 236 Grays Inn Road, London, WC1X 8HB, UK v1 First published: 06 Nov 2017, 6:1960 Open Peer Review https://doi.org/10.12688/f1000research.13060.1 Latest published: 06 Nov 2017, 6:1960 https://doi.org/10.12688/f1000research.13060.1 Reviewer Status Invited Reviewers Abstract Academic publishing is evolving and our current system of correcting 1 2 research post-publication is failing, both ideologically and practically. It does not encourage researchers to engage in necessary post- version 1 publication changes in a consistent way. Worse yet, post-publication 06 Nov 2017 report report ‘updates’ can be misconstrued as punishments or admissions of misconduct. 1. Lex M. Bouter , VU University Medical We propose a different model that publishers of research can apply to Centre, Amsterdam, The Netherlands the content they publish, ensuring that any post-publication Vrije Universiteit, Amsterdam, The amendments are seamless, transparent and propagated to all the Netherlands countless places online where descriptions of research appear. At the center of our proposal is use of the neutral term “amendment” to 2. C.K. Gunsalus , University of Illinois at describe all forms of post-publication change to an article. -
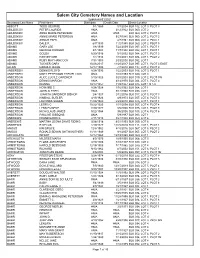
Cemetery Names Master .Xlsx
Salem City Cemetery Names and Location Updated 6/01/2021 Deceased Last Name First Name Birthdate Death Date Grave Location ABBOTT TODD GEORGE 3/1/1969 5/1/2004BLK 102, LOT 3, PLOT 3 ABILDSCOV PETER LAURIDS #N/A 6/12/1922BLK 060, LOT 2 ABILDSKOV ANNA MARIE PETERSON #N/A #N/A BLK 060, LOT 2, PLOT 4 ABILDSKOV ANNIE MARIE PETERSON #N/A 9/27/1985BLK 060, LOT 2, PLOT 2 ABILDSKOV ASMUS PAPE #N/A 4/7/1981BLK 060, LOT 2, PLOT 1 ABILDSKOV DALE P. 6/7/1933 11/2/1985BLK 060, LOT 2, PLOT 5 ADAMS GARY LEE 1/8/1939 7/22/2009BLK 097, LOT 1, PLOT 1 ADAMS GEORGE RUDGER 8/1/1903 11/7/1980BLK 092, LOT 1, PLOT 1 ADAMS GOLDA 6/20/1916 9/1/2002BLK 084, LOT 1, PLOT 3 ADAMS HARVEY DEE 1/1/1914 1/10/2001BLK 084, LOT 1, PLOT 2 ADAMS RUBY MAY HANCOCK 7/31/1905 2/29/2000BLK 092, LOT 1 ADAMS TUCKER GARY 10/26/2017 11/20/2017BLK 097, LOT 1, PLOT 3 EAST ALLEN HAROLD JESSE 12/17/1993 7/7/2010BLK 137, LOT 2, PLOT 4 ANDERSEN DENNIS FLOYD 8/28/1936 1/22/2003BLK 016, LOT 3, PLOT 1 ANDERSEN MARY PETERSON TREMELLING #N/A 1/10/1953BLK 040, LOT 3 ANDERSON ALICE LUCILE GARDNER 5/10/1923 5/25/2003BLK 019, LOT 2, PLOT 3W ANDERSON DENNIS MARION #N/A 4/14/1970BLK 084, LOT 1, PLOT 4 ANDERSON DIANNA 10/17/1957 11/9/1957BLK 075, LOT 1 N 1/2 ANDERSON HOWARD C. -

Residenc Y Sponsor S
RESIDENCY SPONSORS ART OMI With the support of generous sponsors, Art Omi offers transformational opportunities for artists from around the world, enriching both their lives, and those of our community. Art Omi is a not-for-profit arts center with residency programs for international artists, writers, translators, musicians, architects and dancers, and a 120-acre sculpture and architecture park. Art Omi believes that exposure to internationally diverse creative voices fosters tolerance and respect, raises awareness, inspires innovation, and ignites change. By forming community with creative expression as its common denominator, Art Omi creates a sanctuary for the artistic community and the public to affirm the transformative quality of art. Since its founding, Art Omi has been guided by the principle that artistic expression transcends economic, political, and cultural boundaries. robbinschilds performs on Smoke, by Richard Nonas. RESIDENCIES “The residency program at Art Omi was beyond Art Omi has five distinct international residency programs doubt a positive serving five artistic disciplines: and distinctive Architecture, Artists, Dance, Music, experience—a