Tony Hey Vice President Microsoft Research Big Data and the Fourth Paradigm Data Size and Speed Are Growing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The UK E-Science Core Programme and the Grid Tony Hey∗, Anne E
Future Generation Computer Systems 18 (2002) 1017–1031 The UK e-Science Core Programme and the Grid Tony Hey∗, Anne E. Trefethen UK e-Science Core Programme EPSRC, Polaris House, North Star Avenue, Swindon SN2 1ET, UK Abstract This paper describes the £120M UK ‘e-Science’ (http://www.research-councils.ac.uk/and http://www.escience-grid.org.uk) initiative and begins by defining what is meant by the term e-Science. The majority of the £120M, some £75M, is funding large-scale e-Science pilot projects in many areas of science and engineering. The infrastructure needed to support such projects must permit routine sharing of distributed and heterogeneous computational and data resources as well as supporting effective collaboration between groups of scientists. Such an infrastructure is commonly referred to as the Grid. Apart from £10M towards a Teraflop computer, the remaining funds, some £35M, constitute the e-Science ‘Core Programme’. The goal of this Core Programme is to advance the development of robust and generic Grid middleware in collaboration with industry. The key elements of the Core Programme will be outlined including details of a UK e-Science Grid testbed. The pilot e-Science projects that have so far been announced are then briefly described. These projects span a range of disciplines from particle physics and astronomy to engineering and healthcare, and illustrate the breadth of the UK e-Science Programme. In addition to these major e-Science projects, the Core Programme is funding a series of short-term e-Science demonstrators across a number of disciplines as well as projects in network traffic engineering and some international collaborative activities. -

Online Visualization of Geospatial Stream Data Using the Worldwide Telescope
Online Visualization of Geospatial Stream Data using the WorldWide Telescope Mohamed Ali#, Badrish Chandramouli*, Jonathan Fay*, Curtis Wong*, Steven Drucker*, Balan Sethu Raman# #Microsoft SQL Server, One Microsoft Way, Redmond WA 98052 {mali, sethur}@microsoft.com *Microsoft Research, One Microsoft Way, Redmond WA 98052 {badrishc, jfay, curtis.wong, sdrucker}@microsoft.com ABSTRACT execution query pipeline. StreamInsight has been used in the past This demo presents the ongoing effort to meld the stream query to process geospatial data, e.g., in traffic monitoring [4, 5]. processing capabilities of Microsoft StreamInsight with the On the other hand, the WorldWide Telescope (WWT) [9] enables visualization capabilities of the WorldWide Telescope. This effort a computer to function as a virtual telescope, bringing together provides visualization opportunities to manage, analyze, and imagery from the various ground and space-based telescopes in process real-time information that is of spatio-temporal nature. the world. WWT enables a wide range of user experiences, from The demo scenario is based on detecting, tracking and predicting narrated guided tours from astronomers and educators featuring interesting patterns over historical logs and real-time feeds of interesting places in the sky, to the ability to explore the features earthquake data. of planets. One interesting feature of WWT is its use as a 3-D model of earth, enabling its use as an earth viewer. 1. INTRODUCTION Real-time stream data acquisition has been widely used in This demo presents the ongoing work at Microsoft Research and numerous applications such as network monitoring, Microsoft SQL Server groups to meld the value of stream query telecommunications data management, security, manufacturing, processing of StreamInsight with the unique visualization and sensor networks. -

Licensing Information User Manual Release 9.1 F13415-01
