A Collaborative Project for the Documentation of the Shughni Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tajiki Some Useful Phrases in Tajiki Five Reasons Why You Should Ассалому Алейкум
TAJIKI SOME USEFUL PHRASES IN TAJIKI FIVE REASONS WHY YOU SHOULD ассалому алейкум. LEARN MORE ABOUT TAJIKIS AND [ˌasːaˈlɔmu aˈlɛɪkum] /asah-lomu ah-lay-koom./ THEIR LANGUAGE Hello! 1. Tajiki is spoken as a first or second language by over 8 million people worldwide, but the Hоми шумо? highest population of speakers is located in [ˈnɔmi ʃuˈmɔ] Tajikistan, with significant populations in other /No-mee shoo-moh?/ Central Eurasian countries such as Afghanistan, What is your name? Uzbekistan, and Russia. Номи ман… 2. Tajiki is a member of the Western Iranian branch [ˈnɔmi man …] of the Indo-Iranian languages, and shares many structural similarities to other Persian languages /No-mee man.../ such as Dari and Farsi. My name is… 3. Few people in America can speak or use the Tajiki Шумо чи xeл? Нағз, рахмат. version of Persian. Given the different script and [ʃuˈmɔ ʧi χɛl naʁz ɾaχˈmat] dialectal differences, simply knowing Farsi is not /shoo-moh-chee-khel? Naghz, rah-mat./ enough to fully understand Tajiki. Those who How are you? I’m fine, thank you. study Tajiki can find careers in a variety of fields including translation and interpreting, consulting, Aз вохуриамон шод ҳастам. and foreign service and intelligence. NGOs [az vɔχuˈɾiamɔn ʃɔd χaˈstam] and other enterprises that deal with Tajikistan /Az vo-khu-ri-amon shod has-tam./ desperately need specialists who speak Tajiki. Nice to meet you. 4. The Pamir Mountains which have an elevation Лутфан. / Рахмат. of 23,000 feet are known locally as the “Roof of [lutˈfan] / [ɾaχˈmat] the World”. Mountains make up more than 90 /Loot-fan./ /Rah-mat./ percent of Tajikistan’s territory. -

Computational Lexicography: a Training Programme for Language Documentation in West Africa
Computational lexicography: a training programme for language documentation in West Africa Dafydd Gibbon1 and Nadine Borchardt2 1Universität Bielefeld, 2Humboldt-Universität Berlin 1 Training lexicographers for language documentation The goal of the present contribution is to provide an overview and a practical foundation for teaching the lexicographic aspects of language documentation for local languages. Perhaps paradoxically, most of the contribution will be somewhat abstract: for reasons of space, the choice is either to be highly selective with lots of examples (the approach usually taken), or to be comprehensive and highly structured (though intermediate approaches would also have been possible). Since systematic overviews do not exist yet for modern lexicography, we have opted for the second approach. The starting point for the contribution was the need to provide teaching materials for conducting practical training courses on lexicography in language documentation at the Université de Cocody, Abidjan, Côte d’Ivoire, and the University of Uyo, Akwa Ibom State, Nigeria.1 In each case, students have B.A. level training in all areas of linguistics, and consequently, the courses can concentrate on the lexicographic subdiscipline of lexicography in language documentation. The lexicographic application domains include lexicography for field linguistics, language teaching and speech technology, three fields which seem worlds apart, but which experience shows to haveat least some similar basic lexicographic requirements. The specific task which we address is the training of local lexicographers for local language documentation activities. Based on experience of lexicography in field linguistics, language teaching and speech technology (particularly text-to-speech synthesis), we clarify our basic terminology as follows: 1. -