and Writers. As the residencies are discipline specific, Art Omi affords kind of utopian each artist an intense immersion into a global group of their professional peers. Each residency serves the field at large in hedonistic bliss a distinct way, inviting visitors and mentors to engage with the artists while they are in residence. All of the residency programs without daily life have a communal orientation—sharing ideas, creative space, and meals comprises a major part of the residency experience. All distractions and residents attend at no cost to themselves, except travel. -

Authorship, Publication, and Peer Review Mark Hooper* , Virginia Barbour, Anne Walsh, Stephanie Bradbury and Jane Jacobs
Hooper et al. Research Integrity and Peer Review (2018) 3:2 Research Integrity and https://doi.org/10.1186/s41073-018-0046-2 Peer Review COMMENTARY Open Access Designing integrated research integrity training: authorship, publication, and peer review Mark Hooper* , Virginia Barbour, Anne Walsh, Stephanie Bradbury and Jane Jacobs Abstract This paper describes the experience of an academic institution, the Queensland University of Technology (QUT), developing training courses about research integrity practices in authorship, publication, and Journal Peer Review. The importance of providing research integrity training in these areas is now widely accepted; however, it remains an open question how best to conduct this training. For this reason, it is vital for institutions, journals, and peak bodies to share learnings. We describe how we have collaborated across our institution to develop training that supports QUT’s principles and which is in line with insights from contemporary research on best practices in learning design, universal design, and faculty involvement. We also discuss how we have refined these courses iteratively over time, and consider potential mechanisms for evaluating the effectiveness of the courses more formally. Background and allows institutions and researchers to demonstrate The idea that institutions ought to provide researchers their commitment to comprehensive research integrity with formal training in research integrity is now gener- training and to satisfy the requirements of certain fund- ally accepted. How best to conduct research integrity ing bodies. training, however, is a contested issue [1–5]. However, it is not clear that the “standalone” training One option is to provide research integrity training by method is sufficient to teach research integrity effectively way of “standalone” courses or units, covering a broad or to promote an institutional culture that truly values range of responsible research practices. -

Index of Personal Names
Swedish American Genealogist Volume 4 | Number 4 Article 6 12-1-1984 Index of Personal Names Follow this and additional works at: https://digitalcommons.augustana.edu/swensonsag Part of the Genealogy Commons, and the Scandinavian Studies Commons Recommended Citation (1984) "Index of Personal Names," Swedish American Genealogist: Vol. 4 : No. 4 , Article 6. Available at: https://digitalcommons.augustana.edu/swensonsag/vol4/iss4/6 This Article is brought to you for free and open access by Augustana Digital Commons. It has been accepted for inclusion in Swedish American Genealogist by an authorized editor of Augustana Digital Commons. For more information, please contact [email protected]. Personal Name Index Index of Personal Names Note: A name may appear more than once on a page. Two individuals with identical names appearing on the same page are indexed with either a reference to their parishes of birth, or if this is not known, by the addition of