15-853:Algorithms in the Real World
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Leveraging Activation Sparsity for Training Deep Neural Networks
Compressing DMA Engine: Leveraging Activation Sparsity for Training Deep Neural Networks Minsoo Rhu Mike O’Connor Niladrish Chatterjee Jeff Pool Stephen W. Keckler NVIDIA Santa Clara, CA 95050 fmrhu, moconnor, nchatterjee, jpool, [email protected] Abstract—Popular deep learning frameworks require users to the time needed to copy data back and forth through PCIe is fine-tune their memory usage so that the training data of a deep smaller than the time the GPU spends computing the DNN neural network (DNN) fits within the GPU physical memory. forward and backward propagation operations, vDNN does Prior work tries to address this restriction by virtualizing the memory usage of DNNs, enabling both CPU and GPU memory not affect performance. For networks whose memory copying to be utilized for memory allocations. Despite its merits, vir- operation is bottlenecked by the data transfer bandwidth of tualizing memory can incur significant performance overheads PCIe however, vDNN can incur significant overheads with an when the time needed to copy data back and forth from CPU average 31% performance loss (worst case 52%, Section III). memory is higher than the latency to perform the computations The trend in deep learning is to employ larger and deeper required for DNN forward and backward propagation. We introduce a high-performance virtualization strategy based on networks that leads to large memory footprints that oversub- a “compressing DMA engine” (cDMA) that drastically reduces scribe GPU memory [13, 14, 15]. Therefore, ensuring the the size of the data structures that are targeted for CPU-side performance scalability of the virtualization features offered allocations. -
Compress/Decompress Encrypt/Decrypt
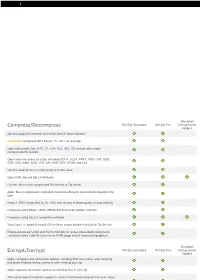
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

NXP Eiq Machine Learning Software Development Environment For
AN12580 NXP eIQ™ Machine Learning Software Development Environment for QorIQ Layerscape Applications Processors Rev. 3 — 12/2020 Application Note Contents 1 Introduction 1 Introduction......................................1 Machine Learning (ML) is a computer science domain that has its roots in 2 NXP eIQ software introduction........1 3 Building eIQ Components............... 2 the 1960s. ML provides algorithms capable of finding patterns and rules in 4 OpenCV getting started guide.........3 data. ML is a category of algorithm that allows software applications to become 5 Arm Compute Library getting started more accurate in predicting outcomes without being explicitly programmed. guide................................................7 The basic premise of ML is to build algorithms that can receive input data and 6 TensorFlow Lite getting started guide use statistical analysis to predict an output while updating output as new data ........................................................ 8 becomes available. 7 Arm NN getting started guide........10 8 ONNX Runtime getting started guide In 2010, the so-called deep learning started. It is a fast-growing subdomain ...................................................... 16 of ML, based on Neural Networks (NN). Inspired by the human brain, 9 PyTorch getting started guide....... 17 deep learning achieved state-of-the-art results in various tasks; for example, A Revision history.............................17 Computer Vision (CV) and Natural Language Processing (NLP). Neural networks are capable of learning complex patterns from millions of examples. A huge adaptation is expected in the embedded world, where NXP is the leader. NXP created eIQ machine learning software for QorIQ Layerscape applications processors, a set of ML tools which allows developing and deploying ML applications on the QorIQ Layerscape family of devices. -
Oak Park Area Visitor Guide
