Learning to Select, Track, and Generate for Data-To-Text
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Huskers Return Home Looking to Continue
Texas Tech Red Raiders (13-12, 5-6 Big 12) at Nebraska Cornhuskers (16-8, 6-5 Big 12) • Game 25 • Lincoln, Neb. • Devaney Center (13,595) • Release Date: Feb. 17, 2006 Radio: Pinnacle Sports Network • TV: ESPN+ • Internet: Huskers.com (live radio, stats) The Coaches Nebraska Yr. Ht. Wt. Pts. Reb. Texas Tech Yr. Ht. Wt. Pts. Reb. Nebraska – Barry Collier, 282-217 overall, 86-85 in six years at NU G Jason Dourisseau Sr. 6-6 200 10.5 6.9 G Martin Zeno So. 6-5 202 15.2 5.6 Texas Tech – Bob Knight, 867-345 overall in 40 years, 103-56 in G Charles Richardson Jr. Jr. 5-9 160 4.0 3.2* G Jarrius Jackson Jr. 6-1 185 19.0 3.0* five seasons at TTU G Jamel White Fr. 6-3 180 6.8 1.8* F Darryl Dora Jr. 6-9 250 7.7 4.5 The Series F Wes Wilkinson Sr. 6-10 220 12.0 6.3 F Jon Plefka Jr. 6-8 245 6.5 4.3 NU leads series 12-8 after 84-68 loss in Lubbock in 2005. C Aleks Maric So. 6-11 265 10.4 8.0 F Michael Prince Fr. 6-7 205 2.5 2.5 *assists *assists Date Opponent Time/Result â â â Huskers Return Home Looking the Colorado game next week after spending most Nov. 18 ^Longwood (FSNMW) W, 80-65 of the past week handling prior commitments with Nov. 19 ^Yale W, 73-64 to Continue Momentum Pinnacle Sports Productions. -

Oh My God, It's Full of Data–A Biased & Incomplete
Oh my god, it's full of data! A biased & incomplete introduction to visualization Bastian Rieck Dramatis personæ Source: Viktor Hertz, Jacob Atienza What is visualization? “Computer-based visualization systems provide visual representations of datasets intended to help people carry out some task better.” — Tamara Munzner, Visualization Design and Analysis: Abstractions, Principles, and Methods Why is visualization useful? Anscombe’s quartet I II III IV x y x y x y x y 10.0 8.04 10.0 9.14 10.0 7.46 8.0 6.58 8.0 6.95 8.0 8.14 8.0 6.77 8.0 5.76 13.0 7.58 13.0 8.74 13.0 12.74 8.0 7.71 9.0 8.81 9.0 8.77 9.0 7.11 8.0 8.84 11.0 8.33 11.0 9.26 11.0 7.81 8.0 8.47 14.0 9.96 14.0 8.10 14.0 8.84 8.0 7.04 6.0 7.24 6.0 6.13 6.0 6.08 8.0 5.25 4.0 4.26 4.0 3.10 4.0 5.39 19.0 12.50 12.0 10.84 12.0 9.13 12.0 8.15 8.0 5.56 7.0 4.82 7.0 7.26 7.0 6.42 8.0 7.91 5.0 5.68 5.0 4.74 5.0 5.73 8.0 6.89 From the viewpoint of statistics x y Mean 9 7.50 Variance 11 4.127 Correlation 0.816 Linear regression line y = 3:00 + 0:500x From the viewpoint of visualization 12 12 10 10 8 8 6 6 4 4 4 6 8 10 12 14 16 18 4 6 8 10 12 14 16 18 12 12 10 10 8 8 6 6 4 4 4 6 8 10 12 14 16 18 4 6 8 10 12 14 16 18 How does it work? Parallel coordinates Tabular data (e.g. -

Cleveland Cavaliers (14-10) Vs