Oracle® Hospitality Cruise Fleet Management Licensing Information User Manual Release 9.1 F13415-01 August 2019 LICENSING INFORMATION USER MANUAL Oracle® Hospitality Fleet Management Licensing Information User Manual Version 9.1 Copyright © 2004, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Seeing the Sky Visualization & Astronomers
Seeing the Sky Visualization & Astronomers Alyssa A. Goodman Harvard Smithsonian Center for Astrophysics & Radcliffe Institute for Advanced Study @aagie WorldWide Telescope Gm1m2 F= gluemultidimensional data exploration R2 Cognition “Paper of the Future” Language* Data Pictures Communication *“Language” includes words & math Why Galileo is my Hero Explore-Explain-Explore Notes for & re-productions of Siderius Nuncius 1610 WorldWide Telescope Galileo’s New Order, A WorldWide Telescope Tour by Goodman, Wong & Udomprasert 2010 WWT Software Wong (inventor, MS Research), Fay (architect, MS Reseearch), et al., now open source, hosted by AAS, Phil Rosenfield, Director see wwtambassadors.org for more on WWT Outreach WorldWide Telescope Galileo’s New Order, A WorldWide Telescope Tour by Goodman, Wong & Udomprasert 2010 WWT Software Wong (inventor, MS Research), Fay (architect, MS Reseearch), et al., now open source, hosted by AAS, Phil Rosenfield, Director see wwtambassadors.org for more on WWT Outreach Cognition “Paper of the Future” Language* Data Pictures Communication *“Language” includes words & math enabled by d3.js (javascript) outputs d3po Cognition Communication [demo] [video] Many thanks to Alberto Pepe, Josh Peek, Chris Beaumont, Tom Robitaille, Adrian Price-Whelan, Elizabeth Newton, Michelle Borkin & Matteo Cantiello for making this posible. 1610 4 Centuries from Galileo to Galileo 1665 1895 2009 2015 WorldWide Telescope Gm1m2 F= gluemultidimensional data exploration R2 WorldWide Telescope gluemultidimensional data exploration WorldWide Telescope gluemultidimensional data exploration Data, Dimensions, Display 1D: Columns = “Spectra”, “SEDs” or “Time Series” 2D: Faces or Slices = “Images” 3D: Volumes = “3D Renderings”, “2D Movies” 4D:4D Time Series of Volumes = “3D Movies” Data, Dimensions, Display Spectral Line Observations Loss of 1 dimension Mountain Range No loss of information Data, Dimensions, Display mm peak (Enoch et al. -
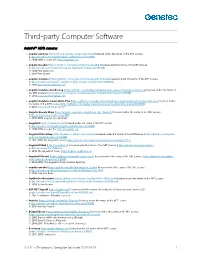
Software License Agreement (EULA)
Third-party Computer Software AutoVu™ ALPR cameras • angular-animate (https://docs.angularjs.org/api/ngAnimate) licensed under the terms of the MIT License (https://github.com/angular/angular.js/blob/master/LICENSE). © 2010-2016 Google, Inc. http://angularjs.org • angular-base64 (https://github.com/ninjatronic/angular-base64) licensed under the terms of the MIT License (https://github.com/ninjatronic/angular-base64/blob/master/LICENSE). © 2010 Nick Galbreath © 2013 Pete Martin • angular-translate (https://github.com/angular-translate/angular-translate) licensed under the terms of the MIT License (https://github.com/angular-translate/angular-translate/blob/master/LICENSE). © 2014 [email protected] • angular-translate-handler-log (https://github.com/angular-translate/bower-angular-translate-handler-log) licensed under the terms of the MIT License (https://github.com/angular-translate/angular-translate/blob/master/LICENSE). © 2014 [email protected] • angular-translate-loader-static-files (https://github.com/angular-translate/bower-angular-translate-loader-static-files) licensed under the terms of the MIT License (https://github.com/angular-translate/angular-translate/blob/master/LICENSE). © 2014 [email protected] • Angular Google Maps (http://angular-ui.github.io/angular-google-maps/#!/) licensed under the terms of the MIT License (https://opensource.org/licenses/MIT). © 2013-2016 angular-google-maps • AngularJS (http://angularjs.org/) licensed under the terms of the MIT License (https://github.com/angular/angular.js/blob/master/LICENSE). © 2010-2016 Google, Inc. http://angularjs.org • AngularUI Bootstrap (http://angular-ui.github.io/bootstrap/) licensed under the terms of the MIT License (https://github.com/angular- ui/bootstrap/blob/master/LICENSE). -
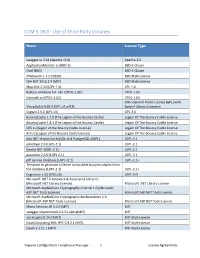