OAK PARK AREA VISITOR GUIDE COMMUNITIES Bellwood Berkeley Broadview Brookfield Elmwood Park Forest Park Franklin Park Hillside Maywood Melrose Park Northlake North Riverside Oak Park River Forest River Grove Riverside Schiller Park Westchester www.visitoakpark.comvisitoakpark.com | 1 OAK PARK AREA VISITORS GUIDE Table of Contents WELCOME TO THE OAK PARK AREA ..................................... 4 COMMUNITIES ....................................................................... 6 5 WAYS TO EXPERIENCE THE OAK PARK AREA ..................... 8 BEST BETS FOR EVERY SEASON ........................................... 13 OAK PARK’S BUSINESS DISTRICTS ........................................ 15 ATTRACTIONS ...................................................................... 16 ACCOMMODATIONS ............................................................ 20 EATING & DRINKING ............................................................ 22 SHOPPING ............................................................................ 34 ARTS & CULTURE .................................................................. 36 EVENT SPACES & FACILITIES ................................................ 39 LOCAL RESOURCES .............................................................. 41 TRANSPORTATION ............................................................... 46 ADVERTISER INDEX .............................................................. 47 SPRING/SUMMER 2018 EDITION Compiled & Edited By: Kevin Kilbride & Valerie Revelle Medina Visit Oak Park -

Winzip 12 Reviewer's Guide
Introducing WinZip® 12 WinZip® is the most trusted way to work with compressed files. No other compression utility is as easy to use or offers the comprehensive and productivity-enhancing approach that has made WinZip the gold standard for file-compression tools. With the new WinZip 12, you can quickly and securely zip and unzip files to conserve storage space, speed up e-mail transmission, and reduce download times. State-of-the-art file compression, strong AES encryption, compatibility with more compression formats, and new intuitive photo compression, make WinZip 12 the complete compression and archiving solution. Building on the favorite features of a worldwide base of several million users, WinZip 12 adds new features for image compression and management, support for new compression methods, improved compression performance, support for additional archive formats, and more. Users can work smarter, faster, and safer with WinZip 12. Who will benefit from WinZip® 12? The simple answer is anyone who uses a PC. Any PC user can benefit from the compression and encryption features in WinZip to protect data, save space, and reduce the time to transfer files on the Internet. There are, however, some PC users to whom WinZip is an even more valuable and essential tool. Digital photo enthusiasts: As the average file size of their digital photos increases, people are looking for ways to preserve storage space on their PCs. They have lots of photos, so they are always seeking better ways to manage them. Sharing their photos is also important, so they strive to simplify the process and reduce the time of e-mailing large numbers of images. -
Winzip 15 Matrix 4.Cdr
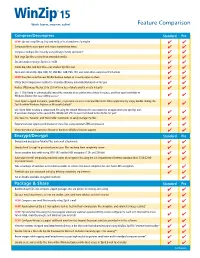
15 Feature Comparison NEW! Compress/Decompress Standard Pro NEW! Zip and unzip files quickly and easily with a brand new zip engine Compress files to save space and reduce transmission times Compress multiple files instantly using WinZip's handy Zip button* Split large Zip files so they fit on removable media Zip and unzip very large Zip files (>4GB) Create Zip, LHA, and Zipx files—our smallest Zip files ever Open and extract Zip, Zipx, RAR, 7Z, LHA BZ2, CAB, IMG, ISO, and most other compressed file formats NEW! Drag files onto the new WinZip Desktop Gadget to instantly zip/unzip them Utilize 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 to 25% with no loss of photo quality or data integrity Use '1-Click Unzip' to automatically extract the contents of an archive into a folder it creates, and then open that folder in Windows Explorer for easy editing access* 'Auto Open' a zipped document, spreadsheet, or presentation in its associated Microsoft Office application by simply double clicking the Zip file within Windows Explorer or Microsoft Outlook* Use 'Open With' to unzip a compressed file using the default Windows file association (or an application you specify), and, if you make changes to the opened file, WinZip will offer to save them back to the Zip file for you* Use 'Save As', 'Rename', and 'New Folder' commands to easily manage Zip files Experience faster zipping performance on most files using optional LZMA compression View international characters in filenames thanks to WinZip's Unicode support Encrypt/Decrypt Standard Pro Encrypt and decrypt confidential files and email attachments Simply check 'Encrypt' to password protect your files and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256-bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

About FOSS for Mac OS X (FREE)