FRI., DEC. 19, 2014 QUICKEN LOANS ARENA – CLEVELAND, OH TV: FSO RADIO: WTAM 1100 AM/100.7 WMMS/LA MEGA 87.7 FM 7:30 PM EST CLEVELAND CAVALIERS (14-10) VS. BROOKLYN NETS (10-14) 2014-15 CLEVELAND CAVALIERS GAME NOTES REGULAR SEASON GAME #25 HOME GAME #14 PROBABLE STARTERS 2014-15 SCHEDULE POS NO. PLAYER HT. WT. G GS PPG RPG APG FG% MPG 10/30 vs. NYK Lost, 90-95 10/31 @ CHI WON, 114-108* F 23 LEBRON JAMES 6-8 250 14-15: 23 23 25.4 5.4 7.6 .494 37.7 11/4 @ POR Lost, 82-101 11/5 @ UTA Lost, 100-102 11/7 @ DEN WON, 110-101 F 0 KEVIN LOVE 6-10 243 14-15: 24 24 17.6 10.5 2.4 .444 36.2 11/10 vs. NOP WON, 118-111 11/14 @ BOS WON, 122-121 11/15 vs. ATL WON, 127-94 C 17 ANDERSON VAREJAO 6-11 267 14-15: 23 23 9.7 6.6 1.3 .547 25.0 11/17 vs. DEN Lost, 97-106 11/19 vs. SAS Lost, 90-92 11/21 @ WAS Lost, 78-91 F 31 SHAWN MARION 6-7 228 14-15: 24 21 5.4 3.5 1.1 .427 24.1 11/22 vs. TOR Lost, 93-110 11/24 vs. ORL WON, 106-74 G 2 KYRIE IRVING 6-3 193 14-15: 24 24 19.9 3.0 5.3 .460 37.8 11/26 vs. WAS WON, 113-87 11/29 vs. -

PAT DELANY Assistant Coach
ORLANDO MAGIC MEDIA TOOLS The Magic’s communications department have a few online and social media tools to assist you in your coverage: *@MAGIC_PR ON TWITTER: Please follow @Magic_PR, which will have news, stats, in-game notes, injury updates, press releases and more about the Orlando Magic. *@MAGIC_MEDIAINFO ON TWITTER (MEDIA ONLY-protected): Please follow @ Magic_MediaInfo, which is media only and protected. This is strictly used for updated schedules and media availability times. Orlando Magic on-site communications contacts: Joel Glass Chief Communications Officer (407) 491-4826 (cell) [email protected] Owen Sanborn Communications (602) 505-4432 (cell) [email protected] About the Orlando Magic Orlando’s NBA franchise since 1989, the Magic’s mission is to be world champions on and off the court, delivering legendary moments every step of the way. Under the DeVos family’s ownership, the Magic have seen great success in a relatively short history, winning six division championships (1995, 1996, 2008, 2009, 2010, 2019) with seven 50-plus win seasons and capturing the Eastern Conference title in 1995 and 2009. Off the court, on an annual basis, the Orlando Magic gives more than $2 million to the local community by way of sponsorships of events, donated tickets, autographed merchandise and grants. Orlando Magic community relations programs impact an estimated 100,000 kids each year, while a Magic staff-wide initiative provides more than 7,000 volunteer hours annually. In addition, the Orlando Magic Youth Foundation (OMYF) which serves at-risk youth, has distributed more than $24 million to local nonprofit community organizations over the last 29 years.The Magic’s other entities include the team’s NBA G League affiliate, the Lakeland Magic, which began play in the 2017-18 season in nearby Lakeland, Fla.; the Orlando Solar Bears of the ECHL, which serves as the affiliate to the NHL’s Tampa Bay Lightning; and Magic Gaming is competing in the second season of the NBA 2K League. -

Arkansas Notes-2.Qxd
