DGT-Translation Memory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Translation at the European Commission – a History
ç HC-30-08-397-EN-C Translation at the European Commission – a history Commission at the European Translation Translation at the European Commission – a history ISBN 978-92-79-08849-0 European Commission Translation at the European Commission – a history European Commission Europe Direct is a service to help you find answers to your questions about the European Union Freephone number (*): 00 800 6 7 8 9 10 11 (*) Certain mobile telephone operators do not allow access to 00 800 numbers or these calls may be billed. More information on the European Union is available on the Internet (http://europa.eu). Cataloguing data can be found at the end of this publication. The content of this publication does not necessarily reflect the position or views of the European Commission Luxembourg: Office for Official Publications of the European Communities, 2010 ISBN 978-92-79-08849-0 doi: 10.2782/16417 © European Communities, 2010 Reproduction is authorised provided the source is acknowledged. Printed in Spain PRINTED ON WHITE CHLORINE-FREE PAPER Acknowledgments In early 2008 the European Commission’s Directorate-General for Translation decided to take stock of its first half-century of work. To put this into effect we consulted numerous sources of documentation, including of course the Commission’s historical archives, and spoke to a hundred or so former and current members of the translation service and to representatives of other Directorates-General. While writing the first draft we realised that this retrospective might be of interest to a wider audience than the Institution’s staff alone. That is how this publication came about. -
Eurostat: Recognized Research Entity
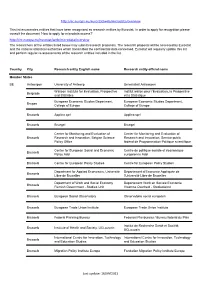
http://ec.europa.eu/eurostat/web/microdata/overview This list enumerates entities that have been recognised as research entities by Eurostat. In order to apply for recognition please consult the document 'How to apply for microdata access?' http://ec.europa.eu/eurostat/web/microdata/overview The researchers of the entities listed below may submit research proposals. The research proposal will be assessed by Eurostat and the national statistical authorities which transmitted the confidential data concerned. Eurostat will regularly update this list and perform regular re-assessments of the research entities included in the list. Country City Research entity English name Research entity official name Member States BE Antwerpen University of Antwerp Universiteit Antwerpen Walloon Institute for Evaluation, Prospective Institut wallon pour l'Evaluation, la Prospective Belgrade and Statistics et la Statistique European Economic Studies Department, European Economic Studies Department, Bruges College of Europe College of Europe Brussels Applica sprl Applica sprl Brussels Bruegel Bruegel Center for Monitoring and Evaluation of Center for Monitoring and Evaluation of Brussels Research and Innovation, Belgian Science Research and Innovation, Service public Policy Office fédéral de Programmation Politique scientifique Centre for European Social and Economic Centre de politique sociale et économique Brussels Policy Asbl européenne Asbl Brussels Centre for European Policy Studies Centre for European Policy Studies Department for Applied Economics, -

Regional Resilience and Discontent in the European Union
Draft and reduced version of the paper: Regional Resilience and Discontent in the European Union Chiara Ferrante Sapienza University of Rome Marco Colagrossi European Commission, Joint Research Centre (JRC), Ispra Nicola Pontarollo European Commission, Joint Research Centre (JRC), Ispra The 2007-2008 financial and banking crisis rapidly spread in Europe, nurturing a severe economic crisis which involved mostly all countries, challenging their ability to recover and restore their growth path. Moreover, the Great Recession affected European countries unevenly, determining regional inequalities, within and between countries (Arestis et al., 2011). Among the effects, less job opportunities and lower social mobility affected, particularly, less dynamic regions and cities and worsened the social conditions of people with a lower social status (Corrado and Corrado, 2011). Indeed, many regions were left outside the agglomeration process going on in metropolitan cities. This rapid growth and GDP concentration involving only dynamic regions fuelled grievances in many local communities, left without support from the institutions (Hendrickson et al., 2018). The regional heterogeneities and the rise of spatial inequalities are among the determinants for intra- and inter- regional conflicts, which may result in a social, economic and political time of instability (Ezcurra and Rodriguez-Pose, 2014). The rising discontent across territories revealed itself in the ballot box, where people expressed their mistrust towards the institutions and the political system, perceived as unable to face their problems and needs (Rodriguez-Pose, 2018). Votes became the expressions of the socio-economic and geographical contexts and, as shown by Dijkstra et al. (2018), they are mirroring the grown feeling of resentment in some territories. -