Free and Open Source Software FREE for Mac OS X A selection of some of the best, yet totally free, software that’s available for the Mac, collected together on a single DVD… plus some bonus videos! Audio PrBoom Graphics First Person Shooter based on the Audacity original Doom. We’ve included Blender Simple sound recording and bonus IWADs from Freedoom. Fully integrated 3D graphics editing tool. creation suite allowing modeling, PySol Fan Club Edition animation, rendering, post- iPodDisk Collection of more than 1000 production, realtime interactive 3D Copy music off your iPod in the solitaire card games. There are and game creation and playback finder, just like a regular disk drive. games that use the 52 card with cross-platform compatibility - International Pattern deck, games all in one tidy, package! Games for the 78 card Tarock deck, eight and ten suit Ganjifa games, Seashore Aleph One Hanafuda games, Matrix games, Image editor that aims to serve the Engine for Bungie's free First Mahjongg games, and games for basic image editing needs of most Person Shooter series Marathon. an original hexadecimal-based computer users, but still has Play online, solo play with rich deck. features like gradients, textures and original story, many total Scorched 3D anti-aliasing for both text and conversions and thousands of brush strokes, as well as supporting Simple turn-based artillery game multiple layers and alpha channel maps. Includes Marathon, and also a real-time strategy game Marathon 2 & Marathon Infinity editing. It is based around the in which players can counter each GIMP's technology and uses the Armagetron Advanced others' weapons with other same native file format, but uses Multiplayer game in 3d that creative accessories, shields and Mac OS X native interface. -
![Archive and Compressed [Edit]](https://docslib.b-cdn.net/cover/8796/archive-and-compressed-edit-1288796.webp)
Archive and Compressed [Edit]
Archive and compressed [edit] Main article: List of archive formats • .?Q? – files compressed by the SQ program • 7z – 7-Zip compressed file • AAC – Advanced Audio Coding • ace – ACE compressed file • ALZ – ALZip compressed file • APK – Applications installable on Android • AT3 – Sony's UMD Data compression • .bke – BackupEarth.com Data compression • ARC • ARJ – ARJ compressed file • BA – Scifer Archive (.ba), Scifer External Archive Type • big – Special file compression format used by Electronic Arts for compressing the data for many of EA's games • BIK (.bik) – Bink Video file. A video compression system developed by RAD Game Tools • BKF (.bkf) – Microsoft backup created by NTBACKUP.EXE • bzip2 – (.bz2) • bld - Skyscraper Simulator Building • c4 – JEDMICS image files, a DOD system • cab – Microsoft Cabinet • cals – JEDMICS image files, a DOD system • cpt/sea – Compact Pro (Macintosh) • DAA – Closed-format, Windows-only compressed disk image • deb – Debian Linux install package • DMG – an Apple compressed/encrypted format • DDZ – a file which can only be used by the "daydreamer engine" created by "fever-dreamer", a program similar to RAGS, it's mainly used to make somewhat short games. • DPE – Package of AVE documents made with Aquafadas digital publishing tools. • EEA – An encrypted CAB, ostensibly for protecting email attachments • .egg – Alzip Egg Edition compressed file • EGT (.egt) – EGT Universal Document also used to create compressed cabinet files replaces .ecab • ECAB (.ECAB, .ezip) – EGT Compressed Folder used in advanced systems to compress entire system folders, replaced by EGT Universal Document • ESS (.ess) – EGT SmartSense File, detects files compressed using the EGT compression system. • GHO (.gho, .ghs) – Norton Ghost • gzip (.gz) – Compressed file • IPG (.ipg) – Format in which Apple Inc. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Kafl: Hardware-Assisted Feedback Fuzzing for OS Kernels
kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels Sergej Schumilo1, Cornelius Aschermann1, Robert Gawlik1, Sebastian Schinzel2, Thorsten Holz1 1Ruhr-Universität Bochum, 2Münster University of Applied Sciences Motivation IJG jpeg libjpeg-turbo libpng libtiff mozjpeg PHP Mozilla Firefox Internet Explorer PCRE sqlite OpenSSL LibreOffice poppler freetype GnuTLS GnuPG PuTTY ntpd nginx bash tcpdump JavaScriptCore pdfium ffmpeg libmatroska libarchive ImageMagick BIND QEMU lcms Adobe Flash Oracle BerkeleyDB Android libstagefright iOS ImageIO FLAC audio library libsndfile less lesspipe strings file dpkg rcs systemd-resolved libyaml Info-Zip unzip libtasn1OpenBSD pfctl NetBSD bpf man mandocIDA Pro clamav libxml2glibc clang llvmnasm ctags mutt procmail fontconfig pdksh Qt wavpack OpenSSH redis lua-cmsgpack taglib privoxy perl libxmp radare2 SleuthKit fwknop X.Org exifprobe jhead capnproto Xerces-C metacam djvulibre exiv Linux btrfs Knot DNS curl wpa_supplicant Apple Safari libde265 dnsmasq libbpg lame libwmf uudecode MuPDF imlib2 libraw libbson libsass yara W3C tidy- html5 VLC FreeBSD syscons John the Ripper screen tmux mosh UPX indent openjpeg MMIX OpenMPT rxvt dhcpcd Mozilla NSS Nettle mbed TLS Linux netlink Linux ext4 Linux xfs botan expat Adobe Reader libav libical OpenBSD kernel collectd libidn MatrixSSL jasperMaraDNS w3m Xen OpenH232 irssi cmark OpenCV Malheur gstreamer Tor gdk-pixbuf audiofilezstd lz4 stb cJSON libpcre MySQL gnulib openexr libmad ettercap lrzip freetds Asterisk ytnefraptor mpg123 exempi libgmime pev v8 sed awk make -