Shughni (Edelman & Dodykhudoeva).Pdf
DEMO : Purchase from www.A-PDF.com to remove the watermark CHAPTER FOURTEEN B SHUGHNI D. (Joy) I. Edelman and Leila R. Dodykhlldoel'a 1 INTRODUCTION 1.1 Overview The Shughni, or Shughnani, ethnic group, ethnonym xuynl, xuynl'tnl, populates the mountain valleys of the We st Pamir. Administratively, the Shughni-speaking area is part of the Mountainous Badakhshan Autonomous Region (Taj ik Viluyali /viukltlori Klihistoni Badakhsholl) of the Republic of Tajikistan, with its major center of Khorog, Taj . Khorugh (370 30/N, 710 3l/E), and of the adjacent Badakhshan Province of Afghanistan. In Tajikistan, the Shughn(an)i live along the right bank of the longitudinal stretch of the river Panj from (Zewar) Dasht in the North to Darmorakht in the south, as well as along the valleys of its eastern tributaries, the Ghund (rlll1d, Taj ik ru nt) and the Shahdara (Xa"tdarii), which meet at Khorog. They also constitute the major population group in the high mountain valley of Baju(w)dara (Bafli (l I>}darii) to the north of Khorog. Small, compact groups are also fo und in central Tajikistan, including Khatlon, Romit, Kofarnikhon, and other regions. In Afghanistan, the Shughn(an)i have also compact settlements, mainly on the left bank of the river Panj in Badakhshan Province. A sizeable Shughn(an)i-speaking com munity is also fo und in Kabul (cf. Nawata 1979) and in Faizabad, the capital of Afghan Badakhshan. Linguistically, the Shughn(an)i language, endonym (xlIyn (I.ln)l, Xll)i/1(lln)J zil'. XUYIUII1 zil'), belongs to the Shughn(an)i-Rushani sub-group of the North Pamir languages. -

Language Documentation and Description
Language Documentation and Description ISSN 1740-6234 ___________________________________________ This article appears in: Language Documentation and Description, vol 12: Special Issue on Language Documentation and Archiving. Editors: David Nathan & Peter K. Austin Archiving grammatical descriptions SEBASTIAN NORDHOFF, HARALD HAMMARSTRÖM Cite this article: Sebastian Nordhoff, Harald Hammarström (2014). Archiving grammatical descriptions. In David Nathan & Peter K. Austin (eds) Language Documentation and Description, vol 12: Special Issue on Language Documentation and Archiving. London: SOAS. pp. 164- 186 Link to this article: http://www.elpublishing.org/PID/143 This electronic version first published: July 2014 __________________________________________________ This article is published under a Creative Commons License CC-BY-NC (Attribution-NonCommercial). The licence permits users to use, reproduce, disseminate or display the article provided that the author is attributed as the original creator and that the reuse is restricted to non-commercial purposes i.e. research or educational use. See http://creativecommons.org/licenses/by-nc/4.0/ ______________________________________________________ EL Publishing For more EL Publishing articles and services: Website: http://www.elpublishing.org Terms of use: http://www.elpublishing.org/terms Submissions: http://www.elpublishing.org/submissions Archiving grammatical descriptions Sebastian Nordhoff and Harald Hammarström Max Planck Institute for Evolutionary Anthropology, Leipzig 1. Introduction Language documentation projects produce and collect audio, video, and textual data, which they usually deposit in archives. Documenters’ understanding of best practices in archiving the primary content of their domain has made considerable progress over recent years. Methods for archiving derived content, such as dictionaries and especially grammatical descriptions, have received less attention. In this paper, we explore what the goals of archiving grammatical descriptions are, and what tasks an archive has to fulfill. -

