Forensic Data Recovery from the Windows Search Database
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Windows 7 Operating Guide
Welcome to Windows 7 1 1 You told us what you wanted. We listened. This Windows® 7 Product Guide highlights the new and improved features that will help deliver the one thing you said you wanted the most: Your PC, simplified. 3 3 Contents INTRODUCTION TO WINDOWS 7 6 DESIGNING WINDOWS 7 8 Market Trends that Inspired Windows 7 9 WINDOWS 7 EDITIONS 10 Windows 7 Starter 11 Windows 7 Home Basic 11 Windows 7 Home Premium 12 Windows 7 Professional 12 Windows 7 Enterprise / Windows 7 Ultimate 13 Windows Anytime Upgrade 14 Microsoft Desktop Optimization Pack 14 Windows 7 Editions Comparison 15 GETTING STARTED WITH WINDOWS 7 16 Upgrading a PC to Windows 7 16 WHAT’S NEW IN WINDOWS 7 20 Top Features for You 20 Top Features for IT Professionals 22 Application and Device Compatibility 23 WINDOWS 7 FOR YOU 24 WINDOWS 7 FOR YOU: SIMPLIFIES EVERYDAY TASKS 28 Simple to Navigate 28 Easier to Find Things 35 Easy to Browse the Web 38 Easy to Connect PCs and Manage Devices 41 Easy to Communicate and Share 47 WINDOWS 7 FOR YOU: WORKS THE WAY YOU WANT 50 Speed, Reliability, and Responsiveness 50 More Secure 55 Compatible with You 62 Better Troubleshooting and Problem Solving 66 WINDOWS 7 FOR YOU: MAKES NEW THINGS POSSIBLE 70 Media the Way You Want It 70 Work Anywhere 81 New Ways to Engage 84 INTRODUCTION TO WINDOWS 7 6 WINDOWS 7 FOR IT PROFESSIONALS 88 DESIGNING WINDOWS 7 8 WINDOWS 7 FOR IT PROFESSIONALS: Market Trends that Inspired Windows 7 9 MAKE PEOPLE PRODUCTIVE ANYWHERE 92 WINDOWS 7 EDITIONS 10 Remove Barriers to Information 92 Windows 7 Starter 11 Access -

Laptop Service Guide
Windows Operating System 3 Turn off visual effects 3 Turn off Windows Search Indexing Feature 4 Defragging Hard Drive 5 Step 1: Locating the Defragment Wizard 5 Step 2: Using Defragment Wizard 6 Checking your hard drive 8 Checking your memory 8 Ensure Windows Defender is enabled 9 Perform Disk cleanup to remove clutter 12 Disable Programs that you do not use frequently from starting when system boots 14 14 Perform regular Windows Defender scans on system 15 Uninstall programs that you do not use anymore 17 Regularly turn off your system when not in use 18 How to shut down your windows machine 19 Perform check disk on hard drive regularly 21 Turn Off Windows Tips and Tricks 23 Turn Off Search Indexing 24 Regularly perform backups as well as create restore points 27 Use Powershell to fix corrupt files: 32 Enable fast start-up: 34 Effect of ram on the system 35 2 Windows Operating System Turn off visual effects I. Open the start menu by pressing the Windows key on your keyboard or by clicking on the icon shown below. a. Type “Advanced System Settings” and click on it when it appears in the Menu. b. Navigate to the “Advanced” tab at the top. c. Click on “Settings” in the “Performance” block d. Select “Adjust for best performance”. e. Click “Ok” to finish the setup. 3 Turn off Windows Search Indexing Feature I. Open the start menu by pressing the Windows key on your keyboard or by clicking on the icon shown below. II. Search for “Index” and choose “Indexing Options” when it appears. -

Navigate Windows and Folders
Windows® 7 Step by Step by Joan Preppernau and Joyce Cox To learn more about this book, visit Microsoft Learning at http://www.microsoft.com/MSPress/books/ 9780735626676 ©2009 Joan Preppernau and Joyce Cox Early Content—Subject to Change Windows 7 Step by Step Advance Content–Subject to Change Windows 7 Step by Step Draft Table of Contents Overview Front Matter ............................................................................................................................................. 3 Contents ................................................................................................................................................ 3 About the Authors ................................................................................................................................ 3 Features and Conventions of This Book ................................................................................................ 3 Using the Companion CD ...................................................................................................................... 3 Getting Help .......................................................................................................................................... 3 Introducing Windows 7 ......................................................................................................................... 3 Part I: Getting Started with Windows 7 .................................................................................................... 4 1 Explore Windows 7 ........................................................................................................................... -