Joint Research Centre Science and Knowledge Management at the Service of Europe’S Citizens
The Joint Research Centre Science and knowledge management at the service of Europe’s citizens The Joint Research Centre is the European Commission’s science and knowledge service. Our researchers provide EU and national authorities with solid facts and independent support to help tackle the big challenges facing our societies today. Our headquarters are in Brussels and we have research sites in five Member States: Geel (Belgium), Ispra (Italy), Karlsruhe (Germany), Petten (the Netherlands) and Seville (Spain). Our work is largely funded by the EU’s budget for Research and Innovation. We create, manage and make sense of knowledge, delivering the best scientific evidence and innovative tools for the policies that matter to citizens, businesses and governments, including: THE DIGITAL TRANSFORMATION • Investigating the impact of new digital A FAIRER AND MORE COMPETITIVE ECONOMY technologies on societies, from children’s • Supporting EU industry through scientific development to the world of work; research leading to new standards; • Helping EU schools assess how well they are using • Helping EU regions build on their strengths digital technologies in teaching and learning with in economic development through smart the SELFIE tool; specialisation; • Analysing the characteristics of online markets and • Supporting EU satellite projects with scientific supporting fair taxation in the digital economy; and technical expertise; • Developing applications for children and adults • Backing the European Pillar of Social Rights with to promote the -

Download Abstract
THE EFFECT OF LIMITED RENEWABLE RESOURCES ON THE ELECTRICITY GENERATION IN A LOW-CARBON EUROPE Pablo Ruiz, Institute for Energy and Transport, Joint Research Centre – European Commission * Westerduinweg 3, NL-1755LE Petten, The Netherlands Phone: +31-224-565150, [email protected] Sofia Simoes, Institute for Energy and Transport, Joint Research Centre – European Commission* Wouter Nijs, Institute for Energy and Transport, Joint Research Centre – European Commission* Alessandra Sgobbi, Institute for Energy and Transport, Joint Research Centre – European Commission* Christian Thiel, Institute for Energy and Transport, Joint Research Centre – European Commission* *The views expressed are purely those of the authors and may not in any circumstances be regarded as stating an official position of the European Commission. Overview Renewable-based electricity generation technologies are recognized to be a major-prerequisite to reach a sustainable and secure energy system by 2050 (European Commission, 2011). From an energy-systems analysis perspective, a significant increase in the relevance of renewable electricity generation technologies is foreseen (European Commission, 2013) both in current policies scenarios and in those targeting over 80% CO2 emission reductions in 2050. Usually the impact of current and future technology cost on their competitiveness is analysed (European Commission, 2013), while less attention has been given to investigate the total amount of renewable resources available. Work has been already conducted to evaluate these renewable potentials (Resch et al., 2008), but still substantial uncertainties remain due to methodological challenges or due to coarse measuring resolution (Badger & Ejsing Jørgensen, 2011). In this paper we will assess the sensitivity of the electricity mix evolution to the available renewable energy sources potentials by analysing the response of the partial equilibrium energy model JRC-EU-TIMES (Simoes et al., 2013) in the 2020-2050 time frame. -

2Nd World Wide Meeting of Young Academies and Joint Conference on “Scientific Support for Policy Making in Sustainable Development: Joining Forces”
2nd World Wide Meeting of Young Academies and Joint Conference on “Scientific support for policy making in sustainable development: Joining forces” 16‐18 November 2015 in Stockholm, Sweden From 16‐18 November 2015 the Global Young Academy (GYA), the Young Academy of Sweden (YAS) and the European Commission’s Joint Research Centre (JRC) co‐organized the 2nd Worldwide Meeting of Young Academies and Joint Conference on “Scientific support for policy making in sustainable development: Joining forces” in Stockholm, Sweden. Nearly all National Young Academies (NYAs) from around the world as well as some initiatives and similar organizations from a total of 32 countries were represented in this meeting. 2nd Worldwide Meeting of Young Academies Three years after the 1st Worldwide Meeting of Young Academies in 2012 in Amsterdam, The Netherlands, this second meeting offered again a great opportunity of exchange, inspiration and plans for cooperation. In the meantime, the movement has grown to currently 30 National Young Academies worldwide as Eva Alisic, Co‐Chair of the GYA from Australia, pointed out. Young Academy representatives met in a speed‐dating session in rotating pairs for five minutes each to draw up at least one joint project or find common points of interest. In following breakouts on topics determined by the participants, such as outreach and dialogue, influencing research policies, internationalization and networking; and the initiation of National Young Academies, groups of representatives exchanged experience in more detail. Issues of regional concern and plans for regional cooperation were discussed in regional breakout sessions for the three major regions with NYAs (Africa, Asia and Europe). -