MISSISSIPPI STATE UNIVERSITY 2007-08 MEN’S BASKETBALL Mississippi State University Athletic Media Relations • PO Box 5308 • MSU, MS 39762 Men’s Basketball SID: David Rosinski • 662-325-3595 • [email protected] Game #24 - Mississippi State (16-7, 7-2) vs. Arkansas (17-6, 6-3) Saturday, February 16, 2008 • 3 p.m. CT • Starkville, MS Humphrey Coliseum (10,500) • ESPN MISSISSIPPI STATE BULLDOGS (16-7, 7-2) 2007-08 MSU RESULTS (16-7, 7-2) Pos. No. Name Ht. Wt. Cl. Hometown PPG RPG APG DATE OPPONENT (TV) SCORE/TIME F 23 Charles Rhodes 6-8 245 Sr. Jackson, MS 14.9 7.7 1.6 bpg Nov. 10 LOUISIANA TECH W 75-45 Nov. 15 CLEMSON (FSN/SUN) L 82-84 C 32 Jarvis Varnado 6-9 210 So. Brownsville, TN 7.1 7.8 4.8 bpg Nov. 17 UT MARTIN W 86-70 G 22 Barry Stewart 6-2 170 So. Shelbyville, TN 12.0 4.3 2.9 Nov. 22 #UC Irvine (ESPNU) W 68-53 Nov. 23 #Southern Illinois (ESPN2) L 49-63 UBSTITUTES G 11 Ben Hansbrough 6-3 205 So. Poplar Bluff, MO 10.3 3.6 2.6 S Nov. 23 #Miami [OH] (ESPN2) L 60-67 G 44 Jamont Gordon 6-4 230 Jr. Nashville, TN 18.1 6.3 4.7 Dec. 1 MURRAY STATE W 78-61 OP G 25 Phil Turner 6-3 170 Fr. Grenada, MS 5.0 3.4 1.0 Dec. 8 SOUTHEASTERN LA. (CSS) W 84-59 Dec. 13 MIAMI [FL] (FSN/SUN) L 58-64 F/C 21 Brian Johnson 6-9 245 Jr. -
![BASKET [2 Tornei] – Basketball Arena – 28 Lug / 12 Ago –](https://docslib.b-cdn.net/cover/4871/basket-2-tornei-basketball-arena-28-lug-12-ago-224871.webp)
BASKET [2 Tornei] – Basketball Arena – 28 Lug / 12 Ago –
BASKET [2 tornei] – Basketball Arena – 28 Lug / 12 Ago – Medagliere (ordinato secondo i totali delle medaglie) ORO ARG BRO Tot. USA 2 0 0 2 ESP 0 1 0 1 FRA 0 1 0 1 AUS 0 0 1 1 RUS 0 0 1 1 2 2 2 6 • Uomini [1] – 12 squadre (sorteggio: 30 Aprile). Gr-A: ARG, FRA, LTU, NGR, TUN, USA. Gr-B: AUS, BRA, CHN, ESP, GBR, RUS. 1. Stati Uniti (USA) – ORO (Tyson Chandler, Kevin Durant, Lebron James, Russell Westbrook, Deron Williams, Andre Iguodala, Kobe Bryant, Kevin Love, James Harden, Chris Paul, Anthony Davis, Carmelo Anthoby) 2. Spagna (ESP) – ARGENTO (Pau Gasol, Rudy Fernandez, Sergio Rodriguez, Juan-Carlos Navarro, Jose Calderon, Felipe Reyes, Victor Claver, Fernando San Emeterio, Sergio Llull, Marc Gasol, Serge Ibaka, Victor Sada) 3. Russia (RUS) – BRONZO (Alexey Shved, Timofey Mozgov, Seregy Karasev, Vitaliy Fridzon, Sasha Kaun, Evgeny Voronov, Victor Khryapa, Semen Antonov, Sergey Monya, Dmitry Khvostov, Anton Ponkrashov, Andrei Kirilenko) 4. ARG; =5. AUS, BRA, FRA, LTU. Finale 1° posto [12-8] USA-ESP 107-100 Finale 3° posto [12-8] ARG-RUS 77-81 Semifinali [10-8] – ARG-USA 83-109 ESP-RUS 67-59 Quarti [8-8] – BRA-ARG 77-82 USA-AUS 119-86 FRA-ESP 59-66 RUS-LTU 83-74 Qualificazioni – (le prime 4 qualificate ai Quarti) Gr-A [29-7] NGR-TUN 60-56; USA-FRA 98-71; ARG-LTU 102-79. [31-7] LTU-NGR 72-53; FRA-ARG 71-64; TUN-USA 63-110. [2-8] FRA-LTU 82-74; ARG-TUN 92-69; USA-NGR 156-73. -

2018-19 Phoenix Suns Media Guide 2018-19 Suns Schedule