Data & Computer Recovery Guidelines
Data & Computer Recovery Guidelines Data & Computer Recovery Guidelines This document contains general guidelines for restoring computer operating following certain types of disasters. It should be noted these guidelines will not fit every type of disaster or every organization and that you may need to seek outside help to recover and restore your operations. This document is divided into five parts. The first part provides general guidelines which are independent of the type of disaster, the next three sections deal with issues surrounding specific disaster types (flood/water damage, power surge, and physical damage). The final section deals with general recommendations to prepare for the next disaster. General Guidelines 2. Your first step is to restore the computing equipment. These are general guidelines for recovering after any type If you do try to power on the existing equipment, it of disaster or computer failure. If you have a disaster is best to remove the hard drive(s) first to make sure recovery plan, then you should be prepared; however, the system will power on. Once you have determined there may be things that were not covered to help the system powers on, you can reinstall the hard drive you recover. This section is divided into two sections and power the system back on. Hopefully, everything (computer system recovery, data recovery) works at that point. Note: this should not be tried in the case of a water or extreme heat damage. Computer System Recovery 3. If the computer will not power on then you can either The first step is to get your physical computer systems try to fix the computer or in many cases it is easier, running again. -

Data Remanence in Non-Volatile Semiconductor Memory (Part I)
Data remanence in non-volatile semiconductor memory (Part I) Security Group Sergei Skorobogatov Web: www.cl.cam.ac.uk/~sps32/ Email: [email protected] Introduction Data remanence is the residual physical representation of data that has UV EPROM EEPROM Flash EEPROM been erased or overwritten. In non-volatile programmable devices, such as UV EPROM, EEPROM or Flash, bits are stored as charge in the floating gate of a transistor. After each erase operation, some of this charge remains. It shifts the threshold voltage (VTH) of the transistor which can be detected by the sense amplifier while reading data. Microcontrollers use a ‘protection fuse’ bit that restricts unauthorized access to on-chip memory if activated. Very often, this fuse is embedded in the main memory array. In this case, it is erased simultaneously with the memory. Better protection can be achieved if the fuse is located close to the memory but has a separate control circuit. This allows it to be permanently monitored as well as hardware protected from being erased too early, thus making sure that by the time the fuse is reset no data is left inside the memory. In some smartcards and microcontrollers, a password-protected boot- Structure, cross-section and operation modes for different memory types loader restricts firmware updates and data access to authorized users only. Usually, the on-chip operating system erases both code and data How much residual charge is left inside the memory cells memory before uploading new code, thus preventing any new after a standard erase operation? Is it possible to recover data application from accessing previously stored secrets. -