Institutions, Policies and Enlargement of the European Union
This booklet is published in all the ofiicial EU languages of the European Union: Danish, Dutch, English, Finnish, French, German, Greek, ltalian, Portuguese, Spanish and Swedish. European Commission Directorate-General for Education and Culture Publications Unit, rue de la LoiAffetstraat 200, B-1049 Brussels A great deal of additional information on the European Union is available on the Internet. It can be accessed through the Europa server (http://europa.eu.int). Cataloguing data can be found at the end of this publication. Luxembourg: Office for Official Publications of the European Communities, 2000 lsBN 92-828-8282-9 O European Communities, 2000 Reproduction is authonsed provided the source is acknowledged. Printed in Belgium Pnrrurro oN wHtrE cHLoRtNE-FREE pApER Foreword This publication is an update of the previous edition of 'Glossary: The reform of the European Union in 150 definitions' that was produced in 1997. As indicated by its original title, this glossary was produced in order to help people to gain a better understanding of the challenges facing the European Union at the time of the Intergovemmental Conference that opened in 1996. It was subsequently expanded to cover the fundamentals ofEuropean integration, the operation of the institutions, the policies of the Community and the contributions of the Amsterdam Treaty. The inclusion of the essential aspects of the enlargement process and of Agenda2}O} and, in the future, the results of the Intergovemmental Conference of 2000, confirms the glossary's vocation of follow- ing European current affairs and explaining them to the public. An update of the definitions contained in this publication is available on the SCADPIus site, which can be accessed on the Europa server at the following address : http ://europa.eu.infl scadplus/. -

Directory of the Commission of the European Communities
Directory of the Commission of the European Communities Commission , of the European Communities s 'lJ1 - t Ci'7 1 Bulletin of the EUROPEAN COMMUNITIES Special Supplement Directory of the Commission of the European Communities Commission of the European Communities Bulletin of the European Communities Special Supplement Directory of the Commission of the European Communities Brussels - January 1974 EUROPEAN COMMUNITIES Commission CONTENTS Page The Commission 5 Special responsibilities of the Members of the Commission 7 Secretariat-General of the Commission 9 Legal Service 11 Spokesman's Group 13 Statistical Office 15 Administration of the Customs Union (ACU) 17 Environment and Consumer Protection Service 19 DG I - External Relations 21 DG II - Economic and Financial Affairs 25 DG III - Industrial and Technological Affairs 27 DG IV - Competition 29 DG V - Social Mfairs 31 DG VI - Agriculture 35 DG VII -Transport 39 DG VIII - Development and Cooperation 41 DGIX - Personnel and Administration 43 DG X - Information 47 DG XI - Internal Market 51 DG XII - Research, Science and Education 53 DG XIII - Scientific and Technical Information and Information Management 55 DG XV - Financial Institutions and Taxation 57 DG XVI - Regional Policy 59 DG XVII - Energy 61 DG XVIII - Credit and Investments 63 DG XIX - Budgets 65 DG XX - Financial Control 67 Joint Research Centre 69 Euratom Supply Agency 70 Security Office 70 Office for Official Publications of the European Communities 71 3 r ' . { THE COMMISSION 200, rue de Ia Loi, 1040 Brussels Tel. 35 00 -

Joint Research Centre
Joint Research Centre The European Commission’s in-house science service Hydrogen Energy for tomorrow Hydrogen Safety in Storage and Transport Why Hydrogen? Hydrogen is not a primary energy source such as coal computer modellers and technical staff of this project or gas but is an energy carrier (similar to electricity) perform pre-normative and underpinning research and can store and deliver energy in a widely useable for the development and improvement of performance form. It is one of the most promising alternative fuels characterisation methodologies for hydrogen storage, for future transport applications. When produced from detection and safety. In addition, they provide renewable sources it provides pollution-free transport, scientific and technological (S&T) support to without carbon dioxide (CO2) emissions, and decreases Community and international standardisation and our dependence on dwindling oil reserves. However, regulatory bodies in this field, and act as a reference significant development is needed before hydrogen on hydrogen storage, detection and safety-related can be exploited in the same way as conventional activities in the Commission’s Joint Technology fossil fuels. Initiative (JTI) on Fuel Cells and Hydrogen (FCH). Dedicated state-of-the-art testing facilities include How does JRC-IET Contribute to the Safe Use of those for: Hydrogen? •testing full-scale high-pressure hydrogen (and natural Safety, performance and end-use efficiency must be gas) tanks for vehicles; all assured before mass public use of hydrogen is •performance characterisation of materials for solid- possible. This is the motivation behind the Hydrogen state hydrogen storage; Safety in Storage and Transport (HySaST) project as it •performance characterisation of hydrogen sensors for supports the EU drive towards clean and efficient safety. -