a Roman numeral II to the second name appearing. .The Swedish letters d, ii and o are indexed as aa, ae and oe. - , Anders John, 54 Anna, 81 Charlotta Christina, 62 Andrew, 53 Brita, 80 Gustaf E., 53, 60 August, 53, 54 Catarina, 89 Samuel G., 54 Bengt, 80 Christina (Kerstin), 79 AHMAN, see AHMAN Bengt, 82 Christina (Kerstin), II, 79 ALGEHR, Gertrud, 76 Carl E., 57 Christina (Kerstin), 83 Kristoffer, 80 Carl F., 54 Christina, 89 Peter, 78 Charles E., 59 Christina, 168 ALGERUS, Laurentius M., Dan, 97 Emmaline, 104 121 E., 24 Gertrud, 84 ALMQUIST, Joh. Ax., 20 Edward, 53, 59 Ingrid, 77 -

Pioneers and Prominent Men of Utah 1023
PIONEERS AND PROMINENT MEN OF UTAH 1023 Elizabeth b. April 19, 1857, m. Lorenzo Arayle; Lydia Maria MARKHAM, STEPHEN (son of David Markham and DIna b. Feb. 1, 1859. died; John Monroe b. Aug., 1860. m. Ann Hosmer of New York). Born Peb. 9, 1800, New York. Came Cowan May 14, 1884; Riley b. April 9, 1863, died; Mary to Utah July 24, 1847, with Brigham Young company. Ann b. Oct. 16, 1864, m. Alpheus Bingham; Virginia b. Married Mary Curtis Oct. 6, 1848, Salt Lake City (daugh May 16, 1866, m. Charles Bingham; George A. b. Aug. 14, ter of Jeremiah Curtis and Ruth Straton of Michigan and 1868, m. Elmira Jensen; Melissa b. Aug. 5, 1874, m. William widow of Orren Houghten, by whom she had one child, Lewis; Princessetta b. Jan. 9, 1876, m. Robert Cowan; Edgar Straton, who married Martha Ann Parnett). She Cynthia May b. May 1, 1870, died; David b. Dec. 11, 1872, was born Nov. 15, 1832. Their children: Orvill Sanford, m. Viola McBeth; Sarah b. July 7, 1877, m. James N. Hansen. m. Mary Ann Robertson; Mary Lucy, m. Andrew Dudley; William Don Carlos, m. Sarah Ann Warner; Sarah Eliza Married Roslna Trevort Dec. 15, 1881. Their children: beth, m. William Ashby; Atta Ruth, m. Henry Angus; William Riley b. Nov. 17, 1882; Daisy b, Dec. 5, 1883, m. Hosmer Merry, m. Jessie Geneva Cleveland; Emily Aurilla, William A. Francom; Myrtle-b. June 8, 1885, m. Frank m. William McKee; Margaret Eliza, m. Owen Morgan; Daley. Families resided at Payson, Utah. Joseph, m. -

Redlich Ancestry
DUTCH BtmGHEE UNION 27 26 THE JOURNAL OF THE III GENEALOGY OF THE FAMILY OF REDUCH Alwynne Samuel Schultsz Redlich, born 4th May 1848. died 9th January 1905, married in St, John's Church, Chnndnkuii, 22nd March OF CEYLON. j,S71. Evelyn Harriet Speldewinde, born 1st April 1850, died 30th mcprabev 1931, daughter of Henry Fredrick Speldewinde and Hen- fI-ett i Wilhelmina Grenier. (D.B.U. Journal, Vol. XXXIII, page 74, (Compiled by Mr, F,. H. de Vos in 1916; revispd b% md Vol. XLII, page 23.) He had by her— Mr. D. V. AMendorff\in 1953) 1 Mary Harriet Ethel, born 12th August 1872, married in St. Michael's and All Angel's Church, Colombo 2lst August 1905, I Arthur Harris Jansz, born 30th June 1877, son of Joseph Edward Jansz and Charlotte Camilla Grenier. (D.B.U. Journal, Johan'n Christiaan Redlich of Strelitz (Mecklenburg,) j Vol. XXIV, page 140, ane Vol, XLII, page 24). Johanna Classina de Jong, and he had by her— 2 Bertha Daisy, born 1st September 1877, married in Holy 1 William Francis, who follows under II. Trinity Church, Colombo. 6th September 1899\ William 2 Johanna Adriana Charlotta, born 19th April 1807, b Button Gregory da Silva, born 13th July 1878, died 17th 30th September 1810. January 1945, son of Severinus Benedictus (Bichard) da Silva 3 Frederick James married Charlotte Grenier, born lot andJ3elina Maria McCarthy nee Staples. (D.B.U. Journal, Vol. 1814, died 3rd January 1835, daughter of Jean F XLIII, pages 165 and 168.) Grenier and Charlotta Pietersz. (D.B.U. -

Hong Kong Principles