CCM 5.18.0 - Use of Third-Party Libraries
CCM 5.18.0 - Use of Third-Party Libraries Name License Type swagger-ui 3.24 (Apache v2.0) Apache-2.0 ApplicationMonitor.cs (BSD-2) BSD-2-Clause Oval (BSD) BSD-3-Clause IPNetwork 1.3.2.0 (BSD) BSD-Style License SSH.NET 2016.1.0 (MIT) BSD-Style License Mvp.Xml 2.3.0 (CPL-1.0) CPL-1.0 balloon windows for .net (CPOL-1.02) CPOL-1.02 Colorutil.cs (CPOL-1.02) CPOL-1.02 GNU General Public License (GPL) with SharpZipLib 0.81.0 (GPL v2 w/CE) Special Library Exception Cygwin 2.6.0 (GPL v3) GPL-3.0 BouncyCastle 1.7.0 (The Legion of the Bouncy Castle) Legion Of The Bouncy Castle License BouncyCastle 1.8.1 (The Legion of the Bouncy Castle) Legion Of The Bouncy Castle License DES.cs (Legion of the Bouncy Castle License) Legion Of The Bouncy Castle License Rc4.cs (Legion of the Bouncy Castle License) Legion Of The Bouncy Castle License Ado.NET drivers for MySQL and PostgreSQL (LGPL) LGPL-2.1 adodbapi 2.0 (LGPL-2.1) LGPL-2.1 Gentle.NET (LGPL-2.1) LGPL-2.1 paramiko 2.6.0 (LGPL 2.1) LGPL-2.1 p0f service database (LGPL v2.1) LGPL-2.1+ Template to generate a Gentle compatible business object from the database (LGPL-2.1) LGPL-2.1+ Cygrunsrv 1.62 (LPGLv3) LGPL-3.0 Microsoft .NET Framework & Associated Libraries (Microsoft.NET Library License) Microsoft .NET Library License Microsoft.AspNetCore.Cryptography.Internal 1.0 (Microsoft ASP.NET Tools License) Microsoft ASP.NET Tools License Microsoft.AspNetCore.Cryptography.KeyDerivation 1.0 (Microsoft ASP.NET Tools License) Microsoft ASP.NET Tools License Mono.Security.dll 4.0.0 (MIT) MIT swagger.objectmodel-2.2.31-alpha(MIT) -

The Fourth Paradigm
ABOUT THE FOURTH PARADIGM This book presents the first broad look at the rapidly emerging field of data- THE FOUR intensive science, with the goal of influencing the worldwide scientific and com- puting research communities and inspiring the next generation of scientists. Increasingly, scientific breakthroughs will be powered by advanced computing capabilities that help researchers manipulate and explore massive datasets. The speed at which any given scientific discipline advances will depend on how well its researchers collaborate with one another, and with technologists, in areas of eScience such as databases, workflow management, visualization, and cloud- computing technologies. This collection of essays expands on the vision of pio- T neering computer scientist Jim Gray for a new, fourth paradigm of discovery based H PARADIGM on data-intensive science and offers insights into how it can be fully realized. “The impact of Jim Gray’s thinking is continuing to get people to think in a new way about how data and software are redefining what it means to do science.” —Bill GaTES “I often tell people working in eScience that they aren’t in this field because they are visionaries or super-intelligent—it’s because they care about science The and they are alive now. It is about technology changing the world, and science taking advantage of it, to do more and do better.” —RhyS FRANCIS, AUSTRALIAN eRESEARCH INFRASTRUCTURE COUNCIL F OURTH “One of the greatest challenges for 21st-century science is how we respond to this new era of data-intensive -

How Do Astronomers Share Data? Reliability and Persistence of Datasets Linked in AAS Publications and a Qualitative Study of Data Practices Among US Astronomers
How Do Astronomers Share Data? Reliability and Persistence of Datasets Linked in AAS Publications and a Qualitative Study of Data Practices among US Astronomers The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Pepe, Alberto, Alyssa Goodman, August Muench, Merce Crosas, and Christopher Erdmann. 