Databridge ETL Solution Datasheet
DATASHEET Extract and Transform MCP Host Data for Improved KEY FEATURES Client configuration tool for Analysis and Decision Support easy customization of table layout. Fast, well-informed business decisions require access to your organization’s key performance Dynamic before-and-after indicators residing on critical database systems. But the prospect of exposing those systems images (BI-AI) based on inevitably raises concerns around security, data integrity, cost, and performance. key change. 64-bit clients. For organizations using the Unisys ClearPath MCP server and its non-relational DMSII • Client-side management database, there’s an additional challenge: Most business intelligence tools support only console. relational databases. • Ability to run the client as a service or a daemon. The Only True ETL Solution for DMSII Data • Multi-threaded clients to That’s why businesses like yours are turning to Attachmate® DATABridge™. It’s the only increase processing speed. true Extract, Transform, Load (ETL) solution that securely integrates Unisys MCP DMSII • Support for Windows Server and non-DMSII data into a secondary system. 2012. • Secure automation of Unisys With DATABridge, you can easily integrate production data into a relational database or MCP data replication. another DMSII database located on an entirely different Unisys host system. And because • Seamless integration of DATABridge clients for Oracle and Microsoft SQL Server support a breadth of operating both DMSII and non-DMSII environments (including Windows 7, Windows Server 2012, Windows Server 2008, UNIX, data with Oracle, Microsoft SQL, and other relational AIX, SUSE Linux, and Red Hat Linux), DATABridge solutions fit seamlessly into your existing databases. infrastructure. -
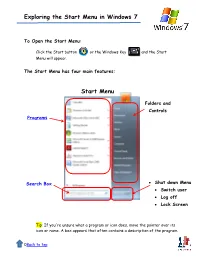
Exploring the Start Menu in Windows 7
Exploring the Start Menu in Windows 7 To Open the Start Menu: Click the Start button or the Windows Key and the Start Menu will appear. The Start Menu has four main features: Start Menu Folders and Controls Programs Shut down Menu Search Box Switch user Log off Lock Screen Tip: If you're unsure what a program or icon does, move the pointer over its icon or name. A box appears that often contains a description of the program. 0Back to top Exploring the Start Menu in Windows 7 Programs (Left Pane of the Start Menu) The programs list includes recently used programs and “Pinned” programs. Click once on a program icon to open it Jump List: If an entry has a black menu arrow, clicking on it will show a “Jump List” of recently opened and Pinned documents. Documents can be opened directly from this list. Jump List Left Click on “All Programs” to show a list of available programs and folders. Organize and move icons by left clicking, then dragging to the desired location. 0Back to top Exploring the Start Menu in Windows 7 Adding or Removing a Program on the Start Menu or Taskbar: Adding or “Pinning” a program on the Start Menu or Taskbar: 1. Find the program icon in the Start Menu, All Programs or Taskbar 2. Right click on the program icon 3. Select “Pin to Taskbar” and/or “Pin to Start Menu” 4. The icon will now be Pinned (stuck) to the selected area. 5. Icons can also be added to the Taskbar from the Start Menu by clicking on the icon in the Start Menu and dragging it to the Taskbar. -

PDF-Xchange Viewer
PDF-XChange Viewer © 2001-2011 Tracker Software Products Ltd North/South America, Australia, Asia: Tracker Software Products (Canada) Ltd., PO Box 79 Chemainus, BC V0R 1K0, Canada Sales & Admin Tel: Canada (+00) 1-250-324-1621 Fax: Canada (+00) 1-250-324-1623 European Office: 7 Beech Gardens Crawley Down., RH10 4JB Sussex, United Kingdom Sales Tel: +44 (0) 20 8555 1122 Fax: +001 250-324-1623 http://www.tracker-software.com [email protected] Support: [email protected] Support Forums: http://www.tracker-software.com/forum/ ©2001-2011 TRACKER SOFTWARE PRODUCTS II PDF-XChange Viewer v2.5x Table of Contents INTRODUCTION...................................................................................................... 7 IMPORTANT! FREE vs. PRO version ............................................................................................... 8 What Version Am I Running? ............................................................................................................................. 9 Safety Feature .................................................................................................................................................. 10 Notice! ......................................................................................................................................... 10 Files List ....................................................................................................................................... 10 Latest (available) Release Notes ................................................................................................. -
Quick Guide Page | 1
Quick Guide Page | 1 Contents Welcome to Windows 10 ................................................................................................................................................................................................... 3 Key innovations ...................................................................................................................................................................................................................... 3 Cortana ................................................................................................................................................................................................................................. 3 Microsoft Edge .................................................................................................................................................................................................................. 4 Gaming & Xbox ................................................................................................................................................................................................................ 5 Built-in apps ....................................................................................................................................................................................................................... 7 Enterprise-grade secure and fast ................................................................................................................................................................................... -