The Iranian Reflexes of Proto-Iranian *Ns
The Iranian Reflexes of Proto-Iranian *ns Martin Joachim Kümmel, Friedrich-Schiller-Universität Jena [email protected] Abstract1 The obvious cognates of Avestan tąθra- ‘darkness’ in the other Iranian languages generally show no trace of the consonant θ; they all look like reflexes of *tār°. Instead of assuming a different word formation for the non-Avestan words, I propose a solution uniting the obviously corresponding words under a common preform, starting from Proto-Iranian *taNsra-: Before a sonorant *ns was preserved as ns in Avestan (feed- ing the change of tautosyllabic *sr > *θr) but changed to *nh elsewhere, followed by *anhr > *ã(h)r. A parallel case of apparent variation can be explained similarly, namely Avestan pąsnu- ‘ashes’ and its cog- nates. Finally, the general development of Proto-Indo-Iranian *ns in Iranian and its relative chronology is discussed, including word-final *ns, where it is argued that the Avestan accusative plural of a-stems can be derived from *-āns. Keywords: Proto-Iranian, nasals, sibilant, sound change, variation, chronology 1. Introduction The aim of this paper is to discuss some details of the development of the Proto- Iranian (PIr) cluster *ns in the Iranian languages. Before we proceed to do so, it will be useful to recall the most important facts concerning the history of dental-alveolar sibilants in Iranian. 1) PIr had inherited a sibilant *s identical to Old Indo-Aryan (Sanskrit/Vedic) s from Proto-Indo-Iranian (PIIr) *s. This sibilant changed to Common Iranian (CIr) h in most environments, while its voiced allophone z remained stable all the time. -

The Socio Linguistic Situation and Language Policy of the Autonomous Region of Mountainous Badakhshan: the Case of the Tajik Language*
THE SOCIO LINGUISTIC SITUATION AND LANGUAGE POLICY OF THE AUTONOMOUS REGION OF MOUNTAINOUS BADAKHSHAN: THE CASE OF THE TAJIK LANGUAGE* Leila Dodykhudoeva Institute Of Linguistics, Russian Academy Of Sciences The paper deals with the problem of closely related languages of the Eastern and Western Iranian origin that coexist in a close neighbourhood in a rather compact area of one region of Republic Tajikistan. These are a group of "minor" Pamir languages and state language of Tajikistan - Tajik. The population of the Autonomous Region of Mountainous Badakhshan speaks different Pamir languages. They are: Shughni, Rushani, Khufi, Bartangi, Roshorvi, Sariqoli; Yazghulami; Wakhi; Ishkashimi. These languages have no script and written tradition and are used only as spoken languages in the region. The status of these languages and many other local linguemes is still discussed in Iranology. Nearly all Pamir languages to a certain extent can be called "endangered". Some of these languages, like Yazghulami, Roshorvi, Ishkashimi are included into "The Red Book " (UNESCO 1995) as "endangered". Some of them are extinct. Information on other idioms up to now is not available. These languages live in close cooperation and interaction with the state language of Tajikistan - Tajik. Almost all population of Badakhshan is multilingual or bilingual. The second language is official language of the state - Tajik. This language is used in Badakhshan as the language of education, press, media, and culture. This is the reason why this paper is focused on the status of Tajik language in Republic Tajikistan and particularly in Badakhshan. The Tajik literary language (its oral and written forms) has a long history and rich written traditions. -

M. Witzel (2003) Sintashta, BMAC and the Indo-Iranians. a Query. [Excerpt
M. Witzel (2003) Sintashta, BMAC and the Indo-Iranians. A query. [excerpt from: Linguistic Evidence for Cultural Exchange in Prehistoric Western Central Asia] (to appear in : Sino-Platonic Papers 129) Transhumance, Trickling in, Immigration of Steppe Peoples There is no need to underline that the establishment of a BMAC substrate belt has grave implications for the theory of the immigration of speakers of Indo-Iranian languages into Greater Iran and then into the Panjab. By and large, the body of words taken over into the Indo-Iranian languages in the BMAC area, necessarily by bilingualism, closes the linguistic gap between the Urals and the languages of Greater Iran and India. Uralic and Yeneseian were situated, as many IIr. loan words indicate, to the north of the steppe/taiga boundary of the (Proto-)IIr. speaking territories (§2.1.1). The individual IIr. languages are firmly attested in Greater Iran (Avestan, O.Persian, Median) as well as in the northwestern Indian subcontinent (Rgvedic, Middle Vedic). These materials, mentioned above (§2.1.) and some more materials relating to religion (Witzel forthc. b) indicate an early habitat of Proto- IIr. in the steppes south of the Russian/Siberian taiga belt. The most obvious linguistic proofs of this location are the FU words corresponding to IIr. Arya "self-designation of the IIr. tribes": Pre-Saami *orja > oarji "southwest" (Koivulehto 2001: 248), ārjel "Southerner", and Finnish orja, Votyak var, Syry. ver "slave" (Rédei 1986: 54). In other words, the IIr. speaking area may have included the S. Ural "country of towns" (Petrovka, Sintashta, Arkhaim) dated at c. -
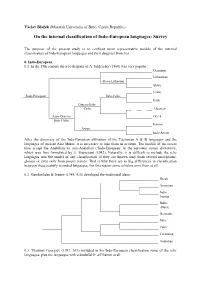
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