Eu Research and Development Programmes
CROSS-CUTTING POLICIES | EU RESEARCH AND DEVELOPMENT PROGRAMMES CROSS-CUTTING POLICIES EU Research and Development Programmes Overview Today’s technologies have the potential to bend the carbon- emissions curve—but new, better, and cheaper innovations are a key component of any achievable plan for a net-zero– emissions economy by 2050. In its special report on Clean Energy Innovation, IEA estimates that currently mature technologies may reduce global emissions by 25 percent until 2070—but at least 35 percent of emissions cuts are expected to be delivered by technologies in the prototyping or demonstration phases. In other words, accelerated clean energy technology is essential to stopping climate change and limiting the rise of global temperatures. Government investment in clean energy research and innovation (R&I) can catalyse greater private-sector investment, help the EU reach its sustainable development targets, and maintain industrial competitiveness. Research and development (R&D) is usually understood as the first step in R&I. In 2017, total R&D spending in the EU was €317 billion, or 2.06 percent of its GDP. This was far below the official 3 percent target and behind Japan (spending 3.20 percent of its GDP), the U.S. (2.78 percent) and China (2.13 percent). Traditionally, around one-third of all R&D funding in the EU comes from public sources (some 10 percent from EU funds, 30 percent from national governments, and 60 percent from higher education). The rest comes from private R&D investments. The EU collates many R&I-related institutions, initiatives, and funds under one programme, Horizon Europe, which will run from 2021–2027 and replace the earlier Horizon 2020. -

Ninth Meeting of the European Union Physical Activity Focal Points Network
Ninth meeting of the European Union Physical Activity Focal Points Network Luxembourg January 2019 25-26 October 2018 Original: English Ninth meeting of the European Union Physical Activity Focal Points Network Meeting Report Address requests about publications of the WHO Regional Office for Europe to: Publications WHO Regional Office for Europe UN City, Marmorvej 51 DK-2100 Copenhagen Ø, Denmark Alternatively, complete an online request form for documentation, health information, or for permission to quote or translate, on the Regional Office website (http://www.euro.who.int/pubrequest). © World Health Organization, 2018. All rights reserved. The Regional Office for Europe of the World Health Organization welcomes requests for permission to reproduce or translate its publications, in part or in full. The designations employed and the presentation of the material in this publication do not imply the expression of any opinion whatsoever on the part of the World Health Organization concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. Dotted lines on maps represent approximate border lines for which there may not yet be full agreement. The mention of specific companies or of certain manufacturers’ products does not imply that they are endorsed or recommended by the World Health Organization in preference to others of a similar nature that are not mentioned. Errors and omissions excepted, the names of proprietary products are distinguished by initial capital letters. All reasonable precautions have been taken by the World Health Organization to verify the information contained in this publication. -

Future Directions for Scientific Advice in Europe
FUTURE DIRECTIONS FOR SCIENTIFIC ADVICE IN EUROPE Edited by James Wilsdon and Robert Doubleday April 2015 Open access. Some rights reserved. This work is licensed under the Creative Commons Attribution-Noncommercial 4.0 International (CC BY-NC 4.0) licence. You are free to copy and redistribute the material in any medium or format and remix, transform, and build upon the material, under the following terms: you must give appropriate credit, provide a link to the licence, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. To view the full licence, visit: www.creativecommons.org/licenses/by-nc/4.0/legalcode The Centre for Science and Policy gratefully acknowledges the work of Creative Commons in inspiring our approach to copyright. To find out more go to: www.creativecommons.org Published by Centre for Science and Policy April 2015 © Centre for Science and Policy. Some rights reserved. 10 Trumpington Street Cambridge CB2 1QA [email protected] www.csap.cam.ac.uk ISBN: 978-0-9932818-0-8 Disclaimer The European Commission support for the production of this publication does not constitute endorsement of the contents which reflect the views only of the authors, and the Commission cannot be held responsible for any use which may be made of the information contained therein. FUTURE DIRECTIONS FOR SCIENTIFIC ADVICE IN EUROPE Edited by James Wilsdon and Robert Doubleday CONTENTS The introduction was updated in June 2015 to take account of developments in the European Commission.