2018-19 PHOENIX SUNS MEDIA GUIDE 2018-19 SUNS SCHEDULE OCTOBER 2018 JANUARY 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 SAC 2 3 NZB 4 5 POR 6 1 2 PHI 3 4 LAC 5 7:00 PM 7:00 PM 7:00 PM 7:00 PM 7:00 PM PRESEASON PRESEASON PRESEASON 7 8 GSW 9 10 POR 11 12 13 6 CHA 7 8 SAC 9 DAL 10 11 12 DEN 7:00 PM 7:00 PM 6:00 PM 7:00 PM 6:30 PM 7:00 PM PRESEASON PRESEASON 14 15 16 17 DAL 18 19 20 DEN 13 14 15 IND 16 17 TOR 18 19 CHA 7:30 PM 6:00 PM 5:00 PM 5:30 PM 3:00 PM ESPN 21 22 GSW 23 24 LAL 25 26 27 MEM 20 MIN 21 22 MIN 23 24 POR 25 DEN 26 7:30 PM 7:00 PM 5:00 PM 5:00 PM 7:00 PM 7:00 PM 7:00 PM 28 OKC 29 30 31 SAS 27 LAL 28 29 SAS 30 31 4:00 PM 7:30 PM 7:00 PM 5:00 PM 7:30 PM 6:30 PM ESPN FSAZ 3:00 PM 7:30 PM FSAZ FSAZ NOVEMBER 2018 FEBRUARY 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 2 TOR 3 1 2 ATL 7:00 PM 7:00 PM 4 MEM 5 6 BKN 7 8 BOS 9 10 NOP 3 4 HOU 5 6 UTA 7 8 GSW 9 6:00 PM 7:00 PM 7:00 PM 5:00 PM 7:00 PM 7:00 PM 7:00 PM 11 12 OKC 13 14 SAS 15 16 17 OKC 10 SAC 11 12 13 LAC 14 15 16 6:00 PM 7:00 PM 7:00 PM 4:00 PM 8:30 PM 18 19 PHI 20 21 CHI 22 23 MIL 24 17 18 19 20 21 CLE 22 23 ATL 5:00 PM 6:00 PM 6:30 PM 5:00 PM 5:00 PM 25 DET 26 27 IND 28 LAC 29 30 ORL 24 25 MIA 26 27 28 2:00 PM 7:00 PM 8:30 PM 7:00 PM 5:30 PM DECEMBER 2018 MARCH 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 1 2 NOP LAL 7:00 PM 7:00 PM 2 LAL 3 4 SAC 5 6 POR 7 MIA 8 3 4 MIL 5 6 NYK 7 8 9 POR 1:30 PM 7:00 PM 8:00 PM 7:00 PM 7:00 PM 7:00 PM 8:00 PM 9 10 LAC 11 SAS 12 13 DAL 14 15 MIN 10 GSW 11 12 13 UTA 14 15 HOU 16 NOP 7:00 -

Full Page Photo Print
USC Men’s Basketball Release Game 34 • USC vs. Boston College • March 20, 2009 • NCAA 1st Round University of Southern California Sports Information Offi ce, Heritage Hall 103, L.A., CA 90089-0601 - Phone: (213) 740-8480 - Fax: (213) 740-7584 2008-09 USC Schedule USC FACES BC IN NCAA FIRST ROUND Exhibition • Trojans making school-record 3rd-straight NCAA trip • Date Opponent Result/Time 10/26 Cardinal & Gold Game ---, 90-74 LOS ANGELES, CALIF. -- The No. 10 seed USC Trojans (21-12, 9-9/T-5th in Pac-10) 11/3 Azusa Pacifi c W, 85-64 will face the No. 7 seed Boston College Eagles (22-11, 9-7/T-5th in ACC) in the fi rst round Regular Season of the NCAA Tournament at the Metrodome in Minneapolis, Minn. on March 20 at 4:20 p.m. 11/15 UC Irvine W, 78-55 PT. USC has won 20 or more games and reached the NCAA Tournament the last three 11/18 New Mexico State W, 73-60 seasons, both school records. The game is being broadcast on CBS with Gus Johnson 11/20 ^vs. Seton Hall L, 61-63 calling the play-by-play and Len Elmore providing color commentary. 11/21 ^vs. Chattanooga W, 73-46 11/23 ^vs. Missouri L, 72-83 USC IN THE NCAA TOURNAMENT -- USC is 11-16 all-time in the NCAA Tournament, 11/28 Tennessee-Martin W, 70-43 losing last season as a No. 6 seed in the fi rst round to No. 11 seed Kansas State 80-67 12/1 San Francisco W, 74-69 in Omaha, Neb. -

Individual Statistical Leaders
Tournament Individual Leaders (as of Aug 14, 2012) All games FIELD GOAL PCT (min. 10 made) FG ATT Pct FIELD GOAL ATTEMPTS G Att Att/G -------------------------------------------- --------------------------------------------- Darius Songaila-LTH........... 24 30 .800 Patrick Mills-AUS............. 6 116 19.3 Tyson Chandler-USA............ 14 20 .700 Luis Scola-ARG................ 8 106 13.3 Andre Iguodala-USA............ 14 20 .700 Manu Ginobili-ARG............. 8 103 12.9 Aaron Baynes-AUS.............. 21 32 .656 Kevin