On the Role and Utility of Grammars in Language Documentation and Conservation
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by ScholarSpace at University of Hawai'i at Manoa Language Documentation & Conservation Special Publication No. 8 (July 2014): The Art and Practice of Grammar Writing, ed. by Toshihide Nakayama and Keren Rice, pp. 53-67 http://nflrc.hawaii.edu/ldc/ 4 http://hdl.handle.net/10125/4584 On the role and utility of grammars in language documentation and conservation Kenneth L. Rehg University of Hawaiʻi at Mānoa The National Science Foundation warns that at least half of the world’s approximately seven thousand languages are soon to be lost. In response to this impending crisis, a new subfield of linguistics has emerged, called language documentation or, alternatively, documentary linguistics. The goal of this discipline is to create lasting, multipurpose records of endangered languages before they are lost forever. However, while there is widespread agreement among linguists concerning the methods of language documen- tation, there are considerable differences of opinion concerning what its products should be. Some documentary linguists argue that the outcome of language documentation should be a large corpus of extensively annotated data. Reference grammars and dictionaries, they contend, are the products of language description and are not essential products of language documentation. I argue, however, that grammars (and dictionaries) should normally be included in the documentary record, if our goal is to produce products that are maximally useful to both linguists and speakers, now and in the future. I also show that an appropri- ately planned reference grammar can serve as a foundation for a variety of community grammars, the purposes of which are to support and conserve threatened languages. -

The Linguistic History of Some Indian Domestic Plants the Harvard
The Linguistic History of Some Indian Domestic Plants The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters. Witzel, Michael. 2009. The linguistic history of some Indian Citation domestic plants. Journal of BioSciences 34(6): 829-833. Published Version doi:10.1007/s12038-009-0096-1 Accessed April 17, 2018 3:26:20 PM EDT Citable Link http://nrs.harvard.edu/urn-3:HUL.InstRepos:8954814 This article was downloaded from Harvard University's DASH Terms of Use repository, and is made available under the terms and conditions applicable to Open Access Policy Articles, as set forth at http://nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms- of-use#OAP (Article begins on next page) Michael Witzel, Harvard University [email protected] THE LINGUISTIC HISTORY OF SOME INDIAN DOMESTIC PLANTS From* the mist of times emerge our earliest Indian texts, the Ṛgveda (c. 1300 -1000 BCE), composed in the Northwest of the subcontinent, and the Sangam texts (c. 2nd cent. BCE - early CE), composed in the extreme South. They contain valuable materials in archaic Indo-Aryan (Vedic Sanskrit) and in archaic Old Tamil respectively. The former belongs, along with Old Iranian (Avestan of Zarathustra), to the ancient Indo-Iranian subfamily of Indo-European that stretches from Iceland to Assam and Sri Lanka.1 The latter belongs to the Dravidian family2 that is restricted to the subcontinent but may have relatives in Northern Asia (Uralic) and beyond.3 As for the plant names found in these old sources, it must be observed that recent advances in archaeobotany4 indicate at least three major nuclei of food production in the subcontinent. -