2014. “How Do Astronomers Share Data? Reliability and Persistence of Datasets Linked in AAS Publications and a Qualitative Study of Data Practices among US Astronomers.” PLoS ONE 9 (8): e104798. doi:10.1371/journal.pone.0104798. http:// dx.doi.org/10.1371/journal.pone.0104798. Published Version doi:10.1371/journal.pone.0104798 Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:12785853 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA How Do Astronomers Share Data? Reliability and Persistence of Datasets Linked in AAS Publications and a Qualitative Study of Data Practices among US Astronomers Alberto Pepe1,2*, Alyssa Goodman1,2, August Muench1, Merce Crosas2, Christopher Erdmann1 1 Harvard-Smithsonian Center for Astrophysics, Cambridge, Massachusetts, United States of America, 2 Institute for Quantitative Social Science, Harvard University, Cambridge, Massachusetts, United States of America Abstract We analyze data sharing practices of astronomers over the past fifteen years. An analysis of URL links embedded in papers published by the American Astronomical Society reveals that the total number of links included in the literature rose dramatically from 1997 until 2005, when it leveled off at around 1500 per year. -

Microsoft Protégé 2012 Case Study Brief OVERVIEW
Microsoft Protégé 2012 Case Study Brief OVERVIEW If you’re an Australian undergraduate Uni student, you’re eligible to enter the Microsoft Protégé Challenge. Your task is to show us how you would market Microsoft Kinect for Windows for use outside the gaming industry. This Case Study Brief gives you some background info, outlines the challenge and details the rules for entry. This is your chance to get your teeth into a real-life marketing challenge and gain experience that will make your CV stand out. And if you’re the Protégé 2012 Grand Prize winner, you’ll also score an amazing prize pack. BACKGROUND: THE KINECT EFFECT Headquartered in Redmond, USA, Microsoft Corporation gestures captured by the 3D sensor as well as the voice is one of the world’s largest technology companies and a commands captured by the microphone array from pioneer in software products for computing devices. someone much further away than someone using a headset or a phone. More importantly, Kinect software can In May 2005, Microsoft released the second iteration of its understand what each user means by a particular gesture hugely popular Xbox video game console, the Xbox 360. or command across a wide range of possible shapes, sizes, Helping the Xbox 360 in its success was the introduction of and actions of real people. Kinect, which became a gaming phenomenon overnight. People were inspired. Six months down the track, a diverse Through the magic of Kinect, controller-free games and group of hobbyists and academics from around the world entertainment – once the stuff of science fiction – had embraced the possibilities of using Kinect with their become a reality. -

A Satellite Constellation Visualization Program for Walkers and Lattice
BOUQUET: A SATELLITE CONSTELLATION VISUALIZATION PROGRAM FOR WALKERS AND LATTICE FLOWER CONSTELLATIONS A Thesis by MANDAKH ENKH Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE August 2011 Major Subject: Aerospace Engineering Bouquet: A Satellite Constellation Visualization Program for Walkers and Lattice Flower Constellations Copyright 2011 Mandakh Enkh BOUQUET: A SATELLITE CONSTELLATION VISUALIZATION PROGRAM FOR WALKERS AND LATTICE FLOWER CONSTELLATIONS A Thesis by MANDAKH ENKH Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Approved by: Chair of Committee, Daniele Mortari Committee Members, John Hurtado John Junkins J. Maurice Rojas Head of Department, Dimitris Lagoudas August 2011 Major Subject: Aerospace Engineering iii ABSTRACT Bouquet: A Satellite Constellation Visualization Program for Walkers and Lattice Flower Constellations. (August 2011) Mandakh Enkh, B.S., Texas A&M University Chair of Advisory Committee: Dr. Daniele Mortari The development of the Flower Constellation theory offers an expanded framework to utilize constellations of satellites for tangible interests. To realize the full potential of this theory, the beta version of Bouquet was developed as a practical computer application that visualizes and edits Flower Constellations in a user-friendly manner. Programmed using C++ and OpenGL within the Qt software development environment for use on Windows systems, this initial version of Bouquet is capable of visualizing numerous user defined satellites in both 3D and 2D, and plot trajectories corresponding to arbitrary coordinate frames. The ultimate goal of Bouquet is to provide a viable open source alternative to commercial satellite orbit analysis programs. -