1 The Hong Kong Principles for Assessing Researchers: 2 Fostering Research Integrity 3 4 David Moher1,2, Lex Bouter3,4, Sabine Kleinert5, Paul Glasziou6, Mai Har Sham7 5 Virginia Barbour8, Anne-Marie Coriat9, Nicole Foeger10, Ulrich Dirnagl11 6 7 1Centre for Journalology, Clinical Epidemiology Program, Ottawa Hospital Research Institute; 2School of 8 Epidemiology and Public Health, University of Ottawa, Ottawa, Canada; 3Department of Epidemiology 9 and Biostatistics, Amsterdam University Medical Centers, location VUmc; 4Department of Philosophy, 10 Faculty of Humanities, Vrije Universiteit, Amsterdam, The Netherlands; 5The Lancet, London Wall Office, 11 London, UK; 6Institute for Evidence-Based healthcare, Bond University, Gold Coast, Qld, Australia; and 12 7School of Biomedical Sciences, LKS Faculty of Medicine, The University of Hong Kong, Pokfulam, Hong 13 Kong SAR, China; 8Queensland University of Technology (QUT), Brisbane, Australia; 9Wellcome Trust, 14 London; 10Austrian Agency for Research Integrity, Vienna, Austria; 11Berlin Institute of Health, QUEST 15 Center for Transforming Biomedical Research, Berlin, Germany 16 17 David Moher: ORCID 0000-0003-2434-4206 18 Lex Bouter: ORCID 0000-0002-2659-5482 19 Sabine Kleinert: ORCID 0000-0001-7826-1188 20 Paul Glasziou: ORCID 0000-0001-7564-073X 21 Mai Har Sham: ORCID 0000-0003-1179-7839 22 Virginia Barbour: ORCID: 0000-0002-2358-2440 23 Anne-Marie Coriat: ORCID 0000-0003-2632-1745 24 Nicole Foeger: ORCID 0000-0001-7775-7325 25 Ulrich Dirnagl: ORCID 0000-0003-0755-6119 26 27 28 23rd November 2019 29 Abstract 30 31 The primary goal of research is to advance knowledge. For that knowledge to benefit research and 32 society, it must be trustworthy. -

Converting Scholarly Journals to Open Access: a Review of Approaches and Experiences David J
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Copyright, Fair Use, Scholarly Communication, etc. Libraries at University of Nebraska-Lincoln 2016 Converting Scholarly Journals to Open Access: A Review of Approaches and Experiences David J. Solomon Michigan State University Mikael Laakso Hanken School of Economics Bo-Christer Björk Hanken School of Economics Peter Suber editor Harvard University Follow this and additional works at: http://digitalcommons.unl.edu/scholcom Part of the Intellectual Property Law Commons, Scholarly Communication Commons, and the Scholarly Publishing Commons Solomon, David J.; Laakso, Mikael; Björk, Bo-Christer; and Suber, Peter editor, "Converting Scholarly Journals to Open Access: A Review of Approaches and Experiences" (2016). Copyright, Fair Use, Scholarly Communication, etc.. 27. http://digitalcommons.unl.edu/scholcom/27 This Article is brought to you for free and open access by the Libraries at University of Nebraska-Lincoln at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Copyright, Fair Use, Scholarly Communication, etc. by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Converting Scholarly Journals to Open Access: A Review of Approaches and Experiences By David J. Solomon, Mikael Laakso, and Bo-Christer Björk With interpolated comments from the public and a panel of experts Edited by Peter Suber Published by the Harvard Library August 2016 This entire report, including the main text by David Solomon, Bo-Christer Björk, and Mikael Laakso, the preface by Peter Suber, and the comments by multiple authors is licensed under a Creative Commons Attribution 4.0 International License. https://creativecommons.org/licenses/by/4.0/ 1 Preface Subscription journals have been converting or “flipping” to open access (OA) for about as long as OA has been an option. -
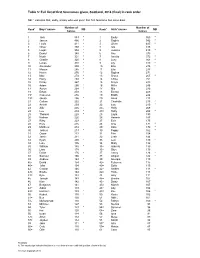
Table 5: Full List of First Forenames Given, Scotland, 2014 (Final) in Rank Order