Durant-USA.............. 8 101 12.6 Anthony Davis-USA............. 11 17 .647 Pau Gasol-ESP................. 8 100 12.5 Kevin Love-USA................ 34 54 .630 Dan Clark-GBR................. 15 24 .625 FIELD GOALS MADE G Made Made/G Tomofey Mozgov-RUS............ 33 53 .623 --------------------------------------------- LeBron James-USA.............. 44 73 .603 Pau Gasol-ESP................. 8 57 7.1 Serge Ibaka-ESP............... 26 45 .578 Luis Scola-ARG................ 8 56 7.0 Nene Hilario-BRA.............. 12 21 .571 Manu Ginobili-ARG............. 8 51 6.4 Pau Gasol-ESP................. 57 100 .570 Kevin Durant-USA.............. 8 49 6.1 Patrick Mills-AUS............. 6 49 8.2 3-POINT FG PCT (min. 5 made) 3FG ATT Pct 3-POINT FG ATTEMPTS G Att Att/G -------------------------------------------- --------------------------------------------- Shipeng Wang-CHN.............. 13 21 .619 Kevin Durant-USA.............. 8 65 8.1 S. Jasikevicius-LTH........... 7 12 .583 Carlos Delfino-ARG............ 8 54 6.8 Dan Clark-GBR................. 8 14 .571 Patrick Mills-AUS............. 6 48 8.0 Andre Iguodala-USA............ 5 9 .556 Carmelo Anthony-USA........... 8 46 5.8 Amine Rzig-TUN................ 8 15 .533 Manu Ginobili-ARG............. 8 43 5.4 Kevin Durant-USA............. -

Chimezie Metu Demar Derozan Taj Gibson Nikola Vucevic
DeMar Chimezie DeRozan Metu Nikola Taj Vucevic Gibson Photo courtesy of Fernando Medina/Orlando Magic 2019-2020 • 179 • USC BASKETBALL USC • In The Pros All-Time The list below includes all former USC players who had careers in the National Basketball League (1937-49), the American Basketball Associa- tion (1966-76) and the National Basketball Association (1950-present). Dewayne Dedmon PLAYER PROFESSIONAL TEAMS SEASONS Dan Anderson Portland .............................................1975-76 Dwight Anderson New York ................................................1983 San Diego ..............................................1984 John Block Los Angeles Lakers ................................1967 San Diego .........................................1968-71 Milwaukee ..............................................1972 Philadelphia ............................................1973 Kansas City-Omaha ..........................1973-74 New Orleans ..........................................1975 Chicago .............................................1975-76 David Bluthenthal Sacramento Kings ..................................2005 Mack Calvin Los Angeles (ABA) .................................1970 Florida (ABA) ....................................1971-72 Carolina (ABA) ..................................1973-74 Denver (ABA) .........................................1975 Virginia (ABA) .........................................1976 Los Angeles Lakers ................................1977 San Antonio ............................................1977 Denver ...............................................1977-78 -

Jugarenequipo-Partidos De Luka Doncic