Presented by Alyssa Goodman, Center for Astrophysics | Harvard & Smithsonian, Radcliffe Institute for Advanced Study
The Radcliffe Wave presented by Alyssa Goodman, Center for Astrophysics | Harvard & Smithsonian, Radcliffe Institute for Advanced Study Nature paper by: João Alves1,3, Catherine Zucker2, Alyssa Goodman2,3, Joshua Speagle2, Stefan Meingast1, Thomas Robitaille4, Douglas Finkbeiner3, Edward Schlafly5 & Gregory Green6 representing (1) University of Vienna; (2) Harvard University; (3) Radcliffe Insitute; (4) Aperio Software; (5) Lawrence Berkeley National Laboratory; (6) Kavli Insitute for Particle Physics and Cosmology The Radcliffe Wave CARTOON* DATA *drawn by Dr. Robert Hurt, in collaboration with Milky Way experts based on data; as shown in screenshot from AAS WorldWide Telescope The Radcliffe Wave Each red dot marks a star-forming blob of gas whose distance from us has been accurately measured. The Radcliffe Wave is 9000 light years long, and 400 light years wide, with crest and trough reaching 500 light years out of the Galactic Plane. Its gas mass is more than three million times the mass of the Sun. video created by the authors using AAS WorldWide Telescope (includes cartoon Milky Way by Robert Hurt) The Radcliffe Wave ACTUALLY 2 IMPORTANT DEVELOPMENTS DISTANCES!! RADWAVE We can now Surprising wave- measure distances like arrangement to gas clouds in our of star-forming gas own Milky Way is the “Local Arm” galaxy to ~5% of the Milky Way. accuracy. Zucker et al. 2019; 2020 Alves et al. 2020 “Why should I believe all this?” DISTANCES!! We can now requires special measure distances regions on the Sky to gas clouds in our (HII regions own Milky Way with masers) galaxy to ~5% accuracy. can be used anywhere there’s dust & measurable stellar properties Zucker et al. -

On Realizing the Concept Study Sciencesoft of the European Middleware Initiative Open Software for Open Science
On Realizing the Concept Study ScienceSoft of the European Middleware Initiative Open Software for Open Science Alberto Di Meglio, Florida Estrella Morris Riedel European Center for Nuclear Research Juelich Supercomputing Centre CERN Forschungszentrum Juelich Geneva, Switzerland Juelich, Germany {Alberto.Di.Meglio,Florida Estrella}@cern.ch [email protected] Abstract—In September 2011 the European Middleware focused on people and their publications, but do not currently Initiative (EMI) started discussing the feasibility of creating an allow collecting information about software and the open source community for science with other projects like EGI, organizations and projects developing or using it. Being able to StratusLab, OpenAIRE, iMarine, and IGE, SMEs like DCore, aggregate the power of cataloguing services of software, Maat, SixSq, SharedObjects, communities like WLCG and people and organizations, analyse trends and generate statistics LSGC. The general idea of establishing an open source and reports would provide a sound basis for judging the community dedicated to software for scientific applications was popularity of software products, enable social-networking-style understood and appreciated by most people. However, the lack of collaborations amongst users and developers, create active, a precise definition of goals and scope is a limiting factor that has cross-disciplinary communities and better promote the value of also made many people sceptical of the initiative. In order to such collaborations and their impact on science in general. understand more precisely what such an open source initiative should do and how, EMI has started a more formal feasibility Rating software and providing a means by which it can be cited study around a concept called ScienceSoft – Open Software for in a similar manner to publications and datasets would enable Open Science.