A Guide to the Syuba (Kagate) Language Documentation Corpus
Vol. 12 (2018), pp. 204–234 http://nflrc.hawaii.edu/ldc http://hdl.handle.net/10125/24768 Revised Version Received: 17 Jan 2018 A Guide to the Syuba (Kagate) Language Documentation Corpus Lauren Gawne SOAS University of London La Trobe University This article provides an overview of the collection “Kagate (Syuba)”, archived with both the Pacific and Regional Archive for Digital Sources in Endangered Cultures (PARADISEC) and the Endangered Language Archive (ELAR). It pro- vides an overview of the materials that have been archived, as well as details of the workflow, conventions used, and structure of the collection. It also provides context for the content of the collection, including an overview of the language context, and some of the motivations behind the documentation project. This article thus provides an entry point to the collection. The future plans for the collection – from the perspectives of both the researcher and Syuba speakers – are also outlined, but with the overwhelming majority of items in the collection available to others, it is hoped that this article will encourage use of the materials by other researchers. 1. Introduction Language documentation involves the development of corpora of materials from which descriptions of grammar and language use can be developed, alongside other uses of the materials by both speakers of the language and researchers. Himmelmann (1998) argues that language documentation and description are two distinct, but interrelated, activities. In reality, the majority of basic linguistic descrip- tion based on primary data is undertaken by the same person who collected the data. Very little of this descriptive work makes clear the nature of the data on which it is built; in a survey of 50 published grammars and 50 PhD dissertations, Gawne et al. -

[email protected] Bloomington, in 47405 Website
JASON SION MOKHTARIAN Department of Religious Studies Indiana University 230 Sycamore Hall, 1033 E. 3rd St. Email: [email protected] Bloomington, IN 47405 Website: www.jasonmokhtarian.com ACADEMIC EMPLOYMENT Indiana University, Associate Professor with tenure (2018-present; Assistant Professor, 2011-2018), Department of Religious Studies Director, Olamot Center for Scholarly and Cultural Exchange with Israel (2018– present) Core Faculty, Borns Jewish Studies Program Adjunct Professor in Central Eurasian Studies, History, Near Eastern Languages and Cultures, Ancient Studies, and Islamic Studies EDUCATION University of California, Los Angeles Ph.D., Dept. of Near Eastern Languages and Cultures (Late Antique Judaism), 2011 University of California, Los Angeles M.A., Dept. of Near Eastern Languages and Cultures (Ancient Iranian Studies), 2007 Hebrew University of Jerusalem Research Fellow in Talmud and Iranian Studies, 2006 University of Chicago Divinity School M.A., History of Judaism, 2004 University of Chicago B.A./A.M., English and Religious Studies, 2001 RESEARCH INTERESTS Rabbinics, ancient Iranian studies, Talmud in its Sasanian context, comparative religion, ancient Jewish magic and medicine, Aramaic magic bowls, Zoroastrianism, Middle Persian (Pahlavi) literature, Judeo-Persian literature, religious interactions in early Islamic Iran, Jews of Persia RESEARCH LANGUAGES Hebrew, Aramaic (Talmud), Old Persian, Middle Persian, Modern Persian, Avestan, Arabic, French, German MOKHTARIAN, Curriculum Vitae 2 ______________________________________________________________________________________________ PUBLICATIONS BOOKS Rabbis, Sorcerers, Kings, and Priests: The Culture of the Talmud in Ancient Iran. Oakland: University of California Press, 2015. Medicine in the Talmud: Natural and Supernatural Remedies between Magic and Science. Under review. JOURNAL ARTICLES “Zoroastrian Polemics against Judaism in the Škand Gumānīg Wizār (Doubt-Dispelling Exposition).” Mizan: Journal for the Study of Muslim Societies and Civilizations 3 (2018).