Table 5: Full list of first forenames given, Scotland, 2014 (final) in rank order NB: * indicates that, sadly, a baby who was given that first forename has since died. Number of Number of Rank1 Boys' names NB Rank1 Girls' names NB babies babies 1 Jack 583 * 1 Emily 569 * 2 James 466 * 2 Sophie 542 * 3 Lewis 411 * 3 Olivia 485 * 4 Oliver 403 * 4 Isla 435 5 Logan 354 * 5 Jessica 419 * 6 Daniel 349 * 6 Ava 379 7 Noah 321 * 7 Amelia 372 * 8 Charlie 320 * 8 Lucy 363 * 9 Lucas 310 * 9 Lily 310 * 10 Alexander 309 * 10 Ellie 278 * 11 Mason 285 * 11 Ella 273 12 Harris 276 * 12 Sophia 271 13 Max 274 * 13 Grace 265 * 14 Harry 268 * 14 Chloe 251 15 Finlay 267 15 Freya 249 16 Adam 266 * 16 Millie 246 17 Aaron 264 * 17 Mia 230 18 Ethan 259 18 Emma 229 19= Cameron 256 19 Eilidh 224 19= Jacob 256 * 20 Anna 218 21 Callum 252 21 Charlotte 213 * 22 Archie 239 22 Eva 210 * 23 Alfie 236 * 23= Holly 208 24 Leo 234 * 23= Ruby 208 * 25 Thomas 228 * 25 Layla 190 26 Nathan 226 26 Hannah 187 27 Riley 223 * 27 Evie 175 28 Rory 215 28 Orla 171 * 29 Matthew 214 29 Katie 170 * 30 Joshua 213 * 30 Poppy 162 * 31 Oscar 212 31 Erin 154 32 Jamie 211 32 Leah 144 33 Ryan 208 * 33 Lexi 140 * 34 Luke 195 34 Molly 132 35 William 180 * 35= Isabella 130 36 Liam 178 35= Skye 130 37 Dylan 176 * 37 Lacey 124 * 38 Samuel 166 38 Abigail 122 * 39 Andrew 163 * 39 Georgia 119 40= David 154 * 40= Rebecca 115 40= John 154 40= Sofia 115 42 Connor 146 42= Amber 113 * 43= Brodie 144 42= Hollie 113 43= Kyle 144 * 44 Amy 111 45 Joseph 143 45= Brooke 107 46 Kian 142 * 45= Daisy 107 47 Benjamin 141 45= Niamh 107 48= Aiden 139 48= Lilly 106 48= Harrison 139 * 48= Zoe 106 * 50 Robert 135 * 50 Rosie 102 51= Ben 130 51 Abbie 101 51= Muhammad 130 52 Robyn 100 * 53 Michael 127 53 Sienna 98 54 Tyler 123 * 54= Summer 96 55 Kai 120 54= Zara 96 56 Euan 114 * 56 Iona 91 57= Arran 112 57 Maya 89 57= Jayden 112 58 Sarah 88 59 Jake 111 * 59= Aria 87 60= Cole 110 59= Maisie 87 60= Ollie 110 * 61 Cara 85 Footnote 1) The equals sign indicates that there is more than one name with this position of rank in the list. -

SURNAME GIVEN NAME MIDDLE NAME DEATH YEAR Baade Earl
SURNAME GIVEN NAME MIDDLE NAME DEATH YEAR Baade Earl Nathaniel 1952 Baade Myron Wayne 1966 Baagoe Walter John 1963 Babb Charles B 1951 Babb Minnie E 1953 Babbitt baby (Glen) 1931 Babbitt Donald E 1962 Babbitt Earl Wade 1967 Babbitt Evlyn L 1975 Babbitt Frank L 1937 Babbitt Gerald Clarence 1927 Babbitt Glenn Edward 1964 Babbitt Harry E 1959 Babbitt Isora 1922 Babbitt Lee H 1927 Babbitt Lena May 1965 Babbitt Mary 1937 Babbitt Ora 1962 Babbitt Richard C 1958 Babbitt Sarah Parsons 1953 Babbitt Violet Sarah 1955 Babbitt Wade E 1933 Babbitt William Glenn 1976 Babbitt William J 1933 Babcock Augusta 1929 Babcock baby (Ralph) 1943 Babcock Chester Norman 1980 Babcock Ella 1937 Babcock George Edward 1969 Babcock Helen Marie 1945 Babcock LaRayne Joyce 1947 Babcock Margaret Esther 1981 Babcock Mary M 1905 Babcook Nita Ann 1960 Babcook Ricky Allen 1961 Babitt Lee H 1927 Bach Henry Jennings 1974 Bachison Michael A 1967 Bachman Arthur Nels 1954 Bachman Henry Frederick 1961 Bachmeier Juanita 1947 Bachofner dau (Wilfred) 1945 Backen Bernice Sylvia 1946 Backer Amelia Sophia 1952 Bacon Alice Frances Pettibone 1926 Bacon Mabel 1957 Bacon Richard O 1937 Bacon Victoria Josephine 1921 Bacus Charles 1942 Bacus Emmett LeRoy 1930 SURNAME GIVEN NAME MIDDLE NAME DEATH YEAR Bacus Mary Josephine 1932 Bacus Wilson 1953 Badger Abbie Elizabeth 1945 Badgett George W 1938 Badgley Gertrude E 1974 Badgley Maxine Ella 1930 Badgley Thomas Enos 1968 Baese Charles John 1951 Baese Christina 1951 Baggarley Eams R 1952 Baggarley Luella 1952 Bagley Audrey Christine 1950 Bagley Claude