Data Compression and Archiving Software Implementation and Their Algorithm Comparison
Calhoun: The NPS Institutional Archive Theses and Dissertations Thesis Collection 1992-03 Data compression and archiving software implementation and their algorithm comparison Jung, Young Je Monterey, California. Naval Postgraduate School http://hdl.handle.net/10945/26958 NAVAL POSTGRADUATE SCHOOL Monterey, California THESIS^** DATA COMPRESSION AND ARCHIVING SOFTWARE IMPLEMENTATION AND THEIR ALGORITHM COMPARISON by Young Je Jung March, 1992 Thesis Advisor: Chyan Yang Approved for public release; distribution is unlimited T25 46 4 I SECURITY CLASSIFICATION OF THIS PAGE REPORT DOCUMENTATION PAGE la REPORT SECURITY CLASSIFICATION 1b RESTRICTIVE MARKINGS UNCLASSIFIED 2a SECURITY CLASSIFICATION AUTHORITY 3 DISTRIBUTION/AVAILABILITY OF REPORT Approved for public release; distribution is unlimite 2b DECLASSIFICATION/DOWNGRADING SCHEDULE 4 PERFORMING ORGANIZATION REPORT NUMBER(S) 5 MONITORING ORGANIZATION REPORT NUMBER(S) 6a NAME OF PERFORMING ORGANIZATION 6b OFFICE SYMBOL 7a NAME OF MONITORING ORGANIZATION Naval Postgraduate School (If applicable) Naval Postgraduate School 32 6c ADDRESS {City, State, and ZIP Code) 7b ADDRESS (City, State, and ZIP Code) Monterey, CA 93943-5000 Monterey, CA 93943-5000 8a NAME OF FUNDING/SPONSORING 8b OFFICE SYMBOL 9 PROCUREMENT INSTRUMENT IDENTIFICATION NUMBER ORGANIZATION (If applicable) 8c ADDRESS (City, State, and ZIP Code) 10 SOURCE OF FUNDING NUMBERS Program Element No Project Nc Work Unit Accession Number 1 1 TITLE (Include Security Classification) DATA COMPRESSION AND ARCHIVING SOFTWARE IMPLEMENTATION AND THEIR ALGORITHM COMPARISON 12 PERSONAL AUTHOR(S) Young Je Jung 13a TYPE OF REPORT 13b TIME COVERED 1 4 DATE OF REPORT (year, month, day) 15 PAGE COUNT Master's Thesis From To March 1992 94 16 SUPPLEMENTARY NOTATION The views expressed in this thesis are those of the author and do not reflect the official policy or position of the Department of Defense or the U.S. -

Rule Base with Frequent Bit Pattern and Enhanced K-Medoid Algorithm for the Evaluation of Lossless Data Compression
Volume 3, No. 1, Jan-Feb 2012 ISSN No. 0976-5697 International Journal of Advanced Research in Computer Science RESEARCH PAPER Available Online at www.ijarcs.info Rule Base with Frequent Bit Pattern and Enhanced k-Medoid Algorithm for the Evaluation of Lossless Data Compression. Nishad P.M.* Dr. N. Nalayini Ph.D Scholar, Department Of Computer Science Associate professor, Department of computer science NGM NGM College, Pollachi, India College Pollachi, Coimbatore, India [email protected] [email protected] Abstract: This paper presents a study of various lossless compression algorithms; to test the performance and the ability of compression of each algorithm based on ten different parameters. For evaluation the compression ratios of each algorithm on different parameters are processed. To classify the algorithms based on the compression ratio, rule base is constructed to mine with frequent bit pattern to analyze the variations in various compression algorithms. Also, enhanced K- Medoid clustering is used to cluster the various data compression algorithms based on various parameters. The cluster falls dissentingly high to low after the enhancement. The framed rule base consists of 1,048,576 rules, which is used to evaluate the compression algorithm. Two hundred and eleven Compression algorithms are used for this study. The experimental result shows only few algorithm satisfies the range “High” for more number of parameters. Keywords: Lossless compression, parameters, compression ratio, rule mining, frequent bit pattern, K–Medoid, clustering. I. INTRODUCTION the maximum shows the peek compression ratio of algorithms on various parameters, for example 19.43 is the Data compression is a method of encoding rules that minimum compression ratio and the 76.84 is the maximum allows substantial reduction in the total number of bits to compression ratio for the parameter EXE shown in table-1 store or transmit a file.