Database Analyst Ii
Recruitment No.: 20.186 Date Opened: 5/25/2021 DATABASE ANALYST II SALARY: $5,794 to $8,153 monthly (26 pay periods annually) FINAL FILING DATE: We are accepting applications until closing at 5 pm, June 8, 2021 IT IS MANDATORY THAT YOU COMPLETE THE SUPPLEMENTAL QUESTIONNAIRE. YOUR APPLICATION WILL BE REJECTED IF YOU DO NOT PROVIDE ALL NECESSARY INFORMATION. THE POSITION The Human Resources Department is accepting applications for the position of Database Analyst II. The current opening is for a limited term, benefitted and full-time position in the Information Technology department, but the list may be utilized to fill future regular and full- time vacancies for the duration of the list. The term length for the current vacancy is not guaranteed but cannot exceed 36 months. The normal work schedule is Monday through Friday, 8 – 5 pm; a flex schedule may be available. The Information Technology department is looking for a full-time, limited-term Database Analyst I/II to develop and manage the City’s Open Data platform. Initiatives include tracking city council goals, presenting data related to capital improvement projects, and measuring budget performance. This position is in the Data Intelligence Division. Our team sees data as more than rows and columns, it tells stories that yield invaluable insights that help us solve problems, make better decisions, and create solutions. This position is responsible for building and maintaining systems that unlock the power of data. The successful candidate will be able to create data analytics & business -

Error Characterization, Mitigation, and Recovery in Flash Memory Based Solid-State Drives
ERRORS, MITIGATION, AND RECOVERY IN FLASH MEMORY SSDS 1 Error Characterization, Mitigation, and Recovery in Flash Memory Based Solid-State Drives Yu Cai, Saugata Ghose, Erich F. Haratsch, Yixin Luo, and Onur Mutlu Abstract—NAND flash memory is ubiquitous in everyday life The transistor traps charge within its floating gate, which dic- today because its capacity has continuously increased and cost has tates the threshold voltage level at which the transistor turns on. continuously decreased over decades. This positive growth is a The threshold voltage level of the floating gate is used to de- result of two key trends: (1) effective process technology scaling, termine the value of the digital data stored inside the transistor. and (2) multi-level (e.g., MLC, TLC) cell data coding. Unfortu- When manufacturing process scales down to a smaller tech- nately, the reliability of raw data stored in flash memory has also nology node, the size of each flash memory cell, and thus the continued to become more difficult to ensure, because these two trends lead to (1) fewer electrons in the flash memory cell (floating size of the transistor, decreases, which in turn reduces the gate) to represent the data and (2) larger cell-to-cell interference amount of charge that can be trapped within the floating gate. and disturbance effects. Without mitigation, worsening reliability Thus, process scaling increases storage density by enabling can reduce the lifetime of NAND flash memory. As a result, flash more cells to be placed in a given area, but it also causes relia- memory controllers in solid-state drives (SSDs) have become bility issues, which are the focus of this article. -

Lookeen Desktop Search
Lookeen Desktop Search Find your files faster! User Benefits Save time by simultaneously searching for documents on your hard drive, in file servers and the network. Lookeen can also search Outlook archives, the Exchange Search with fast and reliable Server and Public Folders. Advanced filters and wildcard options make search more Lookeen technology powerful. With Lookeen you’ll turn ‘search’ into ‘find’. You’ll be able to manage and organize large amounts of data efficiently. Employees will save valuable time usually Find your information in record spent searching to work on more important tasks. time thanks to real-time indexing Lookeen desktop search can also Search your desktop, Outlook be integrated into Outlook The search tool for Windows files and Exchange folders 10, 8, 7 and Vista simultaneously Ctrl+Ctrl is back: instantly launch Edit and save changes to Lookeen from documents in Lookeen preview anywhere on your desktop Save and re-use favorite queries and access them with short keys View all correspondence with individuals or groups at the push of a button Create one-click summaries of email correspondences Start saving time and money immediately For Companies Features Business Edition Desktop search software compatible with Powerful search in virtual environments like Compatible with standard and virtual Windows 10, 8, 7 and Vista Citrix and VMware desktops like Citrix, VMware and Terminal Servers. Simplified roll out through exten- Optional add-in to Microsoft Outlook 2016, Simple, user friendly interface gives users a sive group directives and ADM files. 2013, 2010, 2007 or 2003 and Office 365 unified view over multiple data sources Automatic indexing of all files on the hard Clear presentation of search results drive, network, file servers, Outlook PST/OST- Enterprise Edition Full fidelity preview option archives, Public Folders and the Exchange Scans additional external indexes.