www.jugarenequipo.es Hay 178 partidos en el informe Partidos de Luka Dončić 2015 - 28-febrero-1999 2018 Nota: La casilla de verificación seleccionada indica los partidos completos Código colores sombreado duración indica fuente: Elinksbasket Grabación Intercambio Internet+edición Web RTVE Youtube 2014-2015 Liga Endesa 30/04/2015 Liga Regular Jornada 29 Real Madrid Baloncesto 92-77 Unicaja Málaga 2061 K. C. Rivers: 11 pts 2 reb 1 rec. Rudy Fernández: 2 pts 4 reb 2 asi. Andrés Nocioni: 12 pts 4 reb 3 asi. Facundo Campazzo: 3 pts 1 asi. Jonas Maciulis: 5 pts 3 reb 1 asi. Felipe Reyes: 21 pts 4 reb. Sergio "Chacho" Rodríguez: 7 pts 6 asi. Gustavo Ayón: 4 pts 3 reb 2 asi. Luka Doncic: 3 pts. Sergio Llull: 16 pts 1 reb 7 asi 3 fpr. Ioannis Bourousis: 2 pts 1 reb. Marcus Slaughter: 6 pts 1 reb 1 asi. Stefan Markovic: 2 pts 1 reb 3 asi. Kostas Vasileiadis: 5 pts 1 reb 1 asi. Ryan Toolson: 2 pts 1 reb. Will Thomas: 10 pts 4 reb 1 asi. Carlos Suárez: 15 pts 4 reb 1 tap. Kenan Karhodzic: 2'. Jayson Granger: 11 pts 3 reb 6 asi 5 fpr. Fran Vázquez: 2 pts 1 reb. Mindaugas Kuzminskas: 4 pts 2 reb 1 asi. Jon Stefansson: 2 pts 1 reb 3 asi. Caleb Green: 13 pts 7 reb 3 asi. Vladimir Golubovic: 11 pts 11 reb 3 fpr. Excelente --AVC 16:9 1280x720 3623 kb/s Variable AC3 2 canales 192 kb/s Teledeporte 1:56:21 DVD5 2015 Copa Intercontinental 25/09/2015 Final Ida Bauru Basket 91-90 Real Madrid Baloncesto 3003 Patric Viera: DNP. -
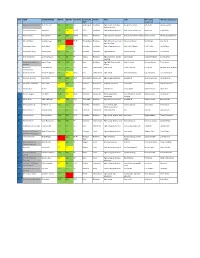
Pick Team Player Drafted Height Weight Position
PICK TEAM PLAYER DRAFTED HEIGHT WEIGHT POSITION SCHOOL/RE STATUS PROS CONS NBA Ceiling NBA Floor Comparison GION Comparison 1 Boston Celtics (via Nets) Markelle Fultz 6'4" 190 PG Washington Freshman High upside, immediate No significant flaws John Wall Jamal Crawford NBA production 2 Los Angeles Lakers Lonzo Ball 6"6 190 PG/SG UCLA Freshman High college production Slight lack of athleticism Kyrie Irving Jrue Holiday 3 Phoenix Suns Josh Jackson 6"8" 205 SG/SF Kansas Freshman High defensive potential Shot creation off the dribble Kawhi Leonard Michael Kidd Gilchrist 4 Orlando Magic Jonathan Isaac 6'10" 210 SF/PF Florida State Freshman High defensive potential, 3 Very skinny frame Paul George Otto Porter point shooting 5 Philadephia 76ers Malik Monk 6'3" 200 SG Kentucky Freshman High college production Slight lack of height CJ MCCollum Lou Williams 6 Sacramento Kings Dennis Smith 6'2" 195 PG NC State Freshman High athleticism 3 point shooting Russell Westbrook Eric Bledsoe 7 New York Knicks Lauri Markkanen 7'1" 230 PF Arizona Freshman High production, 3 point Low strength Kristaps Porzingiz Channing Frye shooting 8 Sacramento Kings (via Jayson Tatum 6'8" 205 SF Duke Freshman High NBA floor, smooth Lack of intesity Harrison Barnes Trevor Ariza Pelicans) offense 9 Minnesota Frank Ntilikina 6'5' 190 PG France International High upside 3 point shooting George Hill Michael Carter Williams Timberwolves 10 Dallas Mavericks Terrance Ferguson 6'7" 185 SG/SF USA International High upside Poor ball handling Klay Thompson Tim Hardaway JR 11 Charlotte